개요
인터넷에서 소통이란 IP에서 IP로 정보를 보내는 것이다.
정보는 여러 포장을 거쳐서 패킷(packet)으로 보내진다.
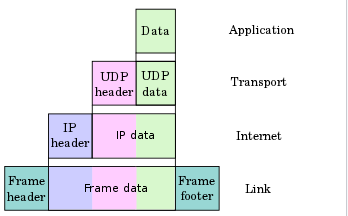
- TCP / IP 4계층 모델
그림과 같이 4개의 layer 구조를 가진다.
Open Systems Interconnection라고 OSI 7계층이라는 구조도 있지만 TCP / IP 4계층 구조가 가장 대중적이다.
- Application 계층에서 Data를 만든다.
- Transport 계층에서 UDP, 혹은 TCP 정보를 만들어 Data를 포장. (헤더에는 port 주소 등이 담긴다.)
- Internet 계층에서 IP 정보를 만들어 포장. (IP 헤더에는 IP 주소 등이 담긴다.)
TCP는 전송 제어 프로토콜인데, 3 way handshake라는 방식을 쓴다.
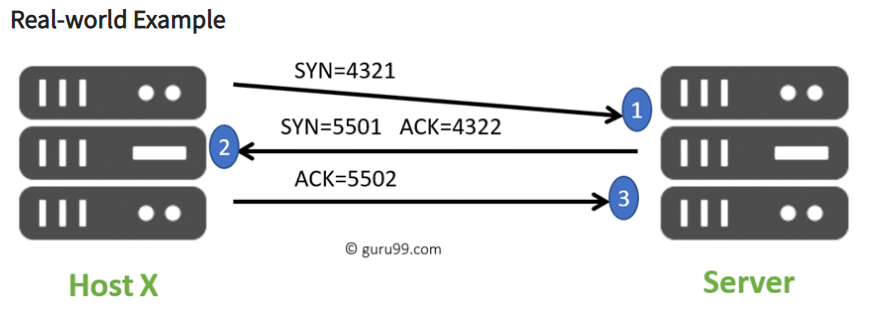
- 접속이 되는지 확인한다.(SYN)
- 서버는 접속이 된다고 요청을 수락, 정보 보내라고 요청한다.(ACK, SYN)
- 클라이언트는 요청을 수락하고, 정보를 보낸다.
한 IP 내에서 여러 요청을 할 때
특정 서비스를 제공하는 사이트에서 그 서비스 하나만 제공하는 경우는 별로 없다.
유저가 한 사이트에서 여러 서비스를 이용하려면 IP 접근만으로는 한계가 있다.
그래서 PORT가 있다.
유명한 포트 번호로는 443(HTTPS)가 있다. 보안 기능을 함께 제공한다.
IP가 도시라면 port는 항구다.
도시에서 교역을 하려면 1번 항구로 가야하고, 배를 수리하려면 2번 항구로 가야하는 식이다.
도메인
IP는 111.111.111.111 이런 식으로 구성되어있는데, 저렇게 주소를 입력해서 사이트를 접속하는 사람은 나는 아직 못 봤다.
DNS(Domain Name System)를 이용하면 도메인을 IP 주소로 변환해서 들어가게 해준다.
URI
Uniform: 구분한다.
Resource: 자원을,
Identifier: 식별자로.
URI는 보통 아래와 같은 형식을 가진다.
(port라던지, 생략되는 부분도 있다.)
schema://host/path?query=...

coffee png라고 검색하면 구글은 저렇게 긴 URI로 검색한다.
URI 설계
이름에 Resource가 들어가는 만큼, URI는 리소스를 기준으로 만들면 좋다.
/create/user... [X]
/user [O]
그렇지만 모든 URI를 리소스로만 만들 순 없다. 위의 구글 예시도 그렇다.
/search같은 건 컨트롤 URI다. 동사로 만드는 편.
똑같은 URI에서 회원 가입도 하고, 회원 조회도 하고..그런 건 어떻게 하지?
바로 HTTP 메소드(GET,POST 등)를 쓰면 된다.
