
입력한 사진을 분석하는 루틴을 추가해서 사진들에서 사람의 얼굴을 찾아보겠습니다.
출력 사진 변경
리스트를 보는 페이지 외에도 하나의 파일만 보도록 하는 페이지를 추가했습니다. 해당 페이지에서 파일 원본을 보는 대신에 face detect된 사각형을 그려서 출력하는 형태로 먼저 패치해보겠습니다.
load_image 교체
stream(?)으로 처리 시도
send_from_director는 경로를 입력받고 해당 파일을 다이렉트로 보내주기때문에, 그 전에 전처리를 하고 send_file을 통해서 fp를 넘기는 형태를 목표해보겠습니다.(in_memory 이미지 개체도 fp로 인식하는건가..?)
from . import cluster
return send_file(cluster.load_image(path))
def load_image(path)
return face_recognition.load_image_file(path)로 1차 수정을 했지만 실패합니다. 해서 load_image_file의 정의를 보러갔더니 이 친구는 이미지를 이미지 객체로 가지고 있는게 아니라 분석을 위한 numpy array 객체로 들고있다고 합니다. 반환 하기전에 일단 이미지 객체로 바꾸는 과정이 필요해보입니다.
file로 내렸다가 회수하도록 수정
numpy array를 받았다가 face_nocation 박스처리를 하고, 임시 디렉토리에 파일을 떨군다음에 새로운 경로를 올려보내주는 것으로 수정해보겠습니다.
cluster.py
import os
import face_recognition
import cv2
def get_located_image_path(path):
dir_path = "/home/hanchi/work/face_clustering/flask_clustering/located"
file_name = os.path.basename(path)
located_path = os.path.join(dir_path, file_name)
npa = load_numpy_array(path)
draw_face_list_on_npa(npa, face_recognition.face_locations(npa))
cv2.imwrite(located_path, npa[:, :, ::-1])
return located_path
def load_numpy_array(path):
return face_recognition.load_image_file(path)
def draw_face_list_on_npa(npa, locations):
for location in locations:
(top, right, bottom, left) = location
cv2.rectangle(npa, (left, top), (right, bottom), (255, 0, 0), 2)
return nparesource.py에서 호출하는 함수는 get_located_image_path 함수입니다. 변경한 사진파일의 저장 경로를 반환함으로서 주소는 그대로지만 내부에서는 변경된 경로의 파일이 반환됩니다.
인식된 얼굴들을 따로 출력
원래 이 부분은 db와 연동되야하는 부분이 훨씬 많지만 일단 썸네일 생성하고, 출력하는 부분을 먼저 진행해보겠습니다. cluster.py 단에서 썸네일을 먼저 생성해봅니다.
cluster.py
어질러진 코드가 막 생성되고 있는중입니다. 붉은 사각형을 그리는 대신, box에 해당하는 이미지를 thumbnail 폴더에 저장하도록 수정했습니다. 저 파일을 sqlite에 다이렉트로 넣을지, 학습처리를 위해서 폴더 단위로 구분해놔야되는지 아직 정확하게 파악이 안되서 일단 만들어만 놓도록 하겠습니다.
