
Spring Cloud Sleuth를 번역합니다.
Introduction
용어
✔️ Spring Cloud Sleuth는 Dapper의 용어를 사용한다.
Span
기본 작업 단위로써 RPC(Remote Procedure Call, 별도의 원격 제어를 위한 추가적인 코드를 작성하지 않고 다른 주소 공간에서 리모트의 함수나 프로시저를 실행 할 수 있게 해주는 프로세스간 통신)를 보내는 것과 RPC에 응답을 보내는 것이 각각의 새로운 span이다. span을 식별하는 데는 64bit의 고유 id와 span을 포함하고 있는 trace의 고유 id가 사용된다. span은 설명, 시간이 기록된 이벤트(timestamped events), 키-벨류 어노테이션(태그), 해당 span을 유발시킨 span의 id, 프로세스 id(일반적으로 ip 주소이다.) 등의 데이터를 포함한다.
span은 생성된 순간부터 시간 정보를 추적하며 최종적으론 중단되어야한다.
추적을 시작하는 초기 span을
root span이라고 부른다. 이 span의 id는 trace id와 동일하다.
Trace
트리 구조로 이뤄진 span 셋. 예를 들어, 분산된 빅데이터 스토어를 실행하는 경우 trace는 PUT 리퀘스트에 의해 형성 될 수 있다. (?) For example, if you run a distributed big-data store, a trace might be formed by a PUT request.
Annotation
이벤트를 적절한 때에 기록할 수 있도록 사용된다. Brave 측정을 사용하면 클라이언트와 서버가 누구인지, 어디서부터 요청이 시작되고 종료됐는지 Zipkin에게 이해시키기 위한 특별한 이벤트를 설정할 필요가 없다. 그러나 (??를) 학습 시키기 위해 이러한 이벤트를 표시하여 어떤 액션이 발생했는지 강조한다.
아래 어노테이션은 특정한 순간에 추가된다.
- cs (Client Sent) : 클라이언트가 요청한 순간. span의 시작을 나타낸다.
- sr (Server Received) : 서버가 클라이언트의 요청을 받고 처리를 시작한 순간. sr 타임스탬프 - cs 타임스탬프 = 네트워크 대기 시간
- ss (Server Sent) : 요청의 처리가 완료된 순간. (즉, 응답이 클라이언트로 전송되는 순간.) ss 타임스탬프 - sr 타임스탬프 = 서버가 요청을 처리하는데 걸린 시간
- cr (Client Received) : 클라이언트가 서버 측에서 보낸 응답을 받는데 성공한 순간. Span의 종료를 나타낸다. cr 타임스탬프 - cs 타임스탬프 = 클라이언트가 서버에 요청을 보낸 뒤 응답을 받는 순간까지 걸린 전체 시간
다음의 이미지는 ZipKin 어노테이션과 함께 시스템에서 Span와 Trace가 어떻게 표현되는지를 보여준다.
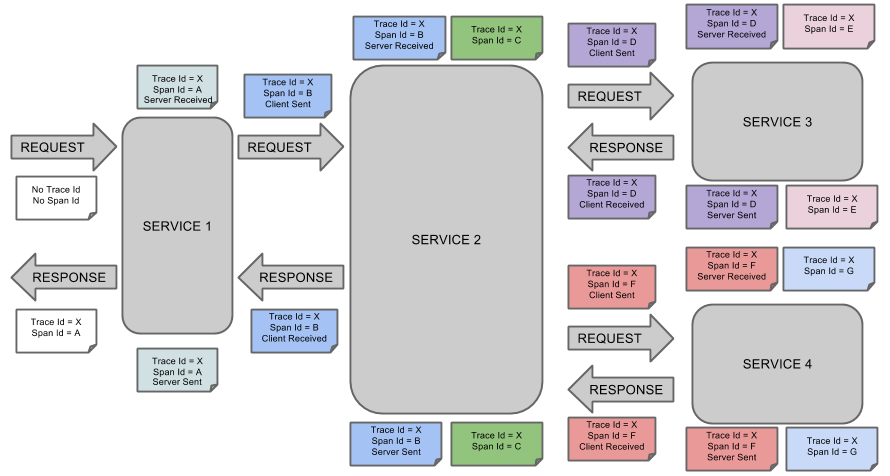
각 메모의 색상이 Span을 나타낸다. (위 이미지에서는 A~G의 7개의 Span이 있다.)
