Zipkin 관련 자료 정리

Distributed Tracing in Microservices using Zipkin, Sleuth and ELK Stack
분산 트레이싱이란?
마이크로서비스의 중요한 도전과제는 이슈를 디버깅하고 모니터링하는 능력이다. 간단한 행위가 마이크로서비스 콜 연속체의 트리거가 되고, 적용된 마이크로서비스를 넘나드는 액션을 추적하는 것은 지루한 작업이다. 이는 각 마이크로서비스는 다른 마이크로서비스에 독립적인 환경에서 실행되기때문에 DB나 log file과 같은 리소스를 공유할 수 없기 때문이다. 추가적으로 개발자들은 비즈니스 플로우에서 어느 마이크로 콜에 의해 많은 시간이 소모됐는지 확실하게 추적하고자한다.
분산 추적 패턴은 마이크로서비스를 구축하는 동안 개발자가 직면하는 위의 문제를 해결한다. Spring Boot 및 Spring Cloud 프레임 워크로 마이크로 서비스를 만들 때 분산 추적에 사용할 수있는 유용한 오픈 소스 도구가 있다. 이 블로그는 이러한 도구의 설치 단계 및 구현을 안내한다.
The Tools
Spring Cloud Sleuth
적절한 HTTP 요청 헤더에 trace 및 span id를 추가함으로써 다음 마이크로서비스의 진행 상황을 추적 할 수있는 Spring Cloud 라이브러리. 라이브러리는 MDC (Mapped Diagnostic Context) 개념을 기반으로하며 컨텍스트에 넣은 값을 쉽게 추출하여 로그에 표시 할 수 있다.
mdc를 사용하여 컨텍스트 정보를 넘기게 되면, slf4j와 logback의 제약 사항을 넘어서 json으로 여러 element를 로깅 할 수 있다.
Zipkin
독립적인 서비스간에 전파되는 모든 요청에 대한 타이밍 데이터를 수집하는데 도움이되는 Java 기반 분산 추적 애플리케이션. 차후의 서비스에서 생성된 시간 통계의 시각화를 찾을 수있는 간단한 관리 콘솔이 있다.
ELK Stack
Elasticsearch, Logstash 및 Kibana의 세 가지 오픈 소스 도구가 ELK 스택을 구성한다. 로그 데이터를 실시간으로 검색, 분석 및 시각화하는 데 사용된다. Elasticsearch는 검색 및 분석 엔진이다. Logstash는 여러 소스의 데이터를 동시에 수집하고 변환 한 다음 Elasticsearch와 같은 "stash"으로 보내는 서버 측 데이터 처리 파이프 라인이다. Kibana를 사용하면 이 데이터를 차트와 그래프로 시각화 할 수 있다.
Spring Cloud Sleuth and Zipkin Example
https://howtodoinjava.com/spring-cloud/spring-cloud-zipkin-sleuth-tutorial/
Zipkin은 마이크로서비스 에코시스템의 분산 추적에 매우 효과적인 툴이다. 일반적으로 분산 추적이란 단일 비스니스를 위해 여러 마이크로서비스가 호출되는 분산 트랜잭션 내 각 컴포넌트의 지연시간 측정이다. 우리의 어플리케이션에서 하나의 트랜잭션을 위해 네개의 다른 서비스/컴포넌트를 호출한다. 분산 추적이 가능할 때 우리는 각 컴포넌트에서 소요되는 시간을 측정할 수 있다.
이는 여러 하부의 시스템이 관련되고 어떤 특정한 상황에서 어플리케이션이 느려지는 순간을 디버깅할 때 유용하다. 이 경우, 어떤 하위 시스템이 실제로 느린 것인지 식별할 필요가 있다. 느린 서비스가 확인되면 해당 문제를 해결하기 위해 다음 작업을 수행할 수 있다. 분산 추적은 에코시스템 내에서 느린 컴포넌트를 식별하는데 도움이된다.
Zipkin
데이터의 수집과 조회를 모두 관리한다. Zipkin을 사용하기 위해서 어플리케이션은 타이밍 데이터를 보고하도록 설계된다.
