
이 돔 말고
DOM이란?
프로그래밍을 공부 하다보면 'DOM에 접근하여', 'DOM이 어쩌구 저쩌구..' 라는 문장을 많이 접해봤을 것이다. 나 역시도 책이나 인터넷 강의들도 리액트와 자바스크립트 공부를 하면서 DOM이라는 단어가 나올때마다 DOM의 정확한 뜻을 몰라 많이 헤메었던 기억이 있다. 그렇기 때문에 오늘 DOM에 대해 정확히 알아보고 넘어가기 위해 이 게시글을 작성하고자 한다.
DOM의 정의
MDN에서 정의한 DOM의 설명을 한번 보자.
문서 객체 모델(The Document Object Model, 이하 DOM) 은 HTML, XML 문서의 프로그래밍 interface 이다. DOM은 문서의 구조화된 표현(structured representation)을 제공하며 프로그래밍 언어가 DOM 구조에 접근할 수 있는 방법을 제공하여 그들이 문서 구조, 스타일, 내용 등을 변경할 수 있게 돕는다.
나는 처음에 이 문장을 보고도 '이게 대체 뭔소리야...' 하면서 이해가 잘 되지 않았었다. 그럼 문서 객체 모델이라는 단어를 한번 분석해보자. 문서 객체란, <html>이나 <body> 같은 html문서의 태그들을 JavaScript가 이용할 수 있는 객체(object)로 만들면 그것을 문서 객체라고 한다. 모델(Model)은 해당 단어에서는 '인식하는 방식'으로 해석된다. 즉 이 해석만 본다면, DOM이라는 것은 웹 브라우저가 HTML을 인식하는 방식, 혹은 document 객체와 관련된 객체의 집합을 의미한다고 볼 수 있다.
웹 페이지가 만들어지는 과정
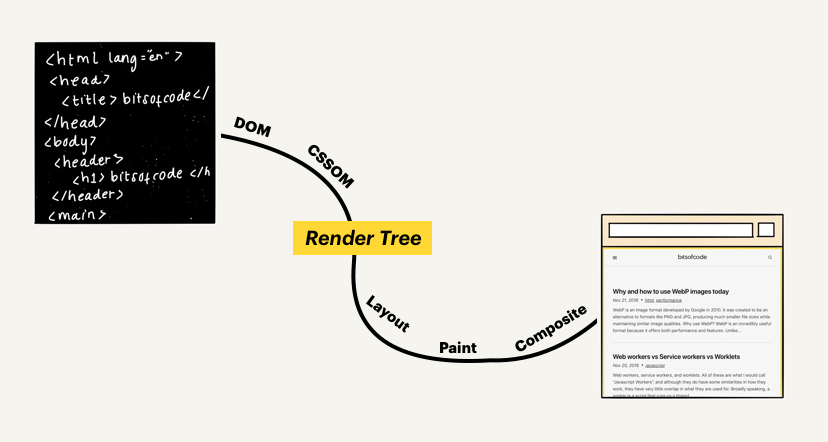
그럼, DOM을 더 자세하게 이해하기 위해 우선 웹 페이지가 만들어지는 과정부터 알아보도록 하자.
웹 페이지는 브라우저가 HTML, CSS, Javascipt를 서버로부터 전달받아 화면에 픽셀화하여 만들어지게 되는데 이때의 과정을 중요 렌더링 경로(Critical Rendering Path), CRP라고 한다. 총 6가지의 단계가 있지만, 간단하게 두 가지로 나누게 되면 브라우저가 읽어들인 문서를 파싱하여 최종적으로 어떤 내용을 페이지에 렌더링 할지 결정하는 단계와, 브라우저가 렌더링을 수행하는 단계로 나눌 수 있다.
이때, 첫번째 단계에서 렌더 트리(Render Tree)가 생성되는데, 이 렌더 트리는 웹 페이지에 표시될 HTML 요소들과 이와 관련된 스타일 요소들로 구성이 되어 있다. 이때 렌더 트리를 생성하기 위해 브라우저가 필요한 2가지 요소가 바로 CSSOM과 DOM 이다. 바로 이때, DOM이 생성된다.
