
이 글은 크롬 자바스크립트 엔진 V8을 기준으로 작성했다.
1. 머릿말

이 글은 JavaScript가 어떻게 컴파일을 하는지 알아본다. 또한 이 글은 구글 크롬의 V8 엔진을 기준으로 작성했다.
컴파일은 사람이 쓰는 C, JavaScript 같은 고수준 언어를 기계어로 번역하면서 문법, 타입 체크 등 여러 작업을 거치는 과정이다. 그리고 JavaScript는 JIT라는 컴파일 방식을 사용한다.
Java 같은 정적 언어와 달리 JavaScript는 동적 언어라서 '실행 중에 최적화'할 필요가 있다. 그 때문에 동적 언어들은 JIT 컴파일을 쓰곤 한다.
정적 타입, 동적 타입 언어?
정적 타입 : 실행 전에 타입을 지정. (예: Java, TypeScript)
동적 타입 : 실행 중에 타입을 결정, 추론. (예: JavaScript)
2. JIT(Just-In-Time)
V8은 JavaScript를 실행하기 직전에 컴파일한다.
이런 방식을 JIT 컴파일이라 부른다. 코드를 바로 실행하지 않고 컴파일하는 이유는 간단한 예시로 설명할 수 있다.
- 특정 코드를 인터프리터로만 10000번 실행시키면 똑같은 내용을 처음부터 끝까지 10000번 읽는다.
- 특정 코드를 컴파일을 써서 10000번 실행시키면 저장했던 코드를 10000번 출력한다.
V8은 JS를 실행할 때 JIT 컴파일을 합니다. 스크립트를 실행하기 직전 파싱 & 컴파일하기 때문에 오버헤드가 많아질 수 있는데요. 이를 방지하기 위해 코드를 캐싱합니다.
스크립트를 처음 컴파일할 땐 캐시 데이터를 만들고 저장합니다. 나중에 V8이 똑같은 스크립트를 컴파일하려고 하면 인스턴스에서 캐시를 가져와서 결과를 바로 출력합니다. 따라서 스크립트를 더 빠르게 실행할 수 있고요.
...
캐시 생성에는 계산과 메모리 비용이 발생하는데요. 그래서 크롬은 이틀 내에 동일한 스크립트를 봤을 때 캐시를 만듭니다. 이렇게 하면 스크립트 파일을 평균 2배 이상 빠른 코드로 바꾸기 때문에 페이지 로딩 시 유저의 시간을 아낄 수 있습니다._
v8-compile-cache의 README.md에서도 확인할 수 있다.
V8의 프로파일러 스레드는 최적화가 필요하면 TurboFan(최적화 컴파일러)를 시켜서 해당 코드를 네이티브 코드로 컴파일한다.
대다수의 JS 정규 표현식 또한 irregexp engine을 사용해서 네이티브 코드로 컴파일한다. 이런 식으로 V8은 런타임에 가용 메모리를 할당한다.
JIT 컴파일은 실행 속도가 빠르다. => 메모리 좀 잡아먹는다. => 메모리 접근이 쉽다 => 보안과 연관된다.
어떨 땐 메모리 할당 없이 실행하는 게 바람직할 수 있는데요. 일부 플랫폼(iOS, 스마트 TV, 게임 콘솔 등)은 가용 메모리에 접근할 수 없습니다. V8를 사용할 수 없단 얘기죠. 가용 메모리 작성을 금지하면 어플 악용을 위한 공격 표면(attack surface)을 줄일 수 있습니다.
...
V8의 JIT-less 모드는 이를 위한 모드입니다. jitless 플래그로 V8을 시작하면 런타임에 가용 메모리를 할당하지 않고 사용합니다._
- 메모리에 접근하기 때문에 공격 표면이 넓어진다.
- 성능은 좋아도 추가적인 메모리와 CPU 사이클을 요구해서 무겁다.
JIT와 대비되는 개념으로 AOT(Ahead-of-Time) 컴파일이 있다. JIT와 AOT의 가장 큰 차이는 컴파일을 브라우저에서 하느냐(JIT), 서버에서 하느냐(AOT)다.