Trace Id = X
Span Id = D
Client Sent다음 이미지는 Span의 부모-자식 관계를 보여준다.
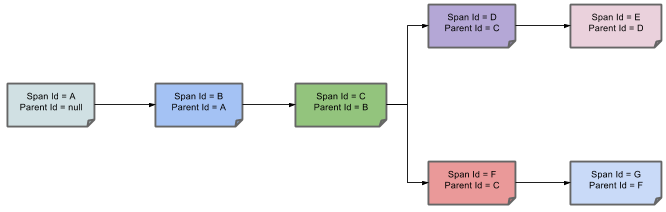
목적
Zipkin을 사용한 분산 추적
❗️ Zipkin ref. https://zipkin.io/
분산 추적 시스템으로써 서비스 아키텍처의 지연 문제를 해결하는 데 필요한 timing data를 수집하는 것을 돕는다. 또한 이러한 데이터의 수집 뿐만아니라 조회도 포함한다.로그 파일에 trace ID가 있다면 한번에 그 위치로 이동할 수 있다. trace ID가 없다면 서비스, 작업의 이름, 태그, 기간과 같은 속성을 사용해 질의할 수 있다. 뿐만 아니라 서비스에서 각 작업이 수행되는데 걸린 시간의 비율, 작업의 실패 여부 등 몇 가지 흥미로운 데이터의 요약본을 확인 할 수 있다.
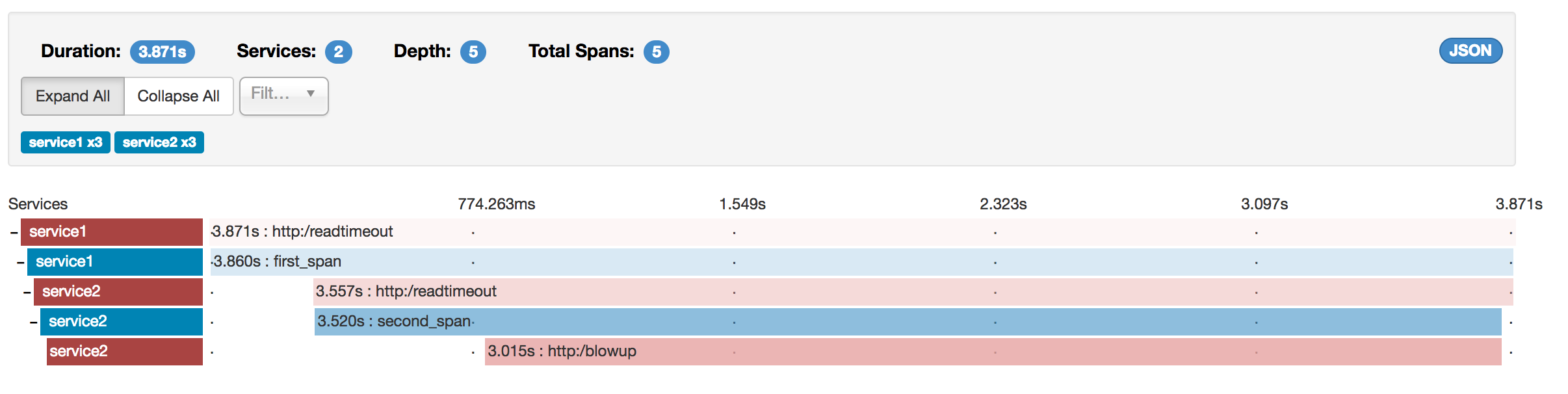
이 예제(위에서 보여준 예제와 동일하다.)에는 7개의 span이 있다. Zipkin에서 traces로 이동하면 다음 이미지에서 볼 수 있듯이 두번째 trace에서 이 숫자(7)를 확인할 수 있다.
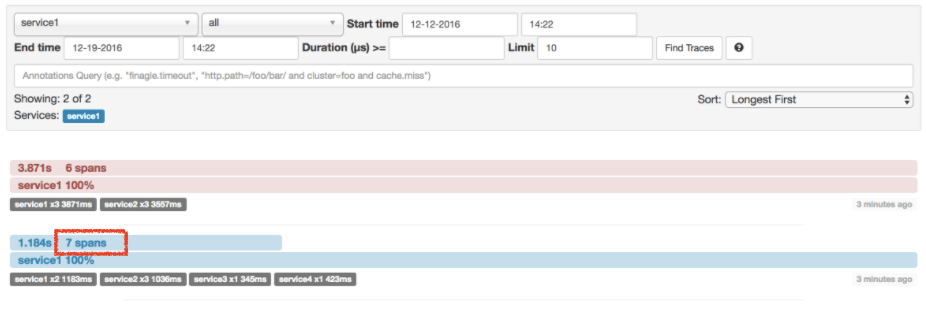
특정 trace를 선택하면 다음처럼 4개의 span을 볼 수 있다.
