💡 JDBC
-
Java Database Connectivity
-
Java에서 제공하는 표준 API (Oracle, mysql, H2 와 같은 라이브러리)
-
Java 기반 애플리케이션
🔅 특징
-
JPA의 방대한 기능을 덜어낸 라이트한 기술
-
DDD 설계 원칙을 따른다.

🔅 사용 흐름
-
-
Entity 클래스 -> 변수에 집어넣고 -> Repository에 넘겨주면 -> 데이터베이스에 들어감 -> 내부적으로 쿼리문 생성 (ORM) -> JDBC
- JDBC 드라이버 로딩 : 사용하고자 하는 JDBC 드라이버를 로딩, DriverManager라는 클래스를 통해서 로딩
- Connection 객체 생성 : DriverManager를 통해 데이터베이스와 연결되는 세션(Session)인 Connection 객체를 생성
- Statement 객체 생성 : Statement 객체는 작성된 SQL 쿼리문을 실행하기 위한 객체, 객체 생성 후에 정적인 SQL 쿼리 문자열을 입력으로 가진다.
- Query 실행 : 생성된 Statement 객체를 이용해서 입력한 SQL 쿼리를 실행
- ResultSet 객체로부터 데이터 조회 (SQL 쿼리문에 대한 결과 데이터 셋)
- ResultSet 객체, Statement 객체, Connection 객체 역순으로 Close
🔅 Connection Pool
-
DB Connection을 미리 만들어서 보관하고, 필요시 제공하는 역할을 하는 관리자
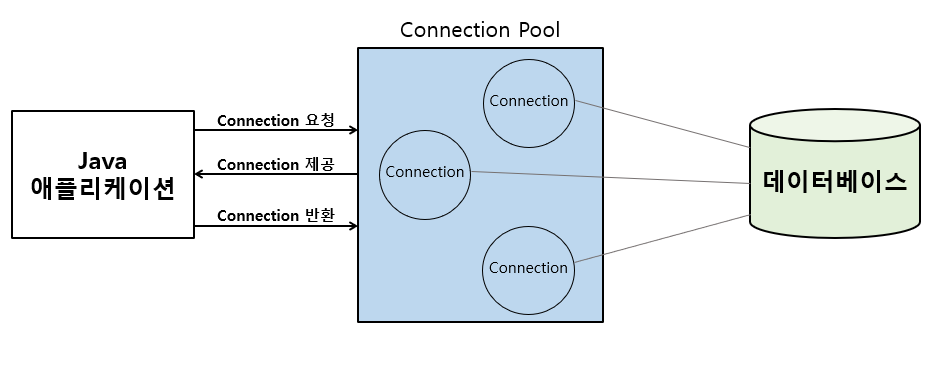
-
필요성 : 기본적으로 Connection 객체를 생성하는 작업은 비용이 많이 드는 작업이기에, 개선이 필요
-
애플리케이션 로딩 시점에 Connection 객체를 미리 생성해두고, DB 연결이 필요시, 미리 만들어 둔 Connection 객체를 사용하여 성능을 향상
-
Spring Boot 2.0 부터는 JDBC API의 필요성 성능면에서 더 나은 이점을 가지고 있는 HikariCP를 기본 DBCP(Database Connection Pool)로 채택
💡 Spring Data JDBC
-
데이터베이스 연동 기술 중 ORM (객체 중심 데이터 액세스 기술) 이용
-
JPA에 비해 기술적 복잡도가 낮다.
- Spring Data JDBC
- JPA
- Spring Data JPA
: 모두 다 배워야 한다.
💡 H2 설정
-
의존 라이브러리 추가 및 H2 설정
dependencies {
...
...
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
runtimeOnly 'com.h2database:h2' // In-memory DB
}⭐️ In-memory DB
- 이름 그대로 메모리 안에 데이터를 저장하는 데이터베이스
- 애플리케이션이 종료되면 사라지는 메모리 데이터베이스 —> H2 많이 사용 (다른 것도 있긴 하다.)
- 개발 및 로컬 테스트 용도로 사용
- PRIMARY KEY에 AUTO_INCREMENT 붙여주면 데이터가 insert될 때마다 자동 증가 --> 데이터를 insert할 때 'message_id' 열에 해당하는 값을 지정해주지 않아야 한다는 의미이다.
ORM에서는 객체의 멤버 변수와 데이터베이스 테이블의 열이 대부분 1대1로 매핑된다.
⭐️ Spring Data JDBC 적용 순서
- build.gradle에 사용할 데이터베이스를 위한 의존 라이브러리 추가한다.
- application.yml 파일에 사용할 데이터베이스에 대한 설정을 한다.
- 'schema.sql'파일에 필요한 테이블 스크립트를 작성한다.
- application.yml파일에서 'schema.sql'파일을 읽어서 테이블을 생성할 수 있도록 초기화 설정을 추가한다.
- 데이터베이스의 테이블과 매핑할 엔티티클래스를 작성한다.
- 작성한 엔티티 클래스를 기반으로 데이터베이스의 작업을 처리할 Repository 인터페이스를 작성한다.
- 작성된 Respository 인터페이스를 서비스 클래스에서 사용할 수 있도록 DI한다.
- DI된 Repository의 메서드를 사용해서 서비스 클래스에서 데이터베이스에 CRUD작업을 수행한다.
⭐️ 핵심 결론
- 데이터 액세스 기술의 유형에는 (1) SQL 중심의 기술과 (2) 객체 중심의 기술로 나뉜다.
- SQL 중심 기술: mybatis, Spring JDBC
- 객체 중심 기술: JPA, Spring Data JDBC
- 인메모리(In-memory) DB는 애플리케이션이 실행된 상태에서만 데이터를 저장하고 애플리케이션 실행이 중지되면 함께 실행이 중지되어 저장된 데이터가 사라진다.
- Spring에서 지원하는 CrudRepository 인터페이스는 CRUD에 대한 기본적인 메서드를 정의하고 있기 때문에 별도의 CRUD 기능을 개발자가 직접 구현할 필요 없다.
- application.properties 또는 application.yml 파일의 설정 정보 등록을 통해 데이터베이스 설정, 데이터베이스의 초기화 설정 등의 다양한 설정을 할 수 있다.
- application.yml 방식은 중복되는 프로퍼티의 입력을 줄여주기 때문에 application.properties 방식보다 더 선호되는 추세이다.
- 엔티티 클래스 이름은 데이터베이스 테이블의 이름에 매핑된다.
- 엔티티 클래스 각각의 멤버 변수는 데이터베이스 테이블의 열에 매핑된다.
- 엔티티 클래스의 멤버 변수에 @Id 애너테이션을 추가하면 데이터베이스 테이블의 기본키(Primary key)열과 매핑된다.

나만의 언어로 기록하며 성장하기 !