Models(stock)
1. LLM이란 무엇인가? (주식 시장의 관점에서)
LLM은 방대한 텍스트 데이터를 학습하여 인간처럼 텍스트를 이해하고 생성하는 AI입니다. 하지만 에이전트 시스템에서 모델은 단순한 '작가'가 아닙니다. '추론 엔진(Reasoning Engine)'입니다.
주식 투자를 예로 들어보겠습니다. (아래 예시를 연결되도록 수정.)
- 텍스트 생성: "오늘의 시황을 요약해줘"라고 하면 뉴스를 읽고 요약합니다.
- 도구 호출 (Tool Calling): "삼성전자 현재가가 얼마야?"라고 물으면, 모델은 자신의 지식(과거 데이터)으로 답하지 않고, '주식 시세 API'라는 도구를 호출해야 한다고 판단합니다. 이것이 핵심입니다.
- 구조화된 출력 (Structured Output): "매수 주문을 넣어줘"라고 하면, 주절주절 말하는 대신
{"ticker": "005930", "action": "buy", "qty": 10}같은 JSON 포맷을 정확히 뱉어냅니다. - 추론 (Reasoning): 예시로 주식 추천이라는 질문에 대해 분석하고 논리적 근거를 들어 결론을 내립니다.
2. 모델 초기화 (Initialize): 투입할 애널리스트 고용하기
(class 등 다른 방법에 대한 방법 추가, 엔트로피 까지 추가.)
LangChain에서는 init_chat_model이라는 함수 하나로 다양한 제조사(OpenAI, Anthropic, Google 등)의 모델을 쉽게 불러올 수 있습니다. 마치 주식 리서치 센터에서 전문 분야가 다른 애널리스트를 고용하는 것과 같습니다.
기본 코드 구조
import os
from langchain.chat_models import init_chat_model
# API 키 설정 (애널리스트 고용 계약서 서명)
os.environ["OPENAI_API_KEY"] = "sk-..."
# 모델 초기화 (GPT-4o라는 베테랑 애널리스트 배정)
# model = init_chat_model("gpt-4o", model_provider="openai")
# 또는 아래와 같이 축약형으로 가능
model = init_chat_model("openai:gpt-4o")주요 파라미터 (Parameters): 애널리스트 성향 조절하기
모델을 생성할 때 temperature, max_tokens 같은 파라미터를 통해 모델의 성격을 조절할 수 있습니다. 주식 분석에서 이 설정은 매우 중요합니다.
| 파라미터 | 설명 | 주식 분석 적용 예시 |
|---|---|---|
| temperature | 창의성 조절 (0~1) | 0.0 (냉철함): 재무제표 분석, 데이터 추출 시 사용. 숫자를 창작하면 안 되기 때문입니다. 0.8 (창의적): "향후 시장 시나리오 3가지를 소설처럼 써줘" 같은 브레인스토밍 시 사용. |
| max_tokens | 응답 길이 제한 | 짧게: "한 줄 요약" (뉴스 헤드라인) 길게: "심층 리포트 작성" (기업 분석 보고서) |
| timeout | 대기 시간 제한 | 실시간 트레이딩 봇이라면 5초 안에 답이 안 올 경우 주문을 취소해야 하므로 짧게 설정합니다. |
제2장: 모델을 부르는 3가지 방법 (Invocation)
모델을 사용하는 방법은 크게 Invoke(단건 호출), Stream(실시간 스트리밍), Batch(일괄 처리) 세 가지가 있습니다. 각각의 방식이 주식 데이터 처리에 어떻게 쓰이는지 시각화와 함께 살펴봅시다.
1. Invoke: 단건 분석 요청
가장 기본적인 형태입니다. 질문을 던지면, 모델이 생각을 마치고 완성된 답변을 줍니다.
상황: 사용자가 "엔비디아(NVDA)의 최근 실적 발표 내용을 바탕으로 투자 의견을 줘"라고 요청했습니다.
from langchain.messages import HumanMessage, SystemMessage
# 대화의 맥락 설정
messages = [
SystemMessage("당신은 월스트리트에서 20년 경력을 가진 반도체 전문 애널리스트입니다."),
HumanMessage("엔비디아의 최근 실적 발표 텍스트를 줄 테니, 핵심 리스크 요인 3가지만 뽑아줘.")