브라우저 입장에선 서버에서 미리 컴파일해서 건네주면 실행할 때 속도는 더 빠르다. 대신 서버 입장에서 빌드 시간이 길어지고, 미리 번역해서 주다보니 파일 크기도 커진다. 각자 장단점이 있다. 여담으로 Java, PyPy도 JIT 방식이다.
PyPy는 JIT 컴파일러를 쓰기 때문에 대체로 파이썬보다 빠릅니다.
-위키피디아-
2-1. Runtime
runtime은 여러 뜻이 있다.
- runtime (실행중)
- runtime libaray (컴파일러, 가상 머신이 쓰는 라이브러리)
- runtime environment (runtime system, 실행할 수 있도록 돕는 프로그램)
tslib 공식 문서. runtime library라고 기술하고 있다.
이 포스팅은 runtime environment 위주로 소개한다.
구글 Apps Script에서는 다음과 같이 소개한다.
자바스크립트 엔진은 파싱과 스크립트 코드를 실행하고, 런타임은 자바스크립트 엔진을 포함합니다. 런타임은 메모리에 접근하는 법, 운영 체제와 상호작용하는 법, 올바른 프로그램 구문 규칙 등을 제공합니다. 각 브라우저마다 JavaScript용 런타임 환경이 있습니다.
엔진: 코드를 파싱하고 실행 가능 명령어로 변환, 실행.
런타임: 외부와 상호작용하기 위해 JavaScript에 객체 제공.
Chrome 브라우저와 node.js는 둘 다 V8 엔진을 쓰지만 런타임은 다르다. Chrome은 window, DOM 객체 등을 쓰고, Node에선 buffer, require, processes 등을 쓴다.
브라우저에서 개발자 도구를 켜고 require를 입력해보면 찾을 수 없는 반면, Node.js를 설치한 vscode에서 require를 쓰면 해당 API를 찾을 수 있다.
이제 JIT 컴파일이 어떻게 이뤄지는지 순서대로 살펴보겠다. 참고로 3, 4, 6번은 Ignition이라는 인터프리터 안에서 일어난다. (JIT 컴파일을 하기 때문에 Ignition을 컴파일러라고 표현할 때도 있다.)
3. Lexical Analysis
렉싱(Lexing), 혹은 스캐닝(scanning)이라고도 부른다. 그리고 이 단계를 담당하는 곳을 어휘 분석기(Lexical Analyzer), 스캐너(Scanner), 렉서(Lexer), 토크나이저(Tokenizer)라고 부르기도 한다.
다운받은 소스 코드는 긴 문자열 스트림으로서 렉서에게 전달되고, 차례대로 스캔해서 문법적으로 유의미한 최소 단위(토큰)들로 쪼개어 분석한다.
예시.
const a = b / 10 + "a";C같은 언어는 아래와 같이 렉싱한다.
| 일반 토큰 | 특수 토큰(예약어) |
|---|---|
| a (식별자) | const (지정어) |
| b (식별자) | = (연산자) |
| 10 (리터럴) | / (연산자) |
| "a" (리터럴) | + (연산자) |
JavaScript는 아래와 같이 렉싱한다.
| 일반 토큰 | 특수 토큰 |
|---|---|
| const (예약어) | |
| a (식별자) | |
| = (부호) | |
| b (식별자) | / (나누기 부호) |
| 10 (숫자 리터럴) | |
| + (부호) | |
| "a" (문자열 리터럴) |
- 특수 토큰은 나누기, 정규 표현식 리터럴// 등이 있는데 소수이고, 나머지는 일반 토큰이다.
- 예약어는 식별자로 못 쓴다. (변수명으로 사용 불가능)
- 지정어(keyword)는 그 언어체계에서 특별한 의미를 가진 단어다. (if, while 등은 지정어 & 예약어다. 지정어 전부가 예약어는 아니다.)
