
📚 Part 2 쿠버네티스와 클러스터 운용
📁 쿠버네티스 소개
📌 서비스 개발 및 운용 방식
- 마이크로서비스 아키텍처 (microservice architecture; MSA)
- 응용 시스템 개발 및 구성을 위한 아키텍처 스타일의 하나
- 이에 비교하여 전통적인 방식의 아키텍처를 모놀리식(monolithic) 아키텍처라고 부르기도 함
- 애플리케이션이 서비스 모음으로 개발되어 각 마이크로서비스는 특정한 기능을 수용하고 개별 작업을 처리, 이 서비스들이 서로 연결되어 전체 응용을 구성
📌 컨테이너 인프라 환경의 적용
- 컨테이너 모델은 마이크로서비스를 구현하기에 적합
📌 쿠버네티스(Kubernetes)란
- 줄여서 k8s라고 표기하는 것을 자주 보게 됨
- 컨테이너 오케스트레이션 솔루션
- 다수의 컨테이너들을 관리하면서
- 자동 배포, 배포된 컨테이너의 동작 보증, 부하에 따른 동적 확장 등의 기능을 담당
- 도커와 잘 어울리는 실행 환경 구성 도구
- 도커 컨테이너들을 클러스터 내에 실행하고 관리하는 데 적합
- 지속적 통합과 인도 (CI/CD)에 유효하게 적용할 수 있음
- 컨테이너는 포드(pod)라고 불리는 k8s 오브젝트와 연관하여 실행 (포드 위에서 실행한다고 대강 표현)
k8s 클러스터
- 물리적인 컴퓨터를 한 개 이상 묶어놓은 것
- 크게 Control Plane과 한 개 이상의 Node로 이루어져 있음
📌 k8s 클러스터의 구성 요소
- 클러스터는 하나 이상의 노드(들)로 구성됨
- 마스터 노드 (컨트롤 플레인)
- kubectl (반드시 마스터 노드에 있어야 하는 것은 아니지만)
- API 서버, etcd - 클러스터의 중심 역할을 하는 구성 요소들
- 컨트롤러 매니저, 스케줄러
- 워커 노드
- 컨테이너 런타임 (CRI; Container Runtime Interface) - 포드를 이루는 컨테이너의 실행을 담당
- kubelet - 포드의 구성 내용을 받아 CRI에 전달하고 컨테이너들의 동작 상태를 모니터링
📌 포드(Pod)와 컨테이너(Container)
Control Plane 안에는 API Server가 있기 때문에 외부로부터 API를 통해 들어오는 요청을 Control Plane은 해석하고 실행을 한다. 요청을 하는 방식은 크게 UI(사용자의 명령을 받아들여서 실행할 수 있음), CLI(API를 호출하는 클라이언트)가 있다. 요청에 대한 일들을 워커 노드가 이 안에 Pod를 만들거나 없애면서 관리하고, Pod들 각각에는 Container가 하나 이상 실행한다.
📌 k8s가 제공하는 기능
- 컨테이너 밸런싱 (container balancing)
- 포드의 부하 균등화를 수행 - 몇 개의 응용을 복제할 것인지를 알려주면 나머지는 k8s가 처리
- 트래픽 로드 밸런싱 (traffic load balancing)
- 응용의 복제본이 둘 이상 있다면 k8s가 트래픽 부하 균등화를 수행하여 클러스터 내부에 적절히 분배
- 동적 수평 스케일링 (HPA; horizontal pod autoscaling)
- 인스턴스 수를 동적으로 확장하거나 감축하여 동적 요구사항에 대응하면서 시스템 자원을 효율적으로 활용
- 오류 복구 (error recovery)
- 포드와 노드를 지속적으로 모니터링하고 장애가 발생하면 새 포드를 실행하여 지정된 복제본의 수를 유지
- 롤링 업데이트 (rolling update)
- 지연 시간을 적용하고 순차적으로 업데이트를 배포함으로써 문제가 발생하더라도 서비스를 정상 유지할 수 있음
- 스토리지 오케스트레이션 (storage orchestration)
- 원하는 응용에 다양한 스토리지 시스템 (Amazon EBS, Googld GCE Persistent Disk 등)을 마운트할 수 있음
- 서비스 디스커버리 (service discovery)
- 태생적으로 수명이 짧은 포드의 동적 성질을 관리하기 위하여 자체 DNS 기반으로 서비스를 동적 바인딩할 수 있는 기능을 제공
📌 k8s Pod 의 생명 주기 (Life Cycle)
- kubectl 을 통해서 API 서버에 포드의 생성을 요청
- (업데이트가 있을 때마다) API 서버는 etcd에 기록하고 클러스터의 상태를 최신으로 유지 (하려고 함)
- 컨트롤러 매니저는 포드를 생성하고, 이 상태를 API 서버에 전달
- 아직 어떤 워커 노드에 포드를 적용할지는 결정하지 않은 상태
- 스케줄러는 포드가 생성되었다는 정보를 인지하고, 이 포드를 어떤 워커 노드에 적용할지를 결정해서 해당 노드에 포드의 실행을 요청
- 해당 노드의 kubelet이 CRI에 요청하여 포드가 만들어지고 사용 가능한 상태가 됨
- k8s 는 절차적인 구조가 아닌 선언적인 구조를 가지고 있음
- 각 요소가 추구하는 상태 (desired state)를 선언하면 현재 상태 (current state) 와 비교하고 지속적으로 맞추어 가려고 노력하는 구조
📌 k8s 오브젝트들
- 기본 오브젝트
- Pod - 한 개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위
- 독립적인 공간과 사용 가능한 IP를 가지고 있음, 언제든지 죽을 수 있음
- Namespace - k8s 클러스터에서 사용되는 리소스들을 구분해 관리하는 그룹
- Volume - 포드가 생성될 때 포드에서 사용할 수 있는 디렉토리를 제공
- Service - 유동적인 포드들에 대한 접속을 안정적으로 유지하도록 클러스터 내/외부에 연결하는 역할
- Pod - 한 개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위
- 디플로이먼트 (Deployment)
- 기본 오브젝트들을 보다 효율적으로 작동할 수 있도록 조합하고 추가로 구현한 것
- 레플리카셋 (replicaset) 오브젝트를 합쳐 놓은 형태로 단순하게 생각할 수 있음
📌 k8s 인프라 구축
- 로컬 환경
- kubeadm, docker desktop 등을 설치, 운용함으로써 로컬 환경에 간단한 클러스터 구성 가능
- 개발 단계에서의 테스트 등에 이용
- Public clouds
- Amazon 의 AWS EKS (Elastic Kubernetes Services)
- GCP (Google Cloud Platform) 의 GKE (Google Kubernetes Engine)
- Microsoft 의 AKS (Azuer Kubernetes Service)
- On-prem 설치
- SUSE 의 Rancher
- RedHat 의 OpenShift
📁 쿠버네티스 기본 사용법
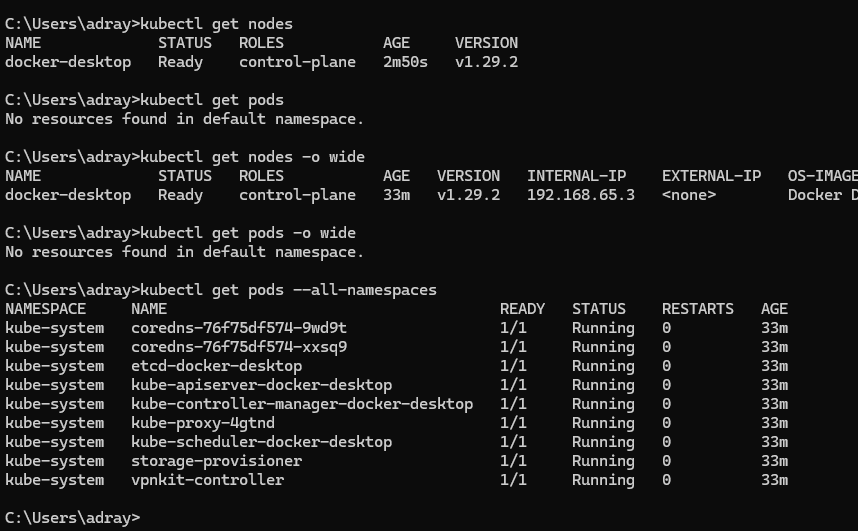
📌 노드(Node)와 포드(Pod) 정보를 조회
- 명령어
kubectl get nodeskubectl get pods
- 어떤 정보를 파악할 수 있는지 알아보자.