CSSOM (Cascading Style Sheet Object Model) - 요소들과 관련된 스타일 정보의 구조화 표현
DOM (Document Object Model) - HTML 요소들의 구조화 표현
트리(Tree) 구조
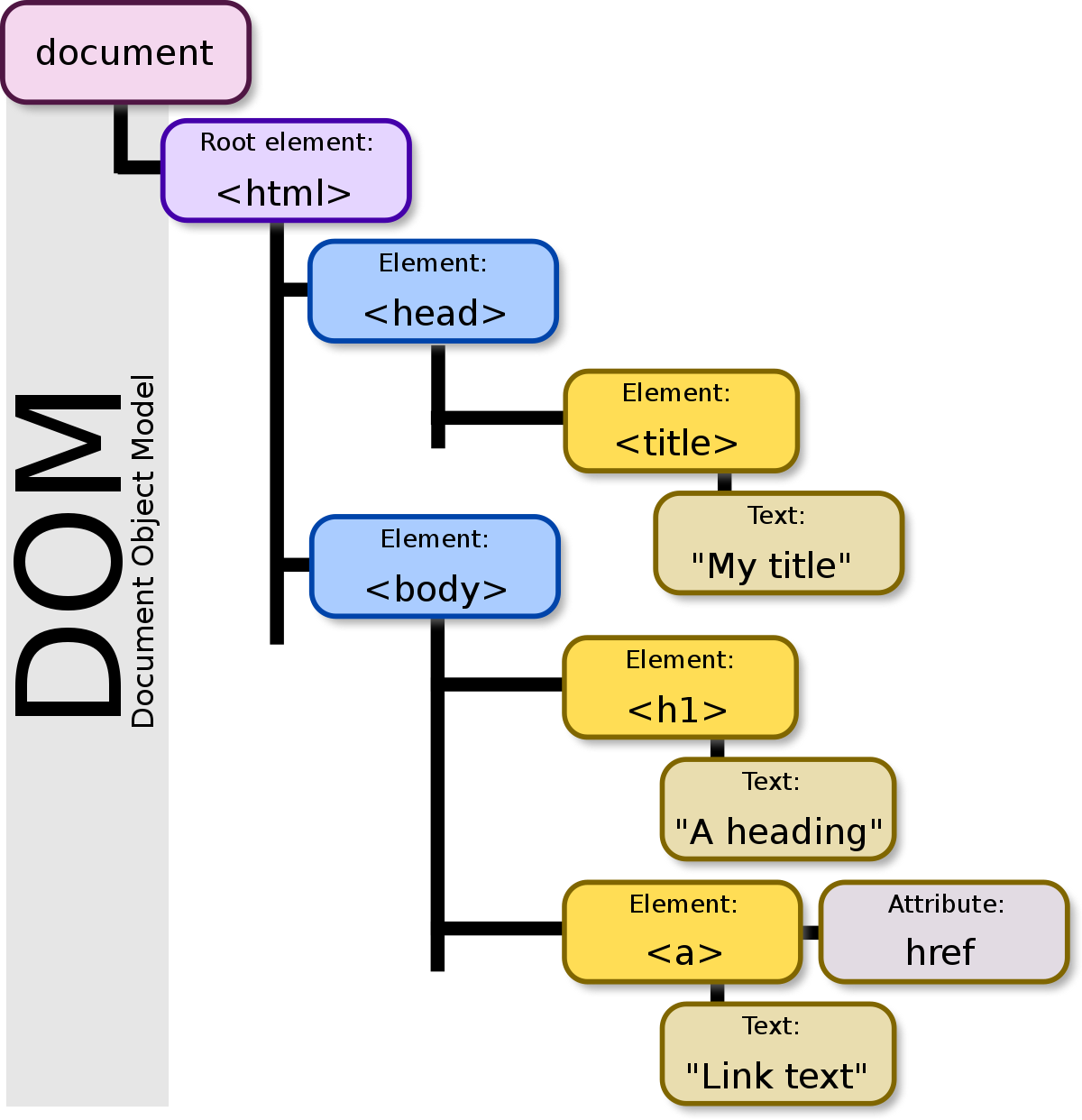
(HTML 문서 내의 DOM 계층의 예)
DOM을 제대로 이해하기 위해서는 트리 구조에 대해서 이해할 필요가 있다. 트리(Tree)는 노드(Node)라고 불리는 개체로 이루어진 자료 구조이다. 여기서 노드(Node)란, HTML을 예로 들때 HTML 문서의 모든 것을 노드라고 할 수 있다.
| 노드 | 설명 |
|---|---|
| 문서 노드(document node) | HTML 문서 전체를 나타내는 노드임. |
| 요소 노드(element node) | 모든 HTML 요소는 요소 노드이며, 속성 노드를 가질 수 있는 유일한 노드임. |
| 속성 노드(attribute node) | 모든 HTML 요소의 속성은 속성 노드이며, 요소 노드에 관한 정보를 가지고 있음. 하지만 해당 요소 노드의 자식 노드(child node)에는 포함되지 않음. |
| 텍스트 노드(text node) | HTML 문서의 모든 텍스트는 텍스트 노드임. |
| 주석 노드(comment node) | HTML 문서의 모든 주석은 주석 노드임. |
트리와 노드에 관한 설명은 다음과 같다.
