ref. https://esbook.kimjmin.net/
위 링크의 내용을 요약, 정리합니다.
서문
- Full-text search engine으로 처음 개발되었지만, ES는 검색엔진을 넘어 보안, 로그분석, 전문(Full-text)분석 등 다양한 영역에서 중요한 역할을 하고 있다.
- Kibana, Logstash, Beats들과 함께 사용하며 다양한 문제들을 해결하고 있다.
- 유닉스 시스템과 자바에 대한 기초 지식이 필요하다.
역사
- 요리 레시피 검색 프로그램을 만들겠다. → 2004년 오픈소스 검색엔진 Compass로 출발
- Apache Lucene이 가진 한계를 보완 → 새로운 검색엔진을 만들기 위한 프로젝트를 시작
- 2010년 Compass에서 Elasticsearch라는 이름으로 변경하고 오픈소스로 공개.
- Logstash, Kibana와 함께 사용되며 한동안 ELK Stack(ES, Logstash, Kibana)이라고 이름으로 불렸으나 2013년 Logstash, Kibana 프로젝트를 정식으로 흡수한다.
- 2015년 회사명을 Elasticsearch에서 Elastic으로 변경, ELK Stack 대신 Elastic Stack으로 정식 명명
❗️ NOTE
루씬(Lucene)은 자바 언어로 이루어진 정보 검색 라이브러리 자유-오픈 소스 소프트웨어이다. 아파치 소프트 웨어 재단에 의해 지원되며, 아파치 라이선스 하에 배포된다.Full text 색인 및 검색 기능을 필요로 하는 모든 응용 프로그램에 적합하지만 웹 검색 엔진 및 로컬 단일 사이트 검색 구현에서의 유용성으로 널리 알려져 있다.
Elastic Stack
ref. Elastic Stack 이란?
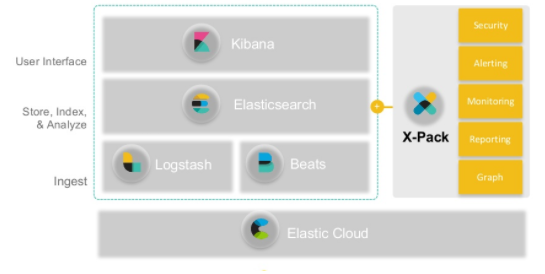
Elastic Search + Logstach + Kibana를 묶어 ELK(ELK Stack)라는 서비스명으로 제공했으나 5.0.0 버전부터 Beats가 포함되며 Elastic Stack이란 이름으로 서비스가 제공되고 있다.
서버로부터 모든 유형의 원하는 데이터를 가져와 실시간으로 해당 데이터를 검색, 분석 및 시작화 할 수 있도록 도와주는 Elastic의 오픈소스 서비스 제품.
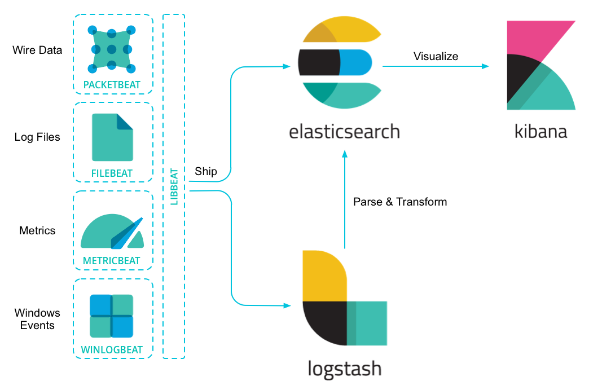
(Elastic Stack의 Flow)
🔎 Elastic Search
루씬(Apache Lucene) 기반의 Full Text로 검색이 가능한 오픈소스 분석엔진. 주로 REST API를 이용해 처리한다. 대량의 데이터를 신속하게 (거의 실시간으로) 저장, 검색, 분석 할 수 있다.
🔎 Logstash
플러그인을 이용해 데이터 집계와 보관, 서버 데이터 처리를 담당한다. 파이프라인으로 데이터를 수집해 필터를 통해 변환 후 Elastic Search로 전송한다.
- 입력 : Beats, CloudWatch, Eventlog 등의 다양한 입력을 지원, 데이터 수집
- 필터 : 형식이나 복잡성에 상관없이 설정을 통해 데이터를 동적으로 변환
- 출력 : ES, Email, ECS, kafka 등 원하는 저장소에 데이터를 전송
🔎 Kibana
데이터를 시각화해주는 도구
🔎 Beats
경량 에이전트로 설치. 데이터를 Logstash또는 ES로 전송하는 도구로써 Logstash보다 경량화되어 있는 서비스이다. Filebeat, Metricbeat, Packetbeat, Winlogbeat, Heartbeat 등이 있으며 Libbeat을 이용하여 직접 구축도 가능하다.
Elasticsearch
- 모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행
- 결과를 클라이언트나 다른 프로그램으로 전달하여 동작하게 한다.
- 기존 RDB 시스템에서 다루기 어려운 Full-text search 기능을 포함
- 점수 기반의 다양한 정확도 알고리즘, 실시간 분석 등의 구현이 가능
- 플러그인을 사용한 기능 확장이 가능
- AWS, MS Azure와 같은 클라우드 서비스, Hadoop 플랫폼들과의 연동도 가능
특징
오픈소스
Elastic Stack의 깃헙 레파지토리에서 소스들을 찾을 수 있다.
아파치 루씬이 자바로 만들어졌으므로 ES 또한 자바로 코딩이 되어있다.
실시간 분석
하둡 시스템과 달리 ES 클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력 (indexing)되고, 동시에 실시간에 가까운 속도로 색인된 데이터의 검색, 집계가 가능하다.
