
ref.
NoSQL 철저 입문 (댄 설리번)
wikipedia - NoSQL
mongodb document - NoSQL vs Relational Databases
정의
원래 의미 : "non SQL" or "non relational"
전통적인 관계형 데이터베이스보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공한다. 단순 검색 및 추가 작업을 위한 매우 최적화된 key-value 저장 공간으로, 레이턴시와 스루풋과 관련하여 상당한 성능 이익을 내는 것이 목적이다.
❗️NOTE
레이턴시(latency) : 자극과 반응 사이의 시간이며, 더 일반적인 관점에서는 관찰되는 시스템에서의 어떠한 물리적 변화에 대한 원인과 결과 간의 지연 시간이다.
스루풋(throughput) 또는 처리율(處理率) : 통신에서 네트워크 상의 어떤 노드나 터미널로부터 또 다른 터미널로 전달되는 단위 시간당 디지털 데이터 전송으로 처리하는 양을 말한다.
NoSQL이라는 명칭은 이 데이터 베이스 시스템이 현재의 데이터베이스 시스템을 대신하지 않는다는 사실을 암시한다. 이런 사실은 관계형 데이터베이스에서 잘 사용해온 SQL이라는 언어와 연관이 있다.
역사
초기의 데이터베이스 관리 시스템
1970년대 관계형 DB가 등장하기 전 → 파일 시스템, 데이터 베이스 시스템 (플랫 파일 데이터 관리 시스템, 계층형 데이터 관리 시스템, 네트워크 데이터 관리 시스템)
- 플랫 파일 데이터 관리 시스템
- 구조화된 데이터 세트를 파일 하나로 만들어서 디스크나 자기테이프 등의 장기기억 저장 장치에 저장하는 방식 → 시스템의 물리적 제약이 존재
- 한계 : 중복 데이터 발생 위험, 파일 구조 변경시 프로그래머들은 새 구조에 맞춰 프로그램을 수정해야함, 비밀을 유지해야하는 일부 정보가 담긴 파일을 공유하기 어려움, 데이터가 여러 파일에 분산되어있으면 일관성의 유지가 어려움, 데이터가 저장된 방식 이외의 다른 방식으로 데이터 접근시 비효율적
- 이러한 한계를 극복하기 위해 아래의 두 시스템이 개발되었다.
- 계층형 데이터 관리 시스템
- 부모-자식 관계의 계층 구조로 데이터 구성 → 플랫 파일 기반 데이터 관리 시스템의 한계인 검색할 때의 비효율성을 극복
- 한계 : 관리하는 엔터티가 부모-자식 관계이며 1:N일 때만 잘 작동한다. 그렇지 않은 경우(N:1이나 N:N) 두 부모에 같은 자식이 존재하게 하려면 자식을 복제하여 각각의 부모 밑에 넣어줘야했다. → 저장 공간을 비효율적으로 사용하게 됨, 데이터 일관성 문제, 데이터 집계 오류 초래
- 이러한 한계를 극복하기 위해 네트워크 데이터 모델 시스템이 발전
- 네트워크 데이터 관리 시스템
- 노드, 엣지를 가지는 그래프 형태, 서로 연결된 데이터 레코드로 구성된다.
- 한계 : 설계와 관리가 여러움.
초기 데이터 관리 시스템에는 여러 가지 단점이 존재하지만 특히 데이터 베이스 구조가 바뀔 때 프로그램도 변경해야한다는 단점이 존재했다. 이는 DB의 논리 구조가 테이프나 디스크에 물리적으로 데이터가 저장되는 방식이 "독립적이지 못했기" 때문이다. DB의 논리 구성과 물리 구성에 대한 구조적 독립성은 DB 관리에서 RDBMS이 가져온 주요 개선점 중 하나이다.
관계형 데이터베이스
❗️데이터 구조의 논리 구성을 물리적인 저장 구조와 분리하였다.
🔎RDBMS(Relational Database Management System)
데이터를 관리하고 애플리케이션 사용자들이 데이터를 읽고 추가/갱신/삭제하는 것을 허용하는 다수의 프로그램으로 구성된 애플리케이션.
데이터 관리에 공통된 언어인 SQL을 사용하도록 설계되었다.
