
[1] 개요
- 복수 개의 프로세서(CPU)를 두어 동시에 여러 작업을 수행할 수 있도록 구성된 컴퓨터 시스템이다.
- 단일 시스템 내에 적은 비용과 작은 부피로 다수의 프로세서를 장착하고 이들을 연결시켜 다중 프로세서 시스템을 구축한다.
- 동시에 프로그램을 수행할 수 있는 프로세서를 2개 이상 두고 각각 그 업무를 분담해 처리 가능하다.
- 많은 추가 비용 없이도 기존 시스템의 계산 능력이 향상되고, 높은 Availability과 높은 Reliability가 보장되도록 구성되어야 한다.
구조
| Loosely-Coupled | Tightly-Coupled |
|---|---|
| 각 프로세서들이 독립적으로 운영(각자 OS 유지) | 하나의 OS가 시스템 전체 자원을 관리 |
| 각 프로세서들이 자신의 메모리 영역을 별도로 가짐 | 모든 프로세서들이 하나의 공유 메모리(shared memory)를 사용 |
| 프로세서들 간 통신을 위한 message passing (메시지 전달) 기법 사용 | 프로세서들 간의 메모리 접근 경쟁 (memory connection) 해결 필요 |
(참고) CPU 관련 용어정의
CPU = Control Unit + Processing Unit
-제어장치는 명령어를 인출하고 해독해 제어신호를 만드는 장치이다.
-처리장치는 제어장치에서 만들어진 제어신호에 근거해 처리할 데이터와 주소 등의 operand(피연산자)를 인출하고 명령어를 수행하는 장치이다.
Instruction Stream과 Data Stream
-명령어 스트림이란 프로세서에 의해 실행되기 위해 순서대로 나열된 명령어 코드들의 집합이다.
-데이터 스트림이란 명령어들을 실행하는데 필요한 순대로 나열된 데이터들의 집합이다.
[2] Flynn의 분류
컴퓨터 구조의 분류법으로, 프로세스 측에 전달되는 Instruction Stream과 Data Stream의 개수를 기준으로 다중처리 시스템을 분류했다.
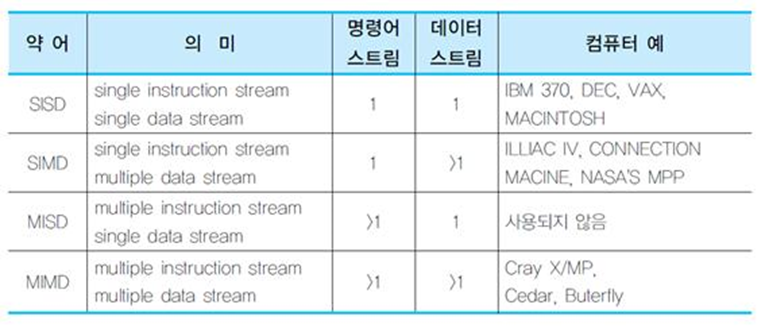
(1) SISD(Single Instruction Stream, Single Data Stream)
- 한 번에 한 개씩의 명령어와 데이터를 처리하는 단일 프로세서 시스템이다.
- 하나의 프로세서에 하나의 연산 장치를 두어 명령어를 처리한다.
- 사실상 병렬처리 개념을 갖지 않는 구조이다.