❗️ NOTE
Vs. Hadoop
배치 기반 분석 시스템.
분석에 사용될 소스 데이터, 분석을 수행할 프로그램을 올려 놓고 분석을 실행하여 결과셋이 나오도록하는 하나의 루틴으로 실행된다.
Full text(전문) 검색 엔진
Lucene은 기본적으로 역파일 색인(inverted file index) 구조로 데이터를 저장하며 이를 사용하는 ES 또한 동일한 방식으로 저장하여 텍스트를 검색한다. 이런 특성을 Full text search라고 한다.
내부적으로 역파일 색인일지라도 사용자 관점에서는 JSON 형식으로 데이터를 전달한다. 질의에 사용되는 쿼리문이나 쿼리에 대한 결과도 모두 JSON 형식으로 전달/반환된다.
key-value 형식이 아닌 문서 기반으로 되어 있으므로 복합적인 정보를 포함해도 그대로 저장이 가능하여 직관적이다.
RESTFul API
Rest API를 기본으로 지원하며 모든 데이터 조회, 입력 삭제를 http 프로토콜을 통해 Rest API로 처리한다.
multitenancy
ES의 데이터들은 index라는 논리 집합 단위로 구성되며 서로 다른 저장소에 분산-저장된다. 서로 다른 인덱스들을 별도의 커넥션 없이 하나의 쿼리로 묶어서 검색, 하나의 출력으로 결과를 도출하는데 이런 특징을 멀티테넌시라고 한다.
Logstash
- ES와 별개로 데이터 수집 및 저장을 위해 개발된 프로젝트
- Logstash가 출력 API로 ES를 지원하기 시작 → 데이터 수집을 위한 도구로 Logstash를 ES의 입력 수단으로 사용하기 시작
- Logstash가 Elastic에 정식으로 합류하며 하나의 스택으로 출범
- JRuby-루비 코드로 개발돼 자바 런타임 버신 위에서 돌아간다.
- Logstash의 데이터 처리 : 입력 → 필터 → 출력
- 입력 : 데이터 저장소에서 데이터 입력받음
- 필터 : 데이터 확장, 변경, 필터링, 삭제 등 가공
- 출력 : 데이터를 데이터 저장소로 전송
- ES와 상관없이 독자적으로 사용도 가능
Kibana
- ES와 연동되는 시각화 도구
- 검색 및 aggregation의 집계 기능을 이용해 ES로부터 문서, 집계 결과 등을 가져와 웹도구로 시각화한다.
- Discover, Visualize, Dashboard 3개의 기본 메뉴와 다양한 App 들로 구성되어 있고, 플러그인을 통해 App의 설치가 가능
Beats
- Logstash의 다양한 기능 때문에 프로그램 부피가 컸고 많은 자원이 요구됨 → ES 클러스터로의 대용량 데이터 전송은 여러 소스를 통했으므로 모든 단말 시스템에 Logstash를 설치하는 것은 부담이 컸음
- 네트워크 패킷을 스니핑해 ES에 저장하고 Kibana로 모니터링 하는 시스템이 오픈 소스로 공개됨 → Elastic에서 개발중이던 Logstash 원격 수집기 프로젝트 대신 Beats를 프로젝트에 투입시킴
- Go 언어로 개발
- Go : 구글에서 개발, 바이너리 실행파일로 컴파일되어 라이브러리 종속성이 낮은 경량의 언어.
- 현재 Elastic 에서는 Packetbeat, Libbeat, Filebeat, Metricbeat, Winlogbeat, Auditbeat 등을 개발하여 배포하고 있으며 전 세계 오픈소스 개발자들로부터 50여가지 이상의 Beats 들이 개발되고 있다.
Elasticsearch 시작하기
데이터 색인
중요한 개념의 용어 정리
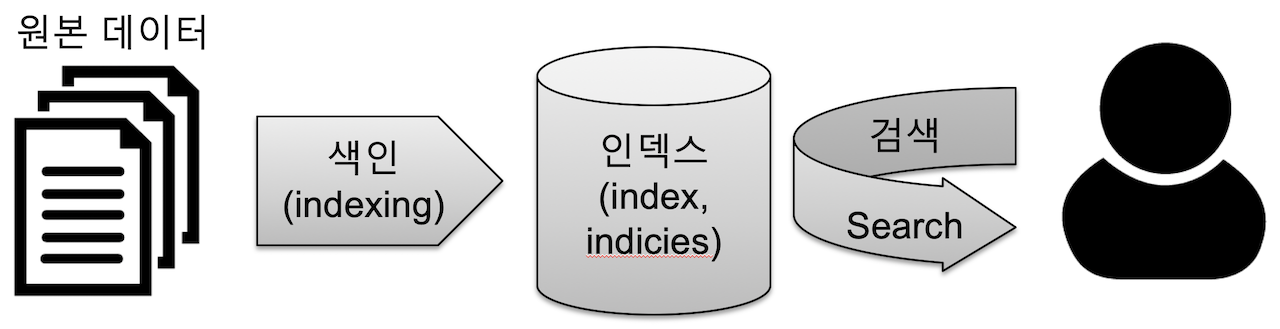
- [동사] 색인(indexing)
데이터를 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환하여 저장하는 일련의 과정. = 색인, 색 과정 - [명사] 인덱스(index, indices)
색인 과정을 거친 결과물 or 색인된 데이터가 저장되는 저장소
ES에서는 도큐먼트들의 논리적인 집합을 표현하는 단위 - 검색(search)
인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정 - 질의(query)
사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 사용하는 검색어 or 검색 조건
설치
자세한 내용은 아래 링크에서 확인 할 수 있다.