저장 시스템의 유형에 상관없이 RDBMS는 데이터 조각이 저장된 위치를 모두 추적해야한다. 디스크와 플래시 장치에는 검색에 대한 엄격한 제한(e.g. 테이프 기반인 경우 순차검색이 필수)이 없으므로 RDBMS 설계자들을 RDBMS의 데이터 조회 방식을 개선했다.
🤔관계형 데이터베이스의 한계
RDB는 데이터베이스 애플리케이션에 사용된 것 중 수십년간 가장 지배적인 유형의 데이터베이스였다. 하지만 웹 출현과 더불어 관계형 데이터베이스의 한계가 점점 더 문제로 드러나게 됐다.
큰 규모의 데이터와 사용자를 대상으로 하려면 대용량 데이터의 읽기/쓰기 작업, 빠른 응답 시간, 높은 가용성이 지원되어야했으며 이런 요구 사항은 RDB로 실현하기 어려웠다.
또한, 과거에 RDB의 성능이 저하되면 더 많은 CPU, 추가 메모리, 더 빠른 저장 장치를 장착함으로써 문제를 해결했으나 이런 방식은 비용이 비싸고 임시방편일 뿐이었다. 결국 데이터베이스 설계자는 비정규화를통해 데이터베이스 스키마를 재설계 해야했다.
NoSQL 데이터베이스의 출현
대용량 데이터 관리 작업에서 특히 중요한 데이터 관리 시스템의 네 가지 특성은 다음과 같다.
👉 확장성 비용 유연성 가용성
확장성
확장성이란 변화무쌍한 작업 부하에 대한 요구 사항을 효율적으로 충족시키는 능력을 뜻한다.
때로는 필요에 따라 서버를 추가하는 작업(스케일 아웃)이 이뤄지는데 RDB에서는 단일 데이터베이스 시스템을 구동하는 여러 서버를 관리하기위해 데이터베이스 소프트웨어가 필요하여 복잡성과 운영 비용이 증가할 수 있다. 반면에 NoSQL은 애초에 클러스터 하나에서 서버 여러개를 이용하도록 설계되었다. 즉, 새로운 서버를 추가/제거할 때 NoSQL DBMS는 사용 가능한 새 서버를 사용하도록 조정한다.
비용
주요 NoSQL 데이터베이스들은 오픈 소스 형태로 제공되며 대부분 오픈 소스 개발자는 자신의 소프트웨어를 사용하는데 비용을 매기지 않는다.
유연성
RDBMS는 관계형 데이터 모델을 사용해 해결 가능한 문제의 범위 "내에서는" 유연한 편이다. 하지만 데이터베이스 설계자는 프로젝트를 시작할 때 애플리케이션 지원에 필요한 모든 테이블과 컬럼을 파악해야 할 뿐만 아니라 대부분의 테이블에 값이 채워져있어야 한다.
(일부) NoSQL 데이터베이스는 고정된 테이블 구조가 필요하지 않다. 즉, 데이터베이스 설계를 변경하지 않고도 필요한 새로운 속성을 동적으로 추가할 수 있다.
가용성
NoSQL 데이터베이스는 저렴한 비용으로 서버를 여러개 이용할 수 있도록 "설계"되었다. 서버 하나가 중지되거나 (유지보수 등의 목적으로) 서비스를 일시 중지해야할 경우 클러스터 내 다른 서버가 작업량 전체를 떠맡을 수 있다. (성능은 다소 저하될지라도 애플리케이션이 중단되지는 않는다.)
✏️정리
전자 상거래🤝와 소셜 미디어💻의 기하급수적인 성장은 확장성이 좋고 저비용에 유연하며 높은 가용성을 지닌 데이터 관리 시스템의 출현을 이끌어 냈다. 일부 경우에 한해 관계형 DB로도 이런 목적 중 일부는 달성할 수 있지만 NoSQL 데이터 베이스와 비교해 고비용 발생 문제와 구현상의 어려움이 발생하곤 한다.
NoSQL 데이터베이스는 RDMS가 가진 한계를 해결하고자 만들어졌다. RDB가 플랫 파일, 계층형, 네트워크 데이터베이스를 대체한 방식으로 "NoSQL 데이터베이스가 관계형 데이터베이스를 대체할 가능성은 낮다." 두 시스템은 서로 보완하고 장점을 흡수해가면서 점점 복잡해지고 요구 사항이 많아지는 애플리케이션에 적응해 나갈 것이다.