- 옵션 "-o wide"를 적용하여 무엇이 더 출력되는지 살펴보자.
📌 컨테이너 이미지를 이용한 포드의 생성
- 명령어
kubectl run <포드이름> --image=<이미지 지정>

📌 쿠버네티스 디플로이먼트
- Deployment
- 응용의 배포를 위하여 많이 이용되는 k8s 의 오브젝트 형태
- 동일한 모습의 포드들의 복제본 모음인 레플리카셋 (replicaset) 을 이용하는 것이 일반적
- 단순한 레플리카셋에 비하여 동적 업데이트 및 롤백 (rollback), 배포 버전의 관리 등이 유연하여 응용의 배포에 널리 이용됨
- 보통은 상태가 없는 (stateless) 응용의 배포에 이용
- (기억하자) 포드는 언제라도 사멸할 수 있음
- 동작 방식
- 디플로이먼트의 상태를 선언하면 k8s 가 동적으로 의도된 상태 (desired state) 가 되도록 레플리카셋을 관리
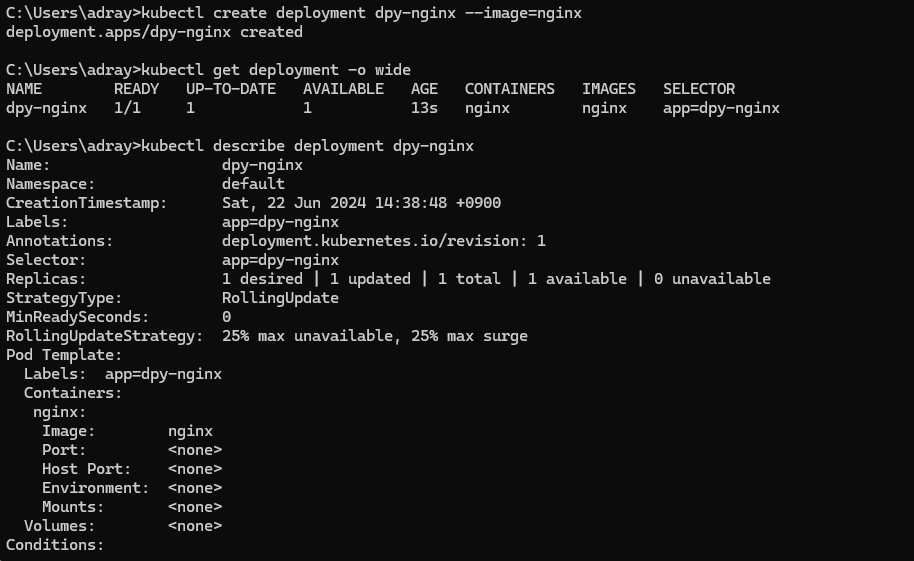
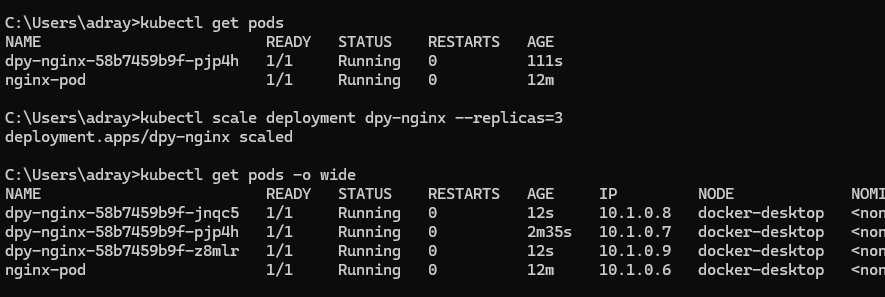
- 디플로이먼트의 상태를 선언하면 k8s 가 동적으로 의도된 상태 (desired state) 가 되도록 레플리카셋을 관리
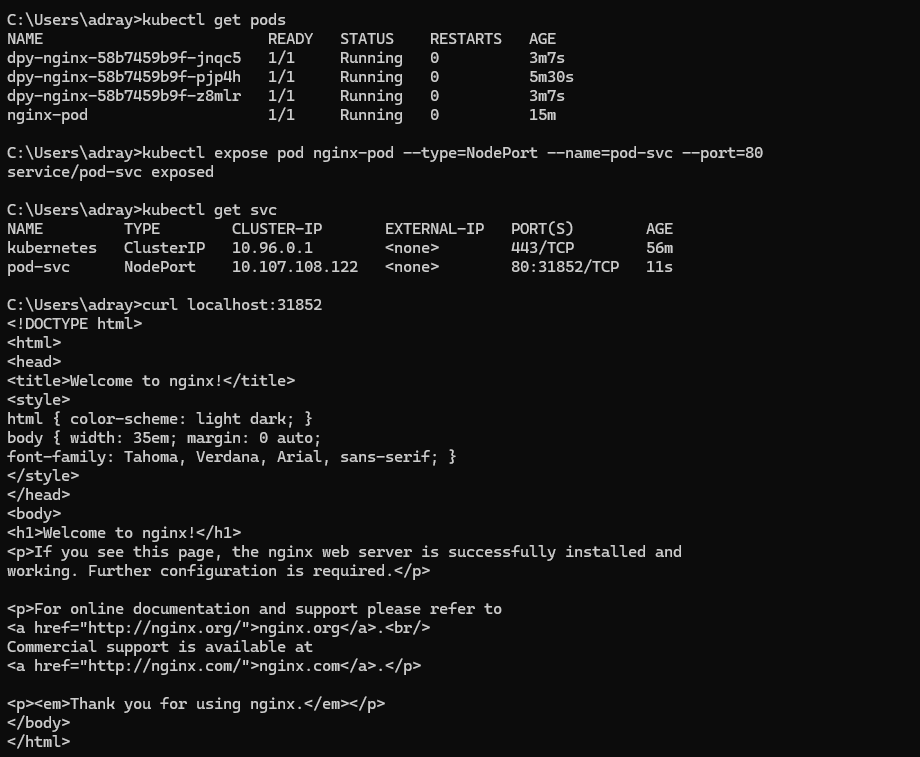
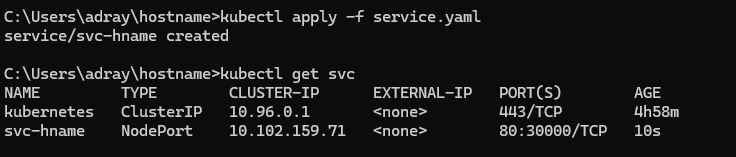
📌 클러스터 바깥으로 응용을 노출해 보자
- k8s 서비스 (service)
- 클러스터 내부의 포드에 의하여 실행되는 응용을 외부에 접근 가능하도록 노출하는 기능을 하는 오브젝트
- 노출하는 대상
- 특정 포드 (또는 포드들의 집합)에서 실행하는 컨테이너의 특정 포트
- 서비스의 서로 다른 형태들
- ClusterIP
- NodePort
- Load Balancer
- ExternalName
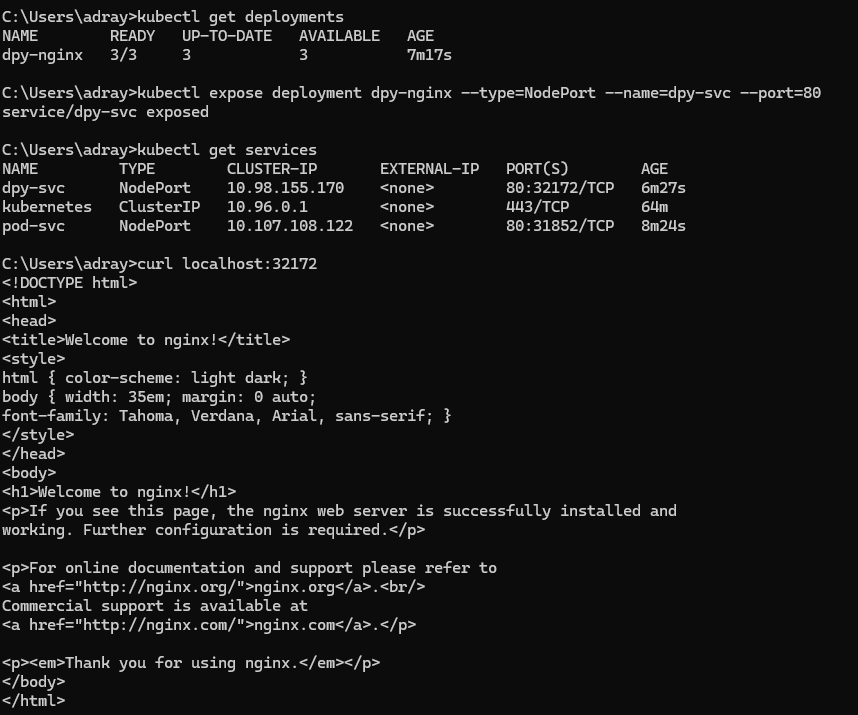
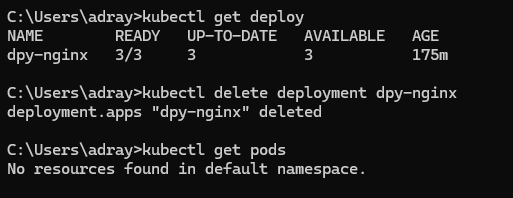
📌 오브젝트의 삭제
- 명령어
kubectl delete <오브젝트 형태> <오브젝트 이름>
삭제하고 나면 해당 서비스가 연결되어 있던 localhost의 포트에 접근 불가함.
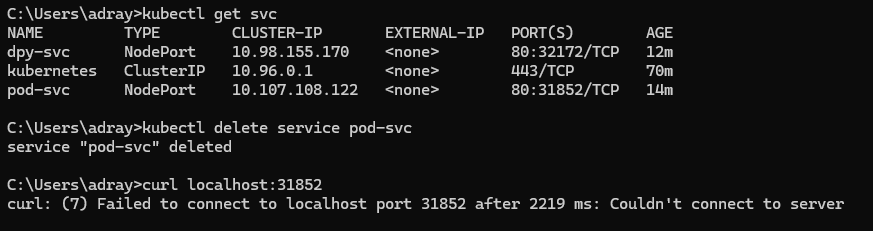
