ref. https://esbook.kimjmin.net/
위 링크의 내용을 요약, 정리합니다.
인덱스 설정과 매칭
인덱스 : 도큐먼트들이 모여있는 논리적인 데이터의 집합 📌
- 하나의 노드에만 존재하는 것 X 샤드 단위로 여러 노드에 걸쳐 저장
→ 데이터 무결성의 보장과 검색 성능의 향상 - 데이터의 저장 및 검색 방법에 대한 설정, 커스텀 애널라이저 같은 도구들은 인덱스 단위로 구분되어 저장
→ 즉, 한 인덱스에서 사용되는 설정이나 도구는 다른 인덱스에 영향 X
Setting
인덱스의 정보 단위 : settings, mappings
PUT <인덱스명> 으로 인덱스를 처음 생성한 뒤,
GET <인덱스명> 으로 조회하면 설정과 매핑 정보를 확인 할 수 있다.
GET <인덱스명>/_settings나 GET <인덱스명>/_mappings를 사용하면 해당 정보만 따로 볼 수 있다.
number_of_shards, number_of_replicas
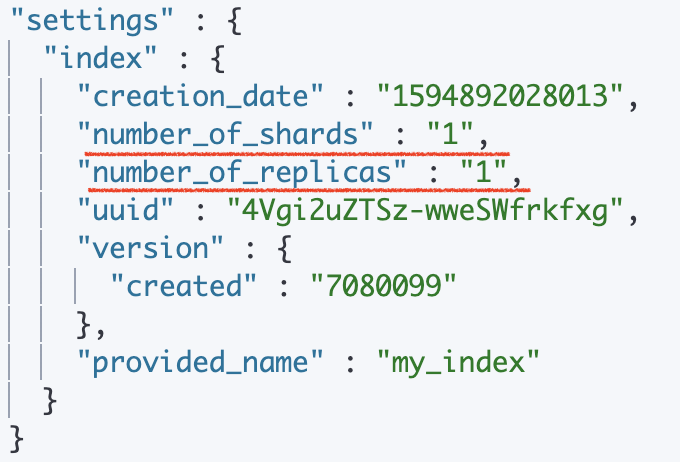
처음 인덱스를 정의하면 몇가지 정보들이 자동으로 생성된다. 샤드 수나 복제본 수는 settings 아래에 설정되는데 샤드수는 7.0부터 디폴트 1개로 설정된다.
인덱스를 생성할 때 설정을 추가하기 위해서는 "settings" 필드에 value를 추가해주면 되는데, 대부분의 설정이 "index" 아래 추가되기 때문에 "index" 레벨은 생략하고 입력해도 된다.
입력하는 방법
- "settings", "index"를 모두 명시하고 "index" 하위에 "number_of_shards"를 정의하기
- "settings" 하위에 "index.number_of_shards"와 같이
.를 이용해 정의하기 - "settings" 하위에 "number_of_shards"를 정의하기 (index 레벨 생략)
number_of_shards 설정은 인덱스를 처음 생성할 때 한 번 지정하면 바꿀 수 없다.
샤드 수를 바꾸려면 새로 인덱스를 정의하고 기존 인덱스의 데이터를 재색인 해야한다.
shrink API나 split API를 이용하는 방법이 있긴하다.
number_of_replicas 설정은 자유롭게 변경 가능하다.
PUT my_index/_settings
{
"number_of_replicas": 2
}refresh_interval
ES에서 세그먼트가 만들어지는 refresh 타임을 설정한다. default 1s
"settings"의 "index" 아래에 설정하며 number_of_replicas와 마찬가지로 자유롭게 설정 변경이 가능하다.
❗️ NOTE
엘라스틱 서치와 세그먼트
엘라스틱 서치는 위와 같이 데이터(document)를 엘라스틱 인덱스로 만든 뒤, 샤드로 분리하여 보관한다.
각 엘라스틱 서치 샤드는 루씬의 인덱스이기도 하다.
루씬은 새로운 데이터를 엘라스틱서치 인덱스에 저장할 때 세그먼트를 생성하는데, 루씬의 인덱스 조각인 이 세그먼트를 조합하여 저장한 데이터의 검색이 이뤄진다.
