워크로드
ref. https://rancher.com/learning-paths/introduction-to-kubernetes-workloads/
So what exactly is a workload? In Kubernetes, there is no object, component, and any kind of construct called a “workload”. However, the term is often used as a general category for tasks and services you want running on your cluster. It might be synonymous with microservices, applications, containers, or processes. Workloads are often long-lived processes, but can also be short-lived on demand or batch jobs.
그렇다면 워크로드란 정확히 무엇일까?
- 쿠버네티스에는 workload라는 오브젝트/컴포넌트/어떤 종류의 구성요소도 존재하지 않는다.
- 이 단어는 클러스터에서 실행하려는 작업이나 서비스 등을 가리키는 말로 종종 사용된다.
- 👉 마이크로 서비스, 어플리케이션, 컨테이너, 프로세스와 동의어일 수 있다.
- workload는 수명이 긴 프로세스이지만 요청시만 수행되거나 배치 잡과 같은 수명이 짧은 프로세스 일 수도 있다.
워크로드가 단일 컴포넌트든 함께 작동하는 컴포넌트 집합이든 관계없이, 쿠버네티스에서는 워크로드를 일련의 파드 집합 내에서 실행한다. 사용자를 대신하여 파드 집합을 관리하는 워크로드 리소스를 사용할 수 있는데, 이러한 리소스는 지정한 상태와 일치하도록 올바른 수의 올바른 파드 유형이 실행되고 있는지 확인하는 컨트롤러를 구성한다.
쿠버네티스는 여러가지 빌트인 워크로드 리소스를 제공한다.
- Deployment :
Deployment의 모든Pod가 "필요 시 교체" 혹은 "상호 교체" 가능한 경우, 클러스터의 스테이트리스 어플리케이션 워크로드를 관리하기에 적합하다. - StatefulSet : state를 추적하는 하나 이상의 Pod를 반드시 동작하게 해준다.
- DaemonSet : 노드-로컬 기능을 제공하는
Pods를 정의한다. - Job 및 CronJob : 실행 완료 후 중단되는 작업을 정의한다.
파드
개념
파드(Pod)란 쿠버네티스에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위이다.
- 하나 이상의 컨테이너 그룹
- 파드는 포함하는 컨테이너를 구동하는 방식에 대한 명세를 포함한다.
- 한 파드 내 컨테이너들은 스토리지와 네트워크를 공유한다.
- 콘텐츠는 항상 함께 배치, 스케줄되며 공유 컨텍스트에서 실행된다.
- 이를 위해 쿠버네티스는 컨테이너 단위가 아닌, 파드 단위의 배포를 선택한다.
- 도커 개념 측면에서, 파드는 공유 네임스페이스와 공유 파일시스템 볼륨이 있는 도커 컨테이너 그룹과 비슷하다.
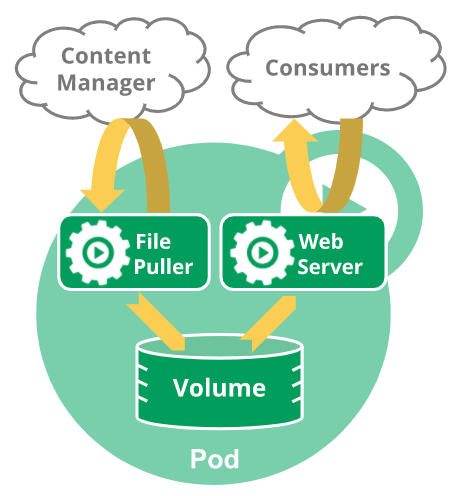
파드는 여러 협력 프로세스(컨테이너)를 지원하도록 설계되었으므로, 컨테이너는 리소스와 의존성을 공유하고 서로 통신하며 종료 시기와 방법 등을 조정할 수 있다.
파드는 기본적으로 파드에 속한 컨테이너에 네트워킹과 스토리지라는 두 가지 종류의 공유 리소스를 제공한다.
