[번역] MongoDB (1) Introduction to MongoDB, BSON Documents, Databases and Collections
Document 번역
2020.05.27
Introduction to MongoDB
ref. https://docs.mongodb.com/manual/introduction/
Document Database
MongoDB의 레코드는 Document이며 field와 value 쌍의 데이터 구조를 가지고 있다. MongoDB의 document는 JSON객체와 유사하다. 필드의 값은 다른 document, 배열, document 배열이 포함될 수 있다.
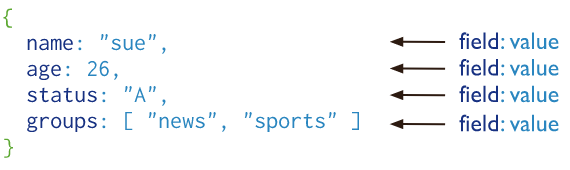
document를 사용함에 있어서 장점은 다음과 같다.
- (object와 같은) document은 많은 프로그래밍 언어에서 근본적인 데이터 유형에 해당한다.
- 내장된 document와 배열은 고비용의 join의 필요성을 줄인다.
- 동적 스키마는 다형성을 매우 잘 지원할 수 있다.
Collections / Views / 맞춤형의 구체화 된 Views
MongoDB는 document를 컬렉션으로 저장한다. 컬렉션은 관계형 데이터베이스의 테이블과 유사하다.
컬렉션으로 저장하는 것 외에도 읽기 전용 View(3.4+), 맞춤형의 구체화 된 View(On-Demand Materialized Views)를 지원한다.
주요 특징
✔️높은 퍼포먼스
MongoDB는 높은 성능의 데이터 지속성(data persistence)를 제공한다. 특히, 임베디드 데이터 모델을 지원하여 데이터베이스 시스템의 I/O 활동을 감소시키고, 내장된 document와 배열의 키를 포함하는 인덱스를 사용해 더 빠른 쿼리를 지원한다.
✔️ 다양한 기능을 제공하는 쿼리 언어
읽기와 쓰기 기능(CRUD)를 지원할 뿐만 아니라 데이터 집계, 텍스트 검색, 지리적 쿼리(Geospatial Queries)를 포함하는 풍부한 쿼리 언어를 제공한다.
참고 :
SQL to MongoDB Mapping Chart
SQL to Aggregation Mapping Chart
✔️높은 가용성
Replica set이라는 MongoDB의 복제 기능은 장애에 대한 자동 조치와 데이터 중복을 제공한다.
Replica set은 동일한 데이터 셋을 유지하면서 중복성을 제공하고 데이터의 가용성을 증대시키는 MongoDB 서버의 그룹이다.
✔️수평적 확장성
MongoDB의 핵심 기능으로 수평 확장성이 있다.
샤딩은 여러 시스템에 데이터를 분산시킨다.
3.4버전부터 MongoDB는 샤드키를 기반으로 데이터 영역 생성을 지원한다. 균형잡인 클러스터에서 MongoDB는 특정 영역의 읽기와 쓰기를 영역내의 샤드로만 보낸다.
❗️NOTE
샤딩(Sharding)은 여러 저장소에 데이터를 분산시키는 방법이다. MongoDB는 샤딩(sharding)을 사용하여 매우 큰 데이터 셋과 높은 처리량의 배포를 지원한다.
✔️여러 스토리지 엔진 지원
- WiredTiger Storage Engine (including support for Encryption at Rest)
- In-Memory Storage Engine.
추가적으로, MongoDB는 타사가 MongoDB용 스토리지 엔진을 개발할 수 있는 접속 가능한(pluggable) 스토리지 엔진 API를 제공한다.
BSON Documents
ref. https://docs.mongodb.com/manual/core/document/#bson-document-format
MongoDB는 데이터 레코드를 BSON document로 저장한다. BSON는 JSON 도큐먼트의 이진표현법으로 JSON보다 더 많은 유형의 데이터를 포함할 수 있다. BSON 스펙은 bsonspec.org에서 확인할 수 있다. 또한 BSON Types에 대해 궁금하다면 여기를 참고하라.
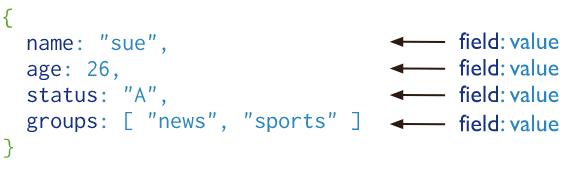
도큐먼트 구조
MongoDB 도큐먼트는 필드(field)와 값(value) 쌍으로 구성되어 있으며 다음의 구조를 가진다.
