들어가기에 앞서
-
push_swap(1) 포스트에서 작성한 자료구조에 대해 공부하고 어떤 자료구조를 사용할지 결정
-
push_swap(2) 포스트에서 정렬 알고리즘 파악
퀵소트를 활용하여 해당 프로젝트를 완성하였으나, 최악의 경우 요구하는 제한된 명령어 수에 맞추지 못해 그리디 알고리즘으로 변경했습니다.
프로젝트에서 요구하는 내용이 제한된 명령어 개수 안에 정렬을 완성시키는 것이어서 현재 상황에서 지금 당장 좋은 것만 고르는 방법을 의미하는 그리디 알고리즘(탐욕법)을 활용하면 최적화된 값을 얻을 수 있습니다.
그러나 해당 프로젝트가 요구하는 것이 자료구조와 정렬 알고리즘에 대해 공부하길 의도하는 것 같으니 이전 포스트 push_swap(2)를 통해 퀵소트와 머지소트에 대해 공부하는 걸 추천드립니다.
🖥️ Mandatory
int main(int argc, char *argv[])
{
t_stack *a;
t_stack *b;
if (argc < 2)
return (0);
a = stack_init();
b = stack_init(); // 덱 a와 b 생성
insert_check(argc, argv); // 들어오는 인자의 유효성 체크
trance_string(argc, argv, a); // 숫자가 문자열로 이루어져 있을때 변환
samesame(a); // 동일한 값이 들어왔는지 확인
atob(a, b); // a에서 b로 적당한 필터를 거쳐 보내줍니다.
clear(a);
clear(b); // 메모리해제
}void atob(t_stack *a, t_stack *b)
{
sortcheck(a); // a가 정렬되어있는지 확인
if (a->size >= 100)
division(a, b);
else if (a->size < 100 && a->size > 10)
division3(a, b); // 전처리 과정을 통해 a에서 b로 보내줍니다.
while (a->size > 3)
pb(a, b); // 숫자 3개 이하는 적은 명령어로 하드코딩이 가능하니 a에 3개만 남기고 b로 마저 보내줍니다.
hardcoding(a); // a의 값들을 하드코딩해서 정렬해줍니다.
while (b->size)
btoa(a, b); // 중요! 그리디 알고리즘을 통해 최적의 값을 b에서 a로 정렬시켜 보내줍니다.
finish(a);
return ;
}큰 동작 방식을 설명하자면,
-
자료구조
덱a와 b를 생성합니다. -
인자에 제대로 된 값이 들어오는지 확인 및 유효한 값으로 변환합니다.
-
최소한의 명령어로 실행시키기 위해 전처리 과정 후 a에서 b로 보내줍니다.
-
b에서 숫자들을 비교하여 적은 명령어로 정렬할 수 있는 값을 골라(그리디 알고리즘) a로 보내줍니다.
-
4번 내용을 덱 b가 비워질 때 까지 계속 반복합니다.
최적화를 위해 전처리 과정을 a의 사이즈 100을 기준으로 2가지 방법으로 나눴습니다.
int pibot(t_stack *list, int num)
{
int *arr;
int pi[4];
int i;
t_node *now;
arr = (int *)malloc(sizeof(int) * list->size);
i = 0;
now = list->top;
while (i < list->size)
{
arr[i] = now->data;
now = now->prev;
i++;
}
quick(0, i - 1, arr);
pi[0] = (arr[(i - 1) / 5]);
pi[1] = (arr[(((i - 1) / 5) * 2)]);
pi[2] = (arr[(((i - 1) / 5) * 3)]);
pi[3] = (arr[(((i - 1) / 5) * 4)]);
free(arr);
return (pi[num]);
}
void division2(t_stack *a, t_stack *b, int p3, int p0)
{
int asize;
asize = a->size;
while (asize--)
{
if (a->top->data > p3)
ra(a);
else
{
pb(a, b);
if (b->top->data <= p0)
rb(b);
}
}
}
void division(t_stack *a, t_stack *b)
{
int p[4];
int asize;
p[0] = pibot(a, 0);
p[1] = pibot(a, 1);
p[2] = pibot(a, 2);
p[3] = pibot(a, 3);
asize = a->size;
while (asize--)
{
if (a->top->data > p[2] || a->top->data <= p[0])
ra(a);
else if (a->top->data <= p[2] && a->top->data > p[0])
{
pb(a, b);
if (b->top->data < p[1])
rb(b);
}
}
division2(a, b, p[3], p[0]);
}덱 a 안에 있는 요소들을 퀵정렬(quick sort)를 통해 정렬하여 적당한 값 4개를 골라 피봇으로 삼아 a를 5등분 시킵니다.