루씬은 순차적으로 세그먼트를 검색하므로 세그먼트 수가 많아지면 검색 속도도 느려진다.

루씬의 flush = 엘라스틱서치의 refresh
세그먼트 생성시 커널 시스템 개시에 세그먼트가 캐시돼 읽기가 가능해진다. refresh가 돼야 읽을 수 있는 상태가 된다. 즉, 인덱스를 새로고침 함으로써 새로 추가한 데이터의 검색이 가능해지는 것이다.
refresh 타임이 1초라면 ES 클러스에 존재하는 모든 샤드가 기본적으로 1초마다 한번씩 refresh 작업이 수행된다.
analyzer, tokenizer, filter
정의하는 기본 구조는 아래와 같다.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_flter": [ "...", "..." ... ]
"tokenizer": "...",
"filter": [ "...", "..." ... ]
}
},
"char_filter":{
"my_char_filter":{
"type": "…"
...
}
}
"tokenizer": {
"my_tokenizer":{
"type": "…"
...
}
},
"filter": {
"my_token_filter": {
"type": "…"
...
}
}
}
}
}"analysis": { } 내용은 한번 생성 후 변경이 불가하다.
이미 만들어진 인덱스에 애널라이저나 토크나이저 등을 추가하거나 사전을 변경하려면 인덱스를 먼저 _close 한 후 다시 _open 함으로써 적용할 수 있다.
Mappings
동적 매핑
미리 정의하지 않아도 인덱스에 도큐먼트를 새로 추가하면 자동으로 매핑이 생성된다.
{
"books" : {
"mappings" : {
"properties" : {
"author" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"category" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"pages" : {
"type" : "long"
},
"publish_date" : {
"type" : "date"
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
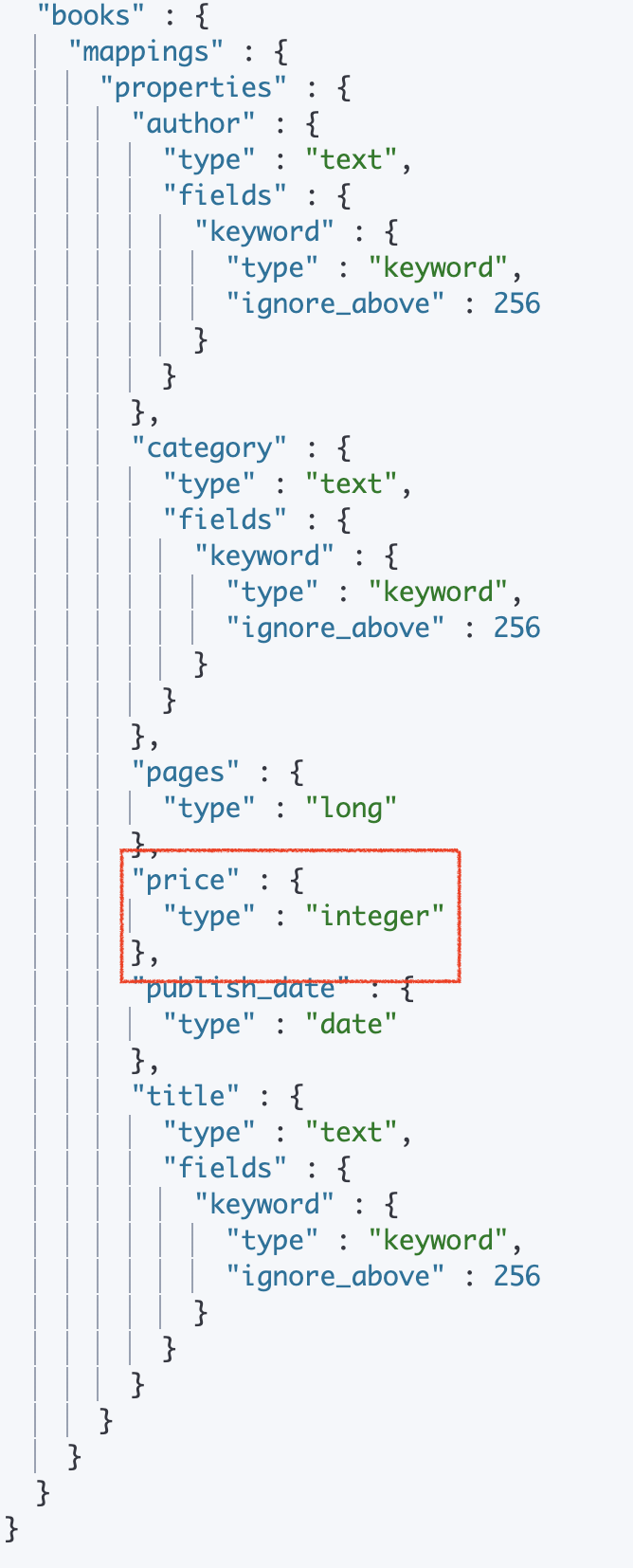
}- properties : 필드 지정
- 데이터 형식에 맞게 "type"이 자동 지정된다.
