
cmd로 다운로드 받은 sql을 실행해본다
- 다운로드 받은 spl있는 폴더 주소창에 cmd치고 엔터
- cmd창이 나오면 sqlplus입력 엔터
- 실행할 id와 비밀번호 입력
- @파일이름.sql → 입력후 엔터
cmd가 자동으로 sql안에 있는 명령어를 실행해준다
그룹함수
- count : 조건에 맞는 행의 갯수를 세준다.
select count (*)||'명' "인원"
from employee
where phone not like '010%';
--count 조건에 맞는 행의 갯수를 출력한다
--()안에는 칼럼명을 써도 되지만 *를 써도 된다
//출력값 3명conut(*) : 아랫줄 where에 있는 조건의 행의 갯수를 샌다
- sum : 칼럼의 합계를 계산한다
SELECT SUM(SALARY)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) = 1;Group by
- 별도의 그룹지정없이 사용한 그룹함수는 단 한개의 결과값만 산출하기때문에 그룹함수를 이용하여 여러개의 결과값을 산출하기 위해서는 그룹함수가 적용될 그룹의 기준을 gorup by절에 기술함
SELECT DEPT_CODE,
SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE- dept_code에 따라 모든 salary의 합을 알고 싶을때
- group by를 써서 dept_code가 기준임을 알려야 한다.
Having
SELECT DEPT_CODE,
FLOOR(AVG(SALARY)) 평균
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING FLOOR(AVG(SALARY)) > 3000000
ORDER BY 1;- 그룹함수로 값을 구해올 그룹에 대해 조건을 설정할 때는 HAVING절에 기술한다.
(WHERE절은 SELECT에 대한 조건)
ROLLUP
- 인자로 전달받은 그룹 중에 가장 먼저 지정한 그룹별 합계와 총 합계를 구한다.
SELECT DEPT_CODE,
JOB_CODE,
SUM(SALARY)
FROM EMPLOYEE
GROUP BY ROLLUP(DEPT_CODE, JOB_CODE)
ORDER BY 1;이경우 dept_code에 속한 job_code의 각각 salary의 총합이 나오지만
dept_code끼리의 총합도 나온다
| dept_code1 | job_code1 | dept_code1 + job_code1인 사람의 salary 합 |
|---|---|---|
| dept_code1 | job_code2 | dept_code1 + job_code2인 사람의 salary 합 |
| dept_code1 | dept_code1의 모든합 | |
| dept_code2 | job_code1 | dept_code2+ job_code1인 사람의 salary 합 |
CUBE
- 그룹으로 지정된 모든 그룹에 대한 합계와 총 합계를 구한다.
SELECT DEPT_CODE,
JOB_CODE,
SUM(SALARY)
FROM EMPLOYEE
GROUP BY CUBE(DEPT_CODE, JOB_CODE)
ORDER BY 1;이경우 dept_code에 속한 job_code의 각각 salary의 총합이 나오지만
dept_code끼리의 총합과 job_code의 총합도 출력된다.