ref. https://esbook.kimjmin.net/02-install/2.2/2.2.1-download-install
$> bin/elasticsearch -d : 백그라운드 실행
$> ps -ef | grep elasticsearch : 실행중인 프로세스 검색
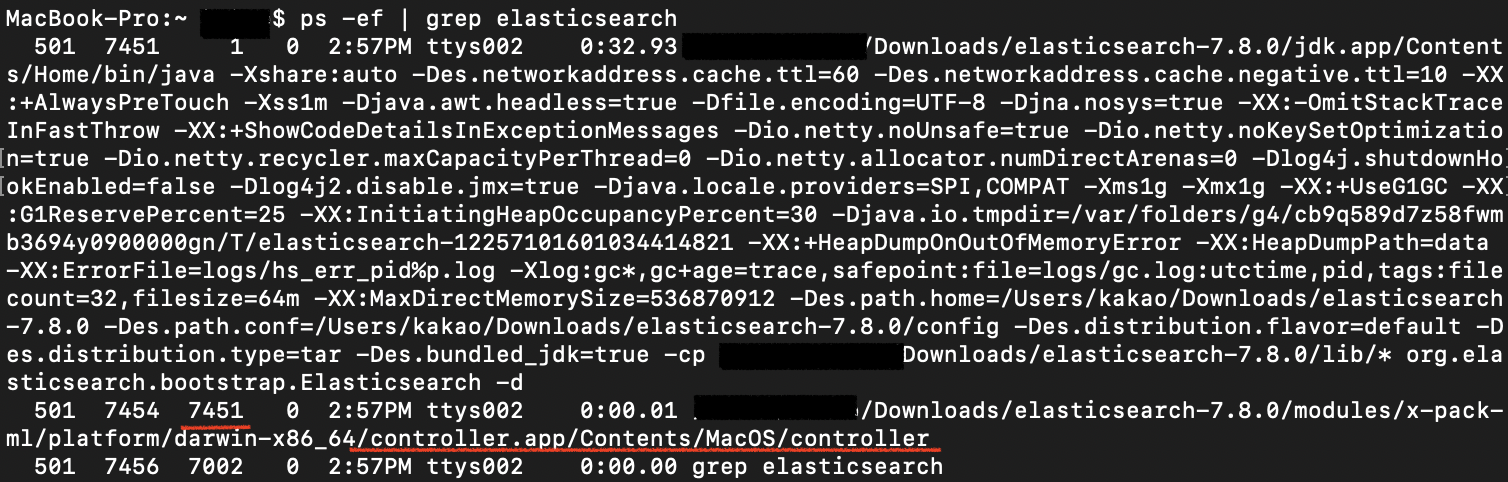
controller → 실행 중인 ES 프로세스
$> kill 7451 : 백그라운드로 실행중인 ES 종료
환경 설정
ES는 각 노드별로 실행될 설정을 적용 → 노드의 역할을 분리하고 클러스터의 속성을 결정한다.
ES의 실행 환경을 설정하는 3가지 방법
- 홈 디렉토리의 config 경로 아래 파일들을 변경
- 시작 명령으로 설정하는 방법
- ES를 처음 실행할 때 -E 커맨드 라인 명령어를 사용
🔎 jvm.options
Java와 관련된 환경변수 대부분을 설정
🔎 elasticsearch.yml
elasticsearch 실행 환경에 대한 실제 설정
YAML 문법으로 설정하므로 작성시 들여쓰기에 유의하도록 하자.
$> cat elasticsearch.yml
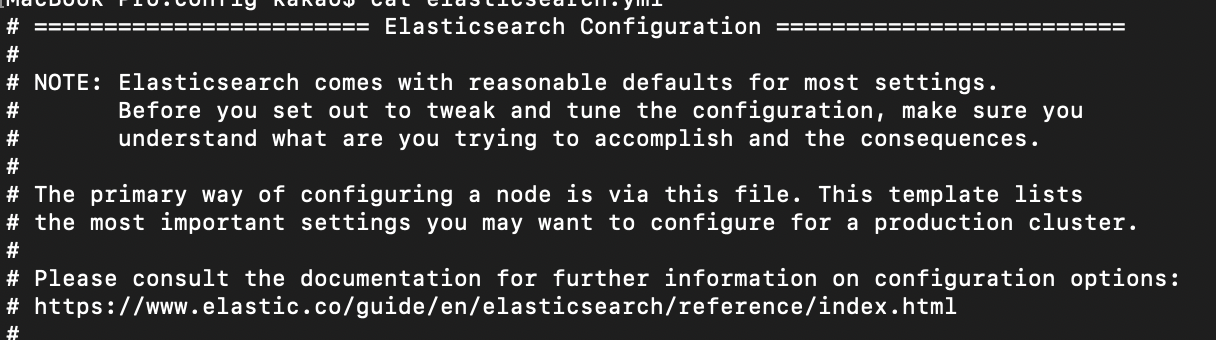
Elasticsearch는 대부분의 설정에 대해 적절한 기본값을 제공한다. 구성을 조정하기 전에 수행하려는 작업과 그에 따른 결과를 반드시 이해해야하고 있어야한다.