def get_located_image_path(path):
located_dir_path = "/home/hanchi/work/face_clustering/flask_clustering/located"
thumbnail_dir_path = "/home/hanchi/work/face_clustering/flask_clustering/thumbnail"
file_name = os.path.basename(path)
located_path = os.path.join(located_dir_path, file_name)
thumbnail_path = os.path.join(thumbnail_dir_path, file_name)
npa = load_numpy_array(path)
locas = face_recognition.face_locations(npa)
# draw_face_list_on_npa(npa, locas)
make_thumbnail_list_on_npa(npa, locas, thumbnail_path)
cv2.imwrite(located_path, npa[:, :, ::-1])
return located_path
def make_thumbnail_list_on_npa(npa, locas, thumbnail_path):
i = 0
dir_path = os.path.dirname(thumbnail_path)
(file_name, file_ext) = os.path.splitext(os.path.basename(thumbnail_path))
for location in locas:
(top, right, bottom, left) = location
print(os.path.join(dir_path, (file_name+"-"+str(i)+file_ext)))
cv2.imwrite(os.path.join(dir_path, (file_name+"-"+str(i)+file_ext)),
get_face_array(npa[:, :, ::-1], location))
i += 1
def get_face_array(npa, box):
img_height, img_width = npa.shape[:2]
(top, right, bottom, left) = box
box_width = right - left
box_height = bottom - top
top = max(top - box_height, 0)
bottom = min(bottom + box_height, img_height - 1)
left = max(left - box_width, 0)
right = min(right + box_width, img_width - 1)
return npa[top:bottom, left:right] 출력된 사진들을 연결해서 띄워본다
좀 더 견고하게 묶어버리고 싶지만 지금은 일단 각 기능들만 슈루룩 짜고있으므로, 좀 더 엉망진창에 몸을 맡기고 뛰어들어봅니다. 이번에는 파일을 업로드 할 때가 아니라 대상 파일만 처음으로 따로 열었을 떄 처리하도록 변경 해보겠습니다. 그리고 계속 로드하게 해놨더니 자꾸 찔끔찔끔 틱이 오는 느낌이라서, check_level(0 미확인, 1 face_recognition, 2 사람)을 부여해서 0일 때만 작동하게 하겠습니다. file.py파일에서 파일을 하나만 여는 view인 file_detail을 수정합니다. 기존에는 id에 맞는 하나의 row만 fetch해오는 루틴만 있었습니다.
뷰 수정
두 가지 루틴을 추가적으로 적용하도록 합니다.
1. check_level이 0일 때, 썸네일을 만들어서 file과 face(썸네일 스키마)을 연결해주는 것.
2. 연결되어있는 face들이 있다면, 해당 face들의 정보도 함께 반환해서 출력할 수 있도로 하는 것.
file.py
...
@bp.route('/<int:file_id>')
def file_detail(file_id):
db = get_db()
file = db.execute(
'SELECT f.id, f.name, f.path, f.created, f.uploaded, username, user_id, f.check_level FROM file f JOIN user u'
' ON f.user_id = u.id WHERE f.id = '+str(file_id)+' ORDER BY created, uploaded DESC'
).fetchone()
# check 레벨 체크
if file['check_level'] == 0: # didn't make thumbnail
cluster.make_thumbnail(file['user_id'], file_id, file['path']) # thumbnail 생성
db.execute(
'UPDATE file SET check_level = ?'
' WHERE id = ?',
(1, file_id)
)
db.commit() # check_level 업데이트
# file 관련 thumbs 레코드들 가져오고
thumbs = db.execute(
'SELECT thumb_path, file.id as file_id FROM file INNER JOIN face ON file.id = face.file_id and file.id = '+str(file_id)
).fetchall()
# db 정보들 반환
return render_template('file/file_detail.html', file=file, thumbs=thumbs)
...글을 작성하다가 더 뼈져리게 느낀 것이 있는데, 현재 thumbnail과 face를 혼용해서 사용하고 있습니다. thumbnail은 cluster에서 네이밍 할 때 사용했고, face는 model 설정할 때 사용했는데.. 막 개발이다보니까 기틀이 없는 느낌입니다.콩가루 코딩 다음에 하나로 통일해야겠습니다.
라이브러리 수정
음.. 용어를 뭐라고 해야할지 몰라서 일단, 라이브러리 수정이라고.. ㅎㅎ.. recognition과 관련된 내용들은 대충 cluster.py 파일 안에 몰아넣고 있습니다. 이 파일 안에서 인식된 얼굴에 대한 썸네일 생성과 db에 데이터를 저장하는 과정을 진행합니다.
cluster.py
def make_thumbnail(user_id, file_id, file_path):
tpg = thumbnail_path_gen(user_id, file_id, file_path) # thumbnail path를 생성하는 클래스(..!)
npa = load_numpy_array(file_path) # 원본 파일 로드
boxes = face_recognition.face_locations(npa) # 얼굴 인식 후 로케이션들 기록합니다.
for i in range(len(boxes)): # 로케이션들을 썸네일로 만들어서 임시 저장합니다.
cv2.imwrite(tpg.get_index_path(i),
get_face_array(npa[:, :, ::-1], boxes[i]))
db = get_db()
for i in range(len(boxes)):
(top, right, bottom, left) = boxes[i]
db.execute( # 썸네일을 디비에도 저장합니다. 현재는 thumbnail의 임시 경로를 저장해두도록 했습니다.