- 동적 생성 시 필드의 값을 보고 타입을 예상 → 가장 넓은 범위 형태의 데이터 타입을 선택
- "pages": 125 라는 필드를 입력하면 자연수를 저장하는 데이터 타입 중 가장 큰 long으로 지정된다.
- date 타입의 경우 JSON 도큐먼트에서 사용하는 ISO8601 표준 날짜 형식을 준수하면 date 타입으로 인식하나 다른 포맷일 경우 text타입으로 인식된다.
매핑 정의
데이터가 입력되어 자동으로 매핑이 생성되기 전에 미리 먼저 인덱스의 매핑을 정의하면 이에 맞춰 데이터가 입력된다.
PUT <인덱스명>
{
"mappings": {
"properties": {
"<필드명>":{
"type": "<필드 타입>"
… <필드 설정>
}
…
}
}
}단, 이미 만들어진 필드를 삭제하거나 필드 타입 및 설정을 변경하는 것은 불가능하다.
필드 변경이 필요한 경우 인덱스를 새로 정의하고, 기존 인덱스 값을 새 인덱스에 모두 마이그레이션해야한다.
이미 만들어진 매핑에 필드를 추가하는 것은 가능하다. (추가할 필드명이 기존 필드와 중복되면 오류 발생)
PUT <인덱스명>/_mapping
{
"properties": {
"<추가할 필드명>": {
"type": "<필드 타입>"
… <필드 설정>
}
}
}| 필드 추가 | 추가후 _mappings |
|---|---|
 |  |
❗️ 최상위 필드와 Object 타입의 내부 필드, 다중 필드도 추가 가능하다.
기존 매핑에 정의되지 않은 필드가 도큐먼트에 있으면 필드가 자동으로 추가된다.
문자열 - text, keyword
인덱스 생성 시 매핑에 필드를 미리 정의하지 않으면 동적 문자열 필드가 생성 될 때 text, keyword 필드가 다중 필드로 같이 생성된다.

🔎 text
- 입력된 문자열을 "텀 단위로 쪼개어" 역색인 구조를 만든다.
- 풀텍스트 검색에 사용할 문자열 필드들을 이 타입으로 지정한다.
🔎 keyword
- 입력된 문자열을 "하나의 토큰"으로 저정한다.
- text 타입에 keyword 애널라이저를 적용한 것과 동일하다.
- 집계(aggregation)나 정렬(sorting)에 사용할 문자열 필드를 이 타입으로 지정한다.
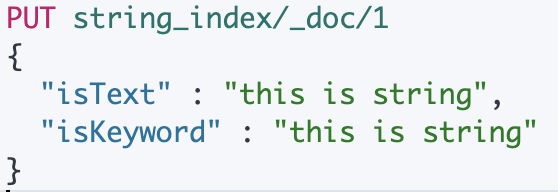
string_index라는 인덱스의 mappings 설정을 다음처럼 셋팅해 생성해보자.

field의 타입에 상관없이 두 필드 모두 "this is string" 이라는 값을 넣어주었다.
| isText field | isKeyword field |
|---|---|
 |  |
keyword 타입인 필드는 분리되지 않고 입력받은 문자열을 통채로 하나의 텀으로 저장하고 있음을 알 수 있다.
숫자 - long, double ...