이 파일을 통해 기본적으로 노드를 구성 할 수 있다. 이 템플릿에는 프로덕션 클러스터를 구성하는데 있어 가장 중요한 설정이 나열되어 있다.
| 설정값 | 설명 |
|---|---|
| cluster.name:"<클러스터명>" | ES의 노드들은 클러스터명이 동일하면 같은 클러스터로 묶이고 그렇지 않으면 물리장비나 네트워크 구성과 상관없이 서로 다른 클러스터로 바인딩된다. 충돌 방지를 위해 클러스터명은 반드시 고유한 이름으로 설정하도록 한다. |
| node.name:"<노드명>" | 노드 이름으로 실행 중인 각 ES 노드들을 구분할 수 있다. |
| node.attr.<key>: "<value>" | 노드별 속성 부여를 위한 네임스페이스를 지정한다. |
| path.data: ["<경로>"] | 색인된 데이터를 저장하는 결로를 지정한다. 배열 형태로 여러개의 경로값의 입력이 가능 |
| path.logs: "<경로>" | ES 실행로그를 저장하는 경로를 지정한다. |
| bootstrap.memory_lock: true | ES가 사용중인 힙메모리 영역을 다른 자바 프로그램이 간섭 못하도록 점유한다. 항상 ture를 권장함. |
| network.host: <ip 주소> | ES가 실행되는 서버의 ip 주소. default= loopback(127.0.0.1), 주석처리 or 루프백인 경우 개발 모드로 실행, 실제 IP 주소로 변경 시 운영모드로 실행된다. |
| http.port: <포트 번호> | 클라이언트와 통신하기 위한 http 포트, default=9200 |
| transport.port: <포트 번호> | 노드들끼리 통신하기 위한 tcp 포트, default=9300 |
| discovery.seed_hosts: [ "<호스트-1>", "<호스트-2>", ... ] | 클러스터 구성을 위해 바인딩할 원격 노드의 IP 또는 도메인 주소를 배열형태로 입력한다. |
| cluster.initial_master_nodes: [ "<노드-1>", "<노드-2>" ] | 클러스터가 최초 실행 될 때 명시된 노드들을 대상으로 마스터 노드를 선출한다. |
❗️ NOTE
디스커버리 : 원격에 있는 노드들을 찾아 바인딩하는 과정
마스터 노드 : 인덱스의 메타데이터, 샤드의 위치와 같은 클러스터 상태 정보를 관리하는 노드, 모든 클러스터는 1개의 마스터 노드가 존재하며 이 노드가 다운되거나 끊어진 경우 마스터 후보 노드 중 새로운 마스터 노드가 선출된다.
🔎 노드의 역할 : master, data, ingest, ml