파드의 사용
- 단일 컨테이너를 실행하는 파드
파드가 하나의 컨테이너만 포함하는 경우이다. 파드는 단순히 컨테이너를 둘러싼 래퍼이며, 쿠버네티스는 컨테이너를 직접 관리하는 대신 파드를 관리한다. - 함께 작동해야하는 여러 컨테이너를 실행하는 파드
함께 배치된 컨테이너는 밀접한 결합성을 가지며 리소스를 공유한다. 이들은 하나의 결합된 서비스 단위를 형성한다.
각 파드는 어플리케이션의 단일 인스턴스를 실행하는 것이 목표이다.
따라서 더 많은 인스턴스를 실행하기 위해 어플리케이션을 수평 확장하는 것을 레플리케이션이라고 한다. 복제된 파드는 일반적으로 워크로드 리소스와 해당 컨트롤러에 의해 그룹으로 생성, 관리된다.
일부 파드는
- 앱 컨테이너 뿐만 아니라
- 초기화 컨테이너도 포함한다.
- 초기화 컨테이너는 앱 컨테이너가 시작되기 전에 실행-완료 된다.
파드 작업
🤔 파드는 상대적으로 일시적인, 일회용 엔티티로 설계되었기 때문에 사용자가 쿠버네티스에서 직접 개별 파드를 만드는 경우는 거의 없다.
파드가 생성될 때, 새 파드는 클러스터의 (워커)노드에서 실행되도록 스케쥴된다.
파드는 다음의 상황이 발생할 때까지 해당 노드에 남아있다.
- 파드 실행 완료
- 파드 오브젝트가 삭제
- 리소스 부족으로 인한 파트의 축출
- 노드 실패
❗️ NOTE
파드에서 컨테이너를 다시 시작하는 것과 파드를 다시 시작하는 것을 혼동하지 말자!
파드는 프로세스가 아닌, 컨테이너를 실행하기 위한 환경이다. 파드는 삭제될 때까지 유지된다.
✔️ 파드와 컨트롤러
워크로드 리소스를 사용하여 여러 파드를 생성하고 관리할 수 있다. 리소스에 대한 컨트롤러는 파드 장애 시 복제 및 롤아웃, 자동 복구 처리한다.
✔️ 파드 템플릿
파드 템플릿이란 파드를 생성하기 위한 명세이며, deployment, job, daemonSet과 같은 워크로드 리소스에 "포함"된다.
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
template:
# 여기서부터 파드 템플릿이다
spec:
containers:
- name: hello
image: busybox
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
restartPolicy: OnFailure
# 여기까지 파드 템플릿이다워크로드 리소스의 각 컨트롤러는 워크로드 오브젝트 내부의 파드 템플릿을 사용하여 실제 파드를 생성하고 사용자 대신 해당 파드를 관리한다.
파드 템플릿이 변경되는 경우, 해당 리소스는 기존의 파드를 갱신하거나 패치하는 대신 수정된 템플릿을 사용하는 새로운 파드를 생성하기 때문에 이미 존재하는 파드에 직접적인 영향을 주지않는다.
리소스 공유와 통신
❗️ 파드는 파드에 속한 컨테이너 간의 데이터 공유와 통신을 지원한다.
✔️ 파드 스토리지
파드는 공유 스토리지 Volume 집합을 지정할 수 있으며 파드 내 모든 컨테이너는 공유 볼륨에 접근 가능하므로 해당 컨테이너들을 데이터를 공유 할 수 있다.
✔️ 파드 네트워킹
각 파드에는 고유한 IP 주소가 할당된다. 파드의 모든 컨테이너는 IP 주소와 네트워크 포트를 포함하는 네트워크 네임스페이스를 공유한다. 즉, 파드 내부에서 각 컨테이너들은 localhost를 사용하여 서로 통신할 수 있다.
다른 파드에서 실행되는 컨테이너와 상호 작용하려는 컨테이너는 IP 네트워킹을 사용해 통신할 수 있다.