에코시스템의 지연 문제나 오류를 해결하기 위해서 어플리케이션, 추적 길이, 어노테이션, 타임스탬프를 기반으로한 모든 trace를 필터링하거나 정렬할 수 있다. 이러한 trace를 분석하여 예상대로 수행되지않는 구성 요소를 결정하고 수정할 수 있다.
Sleuth
Spring Cloud 제품군에 포함된 Tool. TraceId, SpanId를 생성하고 이러한 정보를 서비스 호출을 위한 헤더나 MDC에 추가한다. 이는 Zipkin이나 ELK 같은 도구에서 인덱스나 프로세스 로그 파일을 저장하기 위해서 사용된다. Spring Cloud 제품군의 CLASSPATH에 추가되면 다음과 같은 공통 커뮤니케이션 채널에 자동으로 통합된다.
- RestTemplate 등에 의한 request
- Netfix Zuul microproxy를 통과하는 request
- Spring MVC 컨트롤러에서 수신된 HTTP header
- Apache Kafka나 RabbitMQ와 같은 메세징 기술을 통한 request
Tracing in Microservices With Spring Cloud Sleuth
https://dzone.com/articles/tracing-in-microservices-with-spring-cloud-sleuth
마이크로서비스가 확대되는 동안 개발자들이 맞닿뜨리는 문제 중 하나는 한 마이크로서비스에서 다음으로 전파된 요청을 추적하는 것이다. 특히 호출하는 마이크로서비스의 구현체에 대한 깊은 이해가 없을 때 어플리케이션을 통해 요청이 전달되는 방식을 파악하는 것은 매우 어려울 수 있다.
Spring Cloud Sleuth는 정확한 문제를 해결하기 위한 것이다. Sleuth는 단일 요청이 한 마이크로 서비스에서 다음 마이크로 서비스로 이동하는 방법을 찾을 수 있도록, 마이크로서비스 호출간에 일관된 고유 ID를 로깅에 도입한다.
Spring Cloud Sleuth는 TraceID, SpanID라는 두 가지 유형의 ID를 로깅에 추가합니다. SpanID는 HTTP 요청 전송과 같은 기본 작업 단위를 나타낸다. TraceID에는 트리와 유사한 구조를 형성하는 SpanID set이 포함된다. TraceID는 하나의 마이크로 서비스가 다음을 호출하는 동안 동일하게 유지된다.
(중략)
로그에 포함된 모든 추가 정보들은 훌륭하나, 모든 것을 이해하는 것은 상당히 번거로울 수 있다. ELK stack과 같은 것을 사용하여 마이크로서비스에서 로그를 모으고 분석하는 것이 매우 유용할 수 있다. TraceId를 사용하면 수집된 모든 로그를 쉽게 검색하고 한 마이크로 서비스에서 다음 마이크로서비스로 요청이 어떻게 전달되었는지 확인할 수 있다.
타이밍 정보를 보려면 어떻게 해야할까? 한 마이크로서비스에서 다음 마이크로서비스까지 request가 전달되는데 얼마나 오랜 시간이 걸렸는지 정확하게 계산하는 것은 꽤 힘든 작업이다. 이를 돕는 것이 Zipkin이라는 프로젝트이다. Spring Cloud Sleuth에 zipkin 종속성이 포함되면 Sleuth는 추적정보는 Zipkin 서버로 전송한다.
Distributed Tracing
이 주제에서는 GigaSpaces 클러스터에서 분산 추적을 활용하여 지연 문제를 식별하는 방법을 설명한다.
분산 추적은 복잡한 마이크로서비스 기반의 아키텍처를 모니터링하는 도구로써 빠르게 필수 컴포넌트가 되어가고 있다. 이를 통해 엔지니어는 오류를 정확하게 찾아내고 성능의 병목 현상을 식별할 수 있다.
GigaOps Stack의 일부인 GigaSpaces 모니터링에는 시스템의 지연 문제를 해결할 수 있도록 타이밍 데이터를 수집하는 분산 추적 시스템 인 Zipkin이 포함된다. 이를 통해보다 효과적인 성능 조정이 가능하다.
OpenTracing은 Vender에 구애받지 않는 추적을 위한 API이며 사용자가 분산 추적을 위해 자체 서비스나 라이브러리를 구성 할 수 있다.
