
초코나무숲🌲보다 달달한 숲이 있습니다.
바로 '무작위 숲(Random Forest)' !
지난 토요일에는 <빅데이터 분석기사 제 3회> 실기 시험이 치뤄졌습니다. 첫 시험이었던 지난 2회차 시험과 이번 3회차 시험 모두 40점짜리 작업형 2유형 문제로 '분류' 모델을 만들어 데이터를 학습시키고 예측하는 문제가 나왔다고 합니다.
'회귀'와 '분류'로 대표되는 머신러닝 지도학습에서 랜덤포레스트는 어디에나 쓸수있는 '만능알고리즘'입니다! 모델의 성능 또한 훌륭한 편이기에 빅분기를 준비하시는 분들에게 가장 인기있는 알고리즘이라고 하는데요😎 오늘은 랜덤포레스트에 대해 자세히 알아보겠습니다!-!
Ensemble🎺🎷
앙상블 기법이란, 여러 개의 약한 분류기를 생성하고 각각의 예측을 결합함으로써 단일 분류기보다 신뢰성이 높은 최종 예측 값을 얻어내는 기법입니다.
현재까지 정형데이터의 예측 분석에서 매우 높은 예측 성능을 보여주어 많은 이들에게 사랑받고 있습니다:)
랜덤포레스트는 머신러닝에서 쓰이는 '앙상블 기법'의 대표적인 알고리즘입니다.
앙상블은 일반적으로 '보팅(voting), '배깅(bagging)', '부스팅(boosting)' 방식으로 나뉩니다.
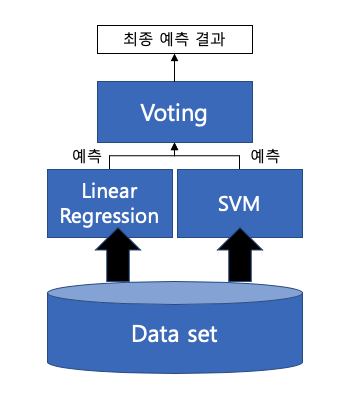
✔️ Voting
'보팅'은 서로 다른 알고리즘의 분류기들을 결합하여 투표를 통해 최종 예측결과를 결정하는 방식으로, 선형 회귀, KNN, 서포트벡터머신(SVM) 등의 머신러닝 알고리즘에서 쓰입니다.
 (출처: http://www.dinnopartners.com/__trashed-4/)
(출처: http://www.dinnopartners.com/__trashed-4/)
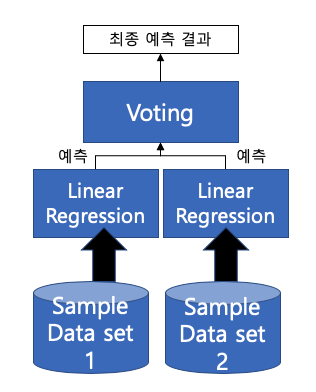
✔️ Bagging
'배깅'은 중복을 허용(복원추출)하여 샘플링한 각각의 데이터 셋을 단일 알고리즘의 여러 분류기에 적용해서 결과를 투표로 결정하는 방식입니다. 여러 개의 작은 데이터 셋을 중첩을 허용해서 만드는 것을 부트스트래핑이라고 합니다.
이러한 '배깅'의 대표적인 알고리즘이 바로 오늘의 주인공, RandomForest 입니다. 랜덤포레스트의 장점은 뛰어난 예측 성능, 빠른 수행 시간, 유연성 입니다.
 (출처: http://www.dinnopartners.com/__trashed-4/)
(출처: http://www.dinnopartners.com/__trashed-4/)
✔️ Boosting
'부스팅'은 여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기의 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에 가중치를 부여하며 학습과 예측을 진행하는 방식입니다.
부스팅 방식의 앙상블 또한 계속 발전 중인데, 기존 '그래디언트 부스팅 알고리즘(GBM)' 의 '긴 수행시간'이라는 단점을 보완하고 예측성능을 더 끌어올린 XgBoost 나 LightGBM 같은 알고리즘 역시 정형 데이터 분류에서 가장 활용도가 높은 알고리즘으로 자리잡았습니다.
RandomForest🌲
랜덤 포레스트는 '의사결정나무(Decision Tree)'를 기반으로 하는 배깅 방식의 대표적인 앙상블 기법으로, 부트스트래핑으로 샘플링된 데이터마다 의사결정나무가 예측한 결과를 소프트보팅하여 최종 예측 결론을 얻는 알고리즘입니다.