컨테이너에 대한 특권 모드
컨테이너 스팩의 보안 컨텍스트에 있는 privileged 플래그를 사용해 특권 모드를 활성화 할 수 있는데, 특권을 보유한 컨테이너 내 프로세스는 컨테이너 외부의 프로세스가 가지는 권한과 거의 동일한 권한을 가지게 된다.
파드 라이프사이클
파드는 정의된 라이플 사이클을 따른다.
Pending → Running → Succeeded or Failed
파드의 수명 ⏱
파드는 계속 이어지는 것이 아닌 임시 엔티티로 간주된다.
파드의 생성, 고유 ID 할당, 종료 or 삭제는 남아있는 노드에 스케줄링된다. 만약 노드가 종료되면 해당 노드에 스케줄된 파드는 타임아웃 기간후에 삭제되도록 설정된다.
쿠버네티스는 컨트롤러라는 고수준 추상화를 사용해 일회용인 파드 인스턴스를 관리한다.
- 파드는 자가 치유되지 않으며, 파드의 스케줄링에 실패하거나 파드가 노드에 스케줄된 후에 실패하면 해당 파드는 삭제된다.
- 리소스 부족 혹은 노드 유지 관리 작업에 의해 파드가 축출되지 않는다.
- UID 가 할당된 파드는 다른 노드르 "재스케줄링" 되지 않는다. 사용자 요청에 의해 이름은 동일하나 UID는 다른 "거의" 동일한 새 파드로 대체될 수는 있다.
❗️ NOTE
볼륨과 같은 것들이 파드와 동일한 수명을 갖는다는 의미는 특정 파드가 존재하는 한 그것 또한 존재함을 뜻한다. 파드가 삭제되고 동일한 대체 파드가 생성되면 그 또한(ex.볼륨) 폐기 후 재생성된다.
파드 단계(phase)
PodStatus : 파드의 status를 나타내는 오브젝트
- conditions
- containerStatuses
- ephemeralContainerStatuses
- hostIP
- initContainerStatuses
- message
- nominatedNodeName
- phase
- podIP
- podIPs
- qosClass
- reason
- startTime
파드의 status필드는 phase 필드를 포함하는 PodStatus 오브젝트로 정의된다.
- phase 필드는 파드가 라이프사이클 중 어느 단계에 해당하는지 표현한다.
phase에 가능한 값은 다음과 같다
| 값 | 의미 |
|---|---|
| Pending | 파드가 쿠버네티스 클러스터에서 승인되었으나, 하나 이상의 컨테이너가 설정되지 않았다. (실행할 준비가 되지 않았다.) |
| Running | 파드가 노드에 바인딩되었고, 모든 컨테이너가 생성되었다. 적어도 하나의 컨테이너가 아직 실행 중 or 시작 or 재시작 중에 있다. |
| Succeeded | 파드에 있는 모든 컨테이너들이 성공적으로 종료되었고, 재시작되지 않을 것이다. |
| Failed | 파드에 있는 모든 컨테이너가 종료되었으나, 적어도 하나 이상의 컨테이너가 실패로 종료되었다. 즉, 해당 컨테이너는 non-zero 상태로 exited 했거나, 시스템에 의해 강제종료 (terminated) 되었다. |
| Unknown | 어떤 이유에 의해 파드의 상태를 얻을 수 없다. |
컨테이너 상태
쿠버네티스는 전체 파드의 phase 뿐만 아니라 파드 내부의 각 컨테이너 상태 또한 추적한다.
- 스케줄러가 노드에 파드를 할당하면
- kubelet은 컨테이너 런타임을 사용해 해당 파드에 대한 컨테이너 생성을 시작한다.
| 상태 | 의미 |
|---|---|
| Waiting | Running, Terminated가 아닌 경우.컨테이너 시작을 완료하는데 필요한 작업을 실행하는 중이다. |
| Running | 컨테이너가 문제없이 실행되고 있음을 나타낸다. |
| Terminated | 컨테이너가 실행을 완료했거나 어떤 이유로 실패한 경우이다. |
컨테이너 재시작 정책
파드의 spec 중 restartPolicy 을 통해 정책을 명시할 수 있다. 이 때 명시된 값은 파드 내 모든 컨테이너에 적용된다.
default 는 Always이며, 이 외에 OnFailure, Never 도 설정할 수 있다.