각자의 노드들이 서로 다른 역할들을 수행하도록 클러스터를 구성할 수 있다. 모든 디폴트 값은 true이다.
모든 설정을 false로 할 경우 오직 클라이언트와 통신만 하는 역할로 사용이 가능하다. (이런 노드를 coordinate only node라고 부른다.)
🔎 커맨드 라인 설정
ES 실행 시 커맨드 명령에 -E <옵션>=<값> 을 이용해 환경 설정이 가능하다.
❗️ NOTE
환경 설정이 elasticsearch.yml과 커맨드 명령 -E에 모두 있는 경우에는 -E 커맨드 명령에서 한 설정이 더 우선해서 적용된다.
Elasticsearch 시스템 구조
대용량 데이터의 증가에 따른 스케일 아웃과 데이터 무결성을 유지하기 위한 클러스터링을 지원한다. 항상 클러스터를 기본으로 동작하며 1개의 노드만 있어도 클러스터로 구성된다.
클러스터 구성
여러 서버에 하나의 클러스터로 실행
- http 포트 (9200~9299) : 클라이언트와의 통신
- tcp 포트 (9300~9399) : 노드간 데이터 교환
일반적으로 1개의 물리 서버당 하나의 노드를 실행할 것을 권장한다.
하나의 물리 서버에 여러개의 노드를 실행하는 경우, 각 노드들은 차례대로 9200, 9201, .. 순으로 포트를 사용하게 된다.
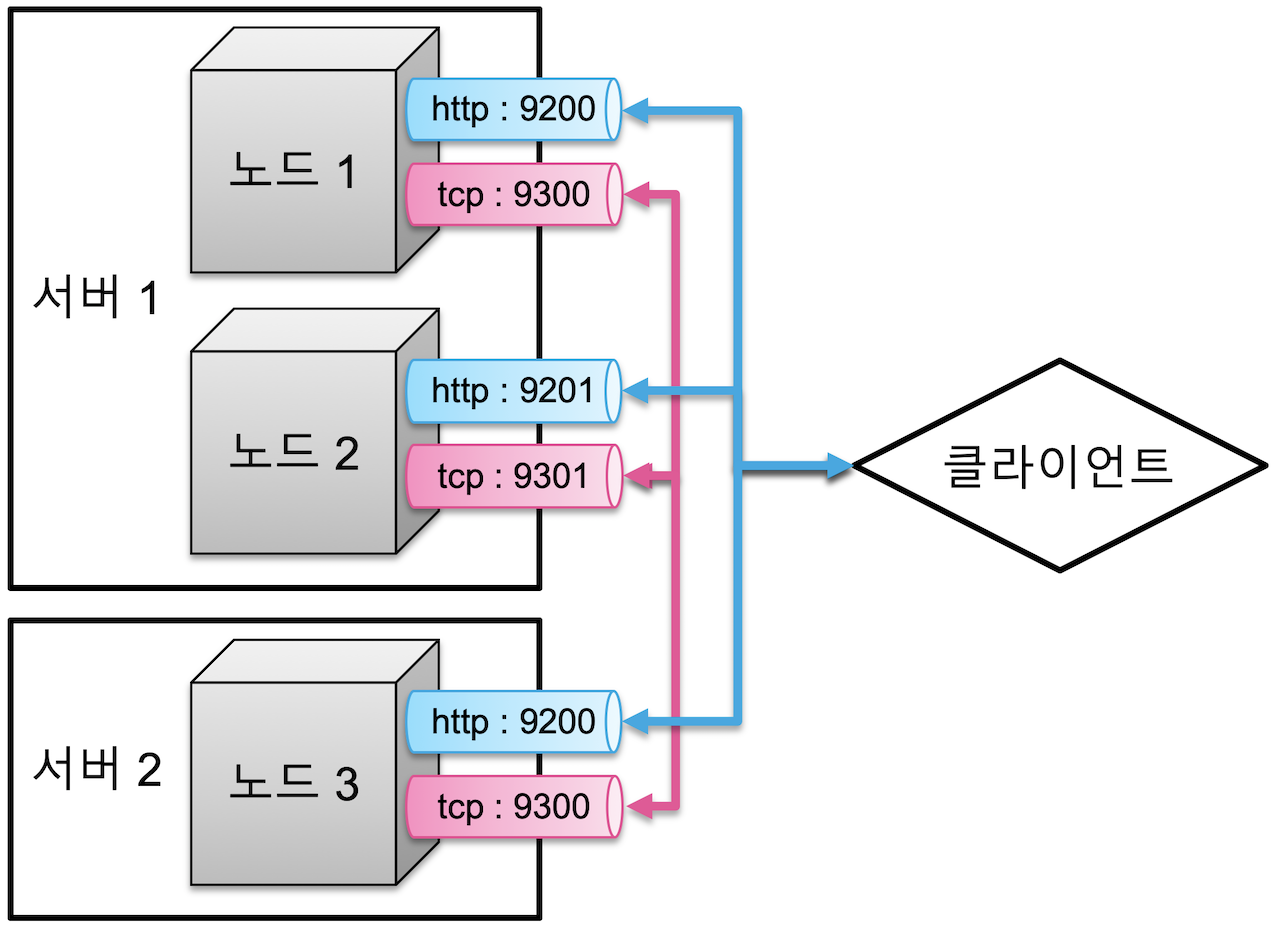
물리적인 구성과 상관 없이 여러 노드가 하나의 클러스터로 묶이기 위해선 cluster.name 설정이 묶여질 노드들 모두 동일해야 한다.
하나의 서버에서 여러 클러스터 실행
❗️ NOTE
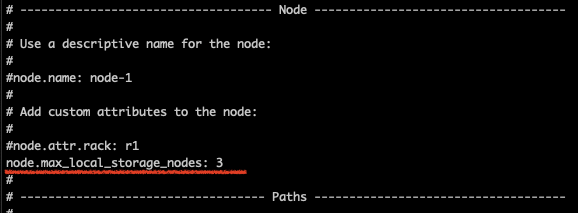
로컬에 여러 터미널을 띄워서 노드를 실행 시킬 때java.lang.IllegalStateException: failed to obtain node locks, tried [[/Users/kakao/Downloads/elasticsearch-7.8.0/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?라는 에러가 뜰 수 있다.하나의 서버에서 하나의 노드만 실행하는 것이 권장사항인 만큼 기본 설정이 노드 1개로 고정되어 있는 듯 하다. 🤔
앞에서 살펴보았던
config/elasticsearch.yml에서node.max_local_storage_nodes: 3를 추가해주자.
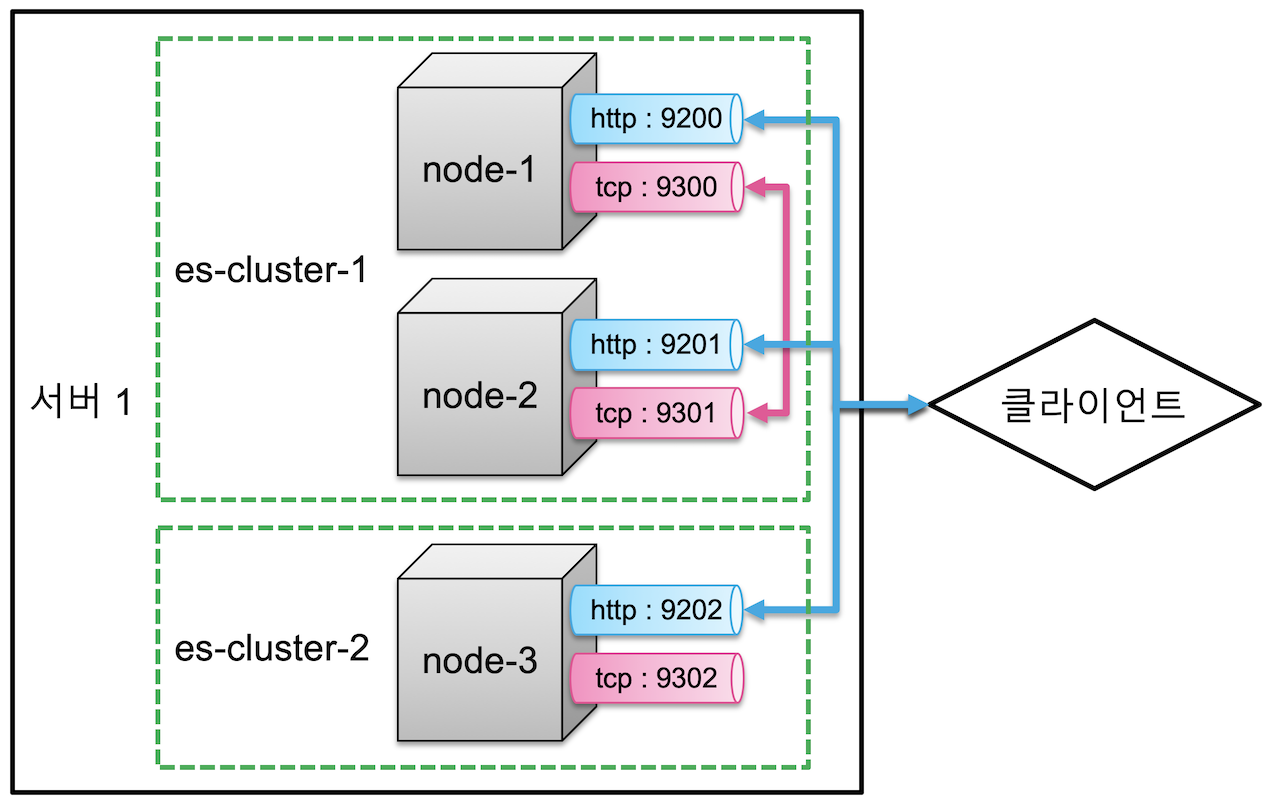
https://esbook.kimjmin.net/03-cluster/3.1-cluster-settings 를 따라가면 아래 구조로 클러스터가 만들어 질 것이다.