- 예약어는 아주 특별한 경우에는 식별자로 사용할 수도 있다. await는 async 함수 내에서만 예약어다. async 함수 밖에서는 변수명으로 아무런 문제 없이 사용할 수 있다.
- 의외로 let은 예약어가 아니다.
- 예약어는 아니지만 strict 모드에서는 식별자로 못 쓰는 말 : let, static, implements, interface, package, private, protected, public
- implements, private 같은 몇몇 단어는 future reserved words(예약 예정어)다.

ECMA-262 12판(2021년)에 등록된 예약어 리스트. var와 const는 있어도 let은 없다.
let let = 123;
const let = 123;
// 'let' is not allowed to be used as a name in 'let' or 'const' declarations.그래서 let만큼은 저런 이유로 차단한다.
“let은 let, const의 선언명으로 쓸 수 없습니다.”
그 말은? var는 let을 변수명으로 쓸 수 있다.
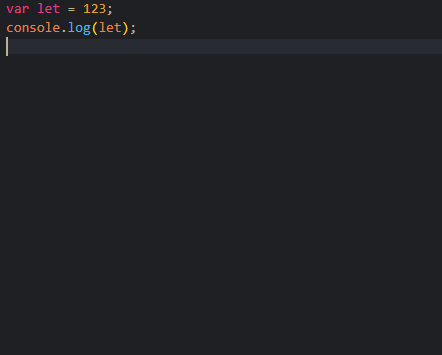
아무런 문제가 발생하지 않는다.
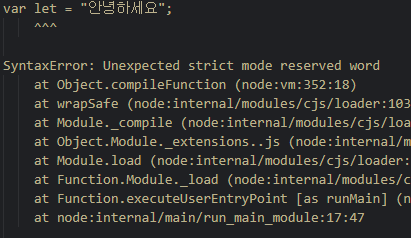
그러나 문서에 쓰인대로 use strict 모드를 쓰면 차단된다.
어휘 분석을 통해 생성된 토큰은 고유 번호와 고유 값을 가지며 구문 분석할 파서에게 (토큰 번호, 토큰 값) 순서쌍을 전달한다. 이 때 index값을 가지고 전달된다. (파싱 과정에서 빠르게 찾고 처리하기 위해서다.)
3-1. Lexical Scope
lexing은 식별자의 유효성, 접근성을 판단하는 과정이고, 그 판단을 위해 lexical scope를 정의한다.
lexical scope란?
식별자가 선언된 곳을 기준으로 정의한, 식별자를 참조할 수 있는 유효 범위를 말한다. 정적 영역(static scope)라고도 부르는데, 호출한 곳을 기준으로 스코프를 정의하는 동적 영역(dynamic scope)과 대비된다.
동적 영역을 사용하는 언어는 몇 없고, 우리가 아는 대부분 현대 언어들은 정적 영역을 사용한다.
for(let i = 0; i < 5; i++){
const num = i + 1;
console.log(num);
}위 코드에서 i와 num은 for문에서만 사용하기 때문에 for문이 끝난 바깥에서는 사용할 수 없다.
num과 i의 스코프는 for문 블록이다.
참고로 let과 const는 어휘적 선언(lexicallyDeclarations)문으로서 var와 별도로 처리된다. (var는 함수 단위 스코프이고 let, const는 블록 단위 스코프다.)
4. Syntax Analysis
파싱(parsing)이라고도 부른다. lexing에서 만든 토큰을 처리하며, 이 때 문법 에러(SyntaxError)가 있으면 에러 메시지를 출력한다.
입력들이 올바르면 구문 구조(syntatic structure)를 만드는데, 모든 구문 검사가 정상처리되면 구분자(";", "," 등), 지정어(const, while, if 등)을 제거하고 필요한 정보만 담아서 트리로 만든다.
이런 트리를 AST(abstract syntax tree, 추상 구문 트리), 혹은 의미 트리(semantic tree)라고 부른다. 옛날에는 CST(구체적 구문 트리, Concrete Syntax Trees)를 사용했으나 점차 AST로 갈아탔다.