특징
NoSQL의 특징
- 설계의 단순성
- 머신들의 클러스터에 대한 더 단순한 수평 확장(RDB의 문제점)
- 이용성에 대한 세밀한 통제
- NoSQL DB에 사용되는 자료 구조(wide column, document, graph, key-value)는 RDB에서 기본적으로 사용되는 것들과는 다르며 일부 작업들은 NoSQL에서 속도가 더 빠른 편이며 "더 유연한" 것으로 간주되기도 한다.
NoSQL vs. RDB
ref. mongodb document - NoSQL vs Relational Databases1과 mongodb document - NoSQL vs Relational Databases2의 일부분을 번역합니다.
쿼리 언어로써 각각 SQL, NoSQL로 불리는 관계형 데이터베이스와 비관계형 데이터베이스는 선택가능한 최신의 데이터베이스의 두가지 주요 타입이다. 요구에 가장 적합한 데이터베이스를 결정할 때 숙지해야할 몇 가지 주요한 차이점이 있다.
✏️tldr 요약
SQL 데이터베이스는 관계형 데이터베이스라고 하며 사전에 엄격하게 정의된 스키마를 요구하는 테이블 기반 데이터 구조를 가진다. NoSQL 데이터베이스 혹은 비관계형 데이터베이스는 document based, graph databases, key-value pairs, wide-column stores일 수 있다. NoSQL 데이터베이스에는 사전에 정의된 스키마가 필요하지 않으므로 "비정형 데이터"를 다룰 때 보다 자유롭게 작업할 수 있다. 관계형 데이터베이스는 수직 확장이 가능하나 일반적으로 비용이 비싸다. 반면에 NoSQL 데이터베이스의 특징인 수평 확장은 비용면에서 더욱 효율적이다.
관계형 데이터베이스(RDBMS)와 NoSQL의 역사
관계형 데이터베이스는 40년 이상 사용되어왔다. 데이터 구조가 훨씬 단순하고 정적이었던 시절(과거)에서 이들은 잘 작동하였다. 하지만 기술과 빅데이터 응용 프로그램이 발전함에 따라 기존의 SQL 기반 관계형 데이터 베이스는 빠르게 확장되는 데이터의 양과 점점 복잡해지는 데이터 구조를 처리할 수 있는 능력이 부족했다. 지난 10년 동안 (비관계형) NoSQL 데이터베이스는 기존의 SQL 기반의 관계형 데이터베이스에 비해 유연하고, 확장 가능하며, 비용적으로 효율적인 대안을 제공하는데 널리 사용되었다.
데이터 모델과 스키마
NoSQL 데이터베이스는 동적 스키마라는 특징이 있으며 "비정형 데이터"라는 것을 사용할 수 있다. 기본적으로 이는 스키마를 먼저 정의하지 않고도 애플리케이션을 빌드 할 수 있음을 의미한다. 관계형 데이터 베이스에서는 시스템에 데이터를 추가하기 전에 스키마를 정의하는 것이 필수였다. 반면에 사전 정의된 스키마가 없는 NoSQL 데이터베이스는 데이터를 갱신하거나 요구사항을 변경하는 것이 더욱 쉽다. 관계형 데이터베이스에서 스키마 구조를 변경하는 것은 고비용이며, 시간이 많이 들고, 종종 중단 시간(downtime)이나 서비스 중단이 발생할 수 있다.
데이터 구조
관계형 데이터베이스는 테이블 기반이다. NoSQL 데이터베이스는 document based, graph databases, key-value pairs, wide-column stores일 수 있다. 관계형 데이터베이스는 데이터가 대부분 구조적이고 관계에 의해 명확하게 정의될 때 구축되었지만 오늘날의 데이터는 훨씬 더 복잡하단 것을 알고 있다. NoSQL 데이터베이스는 오늘날 존재하는 많은 데이터를 구성하고 있는 비정형 데이터(텍스트, 소셜 미디어 게시물, 사진, 비디오, 이메일 등)를 처리하도록 설계되었다.