-
소프트보팅(Soft Voting) 은 분류기들의 레이블 값 결정 확률의 평균을 구한 뒤 확률이 가장 높은 레이블 값을 최종 결과로 결정하는 방식입니다.
-
반면, 하드보팅(Hard Voting)은 예측한 결과값 중 다수의 분류기가 결정한 예측값을 최종 예측값으로 결정하는 방식으로 다수결의 원칙과 유사합니다.
-
일반적으로 소프트 보팅 방식이 예측 성능이 좋아서 더 많이 사용된다고 합니다.
랜덤포레스트는 앙상블 기법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여주어 많은 분석가와 엔지니어들에게 사랑받고 있습니다🥰
RandomForest - PYTHON
이번에는 직접 파이썬에서 랜덤포레스트분류기를 사용하여 분류 모델을 만들고 예측해보겠습니다:)
✈️ 여행 보험 구매 여부 예측 모델
https://www.kaggle.com/tejashvi14/travel-insurance-prediction-data
이번 빅분기 3회차 실기시험에서 실제 사용된 데이터로
랜덤포레스트 분류기를 만들어봅시다!
import pandas as pd
import numpy as np
data = pd.read_csv('../data/TravelInsurancePrediction.csv', index_col=0)
data.info()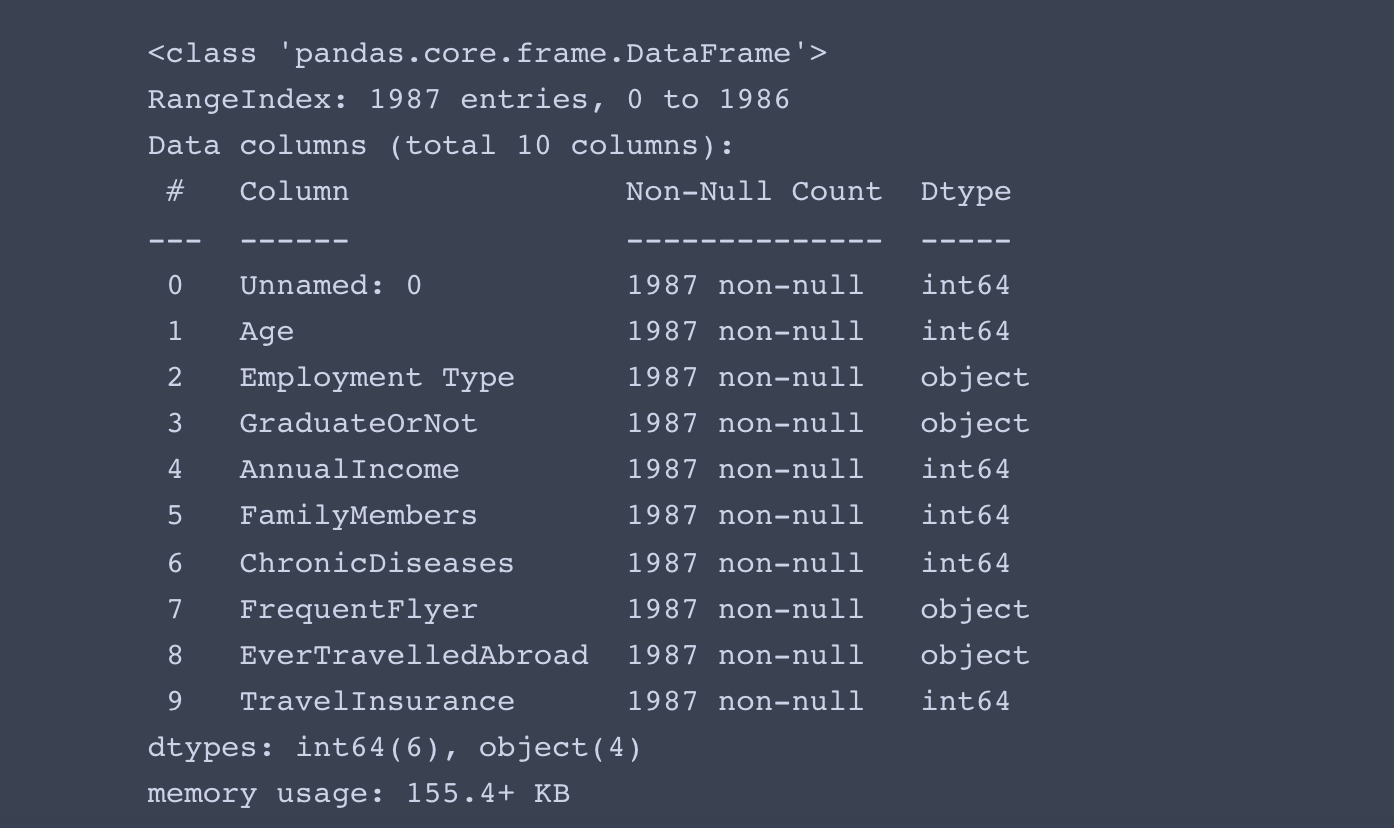
- 결측치는 없고, 범주형 데이터 컬럼이 4개입니다.