여담 1. AST는 고수준 언어와 기계어 사이인 중간 언어이다.
여담 2. TypeScript, ESLint, 프리티어, BABEL 등도 AST를 사용한다.
여담 3. ECMAScript 공식 스펙에는 Parse Tree라고만 표현한다. AST를 뜻한다.
예시
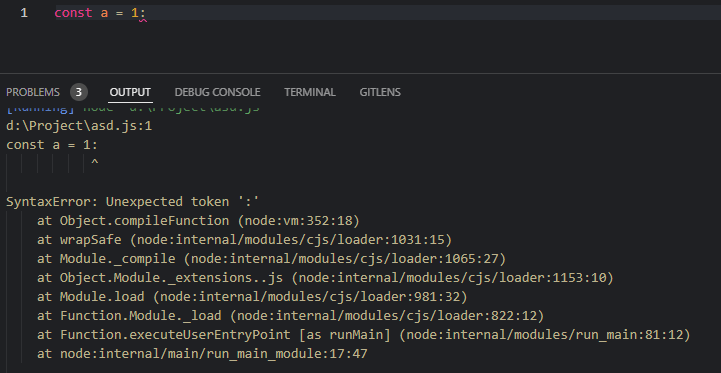
세미 콜론 말고 콜론을 적으니 SyntaxError: Unexpected token ' : '이 발생한다. 표준 토큰이 아니기 때문에 에러가 나는 것.
예시
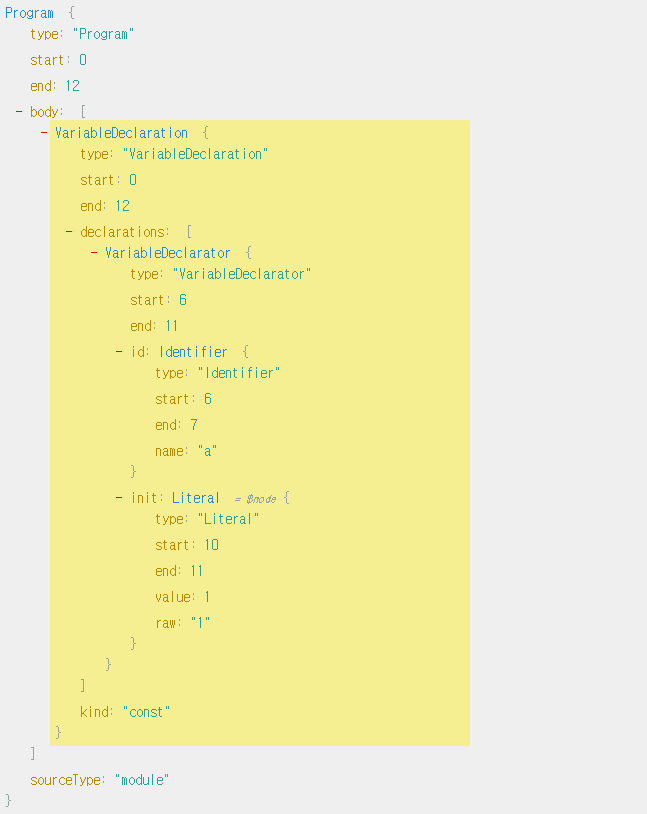
const a = 1;위의 코드는 아래와 같은 AST로 만들어진다.
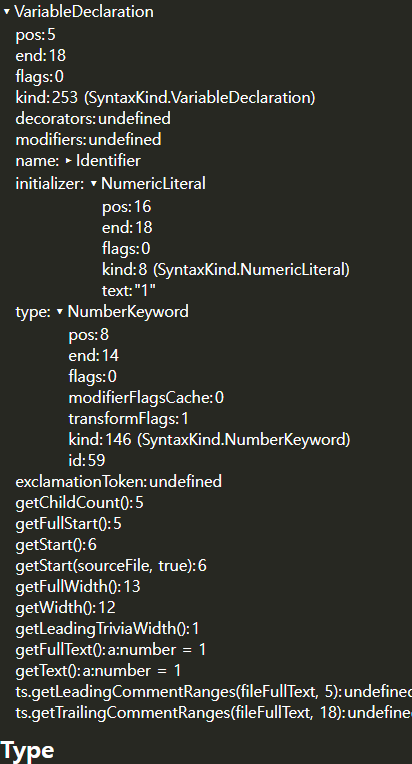
const a:number = 1;타입스크립트는 아래와 같은 AST가 만들어진다.