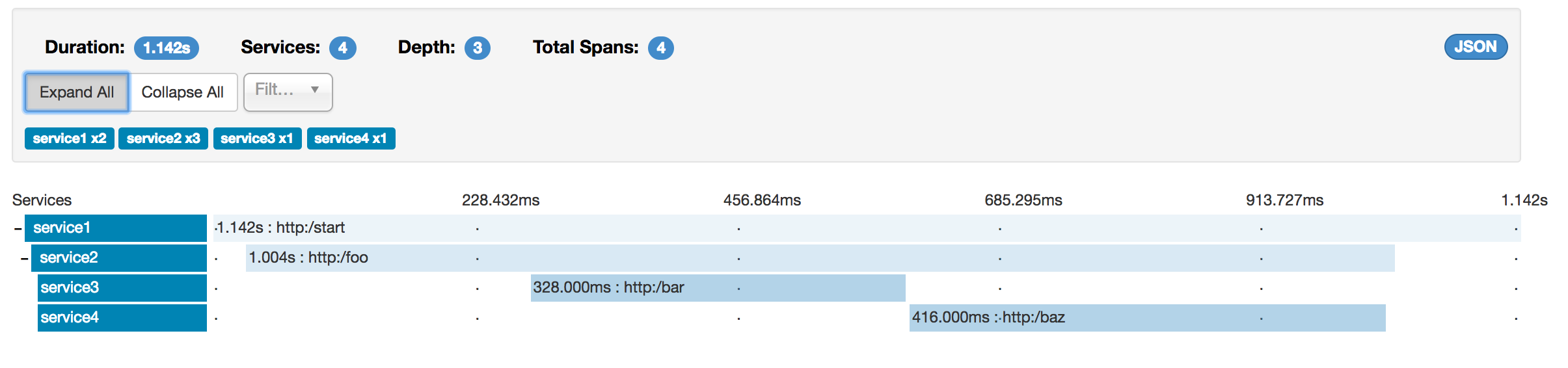
이는 trace를 선택하면 Zipkin에 (sr, ss) 혹은 (cr, cs) 쌍의 span이 전송된 경우 단일 span으로 병합하여 표시하기 때문이다.
http:startspan에서 나온 하나의 span은 sr와 ss 어노테이션을 가진다.service1에서service2로 향하는 RPC 호출에서http:/foo엔드포인트까지 2개의 span이 생성되는데 (1)cs와 cr이벤트는service1쪽에서, (2)sr와 ss 이벤트는service2에서 발생한다. 이 두 span은 RPC 호출과 관련된 하나의 논리적 span을 형성한다.service2에서service3로 향하는 RPC 호출에서http:/bar엔드포인트까지 2개의 span이 생성되는데 (1)cs와 cr이벤트는service2쪽에서, (2)sr와 ss 이벤트는service3쪽에서 발생한다. 이 두 span은 RPC 호출과 관련된 하나의 논리적 span을 형성한다.service2에서service4로 향하는 RPC 호출에서http:/baz엔드포인트까지 2개의 span이 생성되는데 (1)cs와 cr이벤트는service2쪽에서, (2)sr와 ss 이벤트는service4쪽에서 발생한다. 이 두 span은 RPC 호출과 관련된 하나의 논리적 span을 형성한다.