- 자바에서 기본으로 사용되는 숫자 타입들을 지원
- long, integer, short, byte, double, float
- half_float, scaled_float와 같은 ES에서만 사용되는 타입도 있음.
- half_float : 16bit 실수
- scaled_float : 실수형이지만 부동소수점이 아닌 long 형태로 저장하고 옵션으로 소수점 위치를 지정한다. 통화(예: $19.99)같이 소수점 자리가 고정된 값을 표시할 때 유용하다.
❗️ NOTE
"coerce" : <true(default) | false>옵션이 true일 때 "4.5"라는 값이 integer 필드로 들어오면 _source의 값은 그대로 "4.5"이다. 단, 검색이나 집계는 4로 적용된다.
(해당 옵션이 false이면 오류가 발생하고 도큐먼트를 추가할 수 없다.)🤔 전처리된 데이터가 아니면 항상 _source의 값이 변경되지 않음을 유의하자.
따라서, 숫자 필드를 동적으로 생성하는 것은 매우 위험하다. 가장 처음 들어온 도큐먼트의 숫자 값이 4와 같은 자연수인 경우 필드는 자동으로 long 타입으로 생성되고 추후 실수가 들어와도 정상적으로 도큐먼트가 저장된다.
하지만 집계나 검색에서는 자연수로 변환된 값으로 검색되므로 오류가 발생한다.
날짜 - date
-
ISO8601 형식을 따라 입력한다. 일반적으로 다음과 같은 형태로 입력된 경우 자동으로 날짜 타입으로 인식된다.
- "2019-06-12"
- "2019-06-12T17:13:40"
- "2019-06-12T17:13:40+09:00"
- "2019-06-12T17:13:40.428Z"
-
ISO8601 형식이 아닌 경우, 보통 text, keyword로 저장된다.
-
long 타입의 정수인 epoch_millis 형태의 입력도 가능하다.
epoch_millis : 1970-01-01 00:00:00 부터의 시간을 "밀리초 단위"로 카운트 한 값이다.
-
필드가 date형으로 정의된 이후에는 long 타입의 정수를 입력하면 날짜 형태로 저장이 가능하다.
-
이외의 형식으로 저장하기 위해선 format 옵션을 사용해야한다.
-
date 필드는 내부에서는 long 형태의 epoch_millis로 저장
-
매핑의 format 형식만 지정 해 놓으면 지정된 어떤 형식으로도 색인 및 질의가 가능하다. (지정된 format이 여러개인 경우 호환이 가능하단 의미)
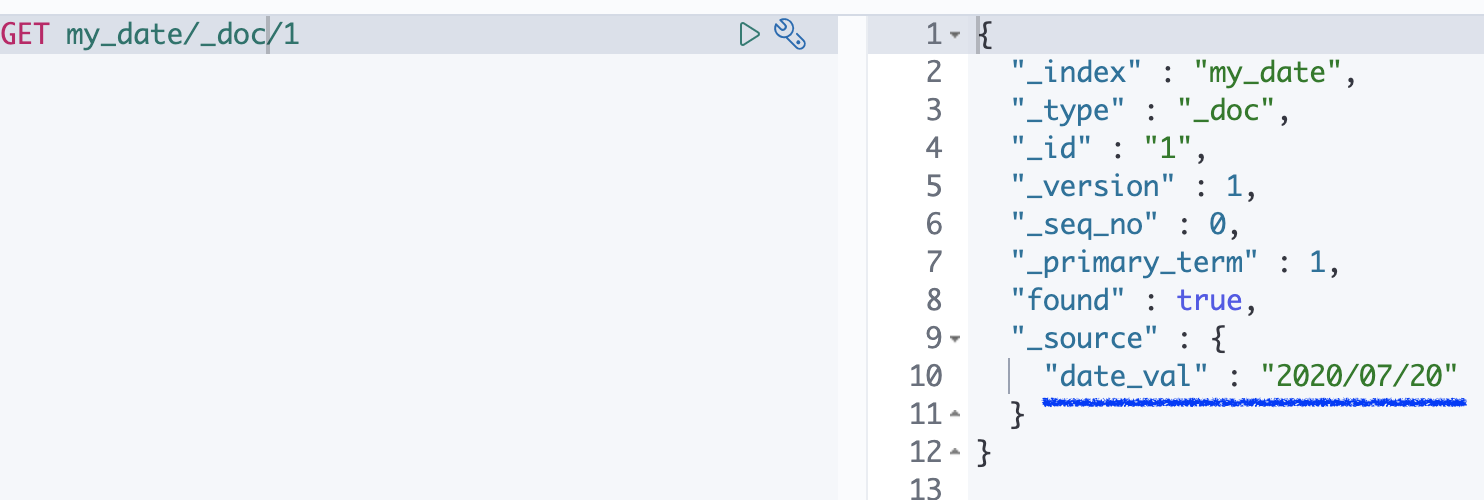
다음 예제에서는 format 옵션을 통해 "yyyy-MM-dd HH:mm:ss"꼴, "yyyy/MM/dd"꼴, epoch_millis 타입으로 들어와도 저장되도록한다.