HTTP 메소드
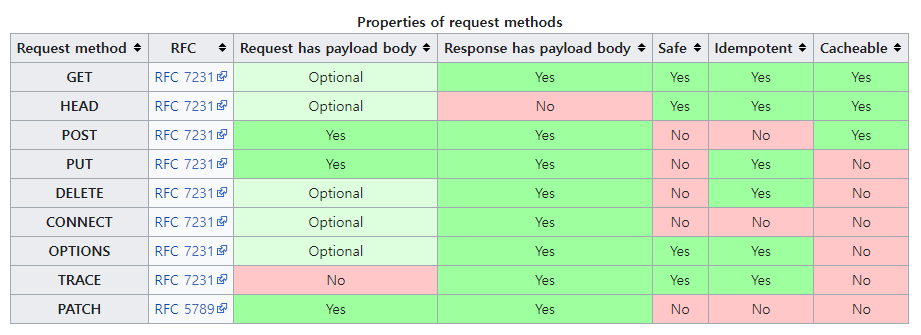
안전성(safe) : 해당 메소드를 호출해도 리소스는 변하지 않는다.
멱등성(Idempotent) : 해당 메소드를 몇 번 호출해도 결과는 동일하다.
캐시 가능(Cacheable) : 해당 메소드는 호출했을 때 캐싱 가능하다.
- GET : 데이터 조회할 때 사용.
- POST : 리소스 신규 등록(URI 몰라도 됨. 서버가 알아서 URI 등록), 정보를 가지고 작업하거나 처리, 조회, 수정할 때 등 다용도
- PUT : 리소스 신규 등록(클라이언트가 URI를 알고 입력해야 됨), 정보 수정(일부 내용 변경할 때엔 PATCH가 더 취지에 맞음. PUT은 기존의 데이터를 다 날려먹기 때문.)
POST처럼 서버가 URI를 만들고 관리하는 디렉토리는 Collection,
PUT처럼 클라이언트가 URI를 알고 관리하면 디렉토리는 Store라 부른다.
HTTP status
200~
정상 처리된 상태
- 200 : 정상 처리됨.
- 201 : 정상처리가 됐고, 서버에서 리소스를 만듦.
- 202 : 요청 접수는 했는데 처리가 안 됨.
- 204 : 요청은 정상처리됐는데 payload가 비어있음.

(벨로그에서 작성하던 글을 임시 저장할 때.)
300~
리다이렉트 관련
- 300 : 요청을 완료하려면 웹 브라우저에서 추가 조치가 필요.
- 301 : 영구적인 리다이렉트. 서버가 URI 주소를 바꿨을 때 리다이렉트시킴.(HTTP 메소드를 GET으로 바꾸는 편이고, 내가 작성한 것들이 날아감)
- 308 : 301이랑 비슷. (HTTP 메소드 유지, 내가 작성한 것들 유지. 하지만 쓸 일은 별로 없음)
- 302 : 일시적인 리다이렉트. HTTP 메소드가 GET으로 변할 수 있음.
- 303 : 일시적 리다이렉트. HTTP 메소드가 GET으로 변함.
- 307 : 일시적 리다이렉트. HTTP 메소드에 변경 없음.
- 304 : 캐시 목적 리다이렉트.
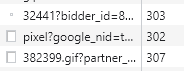
삭제된 글 링크를 클릭했더니 저렇게 리다이렉트 됐다.
400~
클라이언트에서 잘못 요청함
따라서 요청을 재시도해도 성공할 가능성이 없다.
- 400 : 요청 구문, 메시지 등의 오류. (파라미터가 잘못됐거나 API 스펙에 안 맞을 때: 숫자를 보내야 하는데 문자를 보내는 등)
- 401 : 인증 에러. 응답에 www-Authenticate 헤더와 함께 인증법을 줘야함.
인증(Authentication, 본인 확인), 인가(Authorization, 해당 유저의 권한 확인)
테코톡 - 인증과 인가 - 403 : 요청은 맞는데, 권한이 안 맞음.
(일반 사용자가 관리자 권한으로 요청했다던지) - 404 : 해당 리소스를 못 찾음.
(해당 리소스가 서버에 없음. 혹은 해당 리소스를 숨길 때도 사용.)
500~
서버에서 뭔가 잘못함.
요청을 재시도하면 성공할 가능성이 있다.