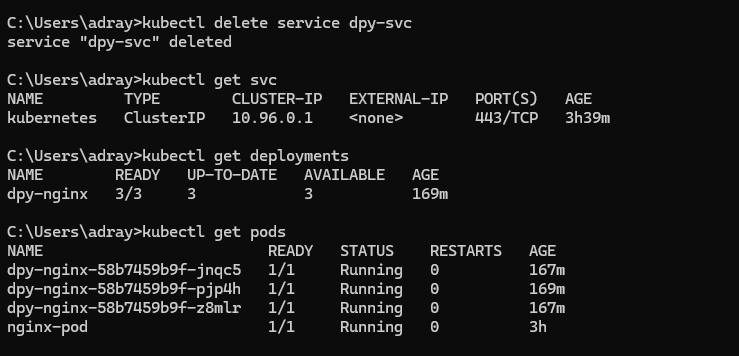
📌 포드의 삭제
kubectl run에 의하여 생성된 포드의 삭제- 디플로이먼트의 생성에 의하여 만들어진 포드의 삭제
포드가 삭제되기는 하지만, 곧 이어 디플로이먼트의 선언 상태에 맞도록 다른 포드가 생성되어 세 개의 포드를 유지한다.
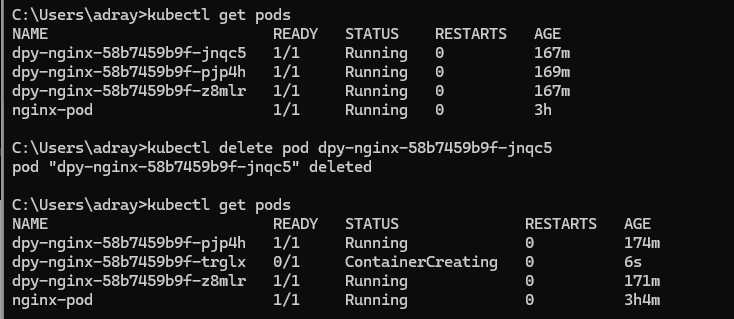
📌 매니페스트 (Manifest)
- k8s 오브젝트에 대한 명세를 파일로 기록한 것
- YAML (Yet Another Markup Language 또는 YAML Ain't Markup Language) 형태를 이용
- 파일에 각 오브젝트에 의도하는 상태 (desired state)를 기술
- 이것을 오브젝트 스펙 (object spec.) 이라고 부름
- 이 파일을 이용하여
- 오브젝트를 생성할 수 있고
- (파일의 내용을 변경하여) 오브젝트의 상태를 변경할 수 있음
- 물론, 파일의 내용을 변경하지 않고 다른 파일을 이용하여 오브젝트 상태를 변경하는 것도 가능
- 자동화가 필요한 환경에서 (당연히) 명령어 라인에 일일이 입력하는 것보다 많이 이용됨
📌 디플로이먼트의 오브젝트 스펙
- 앞서
kubectl create deployment명령을 이용한 것과 동일한 (다만, 옵션--replicas=3적용) 형태의 디플로이먼트를 생성하는데 이용할 수 있는 파일
📌 서비스의 오브젝트 스펙
- 앞서
kubectl expose deployment명령을 이용한 것과 동일한 서비스를 생성하는데 이용할 수 있는 파일- 단,
nodePort설정을 통해 노드의 어느 포트를 통해 노출할 것인지를 설정
- 단,
📌 매니페스트를 이용한 오브젝트 생성
- 명령어
kubectl apply-f<매니페스트 파일>kubectl create -f를 이용할 수도 있으나 위의 명령을 더 널리 이용함- (왜 그럴까?) 이후 실습에서 두 가지 방법을 모두 적용해 보고 생각해 볼 것
📁 쿠버네티스를 이용한 서비스 운용
📌 실습 도구로서의 웹 서버 만들기
🔗 예제로 (쿠버네티스 동작을 관찰하기 위해) 간단한 웹 응용을 제작
- 기능: 웹 요청을 수신하여 이의 응답으로 다음의 두 가지 정보를 출력
- hostname: 이것은 어떻게 설정될까? 노드의 정보인가?