스케일링
관계형 데이터베이스는 수직 확장이 가능하나 일반적으로 고비용이다. 확장을 위해서는 전체 데이터베이스를 호스팅하기 위한 단일 서버가 필요하므로 더 크고 비싼 서버를 구입해야한다. NoSQL 데이터베이스 확장은 저렴한 범용 서버를 이용해 수평 확장함으로써 용량을 추가할 수 있기 때문에 관계형 데이터베이스에 비해 훨씬 저렴하다.
NoSQL과 RDB의 주요 차이점(요약)
| SQL Database | NoSQL Database | |
|---|---|---|
| 데이터 저장소 모델 | 고정 행과 열이 있는 테이블 | document-JSON document, key value store-key value 쌍, wide column-row와 동적 column이 있는 테이블, graph db-노드 및 엣지 |
| 역사 | 데이터 복제 감소에 중점을 둔 1970년대에 개발 | 2000년대 후반에 애자일과 DevOps 관행에 따라 신속한 애플리케이션 변경의 가능과 확장성에 중점을 두고 개발되었다. |
| 예 | Oracle, MySQL, Microsoft SQL Serverm, PostgreSQL | document-MongoDB/CouchDB, key value store-Redis/DynamoDB, wide column-Cassandra/HBase, graph db-Neo4j/Amazon Neptune |
| 주요 목적 | 범용 | document-범용, key value store-간단한 조회 질의를 이용한 대량의 데이터 추출, wide column-예측 가능한 쿼리 패턴을 이용한 대량의 데이터 추출, graph db-연결된 데이터 간의 관계 분석 및 탐색 |
| 스키마 | 엄격 | 유연(융통성있음) |
| 확장(스케일링) | 수직 (더 큰 서버로 확장 포함) | 수평 (서버 간 스케일 아웃) |
| Mutil-Record ACID Transctions | 지원 | 대부분 지원하지 않음. MongoDB 등 일부 기능을 지원하는 경우도 있다. |
| Join | 일반적으로 필요 | 일반적으로 필요하지 않음 |
| data-object 매핑 | ORM 필요 | 대부분 ORM을 요구하지 않는다. MongoDB document는 가장 많이 사용되는 프로그래밍 언어로 데이터 구조에 직접 매핑된다. |
NoSQL의 종류
NoSQL 데이터베이스를 분류하는 방식은 다양하나 데이터 모델에 기반을 둔 것이 일반적인 분류이다.
Wide Columnar
테이블, 로우, 컬럼을 사용하지만 관계형 데이터베이스와는 달리 컬럼의 이름과 포맷은 테이블의 로우마다 "다를 수 있다." 와이드 컬럼 스토어는 2차원 키-값 스토어로 해석할 수 있다.
ref. https://database.guide/what-is-a-column-store-database/
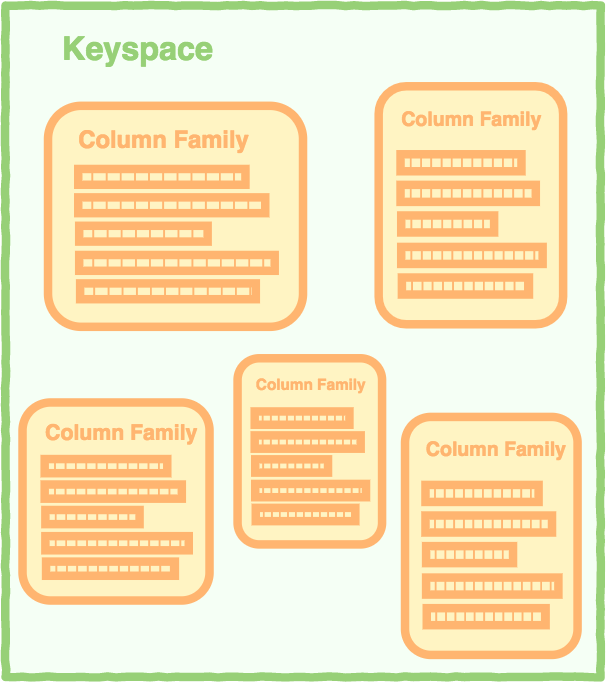 컬럼 패밀리를 포함하는 keyspace이다.