- 500 : 서버 내부 문제. 애매할 땐 500
- 503 : 서버의 일시적 과부하, 혹은 점검용 서버 다운 등.
(Retry-After로 언제 복구될 지 작성할 수도 있음.)
서버 에러는 정말로 서버 문제일 때에만 띄우자.
HTTP 헤더
먼 옛날에는 RFC2616라는 HTTP 표준이 있었다고 한다.
Entity Header, Entity Body 구조였다는데...지금은 달라졌다.
지금은 entity 대신 representation이라고 쓴다.
(REST API에서 RE가 representational이다.)
본문을 payload라고도 표현한다.
헤더는 중요하다. 일종의 육하원칙이 담기는 곳이다.
처음에 IP, TCP 패킷 헤더에서도 IP, PORT 등의 정보가 들어간다는 얘기를 했다.
| 원칙 | HTTP 요청, 응답에 대한 설명 |
|---|---|
| who(누가) | 클라이언트 or 서버 |
| when(언제) | 접속이 가능하면, 조건이 성립하면. |
| where(어디서) | 앱, 웹 브라우저 등에서. |
| what(무엇을) | 데이터 작업, 처리, 생성, 서비스 이용 등 |
| how(어떻게) | 헤더 조건에 맞게 포장해서. |
| why(왜) | 서비스를 이용하고 싶어서(나), 요청이 들어와서(서버) |
헤더에 들어가는 옵션들
- Content-Type : 내용물이 어떤 타입인지 나타냄
- text/html
- charset=UTF-8
- application/json
- image/png....
- Content-Language : 내용물을 어떤 언어로 표시할지.
- ko(한국어)
- en(영어)
그 외에도 여러 가지 중요한 것들이 많이 담겨온다.
아래에 소개하는 것들도 전부 헤더에 들어가는 것들이다.
유용한 헤더 옵션들
- referer : referrer의 오타. 근데 그냥 referer로 쓰이고 있다.
내가 어떤 URI에서 들어왔는지 표시하는 것(뒤로 가기 누르면 보이는 사이트)
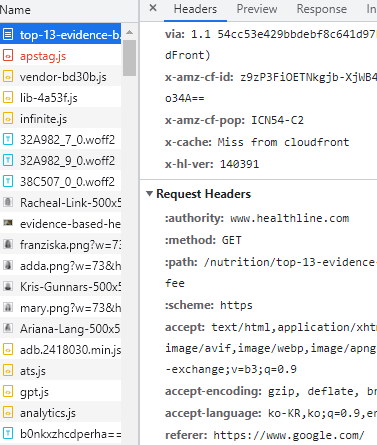
척 봐도 유저의 유입 경로를 분석할 때 최고다.
- user-agent : 클라이언트의 앱 정보(내 웹 브라우저라던지)

어느 브라우저에서 문제가 발생한다던지 조사할 수 있다.
- server : origin 서버의 정보

origin 서버란?
HTTP로 요청과 응답을 주고받을 때엔 중간에 여러 서버들을 거치게 된다.
origin은 최종적으로 응답을 주는 진짜 서버를 일컫는다.
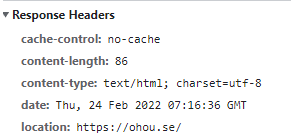
- location : 리다이렉트하는 주소
- HTTP 네고
“웬 네고? 네고왕? 당근에서 악명 높은 네고?”
거기서 말하는 네고 맞다. 협상이다.
우리는 HTTP 요청을 보낼 때 네고를 시도할 수 있다.