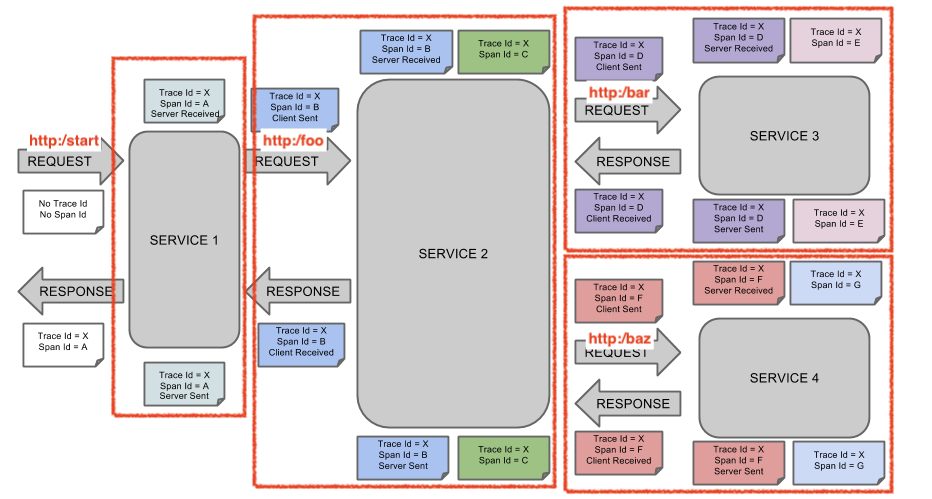
물리적 span의 개수를 세면 http:/start로부터 1개, service1가 호출한 service2에서 2개, service2에서 호출한 service3, service4에서 각각 2개가 있으므로 7개의 span을 가지게 된다.
논리적으로는 service1로 들어오는 요청과 관련된 1개의 span과 RPC 호출과 같은 3개의 span이 있으므로 총 4개의 span을 확인 할 수 있다.
에러 시각화
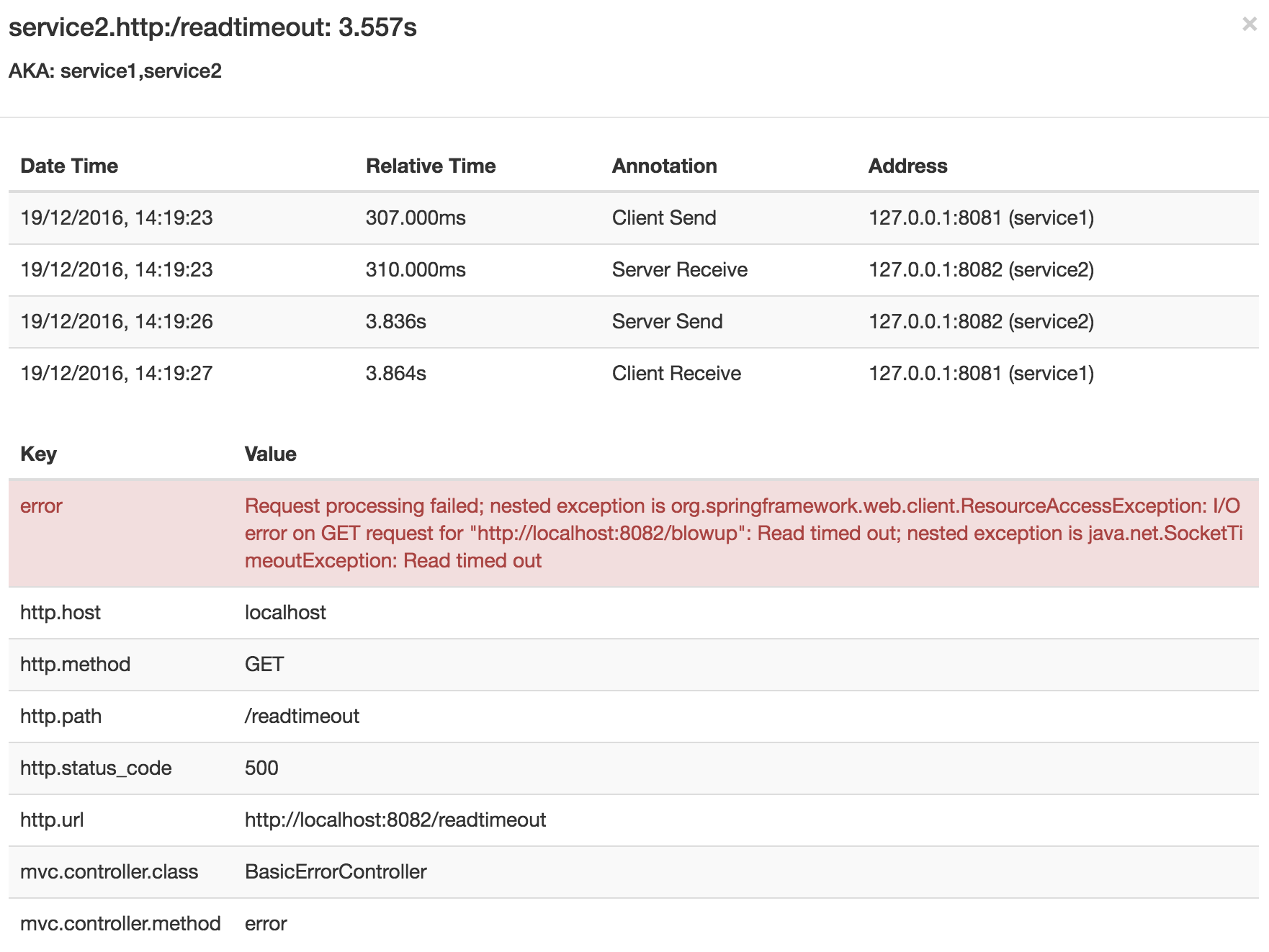
Zipkin을 사용하면 trace 내 오류를 시각화 할 수 있다. 예외가 발생하였으나 포착되지 않은 경우, span에 적절한 태그를 설정함으로써 Zipkin에서 색상으로 이를 구별할 수 있도록 만들 수 있다. trace 리스트에서 빨간색으로 표시된 것은 예외가 발생한 구간이다
아래는 trace를 클릭한 경우에 볼 수 있는 화면이다.