컬럼 패밀리를 포함하는 keyspace이다.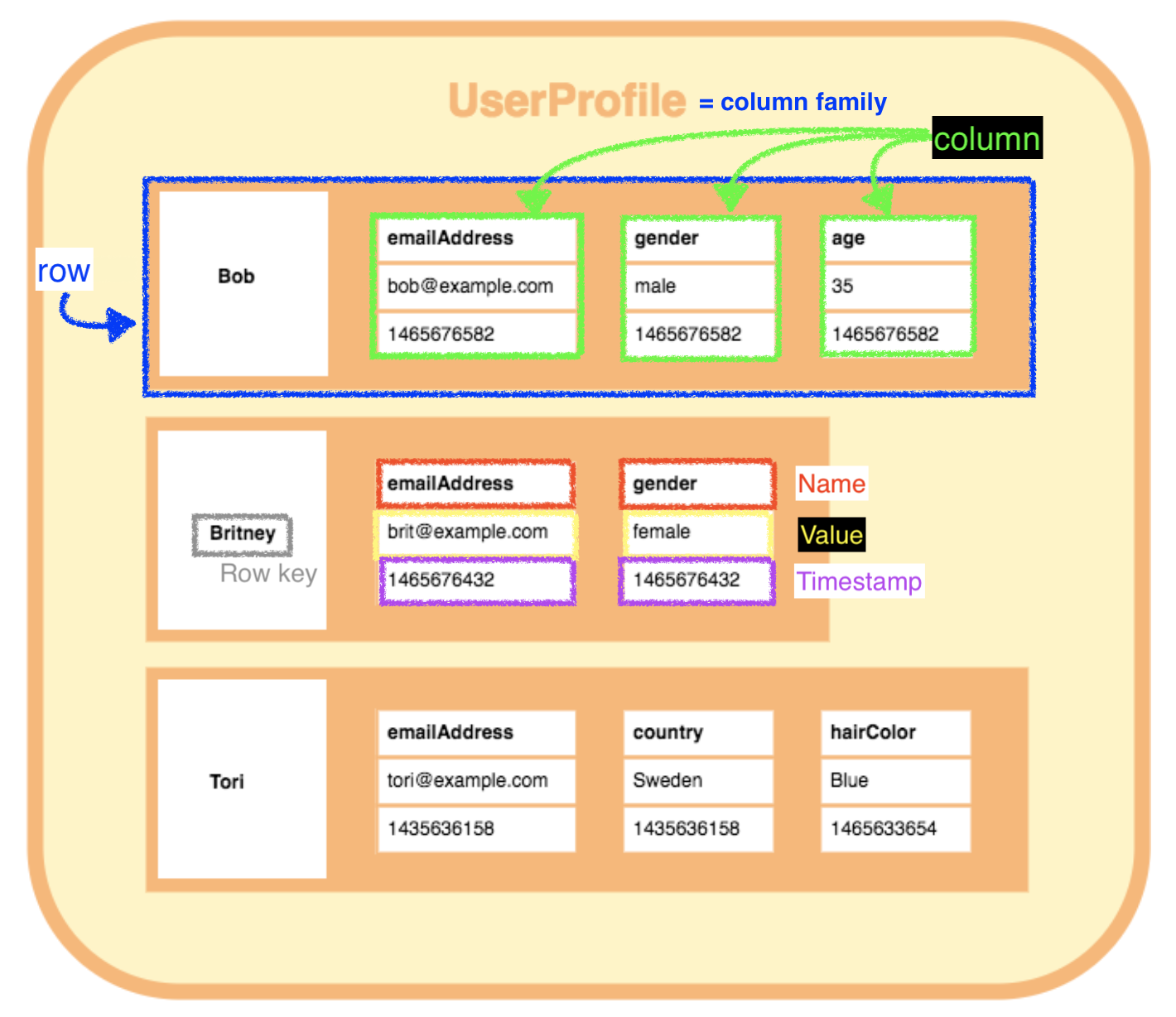 UserProfile이라는 이름의 컬럼 패밀리이며 3개의 row를 포함하고 있다. 각 row는 고유한 column set이 있다. 즉, row는 다른 row와 다른 수, 다른 이름, 다른 데이터 유형의 column을 가져도 무관하다.