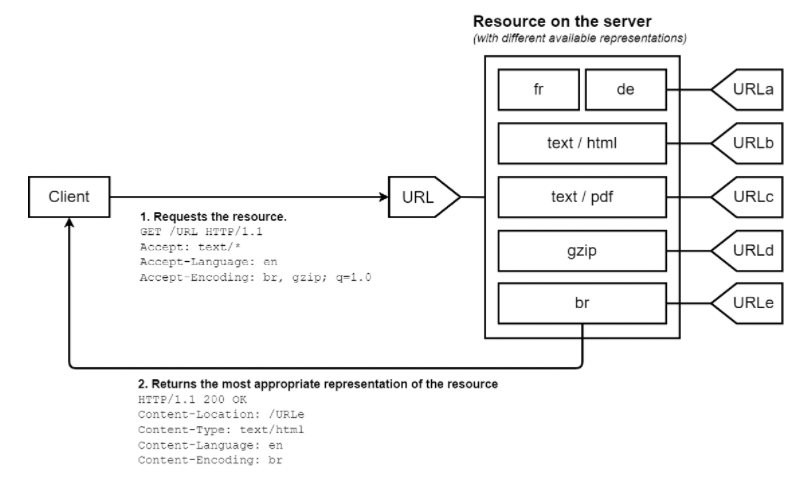
그림과 같이 HTTP 헤더에 Accept: 불라불라를 덧붙여서 요청을 보내면 서버는 그 요청에 '최대한' 맞춰서 응답한다.(무조건은 아니다.)
영어와 일본어만 제공하는 사이트에서 Accept-Language: ko로 보내면 서버는 지 맘대로 보낸다.
만약 서버가 일본어를 기본 옵션으로 설정했으면 일본어를 구경하게 된다.
내가 기본적으로 일본어보단 영어로 보고 싶다면? 아래와 같이 우선 순위를 옵션으로 넣으면 된다.
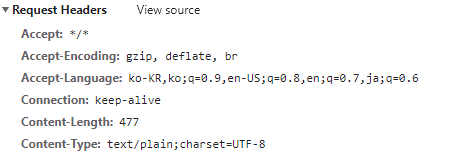
한국어를 최우선으로 요청하고, 없으면 영어, 일본어를 달라고 요청하는 것.
쿠키
- set-cookie : 쿠키 설정
HTTP는 기본적으로 무상태(Stateless) 프로토콜이다.
-> 요청을 보내고, 응답을 받았으면 역할은 끝난다. 기억할 필요도 없다.
하지만 우리는 접속할 때 로그인 상태를 기억해두는 게 일반적이다.
그래서 쿠키를 사용한다. 서버는 응답 시에 헤더에 set-cookie를 준다.
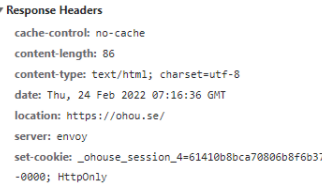
우리(브라우저)는 그 쿠키를 쿠키 저장소에 보관했다가 사용한다.
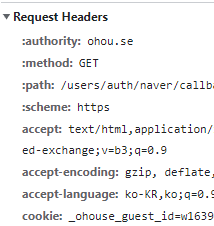
- 쿠키는 Session을 만들어서, 그 Session id만 돌려준다.
- 쿠키는 광고 정보 트래킹에도 사용한다. (이 브라우저를 쓰는 사람이 이러저러한 광고를 보는구나 알 수 있음)
- 쿠키 정보는 항상 서버에 보내기 때문에 정보를 최소로 사용해야 한다.
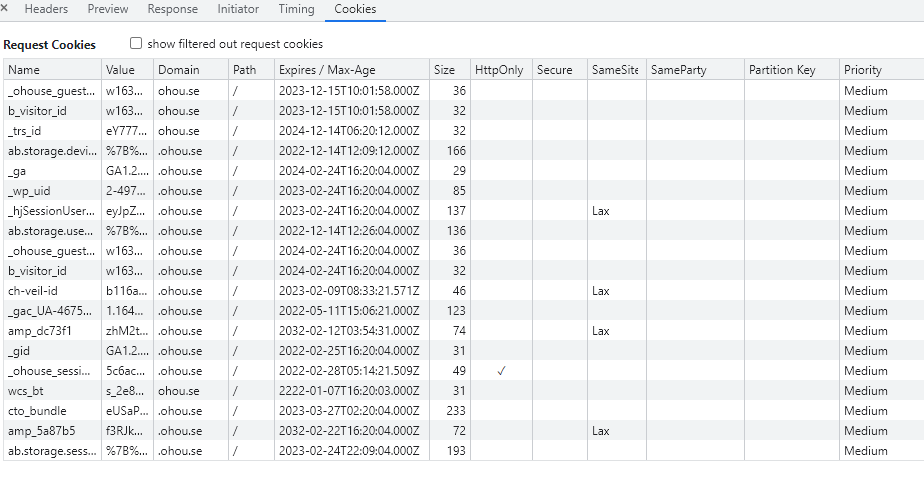
쿠키의 옵션들
Domain : 도메인을 지정해주면 서브(하위) 도메인에서도 쿠키를 사용할 수 있다. 지정 안 하면 정확히 그 도메인에서만 쿠키 사용 가능.