# 수치형 변수 파악
data.describe()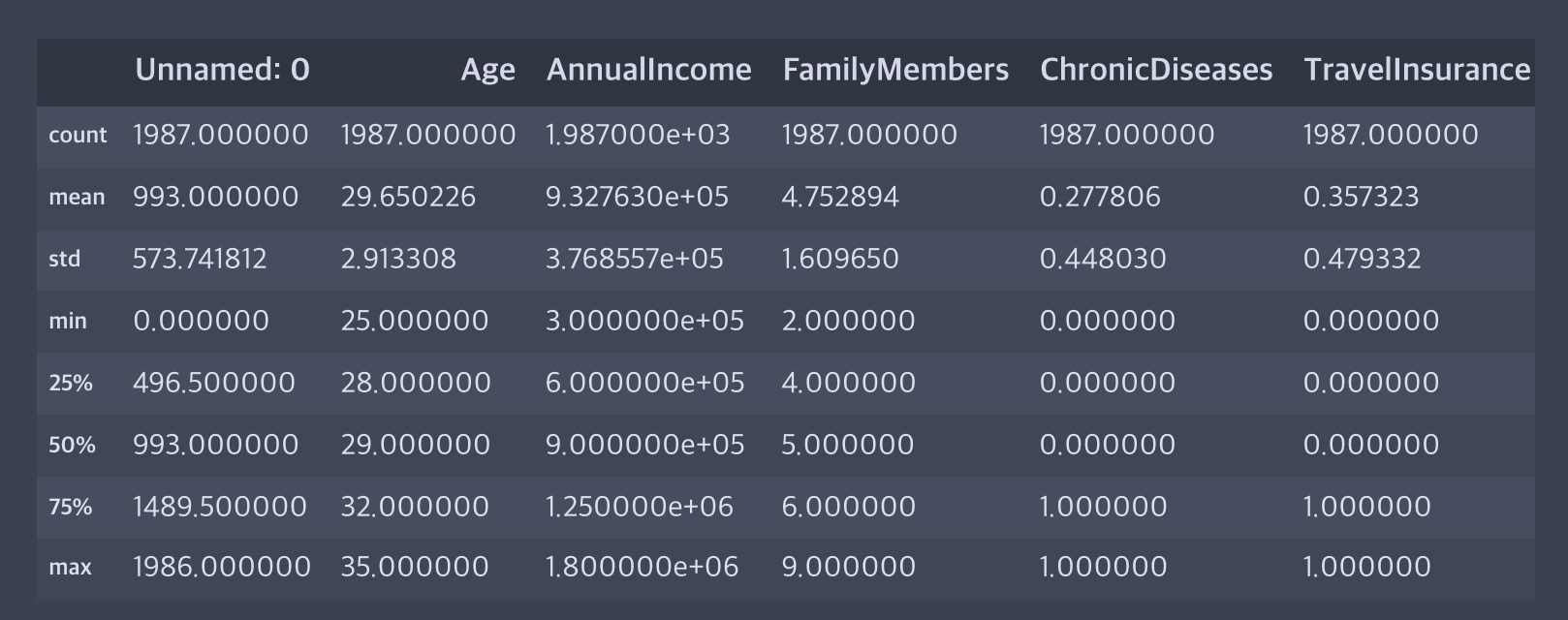
# 명목형 변수 파악
obj = data.select_dtypes(include=object).columns
print(obj)
print()
for col in obj:
