사이트 구동을 위해 Netlify를 사용하였다.
https://www.netlify.com/

기본으로 티쳐블 머신에서 주는 소스 코드는 다음과 같은 화면을 보여주게 한다.
이번 프로젝트에서 딥러닝은 티처블 머신을 통해 진행했다.
https://teachablemachine.withgoogle.com/
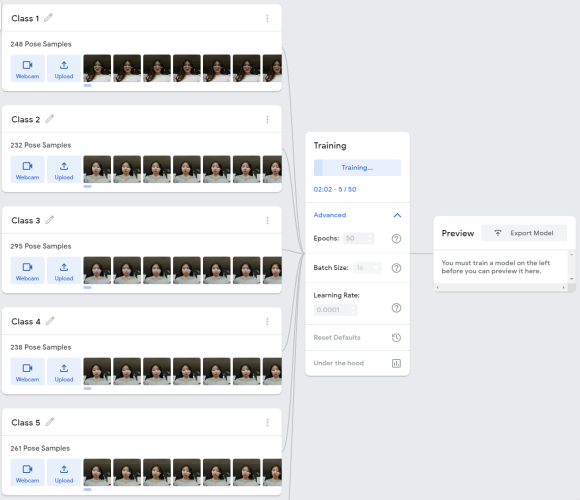
다음과 같이 이미지를 클래스별로 딥러닝 해주었다.
딥러닝 후 다음과 같은 소스코드를 받게 되고 다운로드할 수 있는 압축 파일을 받게 된다.
<div>Teachable Machine Pose Model</div>
<button type="button" onclick="init()">Start</button>
<div><canvas id="canvas"></canvas></div>
<div id="label-container"></div>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@teachablemachine/pose@0.8/dist/teachablemachine-pose.min.js"></script>
<script type="text/javascript">
// More API functions here:
// https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/pose
// the link to your model provided by Teachable Machine export panel
const URL = "./my_model/";
let model, webcam, ctx, labelContainer, maxPredictions;
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// load the model and metadata
// Refer to tmImage.loadFromFiles() in the API to support files from a file picker
// Note: the pose library adds a tmPose object to your window (window.tmPose)
model = await tmPose.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// Convenience function to setup a webcam
const size = 200;
const flip = true; // whether to flip the webcam
webcam = new tmPose.Webcam(size, size, flip); // width, height, flip
await webcam.setup(); // request access to the webcam
await webcam.play();
window.requestAnimationFrame(loop);
// append/get elements to the DOM
const canvas = document.getElementById("canvas");
canvas.width = size; canvas.height = size;
ctx = canvas.getContext("2d");
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop(timestamp) {
webcam.update(); // update the webcam frame
await predict();
window.requestAnimationFrame(loop);
}
async function predict() {
// Prediction #1: run input through posenet
// estimatePose can take in an image, video or canvas html element
const { pose, posenetOutput } = await model.estimatePose(webcam.canvas);
// Prediction 2: run input through teachable machine classification model
const prediction = await model.predict(posenetOutput);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
// finally draw the poses
drawPose(pose);
}
function drawPose(pose) {
if (webcam.canvas) {
ctx.drawImage(webcam.canvas, 0, 0);
// draw the keypoints and skeleton
if (pose) {
const minPartConfidence = 0.5;
tmPose.drawKeypoints(pose.keypoints, minPartConfidence, ctx);
tmPose.drawSkeleton(pose.keypoints, minPartConfidence, ctx);
}
}
}
</script>대략 이런 구성?으로 완성된다.