자세한 내용은 https://opentracing.io/docs/overview/를 참조하라.
Zipkin Tracing Integration
What is Zipkin?
Zipkin은 Google의 Dapper를 기반으로한 유저의 request 플로우나 성능 측정/분석에 대한 정보를 수집하는 분산 추적 기술이다. 오픈 소스이며 밴더 중립적인 API인 Zipkin을 사용하면 분산 애플리케이션 분석과 (특히 애플리케이션 성능을 위해) 데이터를 식별하고 수집 할 때 밴더 종속을 피할 수 있다.
Zipkin에서는 어플리케이션별 동작에 대한 통찰력을 얻기 위해 개발자들이 커스텀 코드베이스에서 기능적으로 추적을 생성하는 것이 가능하다. 프레임 워크는 Zipkin을 사용하여 특정한 프레임워크에 동일한 추적기능을 제공 할 수 있다.
Collecting Application Traces with Zipkin
Zipkin을 사용하여 특정 코드베이스에서 추적을 수집하는 것은 수동 프로세스이다. Zipkin은 많은 (instrumentation-계측이라고 불리는) 공통 라이브러리와의 통합을 제공한다. 그러나 고유한 내부 라이브러리 및 프레임 워크는 개발자가 수동으로 측정해야한다.
Microservices Observability With Zipkin and Spring Cloud-Sleuth
https://medium.com/swlh/microservices-observability-with-zipkin-and-spring-cloud-sleuth-66508ce6840
마이크로 서비스에 대한 수요가 증가하고 대부분의 조직이 마이크로 서비스 아키텍처에 집중한다.
What is Microservice Observability(식별/관찰)?
일반적으로 성공, 실패, 예외 등 모든 동작을 관찰 할 수 있는 능력이다. 모든 동작을 관찰하면 그에 따라 문제를 해결하고 어플리케이션을 더 견고하고 내결함성있게 만들기 위한 조치를 취할 수 있다.
예를 들어, 보안 카메라는 하루의 모든 활동을 기록한다. 비정상적인 활동이 발생하면 보안 카메라를 철저히 관찰하고 특정 기간 동안 의심스러운 활동에 대해 결론을 내릴 것이다.
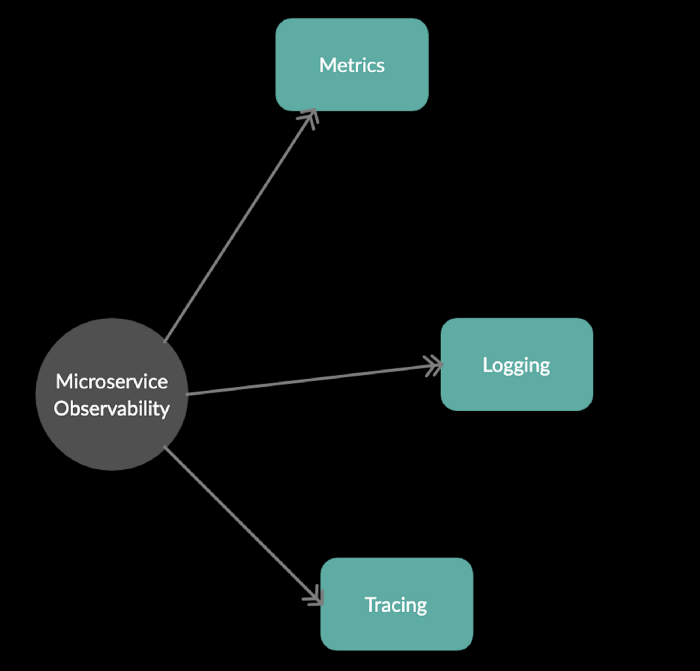
Observability의 주요 컨셉
- Metrics : 일정 기간동안 마이크로서비스 주변에서 발생한 일을 이해하기 위한 통계
- Logging : 요청이 성공, 실패, 예외인지 여부에 관계없이 시스템 주변의 문제를 분석하는 것을 도움
- Tracing : 마이크로 서비스 에코 시스템에서 workflow/request는 여러 서비스와 통신하기 때문에 생산적인 방식으로 workflow를 추적하는 것을 도움.