print('-'*10)
print(col)
print(data[col].value_counts())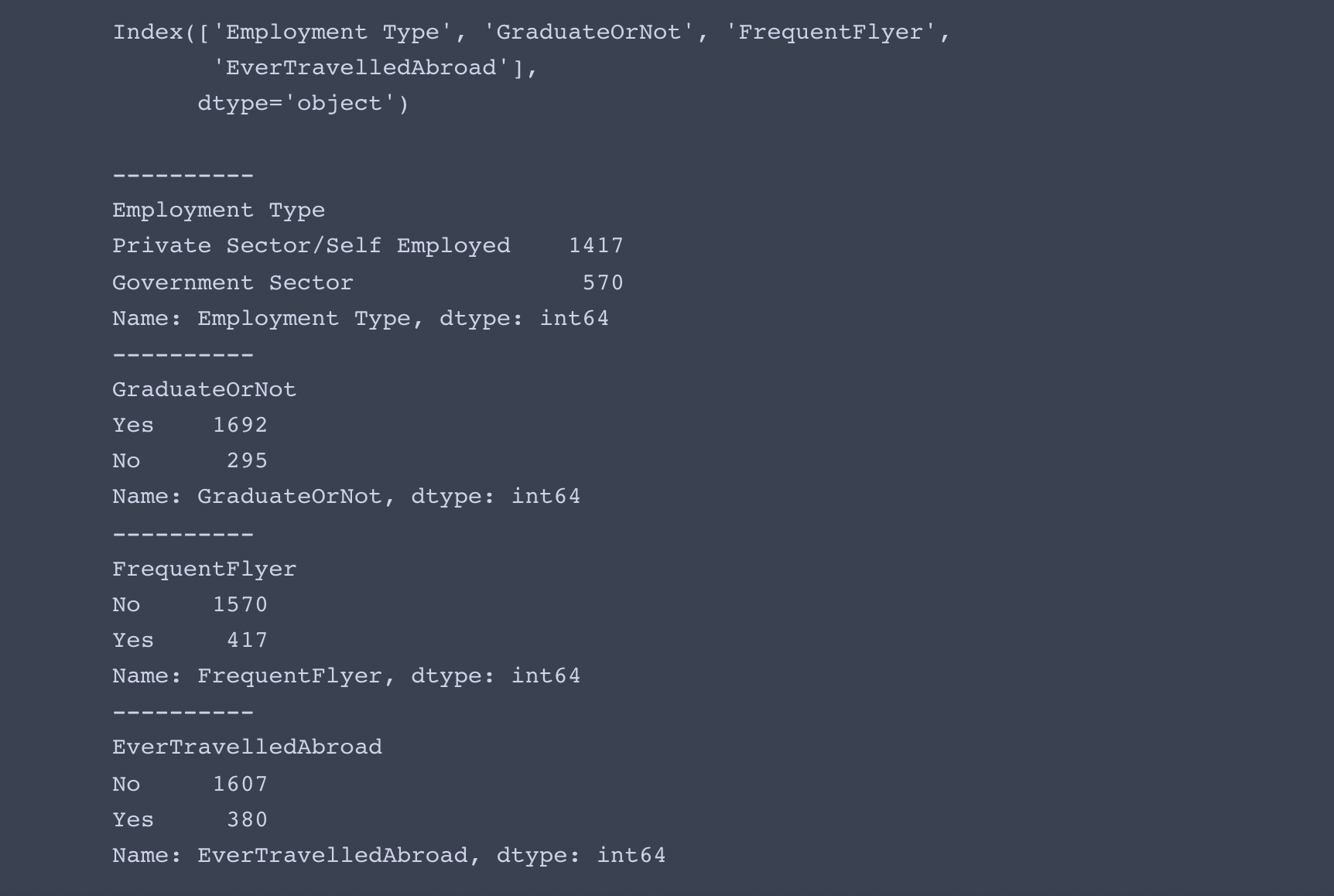
- 4개의 명목형 변수 모두 고유값이 2종류만 존재합니다.
- 라벨인코더를 사용하여 변환해도 괜찮을 것 같아 보입니다.