PUT my_date
{
"mappings": {
"properties": {
"date_val": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
}
}
}
}
boolean
- ture/false
- "true"와 같이 문자열로 입력되도 true로 해석 돼 저장된다.
- 일반적으로 term쿼리를 이용해서 검색한다.
Object와 Nested
🔎 Object
PUT <인덱스 명>
{
"mappings": {
"properties": {
"<오브젝트 타입의 필드명>": {
"properties": {
"<하위 필드명>": {
"type": "<하위필드타입>"
},
"<하위 필드명>": {
"type": "<하위필드타입>"
},
...
}
}
}
}
}object 필드를 쿼리로 검색/집계 할 때는 .를 이용해 하위 필드에 접근한다.
GET <인덱스 명>/_search
{
"query": {
"match": {
"<필드명>.<하위필드명>": "<검색키워드>"
}
}
}❗️ NOTE
하나의 도큐먼트에 특정 필드를 배열로 추가하고 싶다면 따로 배열 타입의 필드를 선언하지 않고 필드 타입의 값만 일치시키면 된다.
- {"<필드명>", ["<값1>", "<값2>"]}
다음과 같은 예제를 보자
PUT movie/_doc/2
{
"title": "The Avengers",
"characters": [
{
"name": "Iron Man",
"side": "superhero"
},
{
"name": "Loki",
"side": "villain"
}
]
}
PUT movie/_doc/3
{
"title": "Avengers: Infinity War",
"characters": [
{
"name": "Loki",
"side": "superhero"
},
{
"name": "Thanos",
"side": "villain"
}
]
}movie 인덱스에 두개의 도큐먼트가 추가되었고, 각 도큐먼트는 object 타입의 characters 필드의 값을 배열로 가지고 있다.
다음과 같이 검색하면 결과가 어떻게 나올까?
GET movie/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"characters.name": "Loki"
}
},
{
"match": {
"characters.side": "villain"
}
}
]
}
}
}characters 배열중 어떤 값의 name이 Loki이면서 side가 villain인 값을 찾는 것처럼 보이고, 결과적으로 "_id"가 "2"인 도큐먼트가 검색될 것 같다.
하지만 결과적으론 "_id"가 "2"인 것과 "3"인 것 모두 검색된다.
이는 term을 저장할 때 오브젝트 타입을 기준으로 저장하는 것이 아닌 최종적으로 가지고 있는 하위필드의 값으로 저장하기 때문이다. 최하위 필드의 값만 보자면, 둘 모두 "Loki"와 "villain"이라는 term을 가지고 있기 때문에 이런 결과가 나오는 것이다.
의도한대로 "_id"가 "2"인 도큐먼트만을 결과로 받고 싶으면 Nested를 사용해야한다.
🔎 Nested
object 타입 필드의 배열이 서로 다른 역색인 구조를 갖길 원할 때 사용한다.
mappings에서 object 타입 내 하위 필드를 명시할 때 "type": "nested"를 추가한다.
nested 타입으로 저장된 데이터를 검색할 때는 "nested" 쿼리를 써야한다.