HTMLparser 문서에서도 파서, 토크나이저를 확인할 수 있다.
4-1. Execution Context
파싱을 마치면 AST를 기반으로 Execution Context를 생성한다. Execution Context에 대해서는 다른 글에서 다룬다.
5. Intermediate Code Generation(TypeScript)
※주의 : 이 과정은 JavaScript에선 발생하지 않는다.
AST를 받아서 또다른 중간 언어를 생성하고 의미 검사(semantic checking)을 실행한다. 이 때 중요한 작업 중 하나가 타입 체크(정적 타입 언어만 해당)이다. 예컨대 문자열을 할당하는 변수에 숫자를 할당하려고 하는지 등을 검사한다.
TypeError is used to indicate an unsuccessful operation when none of the other NativeError objects are an appropriate
indication of the failure cause.
When an ECMAScript implementation detects a runtime error, it throws a new instance of one of the NativeError objects defined in 20.5.5.
TypeError는 실패 원인으로 지목할 적절한 NativeError 객체가 없을 때 표시하는 편입니다.
런타임 에러가 발생하면 (20.5.5에 정의된) NativeError의 인스턴스로 에러를 처리합니다.
여담 1. 타입스크립트는 lexing->parsing->binding->checking->emit 순이다. parsing이 끝나면 binder가 AST를 받아서 심볼을 만든다. checker는 AST와 심볼을 가지고 의미 검사와 타입을 체크한다. emitter는 이를 JavaScript로 발행한다.
여담 2. 타입스크립트로 타입 체크하고, 자바스크립트로 트랜스컴파일하고, 자바스크립트를 또 컴파일하는 게 '빠른 속도 보장'이라곤 못한다. 2022년 3월에 MS는 JS 자체에서도 런타임 방해는 안 하고 타입 체크를 하는 제안서를 내놓았다.
여담 3. 타입스크립트는 정적 언어라 자체 컴파일 과정이 있지만, 타입스크립트로 만든 프로젝트도 결국 배포하고 나면 JavaScript로 변환이 된 상태이므로, 사용자 PC에선 JIT 컴파일이 이뤄진다.
6. Bytecode Generation
JavaScript는 보편적으로 말하는 중간 언어 생성 과정은 없지만, BytecodeGenerator 컴포넌트가 bytecode를 생성하는 과정이 있다. 여기서 말하는 bytecode란 기계어를 추상화한 것이다.
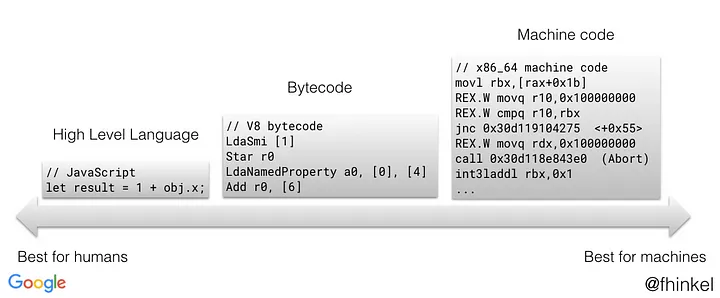
중간 언어 생성과 bytecode 생성은 좀 더 저수준 언어로 변환시킨단 점에서 흡사하지만 조금 다르다.
- 중간 언어 생성 : 코드 실행 전에 추가적인 후처리가 요구되며 오버헤드 방지 등의 목적이 있는 일반적, 개념적 용어
- 바이트 코드 생성 : JIT 컴파일 과정 중 하나. 추가적인 후처리라고 할만한 게 많진 않음.