- IP 주소: 이것은 또 어떻게 설정될까? 포드에 동적으로 붙여지는 것인가?
- 구현 방법
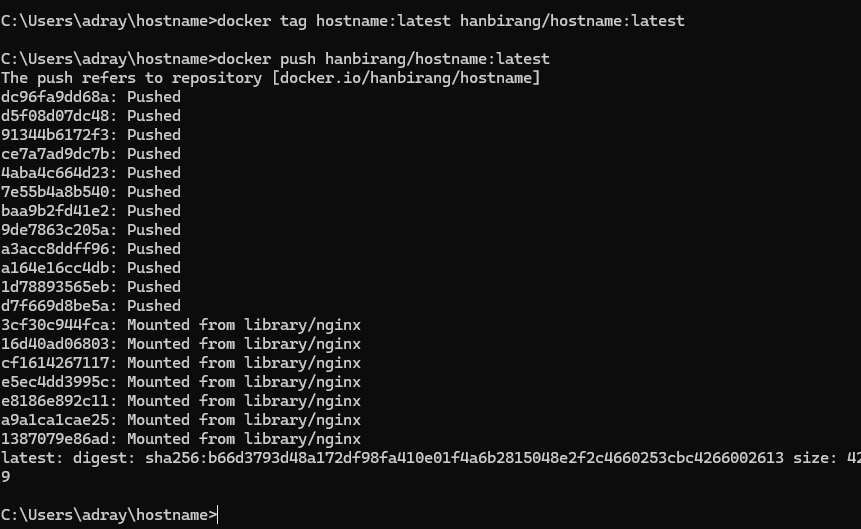
- docker build를 통해 (Dockerfile 작성) 예제 서버 이미지 작성
- 웹 서버로는 nginx를 이용 (base image 는 nginx:latest)
- Flask 를 이용한 웹 응용 작성
- 설정 및 구동 파일 등은 각각 작성해서 이미지에 추가
🔗 이것의 목적은?
- 클러스터에서 수신한 요청에 대하여 k8s 가 반응하는 방식을 간단히 (hostname 과 IP로) 모니터링하려고
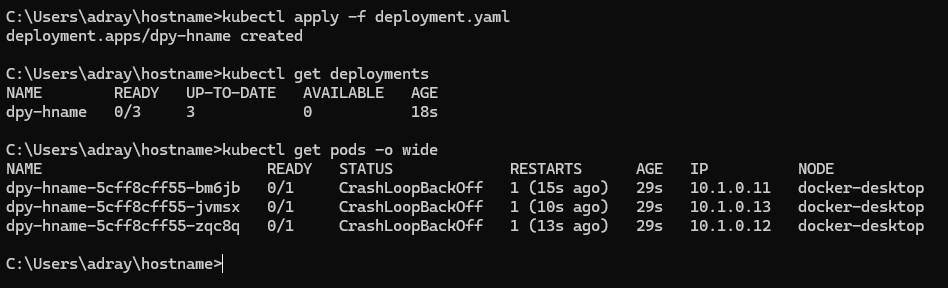
📌 디플로이먼트의 상태 유지
- 디플로이먼트에 의하여 포드들이 배포된 상태에서 이 중 하나 이상의 포드가 (어떤 이유로든) 사멸하면 k8s 는 새로운 포드를 생성하고 같은 종류 (이미지가 동일한) 의 컨테이너를 실행함
- 포드가 사멸하면 k8s 는 새로운 포드를 생성함으로써 디플로이먼트에 선언된 "의도된 상태" 를 유지하려고 함
- 클러스터 외부에는 별도의 서비스에 의하여 노출되므로 개별 포드의 클러스터 내 (동적 할당되는) IP 주소 등에 대해서는 사용자가 관리할 필요 없음
- 단, 포드는 언제든지 죽을 수 있는 오브젝트이므로 컨테이너에 기반한 응용을 개발함에 있어 상태를 띠지 않는 (stateless) 방식으로 만들어야 함
📌 포드의 동작 보증
- 디플로이먼트에 의하여 배포된 포드의 컨테이너 실행에 문제가 생기면 (오류 발생)
- k8s 는 이 포드에서 실행하던 컨테이너를 삭제하고 다시 컨테이너를 생성해 응용을 지속 실행
- k8s 에 의하여 관리되는 포드는 복구할 수 없는 오류를 맞닥뜨리는 경우에도 재시작 (RESTART) 에 의하여 정해진 동작을 지속하도록 보장됨
- (다시한번) 컨테이너에 기반한 응용은 상태를 띠지 않는 (stateless) 방식으로 구현되어야 함
📁 포드의 업데이트와 복구
📌 배포된 소프트웨어의 업데이트와 복구
- 소프트웨어의 업데이트가 발생함에 따라 (매번 새로 배포하는 것이 아니라) 동적 업데이트 필요
- 여기에서는 수동 (kubectl) 으로 업데이트 적용하는 실습을 통해 k8s 가 어떻게 업데이트를 수행하는지 관찰
- 소프트웨어의 업데이트는 실패할 수 있으므로, 빠르고 유연한 복구는 필수 기능
- 업데이트 자체가 실패하는 경우 - 이번 강의의 실습에서 복구 (rollback) 하는 내용 포함
- 새 버전의 소프트웨어가 오동작하는 경우 - 가능한 한 발생하지 않도록 (어떻게?) 해야 하겠으나, 만약 발생하는 경우에는 (이 확률을 0으로 만드는 것은 불가능) 민첩한 복구 조치가 필요
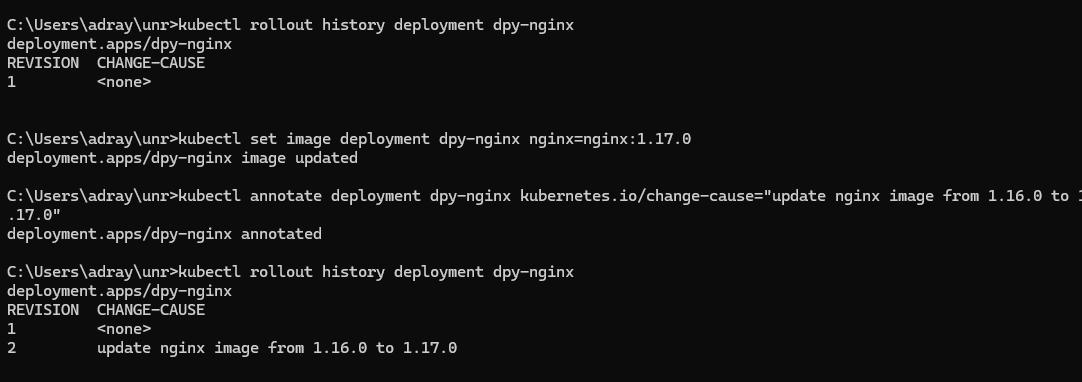
📌 롤아웃 정보의 열람
kubectl apply -f rollout.yaml명령어 실행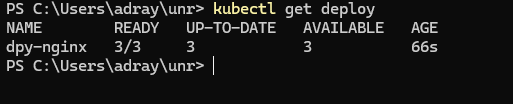
kubectl rollout statue -> 디플로이먼트의 배포 상태를 조회
kubectl rollout history -> 디플로이먼트의 배포 이력을 조회
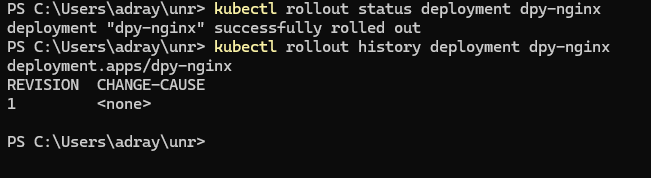
그러나 이력 정보에 쓸만한 것이 남아있지 않다. 따라서 이번에는 kubectl apply에 --record 옵션을 붙여서 실행해보자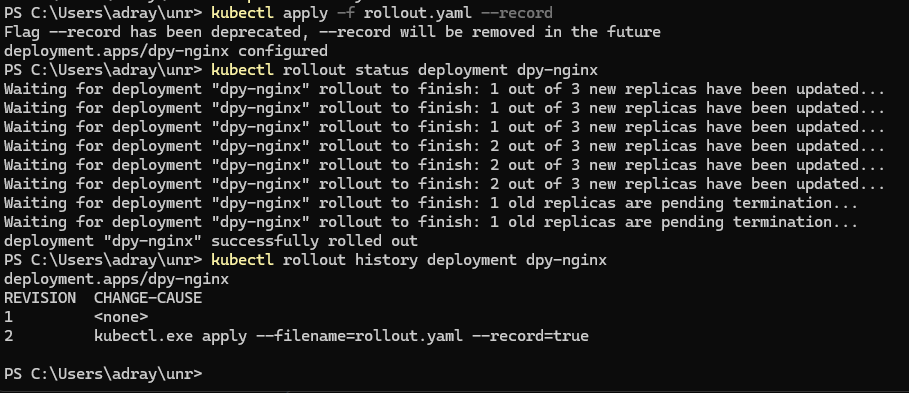
📌 배포 이력의 기록: kubectl annotate
📁 쿠버네티스 서비스와 볼륨
📌 서비스 (Services)
- 클러스터에 외부에서 클러스터에 접속하는 방법
- 클러스터 내부에서 동작하는 기능을 외부로 "노출" 하는 것을 서비스 (service) 라고 부름
- 서로 다른 서비스의 종류
- 클러스터 IP (ClusterIP)
- 노드포트 (NodePort)