span중 하나를 클릭하면 다음처럼 오류의 원인과 이와 관련된 전체 추적을 보여준다.
Brave를 사용한 분산 추적
Spring Cloud Sleuth 2.0.0 버전부터 Brave를 추적 라이브러리로 사용한다. 이를 통해 Sleuth는 컨텍스트를 저장하는 작업을 직접 수행하는대신 Brave에게 위임할 수 있게 되었다.
Sleuth와 Brave는 서로 다른 네이밍/태깅 규칙을 가지기 때문에 Sleuth측이 Brave의 규칙을 따르기로 했다. 하지만 spring.sleuth.http.legacy.enabled = true 설정을 사용해 레거시 Sleuth 접근법을 사용할 수 있다.
Log correlation
네가지 어플리케이션의 로그에 grep으로 특정 trace Id를 스캔하면 다음과 유사한 출력을 볼 수 있을 것이다. (아래 예제에서는 2485ec27856c56f4라는 값으로 스캔하였다.)
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]로그 집계 도구인 Kibana나 Splunk 등을 사용하면 보기좋게 발생한 이벤트를 정렬할 수도 있다. 다음 이미지는 Kibana를 사용한 예이다.
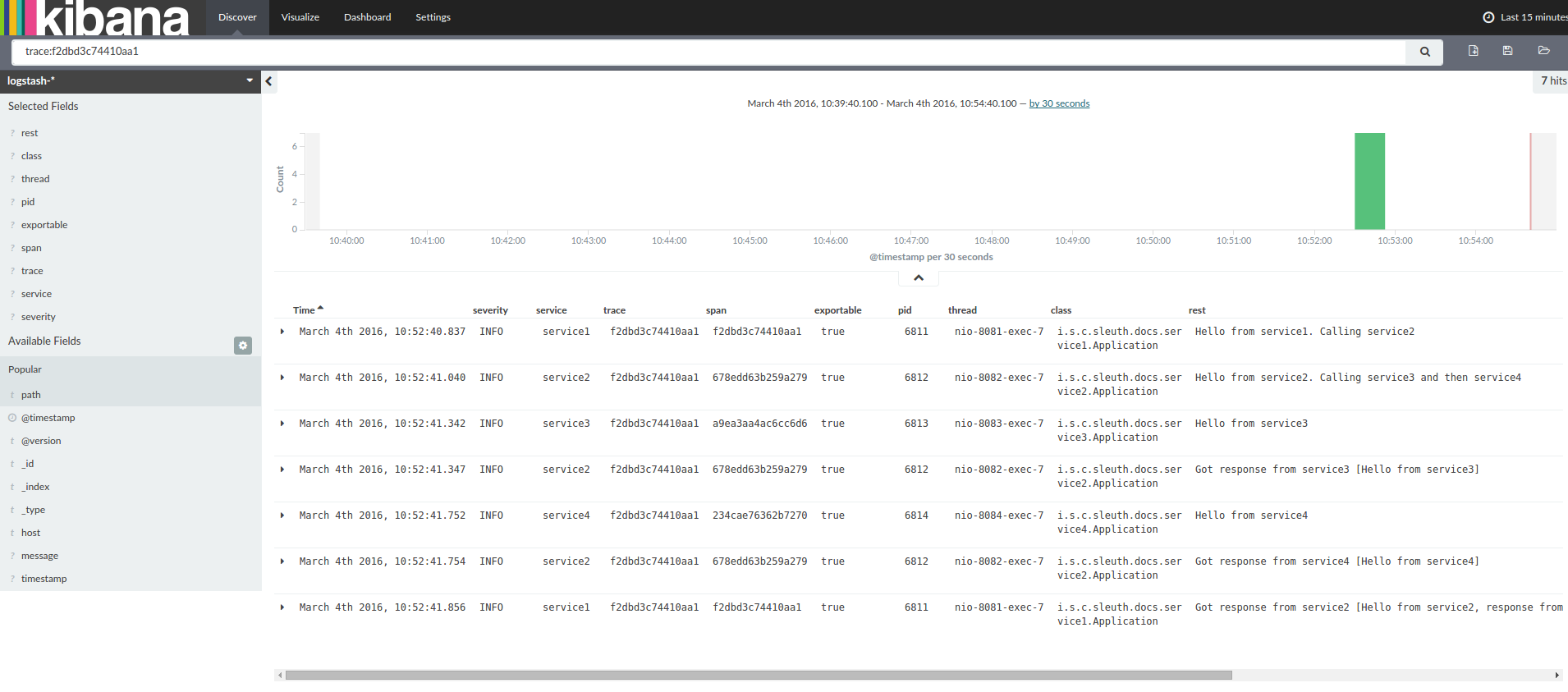
❗️ Note
Kibana : 엘라스틱 서치를 위한 오픈 소스 데이터를 시각화해주는 대시 보드이다.
Splunk : 대량의 데이터를 웹 스타일 인터페이스를 통해 검색, 모니터링, 분석 가능하게 한다.
Logstash를 사용하려는 경우, Logstash를 위한 Grok 패턴은 다음과 같다.
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}Cloud Foundry의 로그와 함께 Grok을 사용하려면 다음 패턴을 사용해야한다.
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}❗️ Note
Logstash : 형식이나 복잡성에 관계없이 데이터를 동적으로 수집, 전환, 전송한다. grok을 이용해 비구조적 데이터에서 구조를 도출하여 IP 주소에서 위치 정보 좌표를 해독하고, 민감한 필드를 익명화하거나 제외시키며, 전반적인 처리를 손쉽게 해준다.