UserProfile이라는 이름의 컬럼 패밀리이며 3개의 row를 포함하고 있다. 각 row는 고유한 column set이 있다. 즉, row는 다른 row와 다른 수, 다른 이름, 다른 데이터 유형의 column을 가져도 무관하다.
🔎 대표적인 Database : Cassandra, HBase, GoogleBigTable, Vertica, Druid, Accumulo, Hypertable
Key-Value
dictionary, hash로 잘 알려져 있는 자료 구조인 연관 배열의 저장, 검색, 관리를 위해 설계된 데이터 스토리지 패러다임이다.
딕셔너리에는 객체나 레코드의 컬렉션이 포함, 이 안에서 각각 데이터를 담고있는 각기 다른 수많은 필드가 포함되어 있다. 이 레코드들은 고유 식별자인 키를 사용하여 저장되고 검색된다. 이는 객체 지향 프로그래밍과 같은 현대의 개념을 더 밀접하게 따르며 상당한 유연성을 제공한다.
Key 안에는 (column, value) 형태로 된 여러개의 필드, 즉 Column families를 갖는다.

🔎 대표적인 Database : Redis, Oracle NoSQL Database, Voldemorte, Oracle Berkeley DB, Memcached, Hazelcast
Document
= 문서 지향 데이터베이스 or Document store
덜 구조화된 데이터라고 알려진 문서 지향 정보를 저장, 검색, 관리하기 위해 설계된 컴퓨터 프로그램
이는 본질적으로 key-value store의 하위 클래스로써 또 다른 NoSQL 데이터베이스 개념이다. key-value와의 차이점은 데이터 처리 방식에 있다. key-value store에서 데이터는 DB에 대해 불투명 한 것으로 간주되는 것과 달리 DB 엔진이 추가 최적화를 위해 사용하는 "meta data 추출"을 위해 문서의 내부 구조에 의존한다.
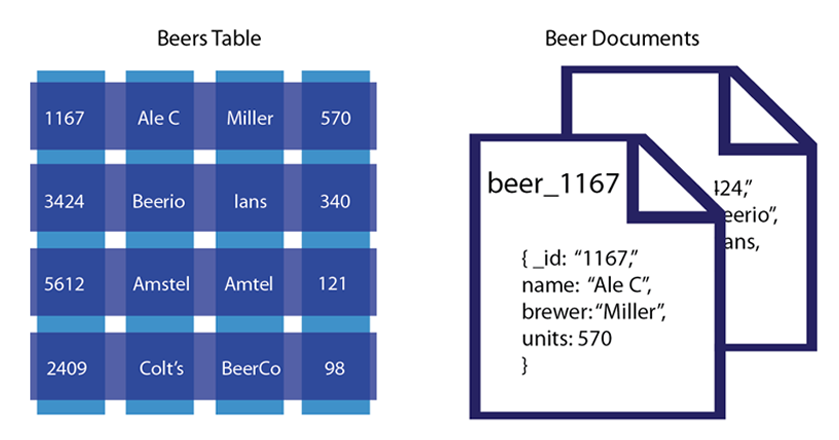
RDB 일반적으로 프로그래머가 정의한 별도의 테이블에 데이터를 저장하며 단일 개체를 여러 테이블에 분산 시킨다. 반면에 Document DB에서는 주어진 객체에 대한 "모든 정보"를 데이터베이스의 "단일 인스턴스"에 저장하며 저장된 모든 객체는 "서로 다를 수 있다." 즉, 테이블 스키마가 정적이지 않고 유동적이며 레코드마다 다른 스키마를 가질 수 있다.
일반적으로 JSON같은 document를 이용해 레코드를 저장한다.
🔎 대표적인 Database : MongoDB, Azure Cosmos DB, CouchDB, MarkLogic, OrientDB
Graph
시맨틱 쿼리를 위해 노드, 엣지, 프로퍼티와 함께 그래프 구조를 사용해 데이터를 표현하고 저장하는 데이터베이스이다. 이 시스템의 주 개념은 그래프(edge or relationship)이며 스토어에 직접 데이터 항목들의 관계를 정한다. 이러한 관계들은 스토어 안의 데이터가 함께 직접 연결될 수 있게 한다.