- 로드밸런서 (Load Balancer)
- 인그레스 (Ingress)
📌 클러스터 IP (ClusterIP)
- 클러스터 내부에서만 접근할 수 있는 IP를 할당
- 포트 포워딩 (port forwarding) 또는 프록시 (proxy)를 통해 클러스터 외부로부터 접근 가능
- 테스트, 디버깅 등의 목적에 제한적으로 이용
📌 노드포트 (NodePort)
- 동작 방식
- 모든 워커 노드의 특정 포트 (NodePort)를 열고 여기로 오는 모든 요청을 노드포트 서비스에 전달
- 노드포트 서비스는 해당 요청을 처리할 수 있는 포드로 요청을 전달
📌 로드밸런서 (Load Balancer)
- 클러스터 외부의 로드밸런서 (public cloud 들은 공히 제공)를 이용하여 부하 균등화 수행
- 노드포트와 달리 특정 노드가 접근 불가한 경우에도 서비스 제공 가능
클러스터 외부에 존재하는 로드밸런서가 노드들의 상태를 체크하고 부하 균등화하여 노드들에 트래픽 전달. (k8s는 이를 지원하기 위하여 LoadBalancer라는 서비스 타입 제공)
📌 인그레스 (Ingress)
- 엄밀히 말하자면 k8s 서비스의 한 종류는 아니고, 복수의 서비스에 대해 목적에 따라 트래픽을 연결하는 도구
📌 동적 수평 오토스케일링
- HPA (Horizontal Pod Autoscaler)
- 부하량에 따라 디플로이먼트의 포드 수를 유동적으로 관리하는 k8s 의 기능
- (보통의 경우) 고려되는 부하량: CPU 및 메모리 사용량
- 메트릭스 서버 (metrics server) 로부터 부하 계측값을 전달받아 동일한 기능을 제공하는 포드의 수를 동적으로 조절
- 부하량에 따라 디플로이먼트의 포드 수를 유동적으로 관리하는 k8s 의 기능
- 스케일링 기준이 되는 값과 최소/최대 포드의 수를 지정
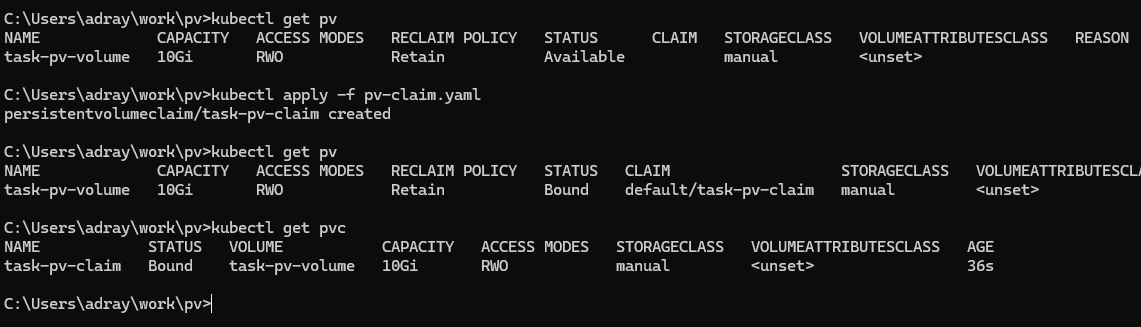
📌 볼륨 (Volumes)
- k8s 는 클러스터 내에서 이용할 수 있는 저장장치 (storage)의 추상화된 객체로 볼륨을 정의
- PV (PersistentVolume)
- 클러스터 내에 존재하는 스토리지를 추상화한 것
- 클러스터 내의 노드에 존재하는 물리적 저장장치를 이용할 수도 있으며, 다양한 원격 저장소 및 클라우드 서비스들도 이용할 수 있음
- PVC (PersistentVolumeClaim)
- (사용자에 의한) PV를 이용하기 위한 요청
- Pod: Node = PVC: PV
- 저장 공간의 크기와 접근 모드 (읽기/쓰기, ...)를 지정
📚 Part 3 젠킨스와 지속적 통합
📁 CI 도구로서의 젠킨스
📌 젠킨스 (Jenkins)
- 자바(Java)로 작성된 오픈소스 자동화 서버
- 지속적 인도 프로세스를 구축하는데 널리 이용됨
- 장점: 유연성과 확장성
📌 CI/CD 시나리오
CI (Continuous Integration; 지속적 통합) 단계
- 일반적으로 개발자가 소스 코드를 커밋하고 푸시하는 것으로 시작
- 응용 소프트웨어를 자동으로 빌드, 통합
- (자동) 테스트를 통하여 배포할 수 있는 상태임을 확인
CD (Continuous Delivery/Deployment; 지속적 인도) 단계
- CI 단계에서 소프트웨어가 배포 가능한 상태임을 확인하는 것으로 시작
- 응용 소프트웨어를 컨테이너 이미지로 만들어 냄
- 포드, 디플로이먼트, 서비스 등 다양한 오브젝트 조건에 맞추어 (미리 설정한 파일을 통해) 배포
📌 지속적 통합 파이프라인 (CI Pipeline)
- 리포지토리에 코드 커밋이 발생할 때마다 빌드, 단위 테스트, 정적 분석 등을 행함
CI 서버는 Jenkins가 담당하고, 코드 리포지토리는 Github에서 담당한다. 깃허브에서 코드를 꺼내다가 Jenkins Slaves에서 빌드, 테스트, 정적 분석 등을 수행한다. 이 과정을 통해 애플리케이션 SW를 만들어내는 과정을 자동화한 것이 CI Pipeline이다.