{
field1: value1,
field2: value2,
field3: value3,
...
fieldN: valueN
}필드의 값은 다른 도큐먼트, 배열, 도큐먼트의 배열을 포함하여 BSON 데이터 타입의 어떠한 것이라도 될 수 있다. 예를 들어 다음의 도큐먼트는 다양한 타입을 가지고 있다.
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}위의 필드들이 가지고 있는 데이터 타입은 다음과 같다:
- _id :
ObjectId를 가진다. - name : 필드 first와 last를 가지는
임베디드 도큐먼트를 가진다. - birth와 death :
Data타입의 값을 가진다. - contribs :
문자열 배열을 가진다. - views :
NumberLong타입의 값을 가진다.
✔️필드 이름
필드 이름은 문자열이다.
도큐먼트는 필드 이름에 대해 다음과 같이 제한을 둔다.
- 필드 이름
_id는 기본키로 사용하기 위한 예약어이다. 이 필드의 값은 컬렉션에서 고유하고, 불변하는 배열이 아닌 어떤 타입이면 가능하다. - 필드 이름은 null 문자를 포함 할 수 없다.
- 가장 상위의 필드 이름은
$문자로 시작할 수 없다. MongoDB 3.6 버전 이후에는 필드 이름이.과$문자를 포함하는 것을 허용한다.
IMPORTANT
MongoDB의 쿼리 언어는 필드 이름이 이러한 문자를 포함하는 document에 대해 항상 "의미가 잘 나타나는" 쿼리를 표현할 수 없다.
쿼리 언어에 이러한 문자에 대한 지원이 추가될 때까지$와.을 사용하는 필드 이름은 권장되지 않으며 공식 MongoDB 드라이버는 지원하지 않는다.
BSON document는 같은 이름의 하나 이상의 필드를 가질 수 있다. 하지만 대부분의 MongoDB 인터페이스는 중복된 필드 이름을 지원하지 않는 자료 구조(e.g. 해시 테이블)를 가진 MongoDB를 나타낸다. 하나 이상의 같은 이름을 가진 도큐먼트를 사용하길 바란다면 driver documentation을 참조하라.
내부 MongoDB 프로세스에 의해 작성된 일부 도큐먼트는 중복된 필드를 가질 수 있지만, 기존의 사용자 도큐먼트에 중복 필드를 추가하는 MongoDB 프로세스는 존재하지 않는다.
✔️필드 값 제한
fCV(featureCompatibilityVersion)가 "4.0" 또는 이전 버전으로 설정된 MongoDB 2.6 ~ MongoDB 버전의 경우 : 인덱싱된 컬렉션의 경우, 인덱싱된 필드의 값은 최대 인덱스 키 길이를 가집니다. 자세한 내용은 Maximum Index Key Length를 참조하십시오.
Dot Notation
MongoDB는 배열의 엘리먼트나 임베디드 도큐먼트의 필드에 접근하기 위해 dot Notation을 사용한다.
✔️배열
제로베이스 인덱스를 기준으로 배열 요소를 지정하거나 엑세스하려면 배열 이름을 .과 제로베이스 인덱스를 연결하고 큰따옴표"로 묶으면 된다.
"<array>.<index>"예를 들어 도큐먼트에 다음의 필드가 있다면,
{
...
contribs: [ "Turing machine", "Turing test", "Turingery" ],
...
}contribs 배열의 세번째 요소를 지정하기 위해선 dot notation "contribs.2"를 사용하면 된다.
더 많은 배열에 대한 쿼리를 보고 싶다면 Query an Array와 Query an Array of Embedded Documents를 참고하면 된다.
✏️SEE ALSO
$[]: 업데이트 작업을 위한 모든 위치를 가리키는 연산자
$[/<identifier/>]: 업데이트 작업을 위한 필터링된 위지 연산자
$: 업데이트 작업을 위한 위치 연산자이자 배열의 인덱스를 알 수 없는 경우 투영 연산자
✔️임베디드 도큐먼트
dot notation을 이용해 임베디드 도큐먼트의 필드를 지정하거나 엑세스하기 위해선 임베디드 도큐먼트의 이름과 필드 이름을 .으로 연결하고 큰따옴표"로 묶으면 된다.
"<embedded document>.<field>"예를 들어 도큐먼트에 다음의 필드가 있다면,
{
...
name: { first: "Alan", last: "Turing" },
contact: { phone: { type: "cell", number: "111-222-3333" } },
...
}name필드의 last라는 이름의 필드를 지정하기위해선 "name.last" dot notation을 사용한다.
contact 필드의 phone도큐먼트의 number를 지정하기 위해선 "contact.phone.number" dot notation을 사용한다.