GET movie/_search
{
"query": {
"nested": {
"path": "characters",
"query": {
"bool": {
"must": [
{
"match": {
"characters.name": "Loki"
}
},
{
"match": {
"characters.side": "villain"
}
}
]
}
}
}
}
}nested 쿼리 안에는 path 옵션으로 nested로 정의된 필드를 명시하고 같은 댑스에 query를 사용해야한다.
nested 쿼리로 검색하면 nested 필드 내부의 값들을 모두 별개의 도큐먼트로 취급한다.
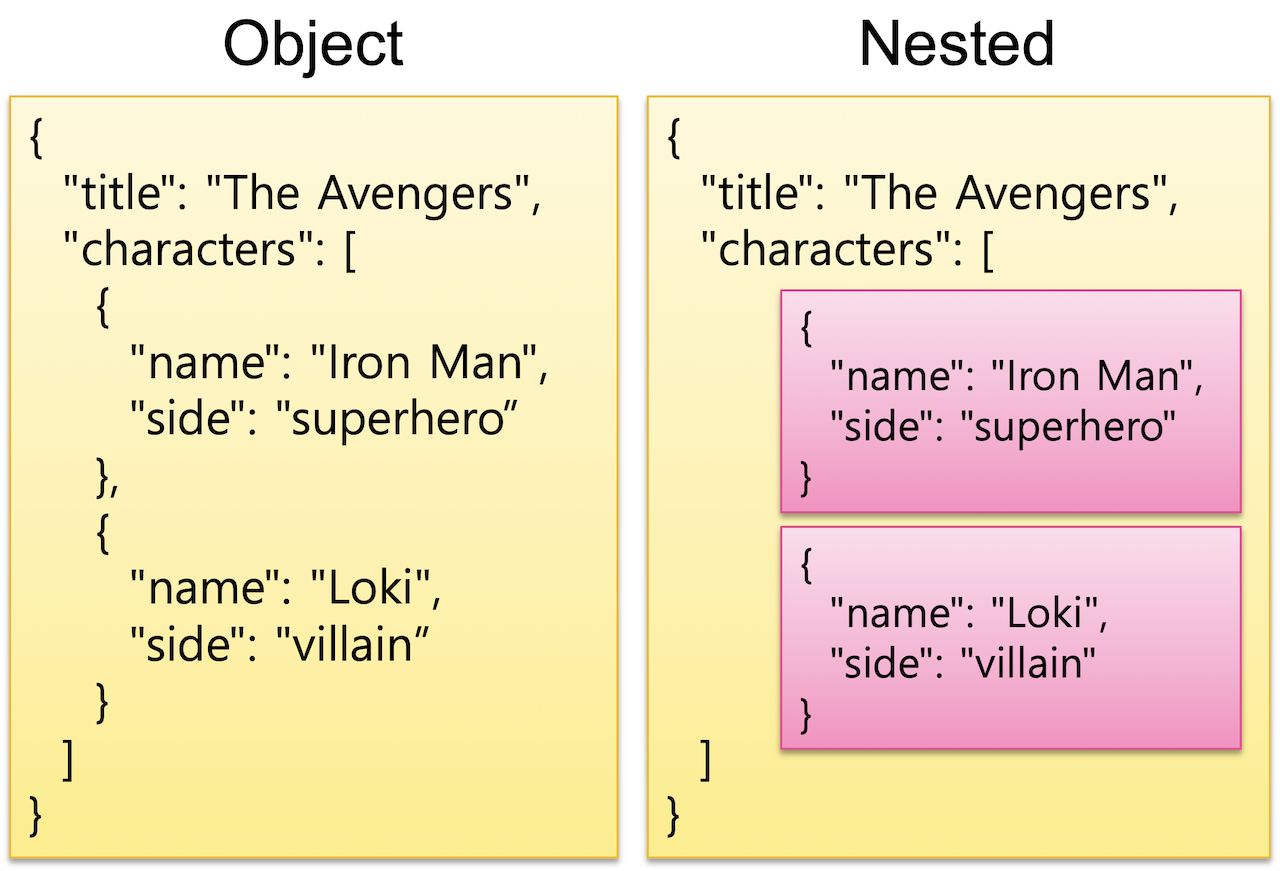
object 필드의 값은 실제로 하나의 도큐먼트 안에 전부 포함되어 있다. 반면에 nested 필드 값들은 내부적으로 별도의 도큐먼트로 분리되어 저장되며, 쿼리 결과에서 상위 도큐먼트와 합쳐져서 보여지게 된다.