📌 젠킨스의 특징
- 다양한 프로그래밍 언어 지원
- 플러그인을 통한 확장
- 사용자가 직접 플러그인을 작성해 젠킨스의 기능을 확장하는 것도 가능
- 이식성
- 여러 종류의 컴퓨터에서뿐만 아니라 컨테이너 및 클러스터 환경에도 부드럽게 적용
- 대부분의 소스 관리 시스템 지원
- 분산 처리 지원
- 마스터/슬레이브 구조를 채택하여 여러 노드에서 작업 수행
- 코드로 파이프라인 구성
- 프로세스 자동화에 적합
📌 젠킨스 아키텍처
- 마스터-슬레이브 구조
- 슬레이브 (slave)는 에이전트 (agent) 라고 부르기도 함
- 마스터
- 빌드 시작 트리거 포착 (예: 코드 커밋)
- 알림 (예: 빌드 실패를 사용자에게 전달)
- 클라이언트와 통신하며 HTTP 요청 처리
- 에이전트에서 실행 중인 작업의 우선순위 조정 등 빌드 환경 관리
- 에이전트
- 마스터에 의한 개시 후 모든 작업을 처리
📌 수평적 확장
- 조직 (개발팀, 테스트팀, 데브옵스팀) 이 늘어날 때마다 마스터 인스턴스의 수를 늘려 가는 방식
- 비교: 수직적 확장 - 마스터에 대한 부하가 증가함에 따라 마스터 시스템에 자원을 추가하는 방식
- 통합 자동화가 복잡해진다는 단점이 있으나, 다음과 같은 중요한 이점이 있음
- 마스터 역할을 하는 컴퓨터의 하드웨어 사양에 대한 부담이 감소 (특히, 조직이 많이 커진다면?)
- 팀마다 각기 다른 설정이 가능
- 팀 전용 마스터 인스턴스가 있으므로 팀워크와 업무 효율이 높아짐
- 마스터 인스턴스 하나에 문제가 생겨도 다른 팀에 끼치는 영향이 최소화됨
📌 테스트 인스턴스와 프로덕션 인스턴스
- 중요! - 젠킨스 인스턴스는 항상 테스트용과 프로덕션용으로 분리 운용해야 함
- 개발팀보다는 운영팀에서 주의를 기울여야 하는 부분
- 다음과 같은 시스템 설정 변경이 일어날 때 프로덕션에 적용하기 이전 철저한 검증이 필요
- 젠킨스 소프트웨어의 업데이트
- 신규 플러그인 적용
- CI/CD 파이프라인의 변경 및 유지보수
📁 k8s 클러스터에 젠킨스 설치
📌 k8s 클러스터에 소프트웨어 설치
- 우리가 지금까지 해온 실험들에서는 손에 꼽을 수 있는 정도 개수의 오브젝트를 생성했음
- 그러나 많은 경우 소프트웨어의 구성은 일일이 관리하기 어려울 정도의 여러 오브젝트들의 묶음으로 이루어져 있음
- 젠킨스를 예로 들자면, (아마도) 우리가 개발해 보게 될 소프트웨어보다 더 복잡한 구조를 갖고 있을 것
- 이러한 작업을 도와 줄 수 있는 도구들도 있음 (예: k8s 용 패키지 매니저)
- 호스트 운영체제에 응용 소프트웨어를 설치하는 것과 비슷한 과정으로 k8s 클러스터에 이미 만들어져 있는 응용을 설치 (배포) 할 수 있음
📌 Helm
- 대표적인 k8s 용 패키지 매니저
- 오브젝트 배포에 필요한 사양이 이미 정의된 차트 (chart)를 이용하여 패키지를 검색하고 내려받아 설치
- 공개되어 있는 소프트웨어 패키지를 k8s 에 배포하는 것 외에도 배포 효율화를 위해 많이 이용되는 방법
- (Linux 의 예와 비교하자면)
- RedHat 계열의 rpm, yum 또는 Debian 계열의 apt와 비슷한 방식으로 동작
📌 Helm 의 기능
- 패키지 검색
- 설정한 저장소 (리포지토리) 에서 패키지를 검색할 수 있음 (저장소는 목적에 따라 추가 및 변경 가능)
- 패키지 관리
- 저장소에서 패키지 정보를 확인하고 사용자 시스템에 패키지 설치, 삭제, 업그레이드, 롤백 등을 지원
- 패키지 의존성 관리
- 패키지를 설치할 때 의존성 관계에 있는 소프트웨어를 같이 설치하고 패키지를 삭제할 때 필요하지 않게 된 소프트웨어를 함께 삭제
- 패키지 보안 관리
- 디지털 인증서와 패키지 체크섬 (checksum)을 이용하여 해당 패키지의 소프트웨어 또는 의존성 관계가 변조되었는지를 확인할 수 있음 (악의적인 공격으로부터 보호)
📌 Helm의 설치
- Helm 프로젝트에서 소프트웨어를 얻어다가 설치
- 각자의 환경에 맞는 바이너리 릴리스를 찾아서 다운로드하고 설치하는 방법
- 설치 스크립트만 받아다가 이것을 실행함으로써 스크립트가 적절한 버전을 얻어다 설치하도록 하는 방법
- 패키지 매니저를 이용하여 설치
- Windows 의 경우 - Chocolatey 와 Scoop 이용 가능
- MacOS 의 경우 - Homebrew 이용 가능
- Linux 의 경우 - apt/yum 등 이용 가능
- 강의에서는 Ubuntu apt 를 이용하여 설치하는 방법과 절차를 설명
- 다른 운영체제 환경을 이용하는 학습자는 비슷한 (그러나 그보다 조금 단순한) 방법을 스스로 적용해서 설치
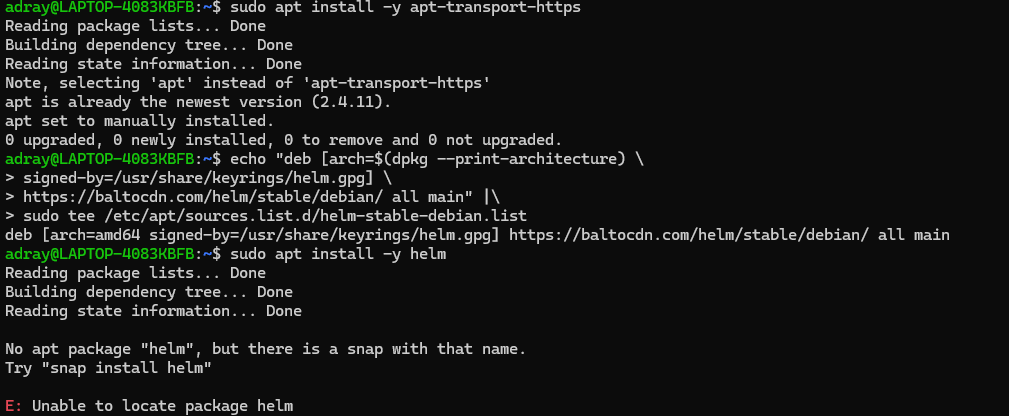
설치하는데 오류가 발생해서 snap을 이용해서 설치하였다.
sudo snap install helm --classic 명령어 사용
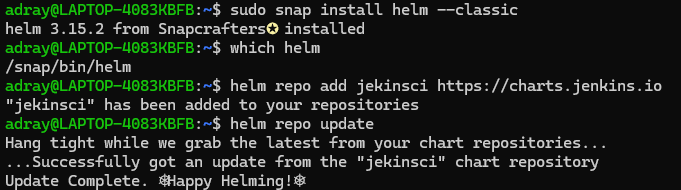
우여곡절 끝에.. 설치 완료 했습니다
설치 완료 했습니다 -> 오류남 -> (설치 완료) 뻥입니다 -> 재설치 -> 설치 완료 했습니다 -> 오류남 -> 뻥입니다 -> 구글링 & 채찍피티.. 무한 반복 후에 겨우 얻은 결실..