선 정렬 후 피봇을 찾는 전처리는 안 해도 동작은 합니다. 그러나 최적의 값을 찾는데 더 많은 명령어로 찾게 되니 최적화를 위한 과정입니다.
5등분 시켜 b로 값들을 보냈다면, b에서 a로 최적의 값을 찾는 그리디 알고리즘을 실행시킵니다.
void btoa(t_stack *a, t_stack *b)
{
int ra_c;
int rb_c;
ra_c = 0;
rb_c = 0;
count(a, b, &ra_c, &rb_c); // 최적의 값을 ra_c, rb_c에 넣어줍니다.
rrrab(a, b, &ra_c, &rb_c);
rrra(a, &ra_c);
rrrb(b, &rb_c); // 최적의 값을 각 스택 맨 위로 옮겨줍니다.
pa(a, b);
}-
count를 통해 최적의 값이 몇 개의 명령어로 a로 보낼 수 있는지 값을 구합니다.
-
rrrab를 통해 rr 명령어와 rrr 명령어를 알맞게 사용하여 a와 b를 동시에 최적 위치로 만들어줍니다.
-
rrra와 rrrb를 통해 rrrab로는 부족했던 a의 들어갈 자리를 맨 위로, 최적의 값을 b의 맨 위로 위치시켜줍니다.
-
pa로 최적의 값을 보내줍니다.
위 방식을 b->size가 0이 될 때까지 진행해 주면 됩니다.
void count(t_stack *a, t_stack *b, int *ra_c, int *rb_c)
{
int b_index;
int new_ra_c;
int new_rb_c;
t_node *now;
now = b->top;
b_index = 0;
while (b_index < b->size) // b 전체를 탐색합니다.
{
new_ra_c = count_ra(a, now->data); // 현재 b인덱스가 a로 들어가기 위한 ra의 개수를 구해줍니다.
if (b_index > (b->size) / 2)
new_rb_c = (b->size - b_index) * -1; // 최적화를 위해 절반보다 크면 rrb
else
new_rb_c = b_index; // 아니면 rb를 진행하여 해당 인덱스를 b의 맨 위로 옮겨주는 명령어 개수를 구해줍니다.
if (b_index == 0 || best(*ra_c, *rb_c, new_ra_c, new_rb_c)) // 기존의 명령어 개수와 새로 구한 명령어 개수를 비교합니다
{
*ra_c = new_ra_c;
*rb_c = new_rb_c; // 비교했을 시 기존보다 현재 명령어가 더 최적의 개수라면 변경해줍니다.
}
now = now->prev;
b_index++;
}
}현재 b의 요소가 rb 또는 rrb를 몇 번 해야 b의 맨 위에 위치하는지,
b가 들어갈 자리는 ra 또는 rra를 몇 번 해야 a의 맨 위에 위치하는지,
이 방법으로 계산한 명령어 개수는 이전 값에 비해 더 적은 명령어인지 하나하나 비교해 줍니다.
int count_ra(t_stack *a, int data)
{
int min;
int max;
int a_index;
t_node *now;
a_index = 1;
now = a->top;
max = max0min1(a, 0);
min = max0min1(a, 1);
if (max < data || min > data) // b의 값이 max보다 크고 min보다 작으면 a의 최소값 인덱스를 리턴
return (maxormin(a, min));
if (a->top->data > data && a->bottom->data < data) // b의 값이 a의 맨 위에 올라갈 수 있는 조건
return (0);
while (1)
{
if (now->data < data && now->prev->data > data) // b의 값이 현재 위치 a값 보다 크고 다음값보다 작을때의 위치
{
if (a_index > (a->size) / 2)
return ((a->size - a_index) * -1); // a절반보다 크면 rra
return (a_index);
}
now = now->prev;
a_index++;
}
}ra의 개수를 계산하기 위해서는 어떤 상황일 때 b의 요소가 들어갈 수 있는지 생각하면 도움이 됩니다.