Geo
- 위치 정보를 표시하거나 검색
🔎 Geo Point
- 위도(latitude), 경도(longitude) 두 개의 실수 값을 가지고 지도 위의 한 점을 나타내는 값
다음 모두 위도 41.12, 경도 -71.34의 위치를 각기 다른 형식으로 저장하는 요청이다.
// object 형식
PUT my_locations/_doc/1
{
"location": {
"lat": 41.12,
"lon": -71.34
}
}
// text 형식
PUT my_index/_doc/2
{
"location": "41.12,-71.34"
}
// geohash 형식
PUT my_index/_doc/3
{
"location": "drm3btev3e86"
}
// 실수 배열 형식
PUT my_index/_doc/4
{
"location": [
-71.34,
41.12
]
}보통은 {"lat": 41.12, "lon": -71,34}와 같이 알아보기 쉬운 object 형식으로 입력한다.
PUT my_geo
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}반드시 geo_point 타입으로 정의해야만 float 타입으로 자동 생성되지 않음을 유의하자.
geo_point 값의 검색에 주로 사용되는 것은 geo_bounding_box 쿼리와 geo_distance 쿼리이다.
🔎 geo_bounding_box 쿼리
- top_letf(좌측 상단)과 bottom_right(우측 하단) 두 개의 위치점을 입력
- 이 네모 범위 내의 도큐먼트들을 불러온다.
GET my_geo/_search
{
"query": {
"geo_bounding_box": {
"location": {
"bottom_right": {
"lat": 37.4899,
"lon": 127.0388
},
"top_left": {
"lat": 37.5779,
"lon": 126.9617
}
}
}
}
}🔎 geo_distance 쿼리
- 필드명과 lat, lon으로 하나의 위치점을 찍고
- distance 옵션으로 반경을 설정하면
- 위치점에서 반경 distance의 원을 그려 내부의 도큐먼트들을 불러온다.
GET my_geo/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": 37.5358,
"lon": 126.9559
}
}
}
}🔎 Geo Shape
- Geo Point : 위도, 경도 두 개의 값을 가진 1차원 데이터 "점"
- Geo Shape : "선", "면" 등의 2차원 값을 저장하고 질의할 수 있다.
"type": "geo_shape"로 선언- 도큐먼트를 입력할 때 "type"에 점, 선, 다중점, 다중선, 다각형 등을 입력
- "coordinates" 값에 [경도, 위도]의 순서의 배열 형식으로 입력
| type | desc | example |
|---|---|---|
| point | 단일점 |  |
| mulipoint | 여러점을 하나의 값으로 저장 | 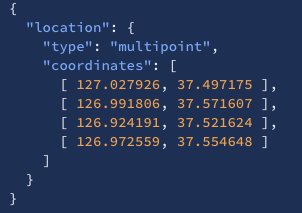 |
| linestring | 점 2개를 배열로 입력하여 이를 잇는 직선을 저장 | 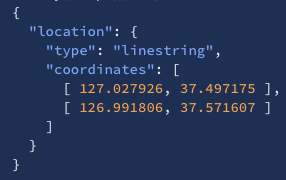 |
| multilinestring | 여러개의 직선을 배열로 저장 |  |
| polygon | 다각형을 저장, 배열의 순서대로 점이 이어진다. 마지막에는 반드시 처음과 같은 점이 입력되어야한다. | 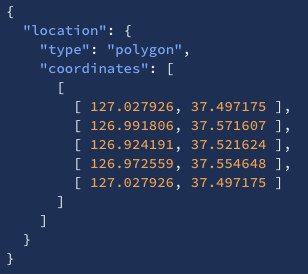 |
| multipolygon | 여러 개의 다각형을 배열로 저장 |  |
| envelope | 직사각형의 영역을 저장, [좌측 상단, 우측하단]으로 입력 |  |
🔎 geo_shape 쿼리
- Geo Shape 타입을 검색할 때 사용
"shape": { }에 검색할 영역의"type"과"coordinates"값을 입력"relation"에 검색할 영역과 도큐먼트의 관계 조건 값을 입력"relation": "intersects": 디폴트 값. 쿼리 영역과 도큐먼트 값 영역이 일부라도 겹쳐지면 참"relation": "disjoint": 도큐먼트가 쿼리 영역과 일부도 겹치지 않는 경우에 참"relation": "within"- 도큐먼트가 쿼리 영역 안에 완전히 포함되어 있는 경우에 참
multi field
- 도큐먼트에는 하나의 필드값만 있지만 여러개의 역색인 및 doc_values들로 저장할 수 있는 기능
{
"mappings": {
"properties": {
"<필드명1>": {
"type": "text",
"fields": {
"<필드명2>": {
"type": "<타입>"
}
}
}
}
}
}- 하나의 텍스트 필드에 여러개의 애널라이저를 적용하기 위해서도 사용한다.