📌 지금까지 ...
- Jenkins를 나의 k8s 클러스터에 설치
- 구성 요소들을 일일이 kubectl 같은 것으로 설치하는 것은 번거롭고 잘못이 발생할 가능성이 큰 일이므로, 이것을 간편하고 효율적으로 해 줄 수 있는 방법을 이용
- Helm 의 설치 - 이것은 클러스터 안에서 실행되는 것이 아니고 내 컴퓨터에서 실행되면서 k8s 클러스터 내에 패키지 배포 및 설정을 행하는 패키지 매니저
- Helm 을 이용해서 (차트는 온라인에서 얻어오는 방식으로) jenkins를 k8s 클러스터에 배포
- Jenkins 가 올바르게 배포되었는지 기본적인 확인
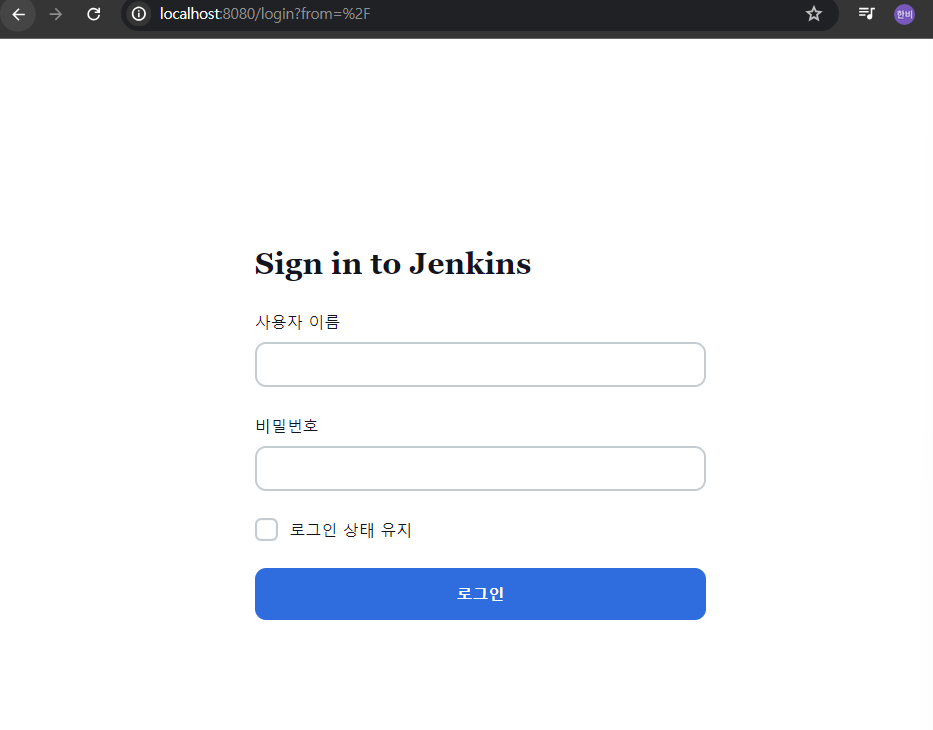
- 포트 포워드를 이용해서 클러스터 내에서 8080 번 포트로 제공 (노출) 하고 있는 서비스에 로컬 컴퓨터의 포트 (예제에서는 이것도 8080번)를 연결
- 브라우저에서 localhost:8080 에 접근해서 Jenkins 의 접속 화면이 연결되는지 확인
- 구성 요소들을 일일이 kubectl 같은 것으로 설치하는 것은 번거롭고 잘못이 발생할 가능성이 큰 일이므로, 이것을 간편하고 효율적으로 해 줄 수 있는 방법을 이용
📌 Jenkins 관리자 비밀번호 알아내기
- 지금 설치된 Jenkins의 관리자 계정 (admin) 설정은 k8s의 secret 오브젝트로 관리됨

이때 아이디는 admin 비밀번호는 여기 나온 문자로 치면 로그인 된다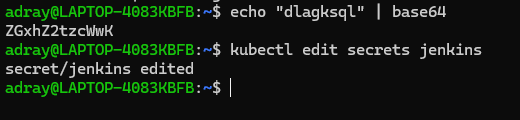
비밀번호 변경완료
📌 Jenkins 기초 설정
- 언어 설정
- 사용자 인터페이스에 기본적으로 적용되는 언어 설정을 영어로 고정
- 메뉴명 등이 달라서 겪을 수 있는 혼란을 피하려는 목적
- 플러그인 "Locale" 을 설치
- Manage Jenkins > System > Locale
- 시간대 설정
- 자신이 살고 있는 지역의 시간대로 서버 시간대를 설정
- 빌드 시작 및 종료 시각 등의 기록을 해석하는 데 혼란을 피하려는 목적
- People > [계정 선택] > Configure > User Defined Time Zone
- 자신이 살고 있는 지역의 시간대로 서버 시간대를 설정
📁 젠킨스 기본 사용법
📌 단순한 예제로 파이프라인 맛보기
- Hello, world!