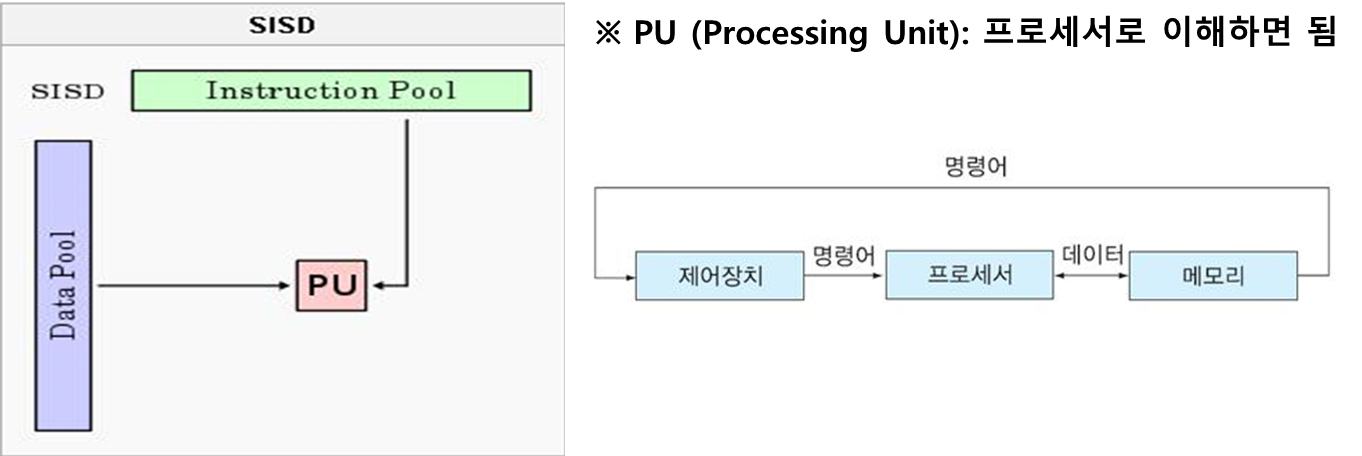
(2) SIMD(Single Instruction Stream, Multiple Data Stream)
- 여러 개의 프로세서들로 구성되고, 프로세서들의 동작은 모두 하나의 제어장치에 의해 제어된다.
- 모든 프로세서들은 제어장치로부터 동일한 명령어를 받지만 명령어 실행 과정에서 서로 다른 데이터들을 사용한다.
- 벡터 연산(행렬 계산 등), 영상처리 등의 병렬처리에 주로 활용된다.
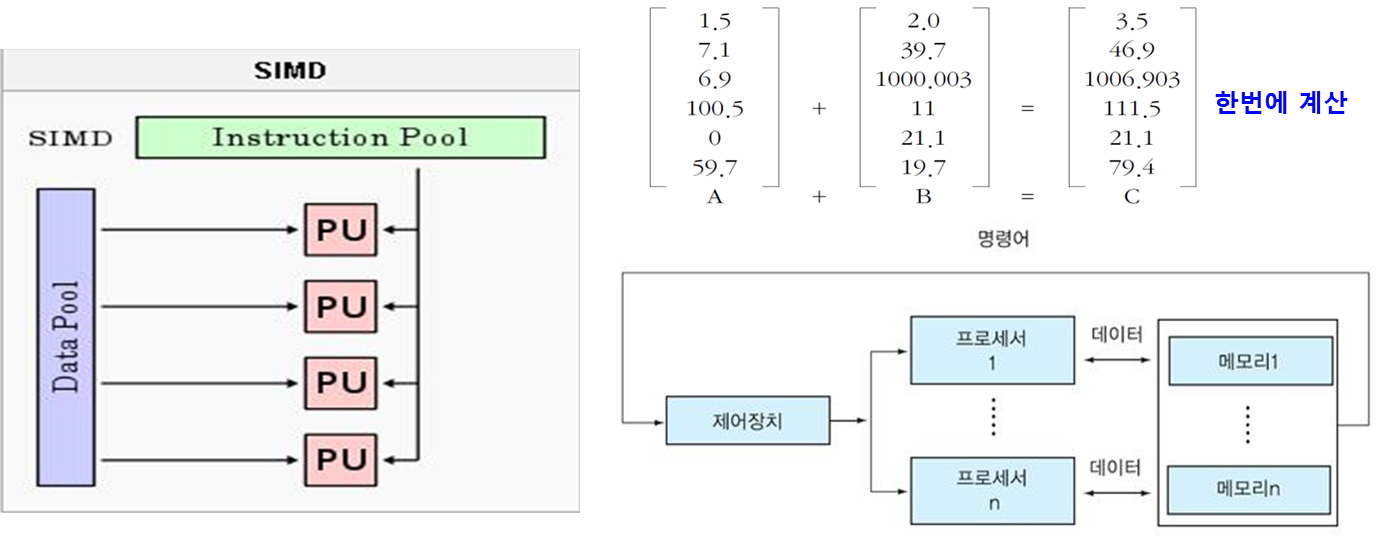
(3) MISD(Multiple Instruction Stream, Single Data Stream)
- 여러 개의 제어 장치와 프로세서를 갖는 구조이다.