'INSERT INTO'
' face (user_id, file_id, face_index, top, right, bottom, left, origin_path, thumb_path)'
' VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)',
(user_id, file_id, i, top, right, bottom, left, file_path, tpg.get_index_path(i))
)
db.commit()맨날 C만했더니핑계 그냥 변수가 많이 쓰기 싫어서 이번에 시작하고 python에서 처음으로 클래스를 사용해봤습니다(...). 원래는 for문이 하나로 되있었는데, 파일 생성과 execute를 번갈아하게 될 경우에 속도나 다중 실행 시 문제가 있을 수 있어서 분리하는게 더 낫다고 판단했습니다. 현재의 목표는 일단 작게 구현하는 것이기때문에 쬐꼼하게 빨리 돌아갈 수 있게 한다고 뚝딱뚝딱 해보았습니다.
인식된 얼굴 추가 결과
로컬에 썸네일 폴더를 만들어주고 해당 페이지를 오픈하게되면 check_level이 1로 올라가면서, 썸네일이 로컬에 생성되고 생성된 파일을 get_image_url 친구가 불러와서 잘 보이게됩니다. 살짝 css를 추가해서 현재는 아래와 같은 상태입니다.
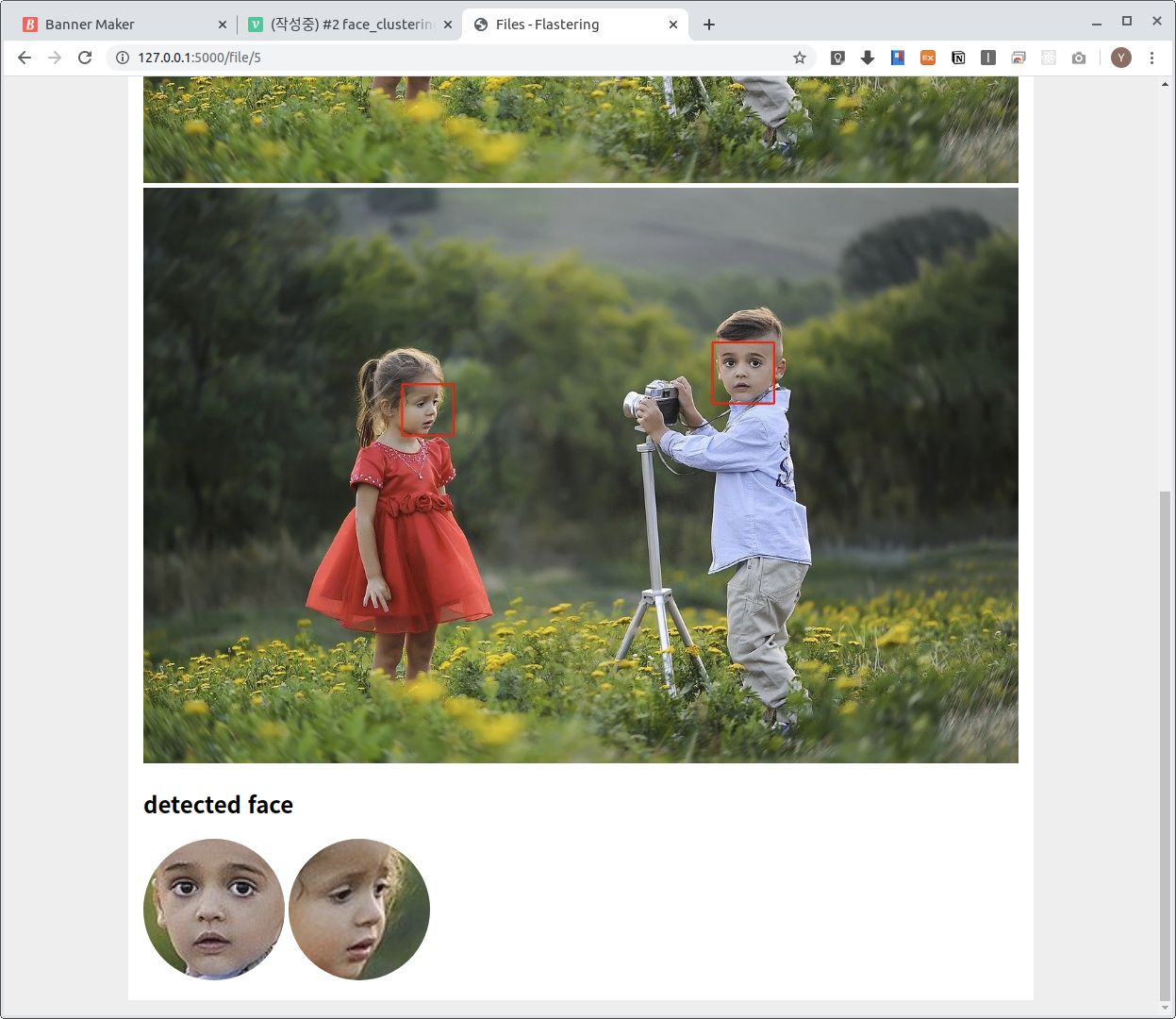
이후 작업
-
클러스터링 관련
자동으로 인식해서 분류해주는 것, 영상 파일 클러스터링 하는 것, 클러스터링 된 애들 카테고리 설정해주는 것, 클러스터링 잘못된 내용들 쉽게 되돌리는 것... 뭐 많습니다. 여기는.. -
페이지 디자인
원래 튜토리얼이 블로그를 만드는걸 가정하고 css를 제공해줘서 현재는 사진을 내려보기엔 너무 불편한 상태로 구현이 되어있습니다. 이를 좀 더 편하게 만들면 좋을 것 같습니다. -