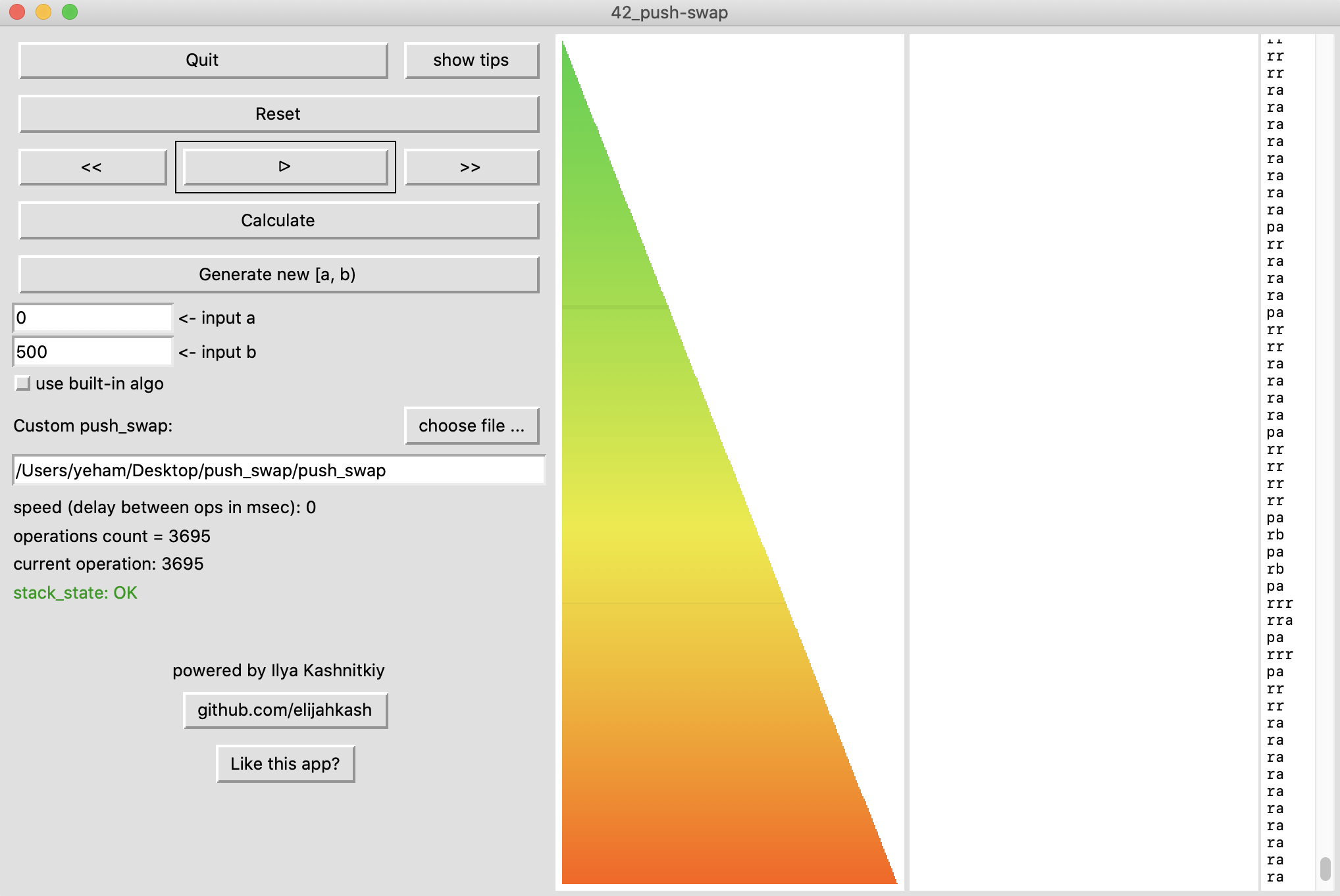
https://youtu.be/push_swap greedy 동작 영상 - yeham
제가 작성한 push_swap을 실행시킨 모습을 담은 영상입니다.
💻 Bonus
보너스 항목은 직접 push_swap의 checker 프로그램을 만드는 프로젝트입니다.
push_swap을 실행하면 sa, rb와 같은 명령어를 출력하는데, checker의 경우 해당 명령어를 인자로 넣었을 때 해당 명령어를 실행시킨 결과값이 정렬되어 있는지 확인하는 프로그램입니다.
void go_check(t_stack *a, t_stack *b)
{
char *order;
while (1)
{
order = get_next_line(0);
if (order == NULL)
break ;
output(a, b, order);
free(order);
}
}이전에 작성한 get_next_line을 이용하여 개행문자 ('\n')를 기준으로 들어오는 명령어를 확인합니다.
void output(t_stack *a, t_stack *b, char *s)
{
if (ft_strcmp(s, "sa") == 1)
c_sa(a);
else if (ft_strcmp(s, "sb") == 1)
c_sb(b);
else if (ft_strcmp(s, "ss") == 1)
c_ss(a, b);
else if (ft_strcmp(s, "pa") == 1)
c_pa(a, b);
else if (ft_strcmp(s, "pb") == 1)
c_pb(a, b);
else if (ft_strcmp(s, "ra") == 1)
c_ra(a);
else if (ft_strcmp(s, "rb") == 1)
c_rb(b);
else if (ft_strcmp(s, "rr") == 1)
c_rr(a, b);
else if (ft_strcmp(s, "rra") == 1)
c_rra(a);
else if (ft_strcmp(s, "rrb") == 1)
c_rrb(b);
else if (ft_strcmp(s, "rrr") == 1)
c_rrr(a, b);
else
error();
}들어온 값을 strcmp로 비교하여 해당 명령어의 동작을 실행시켜줍니다.