디스커버리
노드가 처음 실행할 때 하나의 클러스터로 바인딩하는 과정을 디스커버리라고 한다.
디스커버리는 다음과 같은 순서로 이루어진다.
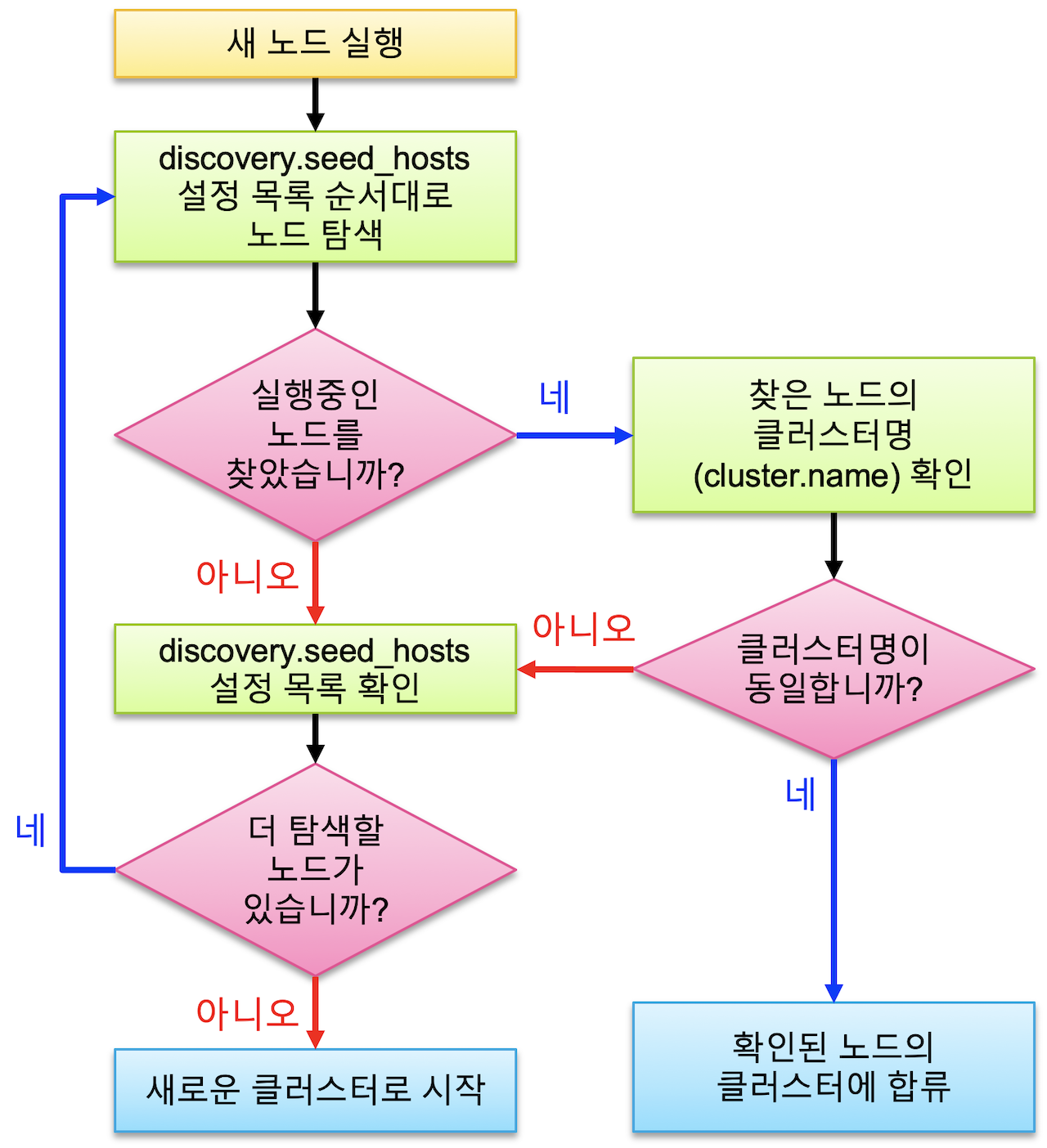
❗️ NOTE
클러스터에 노드가 무수히 많아도 보통discovery.seed_hosts에 "처음에 탐색할 노드 3~5개 정도만" 설정하면 큰 문제 없이 클러스터가 바인딩된다. 보통 마스터 후보 노드들을 지정하게 되며 처음 탐색하는 대상 노드는 반드시 먼저 가동중이어야 한다.