Path : 경로를 지정해두면 그 경로의 하위 경로들까지 쿠키들이 접근 가능하다.
expires : xxxx년 xx월 xx일 xx시 xx분 xx초까지 유효하게 두겠다.
Max-Age : 쿠키 발급일 기준으로 xx초 동안 유효하게 두겠다.
secure : 적용하면 https에서만 쿠키 전송, 미적용시 http에도 쿠키 전송.
HttpOnly : XSS 공격 방지. js에서 쿠키 접근이 불가능.
SameSite : XSRF 공격 방지. 요청 도메인과 쿠키에 설정된 도메인이 같을 때에만 쿠키 전송.
캐시
쿠키 덕분에 로그인 여부를 기억할 수 있게 됐다. 하지만 이걸로는 부족하다.
3MB 이미지를 요청하고, 2초 뒤에 또 그 이미지를 요청한다고 해보자.
캐시가 없으면 똑같은 이미지인데도 3MB짜리 요청을 또 해서 네트워크를 낭비한다.
캐시를 설정하면?
처음에만 다운로드 제대로 받고, 브라우저는 캐시 저장소에 캐시를 저장한다.
캐시가 유효할 동안에는 재방문 시 내 캐시에서 결과를 가져오기 때문에 로딩이 빠르다.
-
캐시의 장점
- 퍼포먼스 : (최초 다운로드 제외하고) 데이터를 부르는 데에 시간과 리소스를 절약할 수 있다.
- 오프라인 작업 : 인터넷 연결이 없이도 프로그램을 작동하는 데에 도움을 줄 수 있다.
- 리소스 효율 : 물리적으로도 도움을 준다. 배터리 절약이라던지.
-
캐시의 단점
- 퍼포먼스 : 캐시는 임시적으로 기억을 저장해두는 개념이다. 여러 앱을 쓰면 그만큼 캐시도 많이 쌓인다는 얘기.
- 손상(corruption) : 캐시도 손상될 수 있고, 그게 에러를 낼 수 있다.
- 낡은 정보(Outdated information) : 오래된 캐시는 잘못된(오래된) 정보를 반환할 수 있다. 버전 1.4.2를 써야하는데 캐시가 버전 1.1.1을 반환시키려고 하면 에러가 날 것이다.
위키에서도 찾아볼 수 있는 내용.
오래된 캐시가 문제라면 보통은 캐시를 비워주면 해결된다.
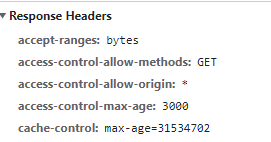
오늘의 집 cache-control 예시.
쿠키와 마찬가지로 max-age를 사용하고 있다.
유효기간을 31534702초나 준다. 대략 1년이다.
근데 정확히 1년은 아니고 364일 23시간 38분 22초라고 계산된다.
왜 저렇게 설정했는지는 모르겠다.
캐시 유효기간이 끝나면 어떻게 처리할까?
누군가는 캐시 유효기간을 비교적 짧게 둘 수도 있다. 예컨대 100초 동안만 유효하도록 설정했다고 치면, 2분 뒤에 또 요청하면 큰 용량을 처음부터 다운로드 받아야한다.
두 가지 방법을 사용한다.
- last-modified
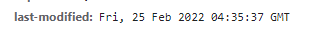
캐시를 저장할 때 최종 수정일 정보를 같이 넣고, 요청을 보낼 때 서버에서 비교한다.
클라이언트에 있는 캐시, 서버에 있는 캐시의 최종 수정일이 동일하면, 동일한 캐시라고 판단한다.
서버는 304 status를 보내면서 "클라이언트야. 네 캐시를 재사용해봐."라고 말한다.