- 각 프로세서들은 서로 다른 명령어들을 실행하지만 처리하는 데이터는 동일한 하나의 스트림이다.
- 하나의 자료 흐름에 대해 복수 개의 연산 장치들이 다른 종류의 연산을 수행한다.
- 응용 분야가 거의 없다.
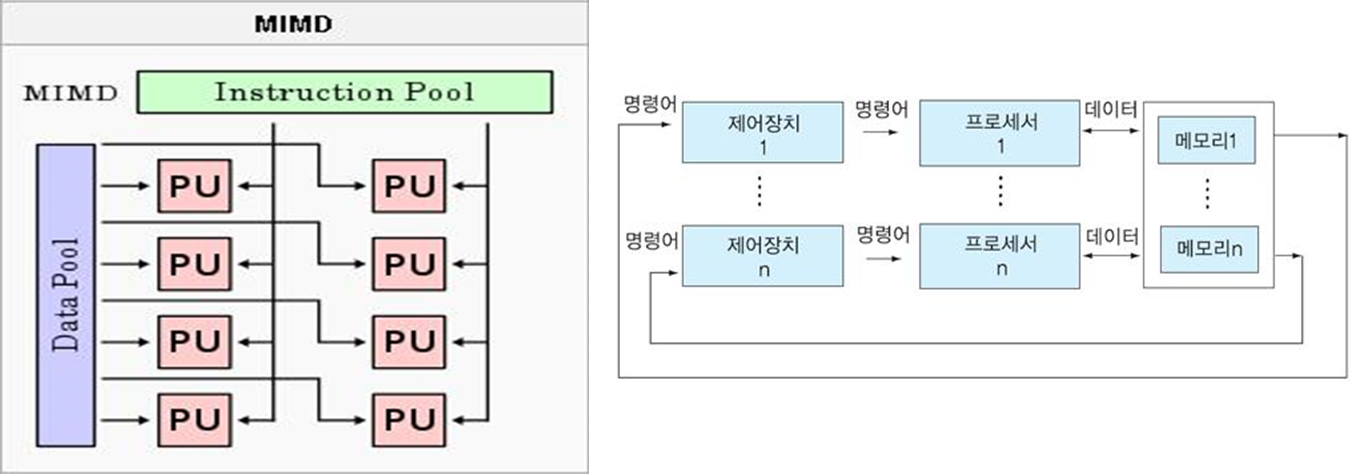
(4) MIMD(Multiple Instruction Stream, Multiple Data Stream)
- 여러 개의 프로세서들이 서로 다른 명령어와 데이터를 처리하며, 대부분의 다중 처리 시스템이 여기에 해당된다.
- Tightly Coupled System : 모든 프로세서가 기억장치를 공유(Shared Memory)하는 구조
- Loosely Coupled System : 각 프로세서가 자신의 지역 메모리(Local Memory)를 가진 독립적인 구조
[3] Parallel Processing
Parallelism(병렬성)
병렬 처리 시스템은 가능한 최대의 병렬 처리율을 얻고자 하는 것이 주 목적이다.
병렬 처리의 어려움
- 사람들의 사고 형태는 동시성을 가지고 병렬적으로 생각한다는 것이 습관화되어 있지 않다.
- 병렬성을 효율적으로 표현할 수 있는 언어가 많이 없다.
- 컴퓨터 하드웨어는 순차적인 작동의 형태로 구성된다.
- 병렬 프로그램의 정확성에 대한 증명이 복잡하고, 디버깅이 어렵다.
Parallelism Level(병렬성의 단계)
(1) Job Level(작업 단계)
두 개의 프로그램을 작업이라 할 때, 만약 계산에 필요한 자료가 각각 준비되어 있을 경우 이 두 작업은 병렬로 처리가 가능하다.
(2) Task Level(태스크 단계)
한 프로그램(작업)이 여러 개의 태스크로 분할될 수 있을 때, 이러한 태스크들은 상호 작용이 필요하다 할지라도 병렬로 처리가 가능하다.