임베디드 도큐먼트를 질의하는 더 많은 예는 Query on Embedded/Nested Documents와 Query an Array of Embedded Documents에서 살펴볼 수 있다.
제한사항
도큐먼트는 다음의 속성을 가진다.
✔️크기 제한
최대 BSON 도큐먼트의 사이즈는 16MB이다.
최대 도큐먼트 사이즈를 통해 하나의 도큐먼트가 과도한 양의 RAM을 사용하거나 전송 중에 과도한 양의 대역폭(bandwidth)를 사용할 수 없음을 보증한다. 최대 사이즈 이상의 도큐먼트를 저장하기 위해서 MongoDB는 GridFS API를 제공한다. 드라이버에 필요한 GridFS에 대한 더 많은 정보를 얻고 싶다면 mongofiles와 도큐먼트를 참고하라.
✔️필드 정렬
MongoDB는 다음의 경우를 제외하고는 작성된 순서로 문서의 필드가 저장된다.
_id필드는 항상 도큐먼트의 첫번째 필드이다.- 필드의 이름을 변경하는 업데이트의 경우 도큐먼트 내 필드는 재정렬된다.
✔️_id 필드
MongoDB에서 각각의 도큐먼트는 기본키의 역할을 하는 유일값인 _id필드가 요구된다. 만약 추가된 도큐먼트가 _id를 포함하고 있지 않다면 MongoDB 드라이버는 _id 필드를 위한 자동 증가하는 값의 ObjectId를 정의한다.
이는 upsert:true를 사용하는 업데이트 작업을 통해 추가된 도큐먼트에서도 적용된다.
_id 필드는 다음의 동작과 제약이 있다.
- 기본적으로 MongoDB는 컬렉션을 생성하는 동안
_id필드에 고유한 인덱스를 만든다. _id필드는 항상 도큐먼트의 첫번째 필드이다. 서버에_id필드가 첫번째에 존재하지 않는 도큐먼트가 추가된다면 서버는_id필드를 첫번째로 옮긴다._id필드는 배열을 제외한 모든 BSON 데이터 유형의 값이 포함될 수 있다.
WARNING📌
복제 기능을 보장하려면_id필드에 BSON 정규식 유형 값은 저장해선 안된다.
To ensure functioning replication, do not store values that are of the BSON regular expression type in the_idfield.
다음은 _id에 저장되는 값에 대한 일반적인 옵션이다.
- ObjectId를 사용하라.
- 가능하다면 일반적인(natural) 고유 식별자를 사용하라. 이는 공간을 절약하고 추가적인 인덱싱을 피하게 해준다.
- 자동 증가 번호를 생성하라.
- 애플리케이션 코드에서 UUID를 생성하라. 컬렉션과
_id의 UUID 값을 더 효율적으로 저장하려면 UUID를 BSON BinData 유형으로 저장하라.
다음과 같은 경우, BinData 유형의 인덱스 키가 인덱스에 더 효율적으로 저장된다.- 이진 서브타입 값은 0-7 또는 128-135의 범위에 있으며
- 바이트 배열의 길이는 0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24 또는 32이다.
- 드라이버의 BSON UUID 기능을 사용해 UUID를 생성하라. 드라이버를 구현할 때 UUID의 직렬화 및 역직렬화 로직을 다르게 구현할 수 있으므로 다른 드라이버와 완전히 호환되지 않을 수 있다는 점은 유의해야한다. UUID와의 상호 운용성에 대한 자세한 내용은 driver documentation을 참조하라.
❗️NOTE
대부분의 MongoDB 드라이버 클라이언트는_id필드를 포함하고 있으며 MongoDB로 insert 작업을 보내기전에ObjectId를 생성하지만, 클라이언트가_id필드없이 도큐먼트를 보낼 경우에mongod는_id필드를 추가하고ObjectId를 생성한다.
도큐먼트 구조의 기타 사용법
데이터 레코드를 정의하는 것 외에도 MongoDB는 query filters, update specifications documents, index specification documents와 다른 여러 구조에 대해 전반적으로 사용된다.
✔️Query filter Documents
Query filter Document는 읽기, 업데이트, 삭제 삭업에 대해 선택될 레코드를 결정하는 조건을 지정한다. <field>:<value> 식을 사용함으로써 동일한 조건을 지정하여 연산자 식을 질의할 수 있다.
{
<field1>: <value1>,
<field2>: { <operator>: <value> },
...
}✔️Update Specification Documents
Update Specification Document는 db.collection.update() 작업 중에 특정한 필드에 변경될 데이터를 지정하기 위해 업데이트 연산자를 사용한다.
ref. https://docs.mongodb.com/manual/tutorial/update-documents/#update-documents-modifiers
db.inventory.updateOne(
{ item: "paper" },
{
$set: { "size.uom": "cm", status: "P" },
$currentDate: { lastModified: true }
}
)위 예제는 inventory 콜렉션의 item이 "paper"인 첫번째 도큐먼트를 업데이트 한다.