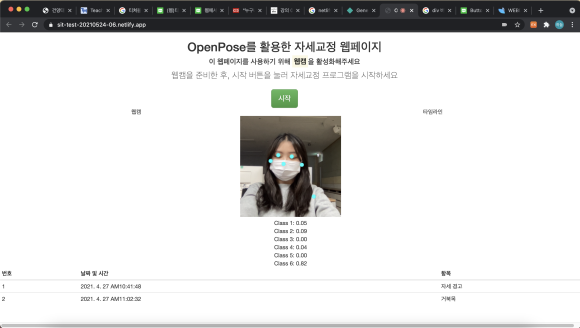
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 합쳐지고 최소화된 최신 CSS -->
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.2/css/bootstrap.min.css">
<!-- 부가적인 테마 -->
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.2/css/bootstrap-theme.min.css">
<!-- 합쳐지고 최소화된 최신 자바스크립트 -->
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.2/js/bootstrap.min.js"></script>
<script src="https://code.jquery.com/jquery-3.6.0.js" integrity="sha256-H+K7U5CnXl1h5ywQfKtSj8PCmoN9aaq30gDh27Xc0jk=" crossorigin="anonymous"></script>
<meta charset="utf-8">
<title>OpenPose를 활용한 자세교정</title>
</head>
<body>
<div class="row text-center" style="width: 100%">
<h2>OpenPose를 활용한 자세교정 웹페이지</h2>
<h4>이 웹페이지를 사용하기 위해 <mark>웹캠</mark>을 활성화해주세요</h4>
<p class="lead">웹캠을 준비한 후, 시작 버튼을 눌러 자세교정 프로그램을 시작하세요</p>
</div>
<div class="row text-center" style="width: 100%">
<div class="row">
<button utton type="button" class="btn btn-success btn-lg" onclick="init()">시작</button>
</div>
</div>
<!--<div class="row">
<div class="col-md-6">
<div class="row text-center" style="width: 100%">
웹캠
</div>
</div>
<div class="col-md-6">
<div class="row text-center" style="width: 100%">
타임라인
</div>
</div>
</div>-->
<div class="row">
<div class="container">
<div class="row">
<div class="row text-center">
<canvas id="canvas"></canvas>
</div>
<div class="row text-center" id="label-container"></div>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@teachablemachine/pose@0.8/dist/teachablemachine-pose.min.js"></script>
<script type="text/javascript">
// More API functions here:
// https://github.com/googlecreativelab/teachablemachine-community/tree/master/libraries/pose
// the link to your model provided by Teachable Machine export panel
const URL = "./my_model/";
let model, webcam, ctx, labelContainer, maxPredictions;
async function init() {
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// load the model and metadata
// Refer to tmImage.loadFromFiles() in the API to support files from a file picker
// Note: the pose library adds a tmPose object to your window (window.tmPose)
model = await tmPose.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// Convenience function to setup a webcam
const size = 250;
const flip = true; // whether to flip the webcam
webcam = new tmPose.Webcam(size, size, flip); // width, height, flip
await webcam.setup(); // request access to the webcam
await webcam.play();
window.requestAnimationFrame(loop);
// append/get elements to the DOM
const canvas = document.getElementById("canvas");
canvas.width = size; canvas.height = size;
ctx = canvas.getContext("2d");
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) { // and class labels
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop(timestamp) {
webcam.update(); // update the webcam frame
await predict();
window.requestAnimationFrame(loop);
}
async function predict() {
// Prediction #1: run input through posenet
// estimatePose can take in an image, video or canvas html element
const { pose, posenetOutput } = await model.estimatePose(webcam.canvas);
// Prediction 2: run input through teachable machine classification model
const prediction = await model.predict(posenetOutput);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + ": " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
// finally draw the poses
drawPose(pose);
}
function drawPose(pose) {
if (webcam.canvas) {
ctx.drawImage(webcam.canvas, 0, 0);
// draw the keypoints and skeleton
if (pose) {
const minPartConfidence = 0.5;
tmPose.drawKeypoints(pose.keypoints, minPartConfidence, ctx);
tmPose.drawSkeleton(pose.keypoints, minPartConfidence, ctx);
}
}
}
</script>
</div>
</div>
</div>
<div>
<table class="table table-condensed">
<!--<table class="table table-striped table-hover">-->
<thead>
<tr>
<th>번호</th>
<th>날짜 및 시간</th>
<th>항목</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>2021. 4. 27 AM10:41:48</td>
<td>자세 경고</td>
</tr>
<tr>
<td>2</td>
<td>2021. 4. 27 AM11:02:32</td>
<td>거북목</td>
</tr>
<tr>
</tbody>
</table>
</div>
</div>
</body>
</html>
Now: Mobile Developer