from sklearn.preprocessing import LabelEncoder
# 라벨인코더
le = LabelEncoder()
for col in obj:
data[col] = le.fit_transform(data[col])
data.info()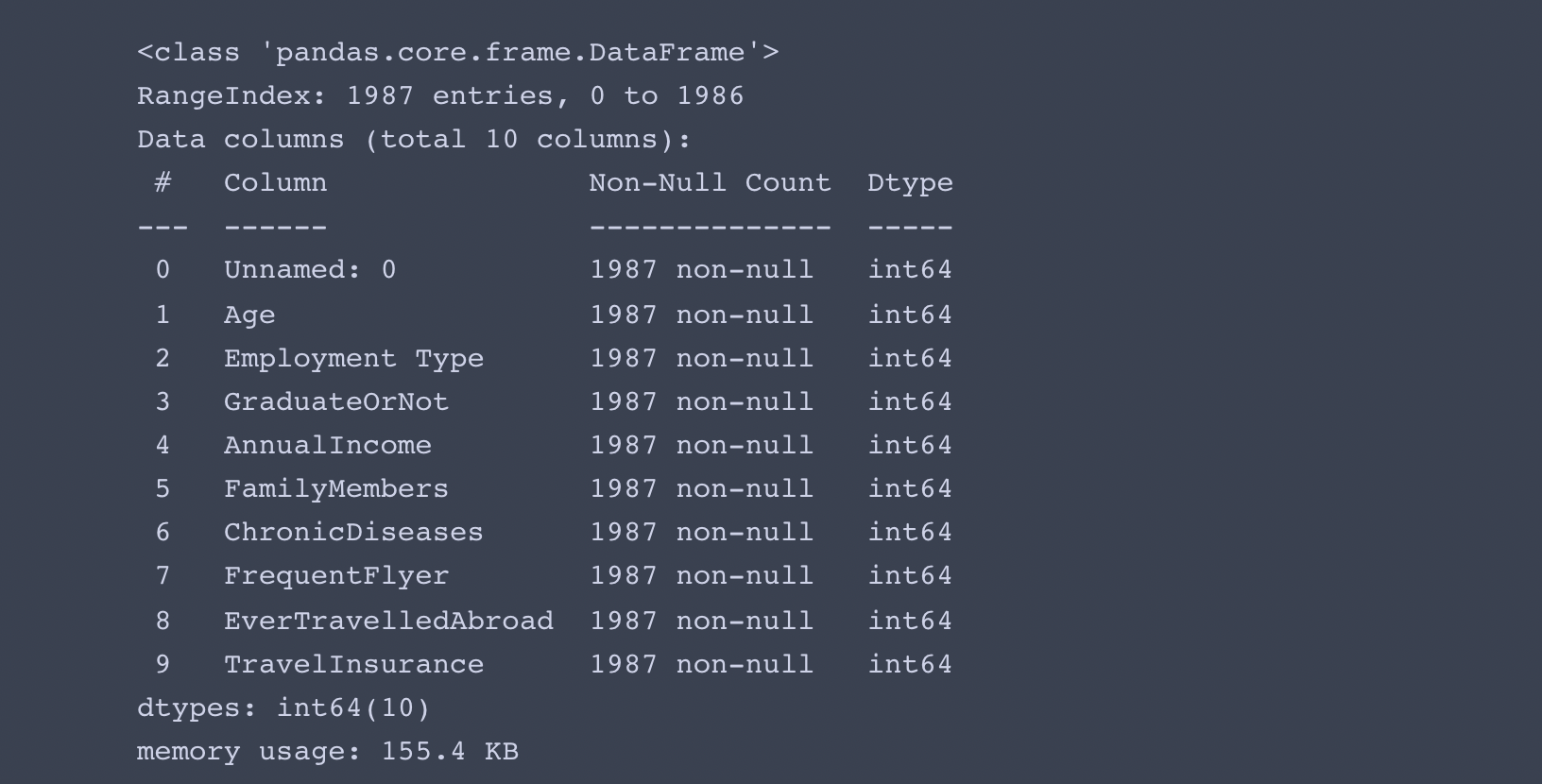
- 잘 변환되었습니다.
import time
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
start = time.time()
# 라벨 분리
X_data = data.iloc[:,1:-1]
y_data = data['TravelInsurance']
# train, test 분리
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.3, random_state=13)
# randomforest 모델링, 학습
rf = RandomForestClassifier(n_estimators=500, max_depth=6, random_state=13)
rf.fit(X_train, y_train)
# 예측 성능 평가
pred = rf.predict(X_test)
pred_proba = rf.predict_proba(X_test)[:,1]
accuracy = accuracy_score(y_test, pred)
roc = roc_auc_score(y_test, pred_proba)
print('accuracy_score:',accuracy)
print('roc_auc_score:',roc)
print('fit time:', time.time()-start)
- 0.5초도 안되는 시간 안에 80% 이상의 높은 예측 성능을 보여줍니다.
- 회귀 모델을 랜덤포레스트로 만들 경우, RandomForestClassifier 대신 RandomForestRegressor 를 사용하면 되고, 평가 지표로는 RMSE, r2_score 등이 사용됩니다.