그리곤 정렬되어 있으면 OK를 아니면 KO를 출력해 주면 되는 프로그램입니다.
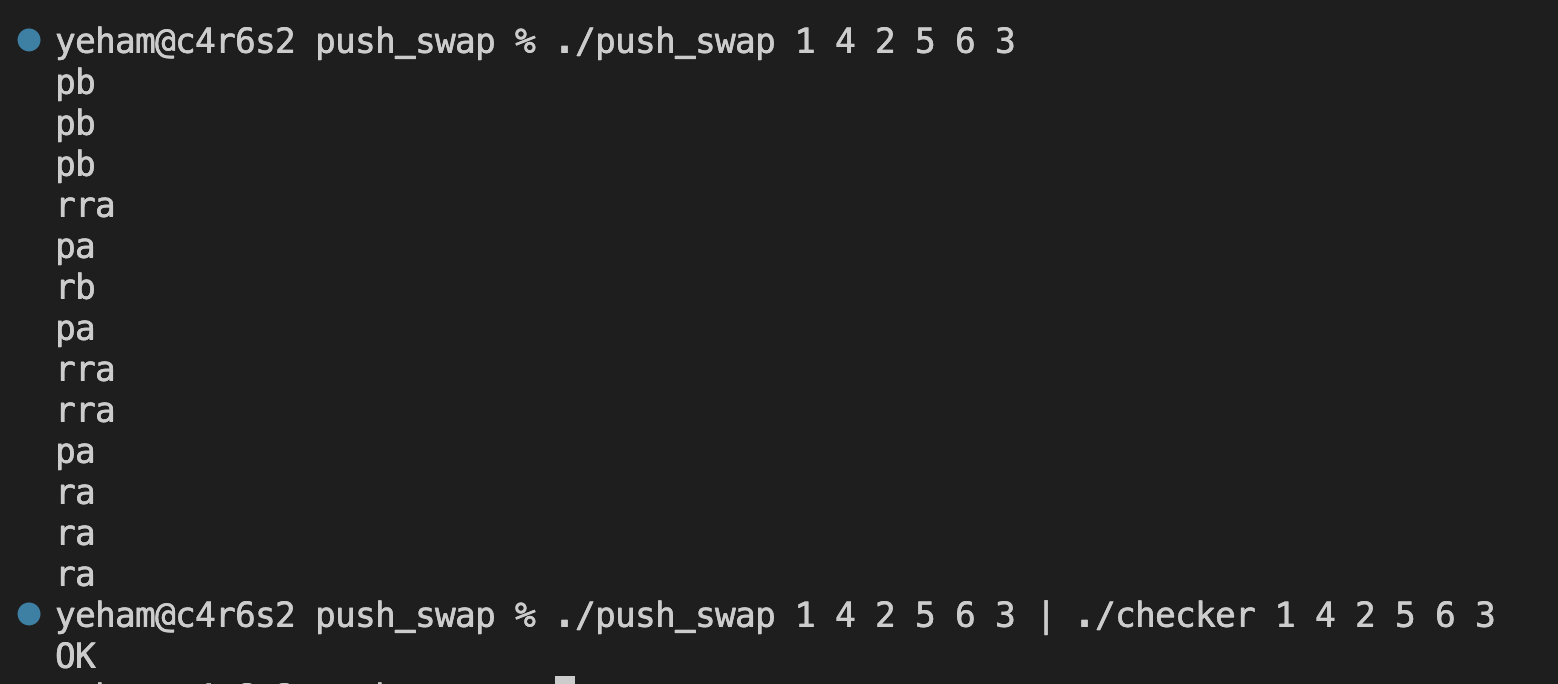
위 이미지와 같은 방법으로 활용할 수 있습니다.
✅ 배운점
큐, 스택, 덱과 같은 자료구조를 연결 리스트로 작성하면서 학부 시간 때 이론으로 배워온 자료구조를 하나하나 직접 짜보며 실력이 늘었고,
sa와 같은 명령어를 실행할 때 이전 노드를 참조해야 하는데, 사이즈의 개수가 1개 이하라면 없는 메모리 주소를 참조하여 segfalut가 발생할 수 있다는 메모리 참조 시 주의해야 할 사항을 알게 되었습니다.
또한 퀵정렬, 병합정렬 등 정렬 알고리즘과 그리디 알고리즘까지 이론으로만 알고 있던 것들을 프로그램을 만들기 위해 적용시키면서,
코딩 테스트를 위해서만 해왔던 알고리즘을 직접 프로그램에 적용시킬 수 있던 값진 경험이었습니다.