파드의 조건
파드는 하나의 PodStatus를 가지며 conditions 라는 필드는 PodCondition 배열 타입이다.
PodCondition 타입은 파드가 조건의 통과 여부를 설명하는데 type[:filed]은 다음과 같다.
| type | 설명 |
|---|---|
| PodScheduled | 파드가 노드에 스케줄되었다. |
| ContainersReady | 파드의 모든 컨테이너가 준비되었다. |
| Initialized | 모든 초기화 컨테이너가 성공적으로 시작되었다. |
| Ready | 파드는 요청을 처리할 수 있으며 일치하는 모든 서비스의 로드 밸런싱 풀에 추가되어야 한다. |
Example :
kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # 내장된 PodCondition이다
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # 추가적인 PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...컨테이너 probe
프로브(probe) kubelet에 의해 주기적으로 컨테이너에 가해지는 진단(diagnostic)이다.
진단을 위해 kubelet은 컨테이너에 의해 구현된 핸들러를 호출한다.
probe는 다음 세 가지 중 하나의 결과를 가진다.
- Success : 컨테이너가 진단을 통과함
- Failure : 컨테이너가 진단에 실패함
- Unknown : 진단 자체가 실패함. 아무런 액션도 수행되면 안됨
진단은 다음의 세 종류가 있다.
- livenessProbe : 컨테이너가 동작 중인지 확인한다. Failure 시 컨테이너를 죽이고 재시작 정책의 대상으로 만든다.
- readinessProbe : 컨테이너가 요청을 처리할 준비가 되었는지 확인한다. Failure 시 엔트포인트 컨트롤러는 파드에 연관된 모든 서비스들의 엔드포인트에서 해당 파드의 IP 주소를 제거한다.
- 프로브가 성공한 경우에만 파드에 트래픽 전송을 시작하려고 하는 경우 이를 지정한다.
- 컨테이너가 대량의 데이터, 설정 파일들, 시동 중에 마이그레이션 처리 등이 있는 경우 이를 지정한다.
- 컨테이너 유지 관리를 위해 자체 중단되길 바란다면 이를 지정한다.
- startupProbe : 컨테이너 내의 어플리케이션이 시작되었는지를 나타낸다. 이 프로브가 주어진 경우, Success 될 때 까지 다른 프로브는 활성화되지 않는다. Failure 시 컨테이너를 죽이고 재시작 정책에 따라 처리한다.
- 서비스를 시작하는 데 오랜 시간이 걸리는 컨테이너가 있는 파드에 유용하다.
파드의 종료
파드는 클러스터의 노드에서 실행되는 프로세스를 나타내므로, 해당 프로세스가 더 이상 필요하지 않을 때 정상적으로 종료되도록 하는 것이 중요하다.
사용자가 파드의 삭제를 요청하면, 클러스터는 파드가 강제로 종료되기 전에 의도한 유예 기간을 기록하고 추적한다. 강제 종료 추적이 적용되면 kubelet은 정상 종료를 시도한다.
플로우의 예는 다음과 같다.
kubelet도구를 사용해 기본 유예 기간(30s)으로 특정 파드를 수동 삭제한다.- API 서버의 파드는 유예 기간과 함께 파드가 "dead"로 간주되는 시간으로 업데이트된다.
👉 로드 밸런서는 종료 유예 기간이 시작되는 즉시 엔드포인트 목록에서 파드를 제거하므로 느리게 종료되는 파드는 트래픽 제공을 유지할 수 없다. kubectl describe를 사용해 삭제하려는 파드를 확인하면 해당 파드는 "Terminating"으로 표시된다.- 파드가 실행 중인 노드에서 kubelet이 파드가 "Terminating"으로 표시됨을 확인하는 즉시 (= 정상적인 종료 기간이 설정됨) kubelet은 로컬 파드의 종료 프로세스를 시작한다.