1. 트리는 하나의 루트 노드를 갖는다.
2. 루트 노드는 0개 이상의 자식 노드를 갖고 있다.
3. 그 자식 노드 또한 0개 이상의 자식 노드를 갖고 있고, 이는 반복적으로 정의된다.
이와 같이 DOM은 트리(Tree) 구조의 자료 형태를 가지고 있다.
DOM에 대해 알아두어야 할 것
1. DOM != HTML
DOM이 HTML 문서로부터 생성되는 것은 맞지만, DOM이 HTML과 같다고 볼수는 없다. DOM이 원본 HTML 소스와 다를 수 있는 두 가지 케이스가 존재한다.
- 작성된 HTML이 유효하지 않을 때
DOM은 유효한 HTML 문서의 인터페이스다. DOM을 생성하는 동안, 브라우저는 유효하지 않은 HTML 코드를 올바르게 교정하게 된다. 예시를 살펴보자.


위와 같이, HTML 규칙의 필수 사항인 <head>와 <body> 태그가 빠져있지만, DOM 트리에서는 올바르게 교정되어 나타나게 된다.
- DOM이 자바스크립트에 의해 수정될 경우
DOM은 HTML 문서를 볼 수 있는 인터페이스 역할을 함과 동시에, 동적으로 변경될 수 있다. 예를 들어, 자바스크립트가 DOM에 새로운 노드를 추가할 수 있다.

하지만 이 코드는 DOM을 업데이트 할 뿐이지, HTML 문서를 변경하진 않는다.
2. DOM은 브라우저에서 보이는 것이 아니다.
앞서 설명한 것처럼, 브라우저 뷰 포트에서 보이는 것은 렌더 트리로, CSSOM과 DOM의 결합체이다. 렌더 트리는 오직 화면에 그려지는 것만으로 구성되어 있기 때문에, 시각적으로 보이지 않는 요소는 제외하게 된다. 예를 들어, <p> 태그에 display:none 스타일 속성을 추가한다면, DOM에서는 <p>요소를 포함하지만, 브라우저 뷰 포트에서는 이것이 나타나지 않는다.
3. DOM은 devTools에서 보이는 것이 아니다.
개발 도구의 요소 검사기는 DOM과 가장 가까운 근사치를 제공하지만, DOM에 없는 추가적인 정보를 포함하기도 한다. 가장 좋은 예가 CSS의 가상 요소이다. ::before 과 ::after 선택자를 사용하여 생성된 가상 요소는 CSSOM과 렌더 트리의 일부를 구성한다. 하지만, 이는 기술적으로 DOM의 일부는 아니다. DOM은 오직 원본 HTML 문서로부터 빌드 되고, 요소에 적용되는 스타일을 포함하지 않기 때문이다.
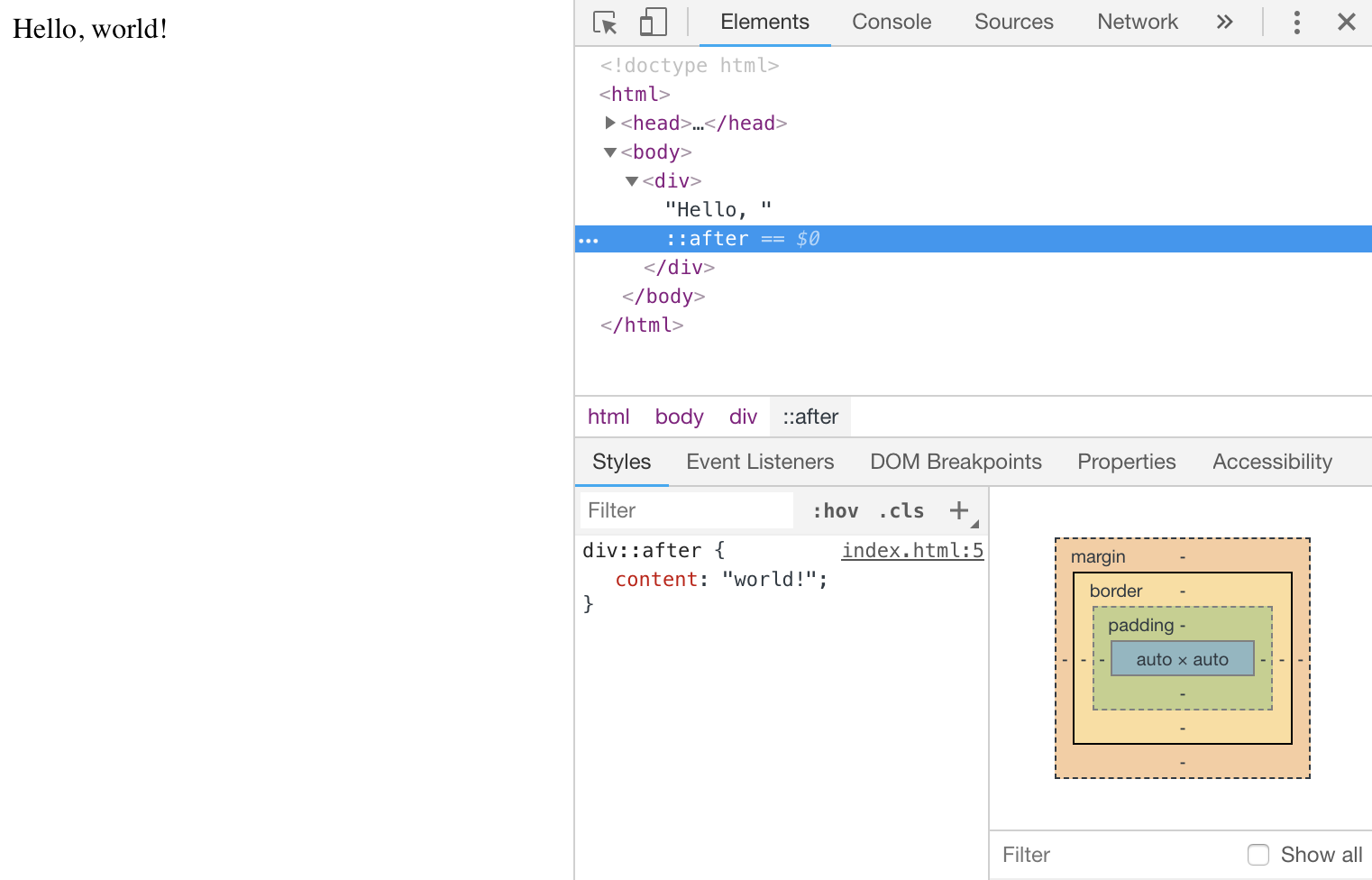