- $set :
size.uom필드를 "cm"으로,status필드를 "P"로 업데이트한다. - $currentDate :
lastModified필드를 현재 날짜로 업데이트한다. 만약lastModified필드가 존재하지 않다면 $currentDate는 필드를 생성한다.
✔️Index Specification Documents
Index Specification Document는 특정 필드를 index와 index type으로 지정한다.
{ <field1>: <type1>, <field2>: <type2>, ... }2020.05.28
Databases and Collections
ref. https://docs.mongodb.com/manual/core/databases-and-collections/
Databases
MongoDB에서 데이터베이스는 도큐먼트의 콜렉션을 가지고 있다. 사용할 데이터 베이스를 선택하기 위해선 mongo 셀에서 use <db> 커멘드를 사용한다. (e.g. use myDB)
✔️Create a Database
데이터베이스가 존재하지 않으면 MongoDB는 해당 데이터베이스에 첫번째 데이터를 추가할 때 데이터베이스가 생성된다. 즉, 존재하지 않는 데이터베이스로 이동한 뒤 mongo셀에 다음처럼 연산을 수행시키면 된다.
use myNewDB
db.myNewCollection1.insertOne({x: 1})insertOne() 연산은 만약 myNewDB 데이터베이스와 myNewCollection1 컬렉션이 존재하지 않으면 새로 이들을 생성한다. 데이터베이스와 컬렉션 이름이 모두 MongoDB 명명 제한을 따르는지 확인하라.
🤔RDB와 비교하면 데이터베이스 = 스키마, 컬렉션 = 테이블 이라고 생각하면 될듯
Collections
MongoDB는 컬렉션 안에 도큐먼트를 저장한다. 컬렉션은 관계형 데이터베이스의 테이블과 유사하다.
✔️Create a Collection
만약 컬렉션이 존재하지 않으면, MongoDB는 해당 컬렉션에 첫번째 데이터를 저장할 때 컬렉션을 생성한다.
db.myNewCollection2.insertOne( { x: 1 } )
db.myNewCollection3.createIndex( { y: 1 } )insertOne()와 createIndex() 연산 모두 아직 각각의 컬렉션이 존재하지 않다면 이를 생성한다. 컬렉션 이름이 MongoDB 명명 제한을 따르는지 확인하라.
✔️명시적 생성
MongoDB는 최대 사이즈나 도큐먼트의 유효성 검사 규칙 설정같은 다양한 옵션과 함께 명시적으로 컬렉션을 생성하기 위한 db.createCollection() 메소드를 제공한다. 그런 옵션을 지정하지 않는 경우 MongoDB는 컬렉션에 첫번째 데이터를 저장할 때 새로운 컬렉션을 자동으로 생성하기 때문에, (db.createCollection() 메소드를 사용해) 컬렉션을 명시적으로 생성할 필요가 없다.
컬렉션 옵션을 수정하는 방법은 collMod에서 확인 할 수 있다.
✔️도큐먼트 유효성 검사
New in version 3.2
기본적으로 컬렉션은 도큐먼트가 같은 스키마를 가지는 것을 요구하지 않는다. 즉, 하나의 컬렉션 내의 도큐먼트는 같은 필드셋을 가질 필요가 없고, 필드의 데이터는 컬렉션 내의 도큐먼트에 따라 다른 타입을 가질 수 있다.
하지만, MongoDB 3.2부터 update나 insert 연산을 하는 동안에 컬렉션의 도큐먼트 유효성 검사 규칙을 지정할 수 있다. 자세한 내용은 Schema Validation을 참조하라.
✔️도큐먼트 구조 갱신
새로운 필드를 추가하기, 필드 지우기, 필드의 값을 새로운 타입으로 변경하기 등과 같은 컬렉션 내의 도큐먼트의 구조를 변경하기 위해서 새로운 구조로 도큐먼트를 업데이트 할 수 있다.
✔️유일 식별자
New in version 3.6
❗️NOTE
featureCompatibilityVersion는 "3.6"또는 그 이상부터 설정되었다. 더 많은 정보는 View FeatureCompatibilityVersion를 참조하라.
컬렉션에는 불변의 UUID가 할당된다. 컬렉션 UUID는 복제본 셋의 모든 멤버와 샤드 클러스터의 샤드에서 동일하게 유지된다.
컬렉션에 대한 UUID를 검색하려면 listCollections 명령 또는 db.getCollectionInfos() 메소드를 실행하라.
