
3주차에는 파이썬 배우기 시작
[수업 목표]
- 파이썬 기초 문법을 안다.
- 원하는 페이지를 크롤링 할 수 있다.
- pymongo를 통해 mongoDB를 제어할 수 있다.
# 언제나 시작은 hello world
print('hello world!')hello world!
자료형
a = 1 # 숫자
b = '가' # 문자열
c = True # bool
d = False # bool
e = [] # 리스트
f = {} # 딕셔너리
g = {'키': [1, 2, 3]}
h = [{'키': '값;}]
i = () # 튜플(tuple)
튜플은 순서가 있는 불변형 자료형
j = set() # 집합자료형
교집합, 합집합, 차집합을 구할 수 있어요
aaa = ['사과', '감', '수박', '참외', '딸기']
bbb = ['사과', '멜론', '청포도', '토마토', '참외']
aa_set = set(aaa)
bb_set = set(bbb)
print(aa_set & bb_set) # 교집합, {'참외', '사과'}
print(aa_set | bb_set) # 합집합, {'감', '수박', '청포도', '딸기', '사과', '멜론', '참외', '토마토'}
student_a = ['물리2', '국어', '수학1', '음악', '화학1', '화학2', '체육']
student_b = ['물리1', '수학1', '미술', '화학2', '체육']
set_a = set(student_a)
set_b = set(student_b)
print(set_a - set_b) # 차집합, {'물리2', '국어', '음악', '화학1'}
변수
a = 2
b = '하이'
print(a+b)
// TypeError: unsupported operand type(s) for +: 'int' and 'str'
// 자바스크립트에서는 '2하이' 라고 나옴
// '2하이'이라는 값을 원한다면 숫자 자료형을 문자열로 바꿔주기
a2 = str(2)
b2 = '하이'
print(a2+b2) # '2하이'
문자열 자르기
text = 'hello world'
print(len(text)) # 11
print(text[:]) # 'hello world'
print(text[0:2]) # 'he'
print(text[:7]) # 'hello w'
print(text[2:]) # 'llo world'
print(text[0:6:2]) # 'hlo' <---- 0부터 6전 까지 2개 간격으로 출력해줭
// [이상:미만:간격] 이라고 생각하면 된다
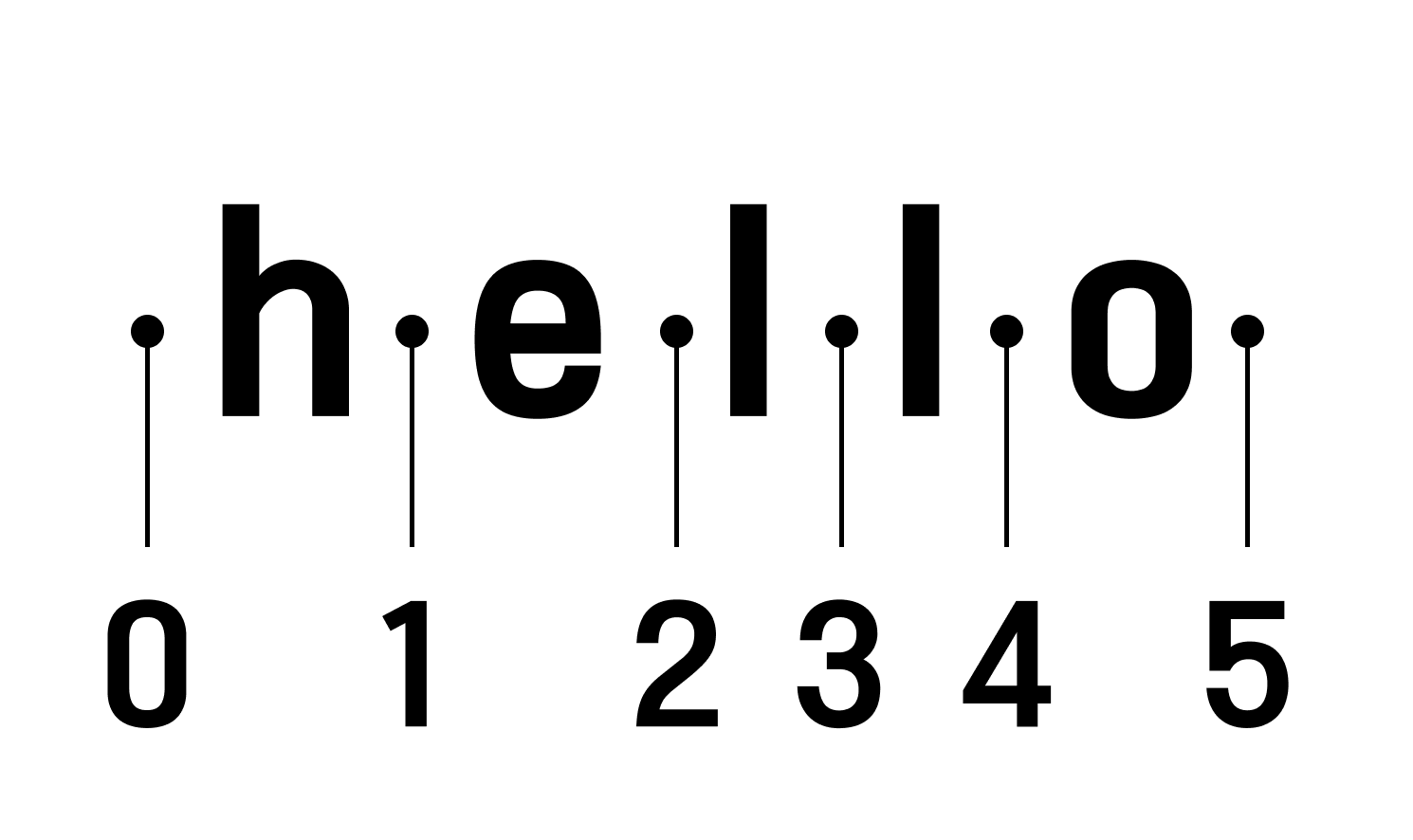
이미지대로 이해하면 쉽다
또 다른 방법으로는
print(text.split(' ')) # ['hello', 'world']
print(g[0]) # 'hello'
text2 = ' 공백자르기 '
h = text2.strip() # '공백자르기'
h1 = text2.lstrip() # '공백자르기 ' <---- 왼쪽공백이 사라짐
h2 = text2.rstrip() # ' 공백자르기'
split처럼 특정문자를 기준을 자를 수도 있다
text3 = '! 안녕하세요 ?'
print(text3.lstrip('!?')) # ' 안녕하세요 ?'
print(text3.rstrip('!?')) # '! 안녕하세요 '
print(text3.strip('!?')) # ' 안녕하세요 '
pip이랑 pypi
수업들으면서 라이브러리를 설치 하는데 궁금증이 생겼다
어떻게 버튼 하나로 쉽게 설치가 가능하지? 그 이유는 내가 파이썬을 설치할 때
pip이라는 소프트웨어도 설치 되기 때문이다
그렇다면 pip은 뭘까?
pip(python install package)
PyPI(Python Package Index)
pip은 pypi라는 파이썬 패키지들을 모아 놓는 저장소로부터 파이썬 패키지를 받아
설치하는 패키지 관리 툴이라고 한다
나는 requests, bs4, pymongo를 사용 했다
requests
import requests
r = requests.get('')
rjson = r.json()bs4
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################pymongo
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# 코딩 시작