이 때, 서버는 payload를 보낼 필요가 없어서 body가 비어있다.
그러면 브라우저는 캐시 저장소에서 유효기간이 끝난 애를 부활시킨다.
요청에선 if-modified-since: 를 사용한다.
한계 : 수정일만 비교하기 때문에, 내용물 변화가 없는 가벼운 수정에도 재다운로드를 시킨다.
- ETag(Entity Tag)

캐시 데이터에는 우리가 임의로 태그를 붙일 수 있다.
etag만 비교해보고 다르면 재다운로드, 같으면 유지하는 식이다.
요청할 땐 if-none-match를 사용한다.
캐시 쓰기 싫을 땐?
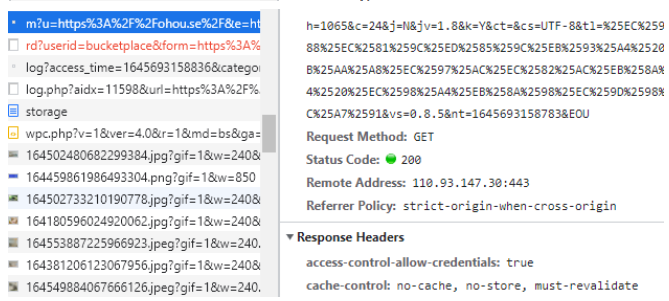
그림과 같이 확실하게 명시해줘야 한다.
명시를 안 하면 브라우저가 멋대로 판단해서 캐시하는 경우도 생긴다.
- no-cache : 캐시해도 되는데, origin 서버에서 검증하고 써라.
- no-store : 저장하지 마라. 얼른 사용하고 빨리 삭제해라. (민감한 정보)
- must-revalidate : 캐시해도 되는데, 만료 뒤에도 origin 서버에서 검증해라.
- 접근 실패시 반드시 오류가 발생해야 함.
- 유효 기간에는 캐시를 사용.
no-cache와 must-revalidate는 둘 다 웹 캐시(프록시 서버)에서 검증한다는 공통점이 있다.
예를 들어 프록시 서버와 origin 서버와의 연결에 일시적으로 문제가 생겼다고 가정해보자.
그럴 때 no-cache는 옛날 결과를 돌려주는 경우도 있다고 한다.(2월 25일 계좌 잔액 요청을 했는데, 1월 11일에 조회한 계좌 잔액을 보여준다던지.)
must-revalidate는 서버 에러(504)를 내보낸다.
웹 캐시(프록시 서버)?
우리가 아는 유명한 서비스들이 다 한국산은 아니다.
외국의 서비스들을 우리가 빠르게 이용할 수 있는 이유는 한국에 프록시 서버를 둬서 캐시를 저장해두기 때문이다. 그런데 위에서 말했듯이, 캐시는 최초로 조회할 땐 풀 다운로드를 받는다.
따라서 서비스를 최초로 이용하는 유저는 시간이 좀 걸린다.
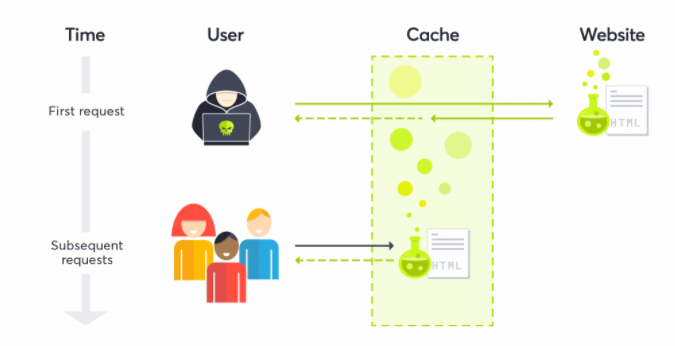
두 번째 이용자부터는 웹 캐시에 저장된 것들을 조회하기 때문에 시간이 단축된다.
HTTP 위키피디아 문서
MDN representation 헤더
MDN HTTP 헤더
MDN HTTP 헤더에 들어가는 것들
MDN 컨텐츠 네고
웹 캐시에 관한 이야기
XSS 공격과 HttpOnly
XSRF 공격과 SameSite
10분 테코톡 - cache
캐시