| dept_code1 | job_code1 | dept_code1 + job_code1인 사람의 salary 합 |
|---|---|---|
| dept_code1 | job_code2 | dept_code1 + job_code2인 사람의 salary 합 |
| dept_code1 | dept_code1의 모든합 | |
| dept_code2 | job_code1 | dept_code2+ job_code1인 사람의 salary 합 |
| dept_code2 | job_code2 | dept_code2+ job_code2인 사람의 salary 합 |
| job_code1 | job_code1의 모든합 | |
| job_code2 | job_code2의 모든합 |
GROUPING
- ROLLUP이나 CUBE에 의한 집계 산출물이 인자로 전달받은 컬럼 집합의 산출물이면 0을 반환하고, 아니면 1을 반환하는 함수이다
select
DEPT_CODE,
JOB_CODE,
SUM(SALARY),
CASE WHEN GROUPING(DEPT_CODE) = 0 AND GROUPING(JOB_CODE) = 1 THEN '부서별합계'
WHEN GROUPING(DEPT_CODE) = 1 AND GROUPING(JOB_CODE) = 0 THEN '직급별합계'
WHEN GROUPING(DEPT_CODE) = 1 AND GROUPING(JOB_CODE) = 1 THEN '총합계'
ELSE '그룹별합계'
END AS "구분"
FROM EMPLOYEE
GROUP BY CUBE(DEPT_CODE, JOB_CODE)
ORDER BY 1;| 부서코드 | 직업코드 | 합계 | grouping | |
|---|---|---|---|---|
| 부서코드1 | 직업코드1 | 부서코드1이며 직업코드1인사람의 합계 | sum(salary)의 영역 | 부서0 직업0 |
| 부서코드1 | 직업코드2 | 부서코드1이며 직업코드2인사람의 합계 | sum(salary)의 영역 | |
| 부서코드1 | 부서코드1의 합계 | cube가 (직업코드1+2)를 계산한값 | 부서0 직업1 | |
| . | . | . | . | . |
| . | . | . | . | . |
| null | null | 모든 부서코드와 직업코드의 합계 | cube가 (부서코드의 합+직업코드합)을 계산한 값 | 부서1 직업1 |
집합연산자
- 합집합 union
select emp_name, emp_id from employee
where dept_code='D5'
union all
select emp_name, emp_id from employee
where salary>=2400000;- 컬럼의 갯수가 같아야 한다
- 컬럼의 데이터 타입이 같아갸 한다
- union all일경우 모든 데이터를 합친다
- union만 쓸경우 중복된 값은 빠진다
interscet
select emp_name, emp_id from employee
where dept_code='D5'
intersect
select emp_name, emp_id from employee
where salary>=2400000;- 중복된 값을 찾아준다 - 교집합
minus
- 차 집합
select emp_name, emp_id from employee
where dept_code='D5'
minus
select emp_name, emp_id from employee
where salary>=2400000;A minus B라면 A에서 B만큼을 뺀 값이 출력된다. 기준이 A
Join
-
두 개 이상의 테이블에서 연관성을 가지고 있는 데이터들을 따로 분류하여 새로운 가상의테이블을 이용하여 출력함. -> 여러 테이블의 레코드를 조합하여 하나의 열로 표현 한 것
-
inner Join : 2개의 칼럼을 비교에 같은 데이터만 가지고옴(데이터가 없으면 가지고 오지 않음)
-
outer Join : 두개의 컬럼값을 비교해을때 업는 데이터도 출력이 가능한 조인
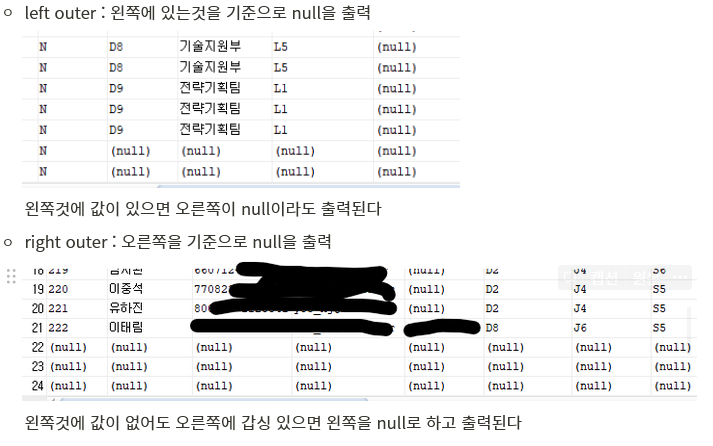
왼쪽것에 값이 없어도 오른쪽에 갑싱 있으면 왼쪽을 null로 하고 출력된다 ### 다중조인 ```sql select * from employee inner join department on dept_code = dept_id inner join job using(job_code); ``` - dapartment와 job을 조인했다

hello world