Zipkin의 사용
Zipkin은 Google 내부적으로 구축된 분산 어플리케이션 디버거인 dapper를 설명하는 Google 문서의 개념을 기반으로 Twitter에서 개발되었다. 이는 데이터의 수집과 조회를 모두 관리한다. Zipkin을 사용하기위해 어플리케이션은 타이밍 데이터를 보고하도록 구현된다.
Zipkin은 어플리케이션 로그의 trace를 확인하여 어플리케이션 지연 시간을 모니터링하는데 도움이 된다. 시간순으로 정렬된 trace는 전체 시스템 성능을 분석하는 것과 지연 시간이 있는 컴포넌트를 식별하는데 도움이되기 때문이다.
What is Sleuth?
Sleuth는 spring-cloud 제품군에 속하며 헤더 및 MDC를 사용하여 여러 마이크로서비스와 통신 할 때 traceId, spanId를 생성한다. 이 정보는 Zipkin과 같은 도구에서 메트릭을 저장하고 인덱싱 및 처리하는데 사용된다. 클래스 패스가 한 번이라도 추가된 스프링 클라우드 제품군에서 왔으므로, RestTemplate, Zuul Proxy, Queue(RabbitMQ, Kafka), MVC 컨트롤러를 통해 외부 시스템에 대한 스프링 부트의 기본 통신 채널에 자동으로 통합된다.
Spring Cloud Sleuth와 Twitter의 Zipkin
프로젝트 설명에 따르면, Spring Cloud Sleuth는 Spring Cloud용 분산 추적 솔루션을 구현한다. 외부 시스템과의 모든 상호작용은 자동으로 계측되어야한다. 로그에서 간단하게 데이터를 캡처하거나 이를 원격 수집 서비스로 전송할 수 있다. Sleuth의 경우 원격 수집기 서비스는 Zipkin이다.
Zipkin은 스스로 "분산 추적 시스템"이라고 설명한다. 이는 마이크로 서비스 아키텍처의 지연 문제를 해결하는데 필요한 타이밍 데이터를 수집하는데 도움이된다. 수집과 조회는 Collector와 Query 서비스를 통해 모두 관리된다. Zipkin은 분산 시스템에서 마이크로서비스가 작동하는 방식에 대한 중요한 통찰력을 제공한다.
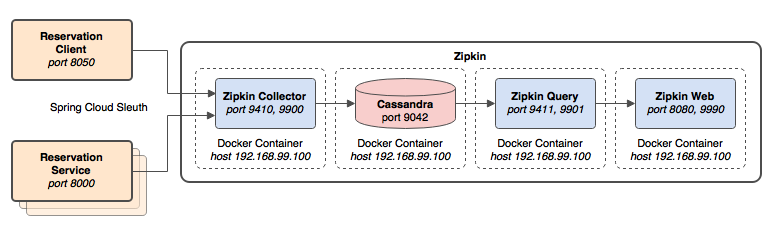
request를 예약 클라이언트의 service/message 엔드포인트 (http://localhost:8050/reservations/service-message)로 보내면 span으로 구성된 trace가 생성된다. 이 경우에 span은 HTTP 요청/응답 라이프사이클의 개별 세그먼트이다. trace는 수집되기 위해 Sleuth에서 Zipkin으로 보내진다. Spring에 따르면 spring-cloud-sleuth-zipkin이 사용 가능하다면 어플리케이션은 Brave를 이용해 Zipkin 호환 trace를 생성/수집한다. 기본적으로는 Apache Thrift를 이용해 port 9410의 Zipkin 수집기로 trace를 전송한다.
port 8080에서 실행되는 Zipkin의 웹브라우저 인터페이스를 trace를 확인하고 개별 span을 클릭함으로써 더 많은 정보를 확인할 수 있다.
Correlation IDs
Sleuth는 traceId와 spanId를 SLF4J MDC(Java용 단순 로깅 Facade - Mapped Diagnostic Context)에 주입한다. 스프링에 따르면 ID는 로그 집계기의 지정된 trace나 span에서 모든 로그를 추출하는 기능을 제공한다. 마이크로 서비스 아키텍처를 모니터링하고 지원하기 위해서는 correlation ID와 로그 집계의 사용이 필수적이다.