보안
로컬에서 돌릴거라서 보안을 딱히 신경쓰지는 않았지만, 세상에서 제일 치명적인 이미지 서버가 아닐까 싶습니다.. 전역에 접근 가능하다니 통제라 세상에나.. 각 유저들이 가진 권한을 서버에게 제공할 수 없어서 아주 곤란한 부분인 것 같습니다.(아니면 유저마다 미디어 서버를 하나씩 켜도록...응 아니야). 좋은 아이디어가 있으면 보완해보고 싶습니다. -
recognition deamon
백그라운드에서 지속적으로 추가된 사진과 변경된 기준을 가지고 사진과 영상을 체크해줄 데몬이 돌고 있어야, 다른 서비스들 흉내라도 낼 수 있을 것 같습니다. -
폴더 탐색 기능
결국 백그라운드랑 비슷한건데, 분류하길 원하는 nas를 다 물려놓고 관련 폴더들을 다 추가해놔야 하나의 서비스에서 여러 nas의 사진들을 분류작업하고 사용할 수 있겠죠?
후기
음.. 오늘로 끝낼 것은 아닙니다만.. 코로나의 영향으로 밖으로 나가지 못하는 찰나에, face_clustering 관련 글을 보고 이틀 간에 똑딱 작업을 해보았습ㄴ다. python을 종종 쓰긴했지만 메인으로 사용하는 언어는 아니었는데, 다양한 곳에서 효율성 좋게 사용되고 있다는 것을 좀 체감했습니다. (이렇게 좋은 라이브러리가 세상에 널려있다니..?) 그리고 생산성... 맨날 C만 주구장창 가지고 놀다가 거의 배우다시피 작업했는데도 불구하고 이틀만에 아주 작은거라도 만들 수 있다는게 흥미로웠고 재미있었습니다. 코로나가 빨리 진정되면 좋겠지만 그 기간동안을 좀 더 개인 작업하는데 시간을 쓸 수 있어서 저에게는 이 또한 유의미한 것 같습니다. 구글포토와 모멘츠에 답답함이 차오르고 있었는데, 아마추어 스타일이지만 원하는 형태로 만져보는 것이 아주 재미있습니다.