(3) Process Level(프로세스 단계)
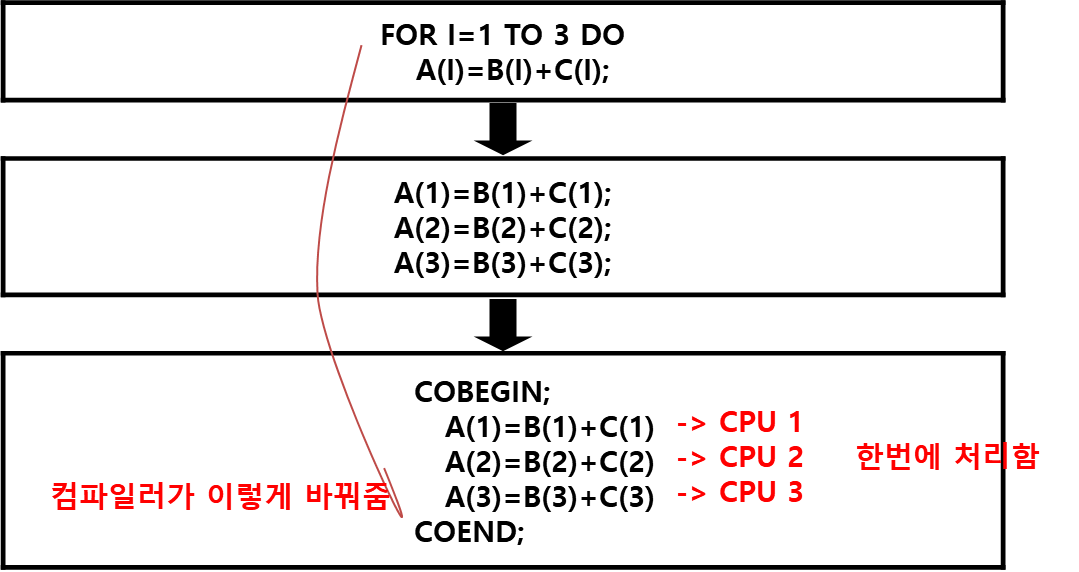
태스크는 여러 개의 프로세스로 분할 가능하며, 이들 프로세스들은 사용자에 의해 또는 컴파일러에 의해 자동적으로 병렬을 수행한다. (대부분은 컴파일러가 한다) 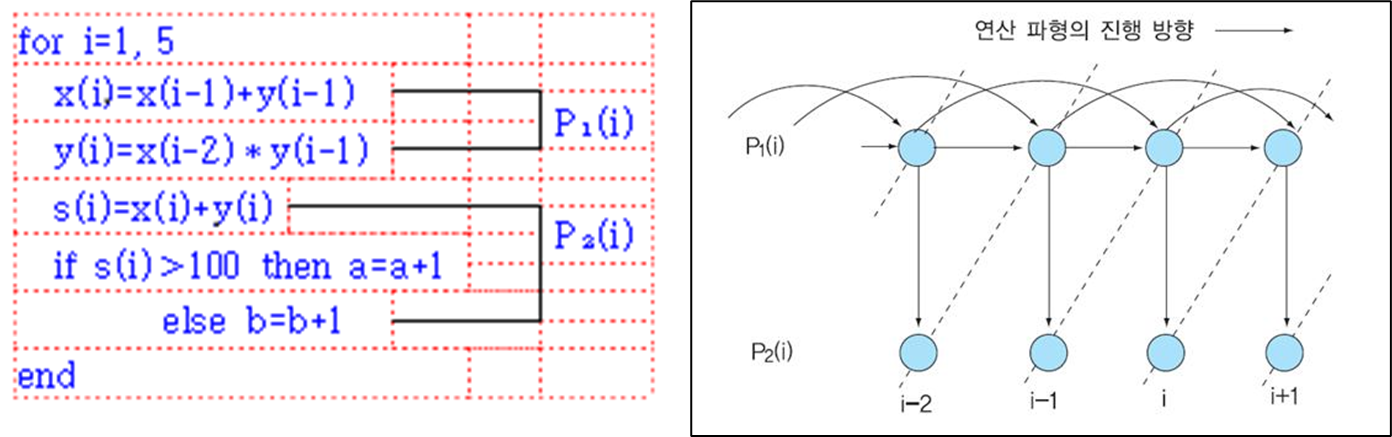 P1(i)와 P2(i)는 병렬 수행하지 않고, P1(i)와 P2(i-1)은 병렬 수행을 한다.