인덱스와 샤드
- 도큐먼트 : 단일 데이터 단위
- 인덱스 : 도큐먼트를 모아놓은 집합 (데이터 저장 단위인 인덱스는 인디시즈indices라고 표현하기도 한다.)
이 글에서는 데이터를 ES레 저장하는 행위는 색인, 도큐먼트의 집합 단위는 인덱스라고 칭한다.
- 샤드 : 인덱스가 분리되는 단위, 루씬의 단일 검색 인스턴스
인덱스는 샤드 단위로 분리되고 각 노드에 분산되어 저장된다. 하나의 인덱스가 5개의 샤드로 저장된 경우 다음과 같다.
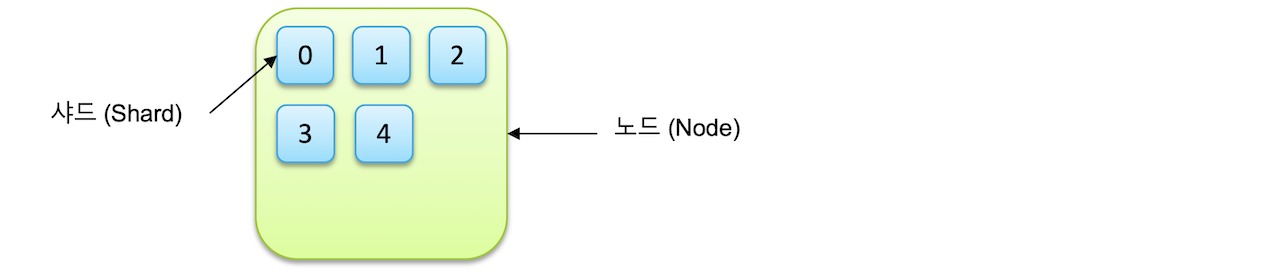
primary shard와 Replica
- 인덱스 생성시 별도의 설정을 하지 않으면 7.0 버전부터는 디폴트로 1개의 샤드(프라이머리 샤드)로 인덱스가 구성된다.
- 클러스터에 노드 추가 → 샤드들이 각 노드로 분산, 디폴트로 1개의 복제본(리플리카)을 생성
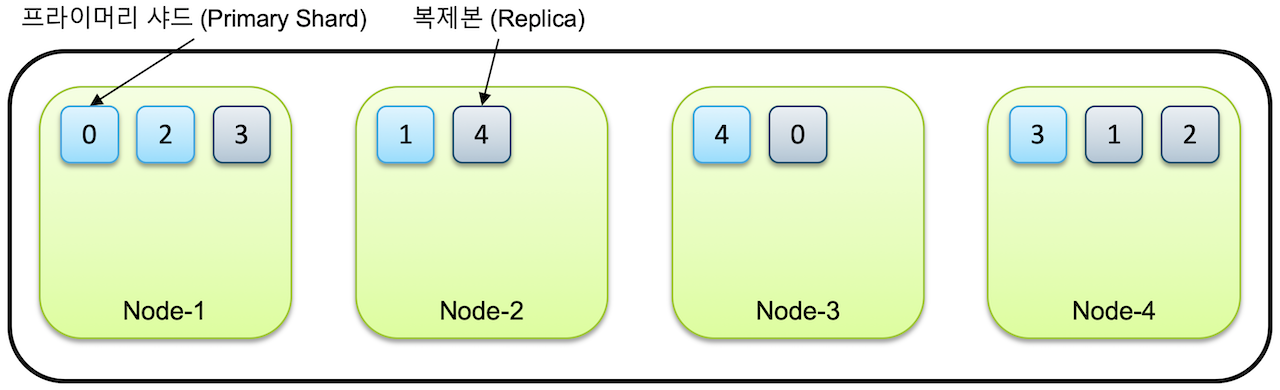
한 인덱스가 5개의 샤드로 구성되고 클러스터가 4개의 노드로 구성된 경우 → 5개의 프라이머리 샤드와 5개의 복제본 → 총 10개의 샤드가 전체 노드에 골고루 분산되어 저장
같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장된다.
❗️ NOTE
노드가 1개만 있는 경우 프라이머리 샤드만 존재하고 복제본은 생성되지 않는다. ES는 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것을 권장한다.
특정 노드가 유실된 경우 클러스터는 (1) 유실된 노드가 복구되길 기다렸다가 (2) 타임아웃이 된 경우 1개만 남은 샤드를 복제한다. 이 때, 프라이머리 샤드가 유실됐다면 남아있던 복제본이 프라이머리 샤드로 승격되고 다른 노드에 새로 복제본이 생성되는 것이다.
샤드 개수 설정
샤드의 개수는 인덱스를 처음 생성할 때 지정할 수 있다. 프라이머리 샤드 수는 인덱스를 재색인 하지 않는 이상 수정이 불가하며 복제본은 수정이 가능하다.
Master & Data Nodes
Master Node
- ES 클러스터는 하나 이상의 노드들로 이루어진다.
- 이 중에는 메타 데이터, 샤드의 위치 같은 클러스터 상태 정보를 관리하는 마스터 노드가 하나 존재한다.
- 1클러스터 1마스터 노드
- 마스터 노드가 없으면 클러스터 작동이 정지된다.
- 기본적으로 모든 노드가 마스터 노드로 선출 될 수 있는 마스터 후보 노드이다.
마스터 후보 노드는 마스터 노드의 정보를 처음부터 공유하므로 마스터 노드에 문제가 생기는 경우 즉시 그 역할을 수행할 수 있다. - 마스터 후보 노드는 최소 3개 이상의 홀수개로 설정해야한다.