- kubelet이 정상 종료를 시작하는 동시에, 컨트롤 플레인(마스터 노드)은 구성된 셀렉터가 있는 서비스를 나타내는 엔드포인트 오브젝트에서 종료된 파드를 제거한다.
👉 이후 ReplicaSet과 기타 workload 리소스는 종료된 파드를 유효한 서비스 내 복제본으로 취급하지 않는다. - 유예 기간이 만료되면 kubelet은 강제 종료를 트리거한다.
- kubelet은 유예 기간을 0 (즉시 삭제)으로 설정하여, API 서버에서 파드 오브젝트의 강제 삭제를 트리거한다.
👉 API 서버가 파드의 API 오브젝트를 삭제하면, 더 이상 클라이언트에서 통신 할 수 없다.
❗️ NOTE 강제 파드 종료
유예 기간을 0 으로 즉시 설정(강제)하면 API 서버에서 파드가 삭제된다. 이 때 파드가 노드에서 계속 실행 중인 경우, 강제 삭제는 kubelet을 트리거하여 즉시 정리를 시작한다.강제 삭제가 수행되면 API 서버는 실행 중인 노드에서 파드가 종료되었다는 kubelet의 확인을 기다리지 않는다.
실패한 파드의 가비지 콜렉션
실패한 파드의 경우, API 오브젝트는 사람이나 컨트롤러 프로세스가 명시적으로 파드를 제거할 때까지 클러스터의 API에 남아있다.
컨트롤 플레인은 파드 수가 구성된 임계값을 초과할 때 종료된 파드(Succeeded 또는 Failed 단계 포함)를 정리한다. 이렇게 하면 시간이 지남에 따라 파드가 생성되고 종료될 때 리소스 유출이 방지된다.
초기화 컨테이너
초기화 컨테이너는 파드의 앱 컨테이너들이 실행되기 전에 실행되는 특수한 컨테이너이며, 앱 이미지에는 없는 유틸리티 또는 설정 스크립트 등을 포함할 수 있다.
초기화 컨테이너는 containers 배열 (앱 컨테이너를 기술하는)과 나란히 파드 스펙에 명시할 수 있다.
개념
초기화 컨테이너는 파드에 하나 이상 포함될 수 있다.
일반적인 컨테이너와 다른 큰 특징으로는
- 초기화 컨테이너는 항상 완료를 목표로 실행된다.
- 각 초기화 컨테이너는 다음 초기화 컨테이너가 시작되기 전에 성공적으로 완료되어야 한다.
초기화 컨테이너는 성공할 때 까지 반복적으로 재시작하려고 시도한다. 하지만, 파드의 restartPolicy를 Never로 설정한 경우에는 초기화 컨테이너 실패는 전체 파드 실패로 인식된다.
파드 spec에 containers 배열과 같은 depth에 initContainers 필드를 추가하면 초기화 컨테이너로 지정된다.
✔️ 일반적인 컨테이너와 차이점
앱 컨테이너의 리소스 limit, volume, 보안 세팅을 포함한 모든 필드와 기능이 지원되나 초기화 컨테이너를 위한 리소스 요청량과 limit는 일반 컨테이너와 다르게 처리된다.
- 모든 컨테이너에 정의된 특정 리소스 요청량 또는 상한 중 가장 높은 것은 유효한 초기화 요청량/상한이다.
- 리소스를 위한 파드의 유효한 초기화 요청량/상한은 다음보다 높다.
- 모든 앱 컨테이너의 리소스에 대한 요청량/상한의 합계
- 리로스에 대한 유효한 초기화 요청량/상한
- 스케줄링은 유효한 요청/상한에 따라 이루어진다.
즉, 초기화 컨테이너는 파드의 전체 라이프사이클에서 사용되지 않는 초기화를 위한 리소스를 예약할 수 있다. - 파드의 유효한 QoS(서비스 품질) 계층은 초기화 컨테이너들과 앱 컨테이너들의 QoS 계층은 같다.