P1(i)와 P2(i)는 병렬 수행하지 않고, P1(i)와 P2(i-1)은 병렬 수행을 한다.
(4) Variable Level(변수 단계)
프로세스 내에 포함되어 있는 변수 수준에서 몇몇 변수들은 병렬 수행이 가능하다.
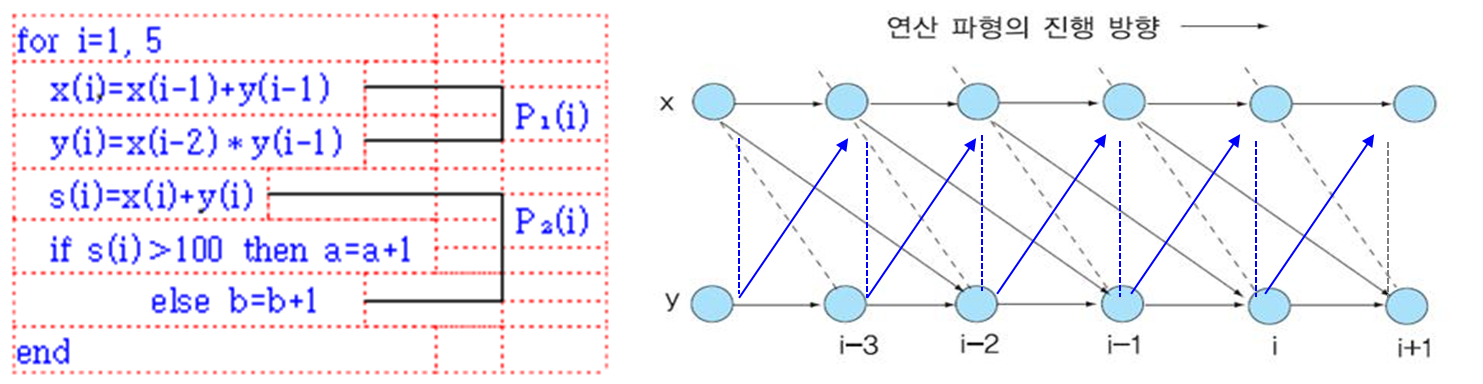
(5) Bit Level(비트 단계)
비트 단위의 병렬 연산을 수행하고, 병렬성이 존재할 수 있는 최저 단계이다.
병렬성의 자동 검출
프로그램 내에서의 명시적인(Explicit) 병렬성과 묵시적인(Implicit) 병렬성으로 구분된다.
Explicit Parallelism
 Program 언어들을 직접 적어준다.
Program 언어들을 직접 적어준다.
Implicit Parallelism
- 컴파일러에 의한 병렬 수행이 가능한 부분을 찾기 위한 방법으로, 병렬성의 검출은 컴파일러, OS, 컴퓨터 하드웨어 등에 위임시킨다.
- 연산 트리 높이 축소(Tree height reduction) 방법과 순환 분산(Loop distribution)방법이 있다.
(1) Computation Step Reduction(연산 단계의 축소)
컴파일러는 연산의 교환, 결합 및 분배 법칙을 이용해 수식에 내재된 병렬성을 찾아낸다.
