[CS] 자료구조 & 알고리즘
1.해시(Hash)
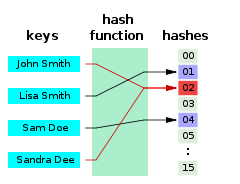
해시 함수에 의해 얻어지는 값데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터(해시 값)로 매핑하는 함수같은 입력값에 대해서 같은 출력값을 보장한다서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황데이터가 많아지면, 다른 데이터가
2.이진탐색트리 (Binary Search Tree)
이진탐색 : 탐색에 소요되는 시간복잡도는 O(logN), but 삽입,삭제가 불가능연결리스트 : 삽입, 삭제의 시간복잡도는 O(1), but 탐색하는 시간복잡도가 O(N)위 두가지를 합하여 장점을 모두 얻는 것즉, 효율적인 탐색 능력을 가지고, 자료의 삽입 삭제도 가능
3.Map & Set

데이터의 집합순서 X, 중복 X빠른 검색 속도를 가진다.인덱스가 따로 존재하지 않기에 iterator를 사용ex) ABBCCCDDD 입력이라도 ABCD만 남아있다!null 값 허용순서가 보장되지 않고, 중복된 값이 없는 자료구조add, remove, oontains와
4.힙 정렬 (Heap Sort)
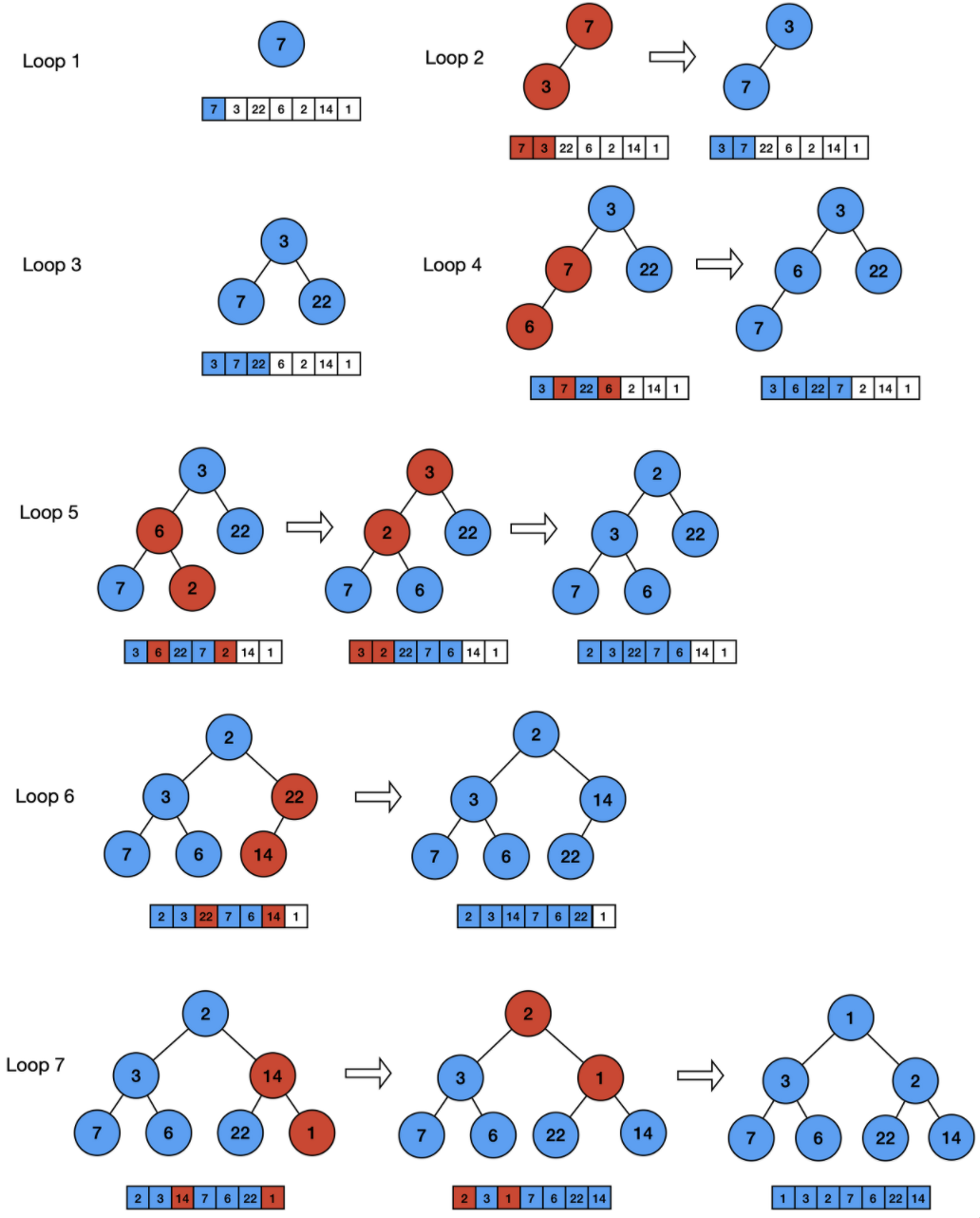
힙 정렬(Heap Sort)이란? 힙(Heap) 자료구조를 기반으로한 정렬 방식 내림차순 정렬을 하고 싶을 땐 최대 힙을, 오름차순 정렬을 하고 싶을 땐 최소 힙을 구성하면 된다. 과정 (최소 힙) 삽입 삭제 

낮은 자리수부터 비교하여 정렬하는 알고리즘ex) 200, 152, 2, 0, 32, 45, 99, 87 있다고 할 때,Queue이기 때문에 선입선출이다. 200, 0, 152, 2, 32, 45, 87, 99 로 정렬된다.십의 자리가 없는 것은 0으로 간주한다. 200