파드가 준비되기 전에 완료되는 것을 목표로 하기 때문에 lifecycle, livenessProbe, readinessProbe, startupProbe를 지원하지 않는다.
다수의 초기화 컨테이너가 파드에 지정되어 있는 경우,
- kubelet은 해당 초기화 컨테이너들을 한 번에 하나씩 실행한다.
- 각 초기화 컨테이너들은 다음 컨테이너 실행 전에 꼭 성공해야된다.
- 모든 초기화 컨테이너들이 실행 완료되었을 때, 파드의 어플리케이션 컨테이너들을 초기화하고 실행시킨다.
Example :
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]위의 파드는 두 개의 초기화 컨테이너를 가진다.
첫 번 째 컨테이너는 myservice를 기다리고, 두 번 째 컨테이너는 mydb를 기다린다. 이 두 컨테이너들이 완료되면 파드가 시작될 것이다.
자세한 동작
- 파드 시작 시, kubelet은 네트워크와 스토리지가 준비될 때까지 초기화 컨테이너의 실행을 지연시킨다.
- kubelet은 파드 사양에 나와있는 순서대로 파드의 초기화 컨테이너를 실행한다.
- 초기화 컨테이너의 시작이 실패되면 초기화 컨테이너는 파드의
restartPolicy에 따라서 재시도된다. - 파드는 모든 컨테이너가 성공되기 전까지
Ready될 수 없다. - 만약 파드가 재시작되었다면, 모든 초기화 컨테이너는 반드시 다시 실행된다.
- 초기화 컨테이너 이미지 필드를 변경하는 것은 파드를 재시작 하는 것과 같다.
- 초기화 컨테이너는 재시작, 재시도, 재실행 될 수 있기 때문에 초기화 컨테이너 코드는 멱등성을 유지해야한다.
- 파드 내의 각 앱과 초기화 컨테이너의 이름은 유일해야한다.
파드 재시작 이유
- 사용자가 초기화 컨테이너 이미지의 변경을 일으키는 파드 스펙(InitContainer) 업데이트를 수행
- 앱 컨테이너 이미지의 변경은 앱 컨테이너만 재시작시킨다.
- 파드 인프라스트럭처 컨테이너가 재시작
- root 접근 권한을 가진 누군가에 의해 강제 수행됐을 것
- 파드 내의 모든 컨테이너들이
restartPolicy가Always로 설정(재시작을 강제)되어있고 종료되었으며 초기화 컨테이너의 완료 기록이 가비지 수집에 의해 유실된 경우
파드 토폴로지 분배 제약 조건
토폴로지란? 컴퓨터 네트워크의 요소들(링크, 노드 등)을 물리적으로 연결해 놓은 것, 또는 그 연결 방식을 말한다.
사용자는 토폴로지 분배 제약 조건을 사용해서 지역, 영역, 노드, 기타 사용자정의 토폴로지 도메인같은 failure-domains 간에 파드가 분산되는 방식을 제어할 수 있다.
필수 구성 요소
✔️ node label
각 노드가 속한 토폴로지 도메인들은 노드 라벨을 통해 인식된다.
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB 위와 같은 노드가 있다면 클러스터는 논리적으로 다음처럼 보인다.

라벨은 수동으로 적용할 수 있으나, 대부분의 클러스트에서 자동으로 채워지는 Well-Known Labels을 재사용할 수도 있다.
파드의 분배 제약 조건
✔️ API
API 필드인 pod.spec.topologySpreadConstraints는 다음과 같이 정의된다.
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnstisfiable: <string>
labelSelector: <object>topologySpreadConstraints 정의를 통해 kube-scheduler에게 새로 생성되는 각 파드를 기존 파드와 어떻게 연관지어 배치할지 알려줄 수 있다.
- maxSkew : 파드가 균등하지 않게 분산될 수 있는 정도
- topologyKey : 노드 라벨의 키
- whenUnsatisfiable : 분산 제약 조건을 만족하지 않은 경우에 처리하는 방법
DoNotSchedule(default) : 스케줄링을 하지 않는다.ScheduleAnyway: skew를 최소화하는 노드에 높은 우선 순위를 부여하고 스케줄링을 계속하도록 한다.