Ignition은 점화라는 뜻이다. 왜 점화일까?
'처음 보는 코드에만 작동'하기 때문인데, 이미 본 적 있는 코드는 Ignition이 parsing 등을 하진 않고 Turbofan이 최적화해둔 bytecode만 가져와서 실행한다.
캐시해둔 코드인지 여부는 Ignition이 검색하고, 캐시한 코드를 사용할지의 판단은 CPU와 캐시 메모리에서 한다.
6-1. Closure
이 과정은 코드의 구조, 스코프를 파악해서 bytecode로 변환하는 과정이다. 이 때, Ignition의 BytecodeGenerator 컴포넌트는 함수에 레지스터를 할당하는데, 여기엔 context object가 포함돼있다. context object는 그 함수의 상태, 함수가 접근할 수 있는 외부 변수, 스코프 정보 등을 가지고 있다.
다시 말해서, bytecode generation 단계에서 closure가 정의된다.
처음 보는 코드만 closure가 생성되고, 재사용 코드가 기존의 closure를 사용하는 이유가 여기에 있다. Ignition은 처음 보는 코드일 때 bytecode generation을 수행하며 closure를 생성하고, 이미 봤던 코드는 bytecode cache에서 찾아서 쓰기 때문에 closure의 특징이 구현된다.
7. Compile
Ignition에서 lexing, parsing, bytecode generation이 끝나면 컴파일러들이 나머지 작업, 즉 bytecode를 machine code로 변환한다. 변환된 코드는 사용자의 CPU 및 환경에 최적화돼있다. V8에서 쓰는 컴파일러는 두 가지가 있다.
Turbofan: 최적화를 하느라 느린 컴파일러.
Sparkplug: 최적화를 안 해서 빠른 컴파일러.
도입부에서 얘기했듯이, 여러 번 실행할 코드는 최적화가 필요하다. 하지만 한 번만 실행하고 폐기할 코드라면? 그런 경우에는 최적화를 안 하는 컴파일러가 필요하다. 그래서 등장한 비최적화 컴파일러가 Sparkplug다.
코드의 양, 코드가 hot한지 cold한지 여부, 사용 가능한 자원의 양, 코드의 복잡성 등 여러 조건에 따라 Sparkplug가 컴파일할지, Turbofan이 컴파일할지 결정된다.
이는 Runtime에 동적으로 결정되는데, 똑같은 코드라 할지라도 사용자마다 환경이 다르기 때문에 어떤 PC에선 Sparkplug로 컴파일할 수도 있고 또다른 PC에선 Turbofan이 컴파일할 수 있다.
사용자 환경마다 다르다는 얘기이며, 똑같은 환경에서 이랬다가 저랬다가 랜덤하게 컴파일하진 않는다는 점에 유념하자.
Hot code? Cold code?
코드가 hot하다: 자주 쓰이는 따끈한 코드.
코드가 cold하다: 하도 안 써서 다 식은 코드.
당장엔 최적화가 필요 없는 코드처럼 보였는데 나중에 최적화가 필요해지면 어떡할까? 그럴 경우엔 Sparkplug가 추가적으로 Turbofan에게 최적화 작업을 맡기기 때문에 사용자는 그 점을 걱정하지 않아도 된다.
7-1. 메인 스레드와 백그라운드 스레드
여기서 말하는 메인 스레드란 Ignition이 작업하는 스레드를 말하며, 백그라운드 스레드는 Turbofan이 작업하는 스레드를 말한다.
옛날에는 메인 스레드만 컴파일을 했다. 그래서 UI가 차단되고 페이지 응답이 없던 때가 많았다. 요즘에는 백그라운드 스레드에서 컴파일을 많이 하고 있다. 다시 말해서, 메인 스레드와 백그라운드 스레드 둘 다 컴파일을 한단 얘기다.
top-level code, 즉시 실행 함수(IIFE)는 이 때 백그라운드 스레드에서 컴파일하며, 그 외 함수들은 메인 스레드에서 맡는다. 또한 백그라운드 스레드는 최적화에 집중한다. (이는 V8 특정 버전 기준이며, 모든 JavaScript 엔진이 그렇다는 뜻은 아니다.)