grok : 비정형 데이터를 파싱하여 정형데이터로 만드는 라이브러리. key/value 형태로 적재한다.
Logstash를 사용한 JSON Logback
로그를 텍스트 파일 대신 Logstash가 즉시 사용할 수 있는 JSON 파일로 저장하려면 다음의 절차가 필요하다.
Dependencies Setup
- Logback이 클래스 경로(
ch.qos.logback:logback-core)에 있는지 확인한다. - Logstash Logback 인코딩을 추가한다. (e.g.
net.logstash.logback:logstash-logback-encoder:4.6)
Logback Setup
Logback 구성 파일(logback-spring.xml)은 다음을 참고한다.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"baggage": "%X{key:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>- 애플리케이션 정보를 JSON format으로
build/${spring.application.name}.json파일에 기록 - 콘솔과 표준 로그 파일은 주석처리
- 이전 섹션에서 보여준 것과 동일한 로깅 패턴을 포함한다.
직접 작성한
logback-spring.xml를 사용하는 경우, 어플리케이션 프로퍼티 파일 대신spring.application.name을 부트스트랩에 전달해야한다. 그렇지 않으면 해당 logback 파일이 프로퍼티를 제대로 읽지 못한다.
Propagating Span Context
span 컨텍스트는 프로세스 경계를 넘어 모든 하위 span에게 전달되어야하는 상태값이다. 즉, span 컨텍스트에는 필수요소인 trace Id와 span Id 뿐만 아니라 전달되기 위한 (어떤)값을 선택적으로 포함할 수 있다. 그리고 이 값을 Baggage로 부르기로 한다.
Baggage는 span 컨텍스트에 저장된 key:value 쌍들의 집합이다. 이는 trace와 함께 이동하며 모든 span에 전달된다. Spring Cloud Sleuth는 HTTP 헤더 앞에 baggage-가 붙거나, 메세징의 경우 baggage_로 시작하는 경우 헤더가 Baggage와 관련있음을 인지한다.