- labelSelector : 일치하는 파드를 찾는데 사용된다.
Example :
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone #"zone:<any value>" 라벨 쌍을 포함하는 노드에 대해서만 균등 분배를 적용한다.
whenUnsatisfiable: DoNotSchedule # 새로 시작되는 파드가 제약 조건을 만족시키지 못하는 경우 스케줄러는 pending 상태를 유지한다.
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1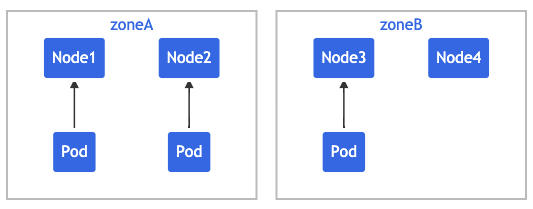
기존 파드가 위와같이 위치한다고 가정한다.
maxSkew: 1 이므로 신규 파드가 "zoneA"에 배치된다면 파드 분포가 [3,1]이 되어 skew가 2가되므로 "zoneB"에 배치될 것이다.
topologyKey: zone 이므로 파드는 node가 아닌 zone을 기준이오 분산되므로, Node3 또는 Node4에 배치 될 수 있다. 👉 만약 topologyKey: zone을 node로 변경하면 maxSkew: 1을 node 에서 판단하기 때문에 Node1, Node2, Node4 중 하나에 배치될 것이다.
Example :
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: k8s.gcr.io/pause:3.1위와 같이 작성할 경우 zone, node의 maxSkew 를 충족하기 위해 Node4에 배치할 수 밖에 없다.
❗️ 규칙
- 신규 파드와 같은 네임스페이스를 가진 파드만이 매칭 후보가 된다.
topologySpreadConstraints[*].topologyKey가 없는 노드는 무시된다.- 즉, maxSkew 계산에 영향을 미치지 않는다.
- 신규 파드는 이런 종류의 노드에 스케줄될 기회가 없다.
- 신규 파드에
spec.nodeSelector또는spec.affinity.nodeAffinity가 정의되어 있으면, 일치하지 않는 노드는 무시하게 된다.
클러스터 수준의 기본 제약 조건
기본 토폴로지 분배 제약 조건을 설정할 수 있으나, 다음과 같은 경우에만 파드에 적용된다.
.spec.topologySpreadConstraints에 어떤 제약 사항도 정의되어 있지 않은 경우- Service, ReplicationController, ReplicaSet, StatefulSet 중 하나에 속한 경우
이는 Scheduling Profile에서 PodTopologySpread 플러그인의 일부로써 설정할 수 있다.
단, labelSelector는 비어있어야 한다는 제약조건이 있으며 그 외에는 위에서 설명했던 파드의 분배 제약 조건과 동일하게 사용한다.
👉 그렇담 selector가 어떻게 작동되는지 의아할텐데, 파드가 속한 Service, ReplicationController, ReplicaSet, StatefulSet에서 계산된다.
Example :
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List❗️ NOTE
기본 스케줄링 제약 조건에 의해 생성된 Skew는 SelectorSpread Plugin에 의해 생성된 Skew와 충돌 할 수 있다.
따라서 PodTopologySpread에 대한 기본 제약 조건을 사용할 때는 Scheduling Profile에서 SelectorSpread을 비활성화 하는 것을 권장한다.
PodAffinity vs. PodAntiAffinity
Affinity : 유연
"Affinity"와 관련된 지시문은 파드를 더 모으거나, 분산시키는 등의 스케줄링 방법을 제어한다.
- PodAffinity : 자격이 충족되는 topology domain에 사용자가 원하는 만큼의 파드를 얼마든지 채울 수 있다.
- PodAntiAffinity : 단일 topoloy domain에는 단 하나의 파드만 스케줄링 될 수 있다.
자세한 내용은 Motivation에서 알아본다.