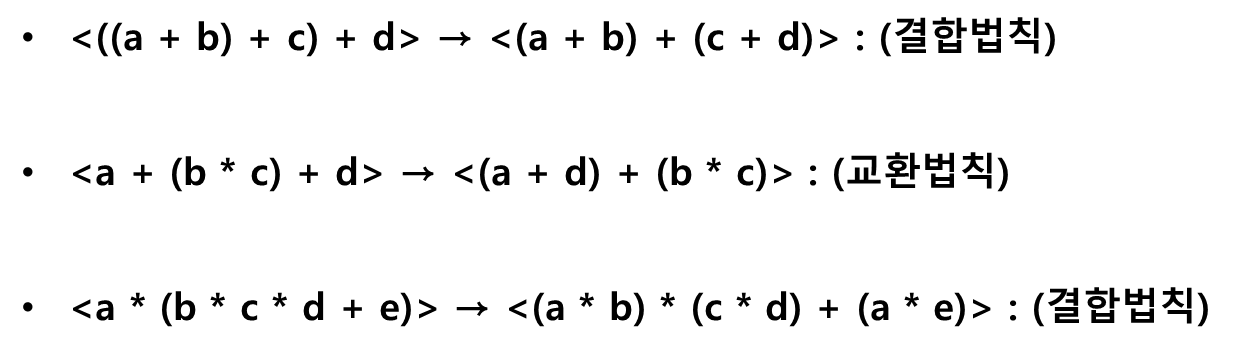
(2) Loop Distribution
순환 본체(Loop Body)내에 있는 일련의 문장들을 병렬로 수행한다.
[4] OS 구성
다중 처리 시스템에서 OS의 기능
- 일반 다중 프로그래밍 시스템의 OS 기능을 포함한다.
- Task Assignment 및 Load Balancing 기능이 필요하다.
- 프로세서의 고장 및 복구에 따른 시스템 재구성 기능(Reconfiguration Capability)이 필요하다.
- 병렬 프로세스 또는 태스크 관리 기능이 필요하다.
- 분할된 병렬 태스크들의 재병합을 위한 동기화 매커니즘이 필요하다.
다중 처리 시스템을 위한 OS의 구성 형태
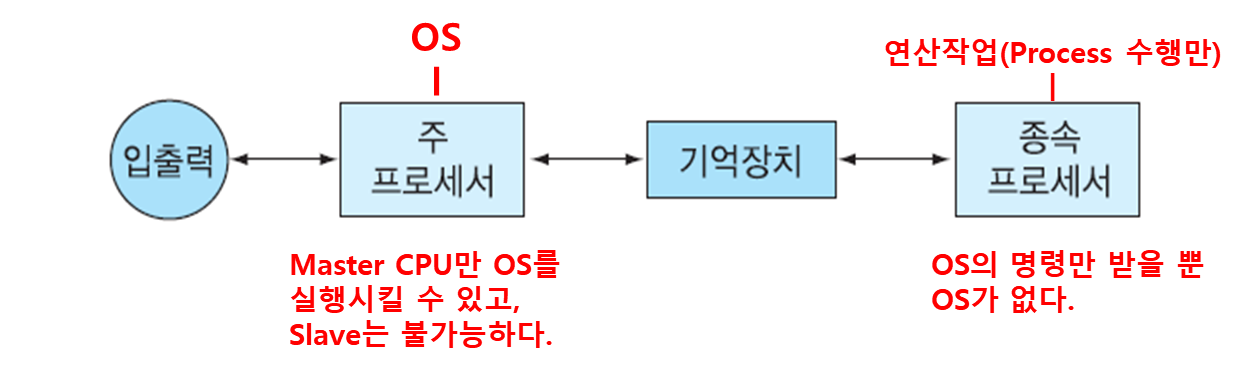
(1) Master/Slave(주종 관계) 구조
- 가장 구현하기 쉬운 다중 처리 시스템의 형태로, 최적 효율 달성은 어렵다.
- 하나의 특별한 프로세서인 주 프로세서만이 OS를 실행하고 종속 프로세서는 오직 사용자 프로그램만을 실행한다.
- 한 프로세서만이 OS를 실행하므로 제어 테이블 등에 대한 상호 배제가 비교적 손쉽다.
- 주로 주(Master)프로세서는 입출력을 종속(Slave)프로세서는 연산 위주로 수행한다.
*Master Processor : 사용자 프로세스 및 OS의 실행 권한/책임
*Slave Processor : 사용자 프로세스들만을 실행
시스템 내의 Processing Element(PE)들 중 하나를 Master로 지정한다.