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"nori_analyzer": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english"
},
"nori": {
"type": "text",
"analyzer": "nori_analyzer"
}
}
}
}
}
}"mappings" 쪽을 보면 "message" 필드에 멀티 필드가 적용되고 있는 것을 알 수 있는데, "message" 필드는 english 애널라이저를 사용한 경우와 nori_analyzer를 사용한 경우에 대한 역색인도 만들어 진다.
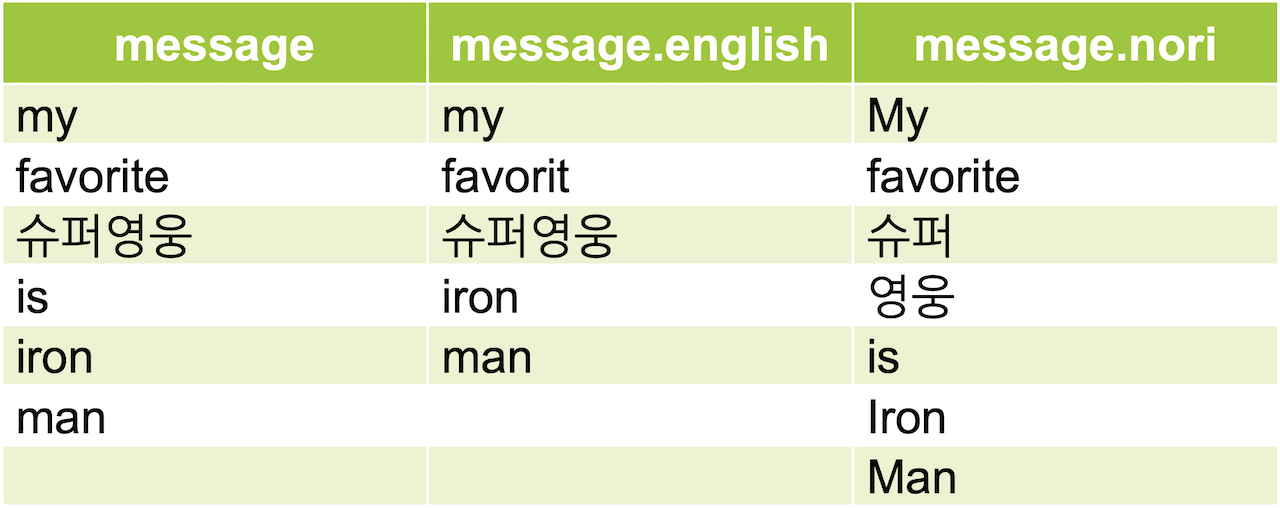
검색 시
GET my_index/_search
{
"query": {
"match": {
"message": "영웅"
}
}
}라고 검색하지 않고,
GET my_index/_search
{
"query": {
"match": {
"message.nori": "영웅"
}
}
}처럼 "message.nori"라고 표기해야 검색 결과가 나올 것이다.
멀티 필드는 한 필드에 여러 애널라이저를 적용해야 하는 경우, 특히 다국어로 씌여진 도큐먼트를 분석하는 경우에 매우 유용하다.

인덱스를 생성해서 저장했는데 다른유저로 로그인하면 그 인덱스가 보이지 않습니다.공유를 하려면 어떻게 해야하나요>