❗️NOTE
Semantic Query는 데이터에 포함된 구문, 시멘틱(의미) 및 구조적 정보를 기반으로 명시적 및 암시적으로 파생된 정보를 모두 검색한다. 즉, 연관관계나 상황에 따라 알맞는 질의 및 분석이 가능하다.시멘틱 쿼리는 named graphs, linked data, triples에서 작동한다. 쿼리는 정보 사이의 실제 관계를 처리하고 데이터 네트워크로부터 답을 유추할 수 있다. 이는 비정형 텍스트에 의미론을 사용해 더 나은 검색 결과를 도출하는 의미론적 검색과는 대조적이다.
정확한 결과를 전달하거나 (아마도 단일 정보의 독특한 선택일 것이다.) 패턴 매칭과 디지털 추론을 통해 더 모호하고 폭넓은 질문에 답하기 위해 고안되었다.
일반적인 그래프를 표현한다는 점에서 네트워크 모델 데이터베이스와 비슷하지만 이는 더 낮은 수준의 추상화로써 동작하며 일련의 엣지 간의 용이한 횡단이 불가능했다.
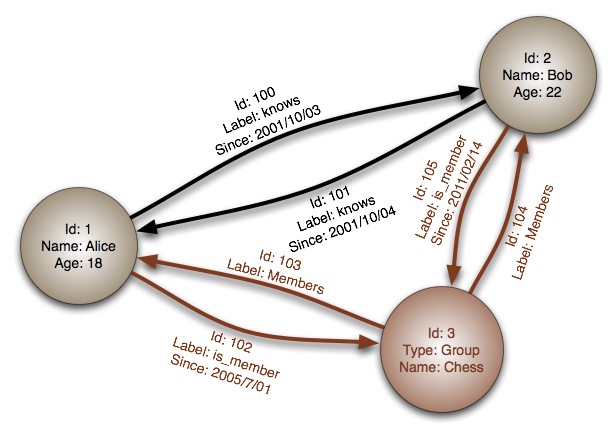 노드 : 추적 대상이되는 실체 = 레코드
노드 : 추적 대상이되는 실체 = 레코드
엣지 : (=그래프 or 관계) 노드를 다른 노드에 연결하는 선, 관계를 표현
프로퍼티 : 노드의 정보
RDBMS보다 퍼포먼스가 좋고 유연하며 유지보수에 용이하다.
🔎 대표적인 Database : Neo4j, Blasegraph, OrientDB
성능
벤 스코필드는 여러 유형의 NoSQL 데이터베이스의 등급을 다음과 같이 평가했다.
| 데이터 모델 | 성능 | 확장성 | 유연성 | 복잡성 | 기능 |
|---|---|---|---|---|---|
| 컬럼 지향 스토어 | 높음 | 높음 | 준수 | 낮음 | 최소 |
| 도큐먼트 지향 스토어 | 높음 | 가변적(높음) | 높음 | 낮음 | 가변적(낮음) |
| 그래프 데이터베이스 | 가변적 | 가변적 | 높음 | 높음 | 그래프 이론 |
| 키-값 스토어 | 높음 | 높음 | 높음 | 없음 | 가변적(없음) |
| 관계형 데이터베이스 | 가변적 | 가변적 | 낮음 | 준수 | 관계대수 |
❗️NOTE
그래프 이론(graph theory)은 수학에서 객체 간에 짝을 이루는 관계를 모델링하기 위해 사용되는 수학 구조인 그래프에 대한 연구이다. 이 문맥에서 그래프는 꼭짓점(버텍스/vertex), 교점(노드/node), 점(포인트/point)으로 구성되며 이것들은 변(엣지/edge, 간선), 즉 선으로 연결된다.관계대수(relational algebra)는 컴퓨터 과학의 관계형 데이터베이스의 관계 모델에서, 집합론과 1차 논리에 기반하여 관계(표)로 표현된 데이터를 취급하는 대수적인 연산 체계이다.
데이터베이스 관계대수는 기본 연산 집합이며, 연산자(operator)에는 단항연산자(unary operator)와 이항연산자(binary operator)가 있으며 연산종류에는 기본연산과 유도된 연산이 있다.