- 사실은 빌드 및 배포 등에 대해서는 아직 아무런 하는 일이 없는 예제
- 그러나 Jenkins "Item" 을 생성하고 이것이 어떤 방식으로 동작하는지를 엿보는 목적으로 테스트
- 실제로 벌어지는 일들
- Jenkins 마스터는 k8s 클러스터 내에 동적으로 에이전트를 생성
- 에이전트에서는 지정한 ("Hello, world!"를 콘솔에 표시하는) 작업을 수행
- 에이전트의 작업 수행 결과는 마스터에게 보고되고, 우리는 이것을 눈으로 확인해 볼 것
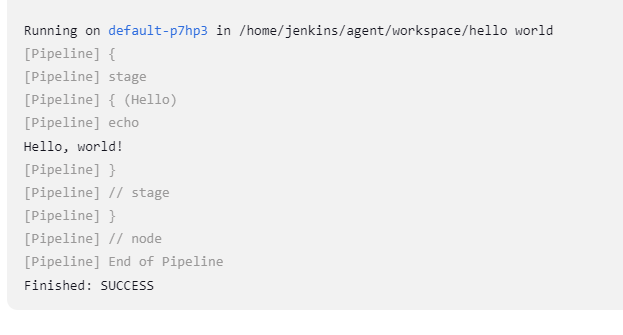
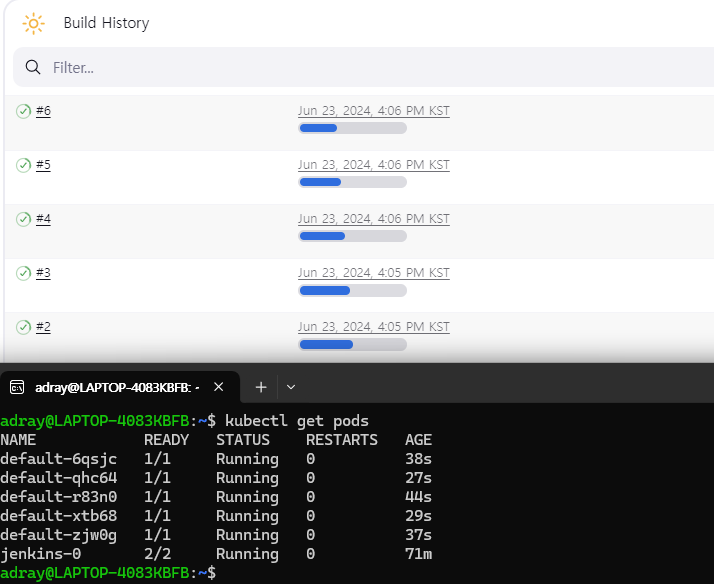
📌 클러스터 내 에이전트 동작 관찰
- k8s 클러스터에서 Jenkins 는 에이전트를 동적으로 프로비저닝
- 이를 위해서 Kubernetes 플러그인이 설치되어 있어야 하며, 적절한 설정도 되어있어야 함
- 우리의 실습에서는 helm을 이용하여 Jenkins를 설치할 때 이러한 설정들도 (기본값으로) 구성되어 있음
- 동적 에이전트 프로비저닝 테스트
- (인위적으로) 빌드 과정이 오래 걸리는 파이프라인을 구성
- 순차적으로 여러 차례의 빌드를 스케줄 ("Build Now" 버튼을 여러 번 눌러서)
- Jenkins 의 동작과 k8s 클러스터의 상태를 관찰
📌 지금까지의 내용 요약
- Jenkins는 "Item” 단위로 프로젝트를 관리
- 웹 사용자 인터페이스를 이용해서 설정할 수 있고 상태를 열람할 수 있도록 되어 있음
- 파이프라인에 빌드 절차를 기술할 수 있음
- 앞에서는 매우 간단한 (echo 'Hello, world!') 동작을 시험 삼아 기술해 보았음
- 빌드는 어떤 이벤트에 의하여 시작
- 앞에서는 "Build Now"를 클릭함으로써 수동으로 빌드 개시했음
- 보통은 SCM (예: git) repository 에 발생하는 이벤트 (예: push)에 의하여 트리거됨
- k8s 클러스터에서 운용되는 Jenkins 는 동적으로 에이전트 프로비저닝
- 이와 관련한 설정은 이미 helm 을 이용해 Jenkins를 설치할 때 이루어져 있었음 - 사실, 설정해야 할 것은 꽤 많음
- 지금부터 (아주 겉핥기 식으로) 둘러보고, 이후 CI/CD 파이프라인을 구성하면서 하나하나 알아가기로
📁 젠킨스 프로젝트 설정
📌 첫 번째 젠킨스 프로젝트 실습
- 목표
- 간단한 웹 응용 (이전 실습에서 만들었던 것)을 젠킨스에 의하여 빌드 및 배포되도록 설정해 보기
- 단계
- 프로젝트 소스가 담긴 GitHub 리포지토리 준비
- 젠킨스의 빌드 환경을 설정
- Docker를 이용하여 이미지를 빌드하고 DockerHub 레지스트리에 푸시
- kubectl 을 이용하여 레지스트리로부터 이미지를 가져다가 같은 클러스터에 배포 (및 노출)
- 프로젝트가 간단한 데 비하여 설정할 것들이 좀 많지만, 처음엔 어색해도 몇 번 비슷한 일을 하다보면 익숙해질 것
- 시행착오를 몇 차례 거치면서 프로젝트 설정을 다듬어 갈 계획
- 앞으로 CI/CD 파이프라인 구축을 위해 익혀 두어야 하는 일들
📌 프로젝트 리포지토리의 준비
- GitHub 에 새로운 리포지토리 (여기에서는 public 가정) 생성
- 이후 강의노트에서는 sheayun/pl-exp 라는 주소로 만들어져 있다고 가정
- 여기에 “쿠버네티스를 이용한 서비스 운용" 실습에서 이용했던 파일 일곱 개를 그대로 배치
- app.py - 단순한 기능 (hostname 과 IP 주소를 출력)을 가지는 flask 기반 웹 응용 스크립트
- requirements.txt - Flask 응용 실행에 필요한 패키지를 저장하기 위한 파일
- site.conf - Nginx 서버를 이용하여 요청을 flask 응용이 서비스하도록 설정하기 위한 파일
- start.sh - 컨테이너가 생성될 때 웹 서버 (nginx)와 flask 응용을 구동하기 위한 셀 스크립트
- Dockerfile - 위의 파일들을 이용해서 도커 이미지를 생성하기 위한 파일
- deployment.yaml - 만들어진 도커 이미지를 k8s 클러스터에 디플로이먼트 형태로 생성하기 위한 파일
- service.yaml - 위에서 생성한 디플로이먼트를 NodePort 서비스의 형태로 노출하기 위한 파일
📌 컨테이너 스펙을 작성해서 포드 템플릿의 설정을 완성
- 신규 추가하는 포드 템플릿에는 두 개의 컨테이너 스펙이 포함되도록 할 예정
- 따라서 이것에 의해서 생성되는 포드에서는 두 개의 컨테이너가 실행될 것
- 빌드 작업을 실행할 컨테이너 (이름: jnlp)
- JNLP (Java Network Launch Protocol)을 따라 Jenkins 마스터와 작업 조율하면서 빌드 작업 실행
- docker CLI 와 kubectl CLI (잠시 후에 이용하려고 하니)를 갖추고 있음
- 미리 만들어진 (이후에는 이런 것들을 직접 만들어 빌드 환경을 구성하게 됩니다만) 이미지 이용:
- sheayun/jenkins-agent-sample
- 도커 데몬 (daemon)을 실행하는 컨테이너 (이름: dind)
- 어느 클러스터에 있더라도 통일된 docker build 환경을 제공하기 위해 독립된 컨테이너로 제공 (예를 들어 현재 docker desktop 으로 클러스터 제공하고 있는 호스트의 daemon 이용하지 않음)
- 이미지는 docker:latest 를 이용하기로 함
- 어느 클러스터에 있더라도 통일된 docker build 환경을 제공하기 위해 독립된 컨테이너로 제공 (예를 들어 현재 docker desktop 으로 클러스터 제공하고 있는 호스트의 daemon 이용하지 않음)
자꾸 오류가 발생해서 jenkins의 branch 설정을 main으로 바꾸어 주었다.
📁 간단한 젠킨스 파이프라인
📌요약
- Jenkins 파이프라인의 구성
- Jenkins 파이프라인 정의에는 두 가지 방식이 있음
- 선언적인 (declarative) 방식: 우리가 지금까지 실습한 방법
- 빌드 단계 (stage) 를 선언적으로 정의하는 방식
- 스크립트 (scripted) 방식: 아직까지는 마주친 적 없지만 앞으로 만나보게 될 것
- 빌드 단계 (stage)를 절차적으로 기술하는 (스크립트를 실행하는) 방식
- 선언적인 (declarative) 방식: 우리가 지금까지 실습한 방법
- Jenkins 파이프라인 정의에는 두 가지 방식이 있음
- 두 가지 방식으로 파이프라인 실습을 해 보았음
- Jenkins UI 에서 선언적 스크립트를 입력하는 방식
- GitHub repo 에 Jenkinsfile 로 파이프라인 스크립트를 저장하는 방식