개발 도구에서는 가상 요소가 DOM의 일부가 아님에도 나타나게 된다. 이러한 이유로 가상 요소는 DOM의 일부가 아니기 때문에 자바스크립트로 수정할 수 없다.
DOM에 접근하는 방법
자바스크립트로 웹을 다루기 위해서는 DOM 요소에 접근해야 하는데, 다음과 같은 메소드를 이용하여 웹 페이지에서 특정 요소를 찾을 수 있다.
| 메서드 | 설명 |
|---|---|
| document.getElementById("id명") | 해당 id명을 가진 요소 하나를 반환한다. |
| document.querySelector("선택자") | 해당 선택자를 만족하는 요소 하나를 반환한다. |
| document.getElementsByClassName("class명")[순서] | 해당 class명을 가진 요소들을 배열에 담아 인덱스에 맞는 요소를 반환한다. |
| document.getElementsByTagName("태그명")[순서] | 해당 태그명을 가진 요소들을 배열에 담아 인덱스에 맞는 요소를 반환한다. |
| document.querySelectorAll("선택자명")[순서] | 해당 선택자를 만족하는 모든 요소들을 배열에 인덱스에 맞는 요소를 반환한다. |
요약 정리
요약해서 정리해 보자면, DOM은 넓은 의미로는 웹 브라우저가 HTML을 인식하는 방법, 좁은 의미로는 document 객체의 집합이라고 볼 수 있으며 DOM은 중요 렌더링 경로의 렌더 트리에서 생성되는데, 노드의 집합인 트리 구조로 이루어져 있다고 말할 수 있다. 또한 DOM은 HTML 그 자체가 아니며, 브라우저와 devTools에서 보이는 것이 아니고 특정 메서드를 통해 자바스크립트에서 DOM에 접근할 수 있다.
참고 문서
https://developer.mozilla.org/ko/docs/Web/API/Document_Object_Model/Introduction
https://iamdaeyun.tistory.com/entry/DOM-01Document-Object-Model-DOM%EC%9D%98-%EB%9C%BB
https://ko.wikipedia.org/wiki/%EB%AC%B8%EC%84%9C_%EA%B0%9D%EC%B2%B4_%EB%AA%A8%EB%8D%B8
http://tcpschool.com/javascript/js_dom_node
https://wit.nts-corp.com/2019/02/14/5522