현재 baggage 개수나 크기에 제한은 없다. 하지만 그 수가 너무 많으면 시스템의 처리량이 감소하거나 RPC 대기시간이 증가할 수 있다. 극단적인 경우로는 너무 많은 baggage는 전송수준의 메세지나 헤더 용량을 초과시켜 어플리케이션에 문제를 일으킬 수도 있다.
다음은 span에 baggage를 설정하는 예시이다.
Span initialSpan = this.tracer.nextSpan().name("span").start();
ExtraFieldPropagation.set(initialSpan.context(), "foo", "bar");
ExtraFieldPropagation.set(initialSpan.context(), "UPPER_CASE", "someValue");Baggage vs. Span Tags
Baggage는 trace와 함께 이동한다. (모든 자식 span은 부모의 baggage를 포함한다.) Zipkin은 Baggage를 알지못하며 해당 정보를 받지 않는다.
Sleuth 2.0.0 부터는 프로젝트 configuration에서 명시적으로 baggage 키 네임을 전달해야한다. 해당 설정은 여기에서 자세히 알아볼 수 있다.
Tags은 특정한 span에 첨부된다. 즉, 오로지 특정 span에게서만 표시되는 것이다. 하지만 tag를 가지고 있는 span이 있다면, 어떤 trace를 찾기위해 tag를 이용할 수 있다.
baggage를 기준으로 span을 조회하기 위해서는 해당 항목을 root span에 tag로 추가해야한다.
❗️ span은 반드시 범위 내에 있어야한다.
다음은 baggage를 사용하는 통합 테스트 예시이다.
설정
spring.sleuth:
baggage-keys:
- baz
- bizarrecase
propagation-keys:
- foo
- upper_case코드
initialSpan.tag("foo",
ExtraFieldPropagation.get(initialSpan.context(), "foo"));
initialSpan.tag("UPPER_CASE",
ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));프로젝트에 Sleuth 추가하기
이 섹션에서는 Maven/Gradle을 사용해 프로젝트에 Sleuth를 추가하는 방법을 설명한다.
어플리케이션 이름을 Zipkin에 제대로 표시하기 위해서는
bootstrap.yml의spring.application.name프로퍼티를 설정하라.
Only Sleuth (log correlation)
Zipkin 통합없이 오로지 Spring Cloud Sleuth만 사용하려면 spring-cloud-starter-sleuth를 추가한다.
dependencyManagement { //1
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { //2
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}1️⃣ 버전을 직접 관리하지 않도록 Spring BOM을 통한 종속성 관리를 추가하는 것을 추천한다.
2️⃣ dependencies에 spring-cloud-starter-sleuth를 추가한다.
HTTP를 통해 Zipkin을 Sleuth와 함께 사용하기
Sleuth와 Zipkin을 모두 사용하기 원한다면 spring-cloud-starter-zipkin를 추가한다.
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}RabbitMQ나 Kafka를 통해 Zipkin을 Sleuth와 함께 사용하기
❗️ NOTE
RabbitMQ :
Kafka :
HTTP 대신 RabbitMQ 또는 Kafka를 사용하려면 spring-rabbit 또는 spring-kafka 종속성을 추가해야한다. 목적지의 디폴트 이름은 zipkin이다.
kafka를 사용하는 경우 spring.zipkin.sender.type 속성을 설정해 줘야한다.
spring.zipkin.sender.type: kafka❗️
spring-cloud-sleuth-stream는 더 이상 사용되지 않으며 목적지와 호환되지 않는다.
RabbitMQ를 사용하는 경우 spring-cloud-starter-zipkin와 spring-rabbit를 추가한다.
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
compile "org.springframework.amqp:spring-rabbit" // 1
}1️⃣ RabbitMQ를 자동으로 구성하려면 spring-rabbit 종속성을 추가한다.
Zipkin 자동 구성 재정의
Spring Cloud Sleuth는 버전 2.1.0부터 여러 추적 시스템에 동시에 trace를 전송할 수 있다. 이 작업을 수행하기위해 모든 추적 시스템은 Reporter<Span\>와 Sender가 필요하다. 기본적으로 제공되는 Bean을 대체하려면 특정 이름을 전달해야하는데 각 빈에 대해 ZipkinAutoConfiguration.REPORTER_BEAN_NAME과 ZipkinAutoConfiguration.SENDER_BEAN_NAME를 사용하면 된다.
@Configuration
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter() {
return AsyncReporter.create(mySender());
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
} 