결국 중요한 건 메인 스레드이기 때문에, 백그라운드 스레드는 메인 스레드가 효율적으로 동작하도록 그때그때 상황에 맞춰서 다르게 작업한다. 무조건적으로 어떤 건 백그라운드 스레드가 담당, 어떤 건 메인 스레드만 담당하진 않는다.
top-level code?
최상위 수준, 즉 전역 코드를 말한다. 함수처럼 특정 이벤트가 발생해야만 실행되는 코드는 해당 사항이 없다.
여담.
먼 옛날에는 Full Code Generator + Crankshaft 구조를 사용했다. -> 2017년 Ignition+ Turbofan으로 변경 -> 2021년 Ignition+ Sparkplug+ Turbofan으로 변경.
크롬은 41 버전부터 V8의 StreamedSource API로 백그라운드 스레드의 js 파싱을 지원했습니다.
이를 통해 V8은 크롬이 네트워크에서 파일의 첫 번째 청크를 다운로드하는 순간부터 js 코드 파싱을 시작하고, 크롬이 스트리밍하는 동안에도 병렬적으로 파싱할 수 있었죠.
덕분에 파일 다운로드가 끝날 쯤에는 파싱도 거의 동시에 끝나서 로딩 시간을 단축했습니다.
...
하지만 V8의 베이스라인 컴파일러의 한계로 인해, V8은 여전히 메인 스레드로 돌아가서 파싱을 마무리하고 스크립트를 JIT 머신 코드로 컴파일해서 실행할 필요가 있었습니다.
이번에 우리는 Ignition + TurboFan 파이프라인으로 전환하면서 바이트 코드 컴파일을 백그라운드 스레드에게 넘겨줄 수 있게 되었고, 덕분에 메인 스레드는 더 부드럽고 응답성이 좋은 브라우징 환경을 제공하게 됐습니다.
스트리밍? 청크?
청크는 데이터 조각이다. 스트림(Stream)은 자료를 작은 청크들의 흐름으로 가공해서 보내는 것이다.
만약 파일 용량이 현재 사용 가능한 메모리보다 크다면 조율할 필요가 있습니다. 스트림이 그걸 합니다. 유튜브, 넷플릭스는 대용량 동영상을 다운로드 시키지 않습니다. 청크 흐름을 계속 받으면서 실시간으로 영상을 시청하죠.
스트림은 대용량, 미디어 처리에 유용할 뿐 아니라, 코드의 '조합성'에도 강력한 힘을 줍니다. 여러 코드의 조합으로 결과를 만들 수 있습니다. 또한 스트림은 메모리와 시간을 효율화합니다.
Node.js에서는 4가지 종류의 스트림이 있습니다. 쓰기 스트림, 읽기 스트림, 복합(읽기쓰기 가능한) 스트림, 변형 스트림(자료를 읽기, 쓰기용으로 변환).
우리는 인터프리터 최적화의 한계에 부딪혔습니다.
V8의 인터프리터는 최적화가 매우 잘 되어있고, 아주 빠릅니다.
하지만 인터프리터는 우리가 해결할 수 없는 고유한 오버헤드를 발생시킵니다. 예를 들면 바이트코드 디코딩 오버헤드나 디스패치 오버헤드는 인터프리터 기능의 본질적인 부분이기 때문이죠.
...
현재의 2-컴파일러 모델로는 더 빠른 최적화를 계층화할 수 없습니다.
최적화 속도를 올리도록 할 수는 있지만, 최고 퍼포먼스를 깎고 최적화 경로를 제거해야 속도를 올릴 수 있는 상황입니다.
...
스파크플러그 도입 : 이그니션 인터프리터와 터보팬 최적화 컴파일러 사이에 넣은, V8 9.1버전부터 도입된 비최적화 JS 컴파일러
...