Data Node
- 실제로 색인된 데이터를 저장하고 있는 노드
- 마스터 후보 노드에
node.data: false를 설정하면 마스터 노드 역할만 수행하고 데이터를 저장하지 않게 할 수 있다.
Split Brain
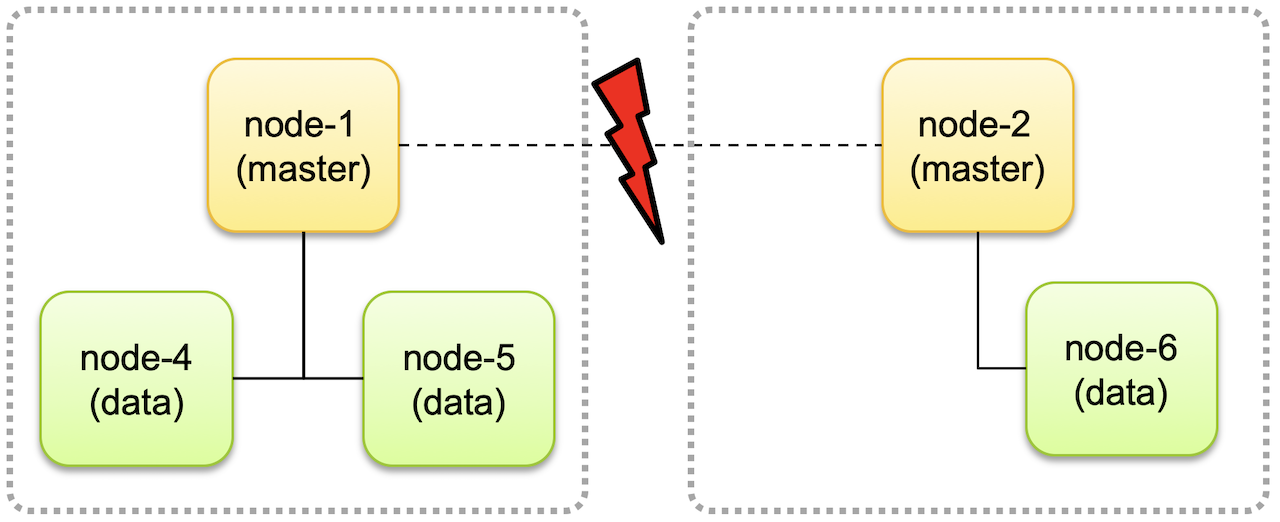
위와 같이 네트워크 단절로 마스터 후보 노드인 node-1과 node-2가 분리되면 각자가 서로 다른 클러스터로 구성돼 계속 동작하는 경우가 있다.
이 때 각 클러스터에서 데이터의 변동이 있는 경우 하나의 클러스터로 다시 합쳐 질 때 데이터 정합성, 무결성에서 문제를 일으킨다. 👉 Split Brain
이를 방지하기 위해 마스터 후보 노드를 최소 3개로 두고 클러스터에 마스터 후보 노드가 최소 2개 이상 존재하는 경우에만 클러스터가 동작하도록 해야한다.
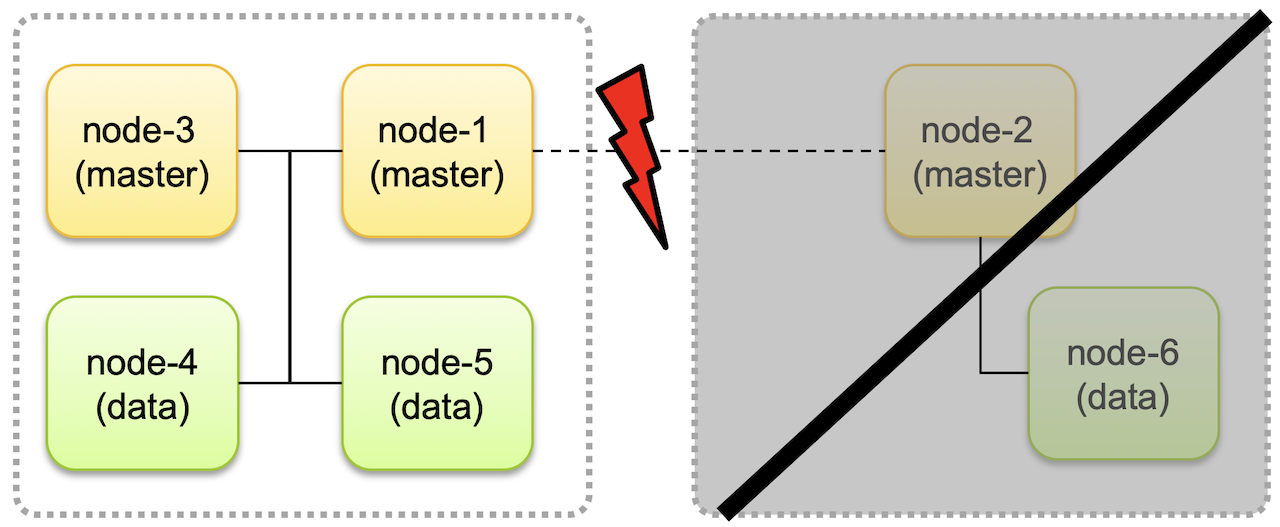
위와 같은 경우 클러스터 분리시 마스터노드가 1개인 클러스터(우측)은 동작을 멈춘다.
복구 될 시 node-4, node-5의 데이터 정보가 node-6로 업데이트 되므로 데이터 정합성에 문제가 없게된다.
마스터 후보 노드 개수는 항상 홀수로 하고, 가동을 위한 최소 마스터 후보 노드 설정은 (전체 마스터 후보 노드 개수)/2 + 1로 설정한다.