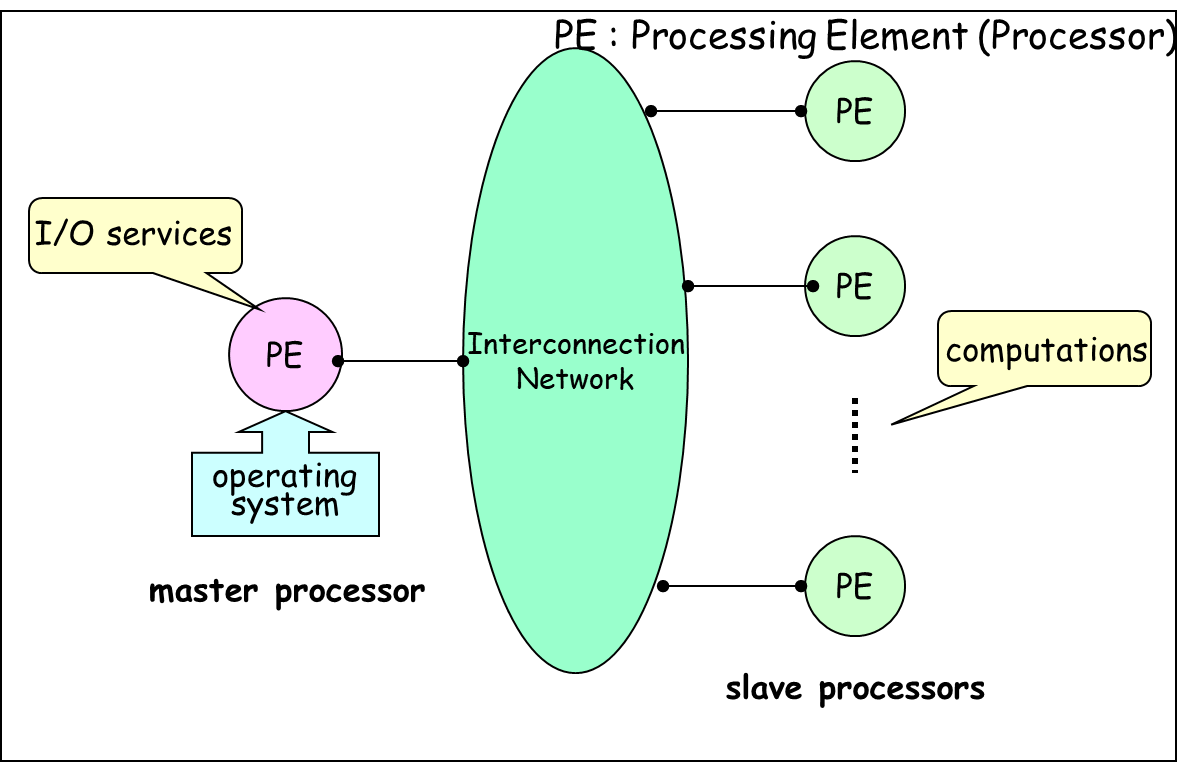
문제점
- Master Processor에 과부하를 초래한다. (입출력과 연산을 할 때 과부하가 걸릴 수 있어 따로 관리)
- Master Processor의 고장 시 Reliability에 심각한 문제가 발생한다.
- Master Processor의 과부하 시에 전체 시스템의 프로세서 활용도가 저하된다.
해결 방법
- Master Processor에 입출력 위주 프로세스(I/O-bound process)를 할당한다.
- Slave Processor들에 연산 위주 프로세스(compute-bound process)를 할당한다.
(2) Separate Executives(독립 수행) 구조
- Load Balancing을 통한 시스템 성능 향상이 주 목적이다.
- 각 프로세서가 자신의 OS를 가진다. (단일 컴퓨터 시스템의 경우와 동일하게 운영)
- OS의 기능이 각 프로세서에서 독자적으로 수행되기 때문에, 전체 시스템의 총괄 정보에 대한 접근은 상호 배제가 보장되어야 한다. (독립적으로 수행하지만 언젠간은 합병해야 하기 때문)
- Master/Slave 구조에 비해 Reliability가 높지만, 시스템 구성이 복잡하다.
- Master/Slave 구조와의 차이점은 각 프로세스마다 CPU의 유무이다.