스파크플러그는 컴파일을 빨리 하도록 디자인됐습니다. 엄청 빨리요. 너무 빠른 나머지 우리가 원하면 언제든 컴파일할 수 있기 때문에 터보팬 코드보다 더 적극적으로 코드를 계층화할 수 있습니다.
크롬은 2021년에 메모리 관련 이슈를 개선했다고 발표했다. 하지만 여전히 프로세스와 메모리를 많이 잡아먹고 싫어하는 사람이 많다.
8. Execution
최종적으로 우리 컴퓨터의 CPU가 기계어를 받아서 실행한다. 한 가지 사실을 환기하자면, 웹 페이지가 화면에 띄워지는 과정을 돌아보자. HTML 파일을 읽어들이다가 script 문을 만나면 JS를 다운로드받고, 실행한다. 옵션으로 async나 defer도 있겠지만, 아무튼 다운로드를 다 받아야 실행을 한다.
V8은 JS 다운로드를 시작하자마자 lexing, parsing, bytecode generation, 최적화 등의 과정을 계속 수행한다. (단, compile은 제외.) 다운로드를 받고나서 분석 -> 실행하지 않고, 다운로드를 받으면서 분석하고, 다운로드가 끝나면 bytecode -> machine code로 컴파일하고 바로 실행한다.
8-1. Call Stack, Execution Context
JavaScript를 실행하면 Call Stack에 Execution Context를 push한다. 그리고 코드를 실행하면 pop한다. 흔히 말하는 Call Stack이 작업을 처리한다는 말은 비유적인 표현인데, 실제로는 기계어로 번역된 코드를 CPU가 실행한다.
Call Stack은 CPU가 어떻게 작업을 처리했고, 어떻게 처리할지 코드를 추적하고 기록하는 역할이고, CPU는 코드를 실행하면서 Call Stack의 기록을 참조한다. 기록용 코드와 실제 실행용 코드가 다르단 점만 알아두자.
A라는 작업 이후에 B라는 작업을 수행하는 상황을 가정해보겠다.
CPU가 A의 기계어 코드를 작업할 때 Call Stack은 A,B의 AST를 push한다. CPU가 A 작업을 마치면 그때 Call Stack은 A를 pop한다. 정리하자면, Call Stack은 Execution Context를 활용해서 코드 추적을 하고 디버깅, 에러 처리 등 효율적인 관리를 목적으로 한다. '직접적 코드 실행 자체' 하고는 연관이 없다.
9. 마무리
내용이 깊고 방대하기 때문에 조사를 하는 동안 이해하기 어려운 개념이 많았다. 그래도 JavaScript를 조금은 더 알게 된 기분이 든다.
10. 참조
- 사진 출처
- V8 wikipedia
- V8 Blog
- V8 Runtime Overview
- 네이버 웨일의 크롬 컴파일 분석 및 웨일 개선
- Abstract Syntax Tree (AST) wikipedia
- JavaScript AST Explorer
- fkling/astexplorer
- TypeScript AST Viewer
- How js run on browser
- How the JIT compiler optimizes code
- What is the difference between JavaScript Engine and JavaScript Runtime Environment
- Writing a JavaScript Interpreter – A Detailed Interpretation of AST and Its Application
- ECMA-262, 12th edition
- TypeScript Compiler Internals
- TypeScript compiler GitHub
- Native code
- Attack surface wikipedia
- PyPy wikipedia
- Differences between JDK, JRE and JVM
- Scope - MDN Web Docs Glossary
- Scope (computer science)
- Understanding Streams in Node.js
- A Proposal For Type Syntax in JavaScript
- 자바스크립트 개발자를 위한 AST(번역)
- Understanding execution context and scope promotion from JavaScript code parsing process
- 자바스크립트는 어떻게 작동하는가: V8 엔진의 내부 + 최적화된 코드를 작성을 위한 다섯 가지 팁
- 컴파일러 입문 - 오세만 저