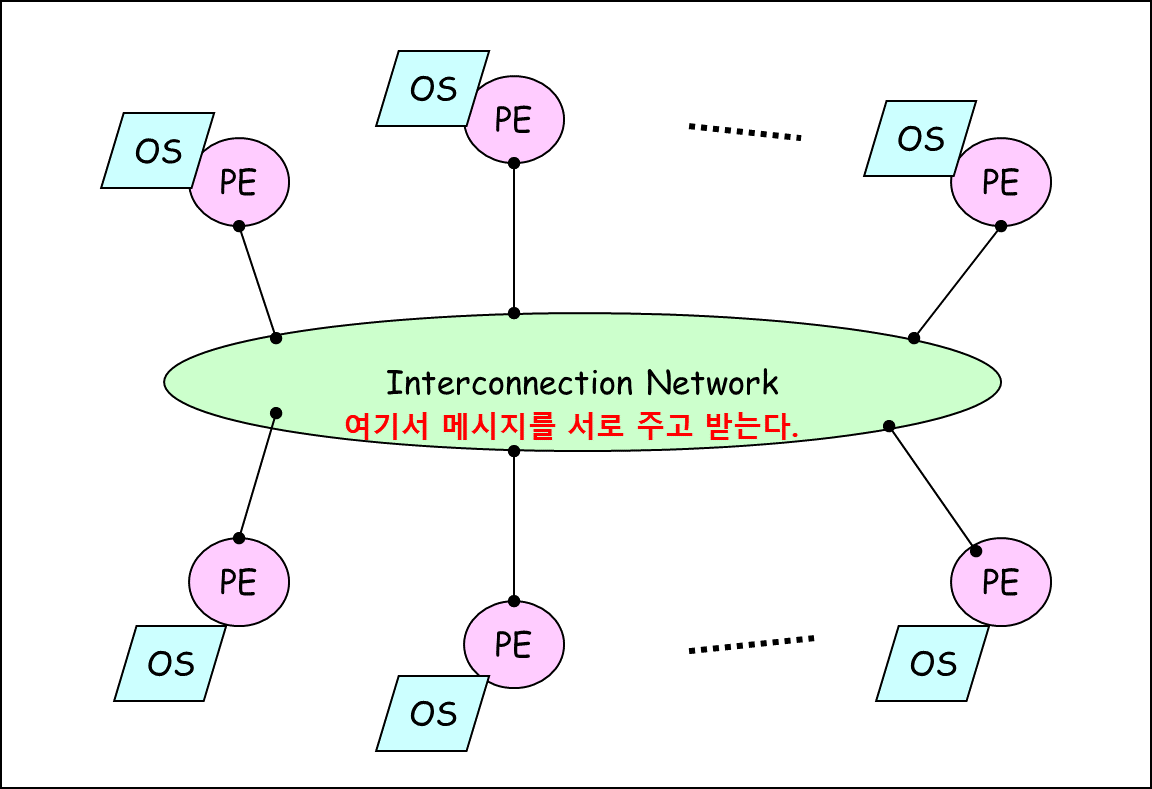
(3) Symmetric Treatment(대칭적 OS) 구조
- 모든 프로세서가 동등한 입장의 대칭성을 가지는 형태로 OS하나를 공유한다.
- 모든 형태의 자원에 대한 대칭성으로 인해 작업 부하(Work Load)에 대한 균형을 이룰 수 있다.
- 시스템 내의 어느 프로세서나 OS의 실행 권한을 가지며, 여러 프로세서들이 동시에 OS를 수행할 수 있으므로 재진입코드와 상호 배제가 필요하다. (공유하기 때문에 기다려야 함, 우선순위는 없음)
- 신뢰성이 높고, 시스템 자원 활용도를 높일 수 있다.
- 한 프로세스에 대한 병렬처리 요구 시 여러 프로세서들의 공동 작업도 가능하다.
 OS와 연결된 2개만 쓸 수 있다는 것이 아닌 모두 쓸 수 있다는 의미의 그림이다.
OS와 연결된 2개만 쓸 수 있다는 것이 아닌 모두 쓸 수 있다는 의미의 그림이다.
Master/Slave구조와 Symmetric구조 중 만들기 더 어려운 것은 Symmetric구조이다.(이유 : 상호배제 유무)