]
# 모델 호출
response = model.invoke(messages)
print(response.content)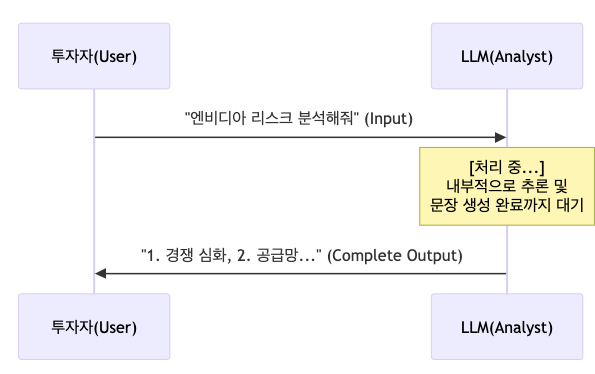
2. Stream: 실시간 뉴스 피드처럼 받기
모델이 긴 리포트를 쓸 때, 다 쓸 때까지 기다리면 사용자는 답답합니다. stream을 사용하면 모델이 글자를 생성하는 즉시 화면에 뿌려줍니다. 주식 시장의 '티커(Ticker)'나 실시간 뉴스 속보와 같습니다.
상황: 장 마감 직후 쏟아지는 공시 정보를 실시간으로 해석해서 보여줄 때.
# 스트리밍 방식으로 호출
print("--- 실시간 분석 중 ---")
for chunk in model.stream("테슬라의 이번 분기 인도량 보고서 요약해줘"):
# 한 글자(토큰)씩 생성되는 대로 즉시 출력
print(chunk.content, end="", flush=True)[Python 시각화] Stream 데이터의 누적 개념
스트리밍은 조각(Chunk)들이 모여 하나의 완성된 메시지가 되는 과정입니다.
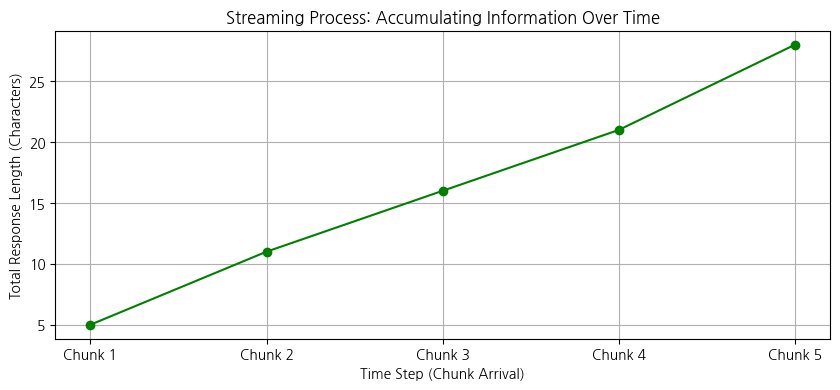
(위 그래프는 시간이 지남에 따라 정보가 어떻게 사용자에게 전달되는지를 보여줍니다. Invoke는 마지막 시점에 한 번에 도달하지만, Stream은 선형적으로 정보가 전달됩니다.)
3. Batch: 포트폴리오 일괄 분석 (병렬 처리)
여러 종목을 동시에 분석해야 할 때 for 문을 돌려 하나씩 요청하면 너무 느립니다. batch를 사용하면 여러 요청을 동시에(병렬로) 보내 처리 속도를 획기적으로 높일 수 있습니다.
상황: 내 포트폴리오에 있는 5개 종목(애플, 마소, 구글, 아마존, 메타)에 대해 각각 "매수/매도/보류" 의견을 한 단어로 받고 싶을 때.
stocks = ["AAPL", "MSFT", "GOOGL", "AMZN", "META"]
prompts = [f"{ticker} 주식에 대한 현재 월가 컨센서스를 '매수', '매도', '중립' 중 하나로만 답해." for ticker in stocks]
# 일괄 처리 (병렬로 실행되어 훨씬 빠름)
responses = model.batch(prompts, config={'max_concurrency': 5})
for ticker, response in zip(stocks, responses):
print(f"{ticker}: {response.content}")
(배치 처리를 하면 전체 소요 시간이 획기적으로 단축됨을 볼 수 있습니다.)
요약
모델은 에이전트의 두뇌입니다. 어떤 두뇌를 쓰느냐(모델 선택), 그 두뇌에게 어떤 지시를 내리느냐(프롬프트 및 파라미터), 그리고 어떻게 일을 시키느냐(Invoke/Stream/Batch)에 따라 여러분이 만드는 'AI 주식 비서'의 성능이 결정됩니다.
- 정확성이 필요한 데이터 추출에는
temperature=0을 사용하세요. (예: 재무제표에서 PER 추출) - 사용자 경험(UX)이 중요하다면
stream을 사용하여 기다리는 지루함을 없애세요. - 대량의 뉴스나 종목을 처리할 때는 반드시
batch를 사용하여 API 비용과 시간을 절약하세요.
(더 자세한 내용 추가)
1. Temperature란 무엇인가?
AI 모델(LLM)이 다음 단어를 선택할 때 "얼마나 모험(무작위성)을 할 것인가"를 조절하는 설정값입니다. (보통 0에서 1, 또는 2 사이의 값을 가집니다.)
Temperature가 낮음 (0에 가까움):
성격: 모범생, 로봇, 원칙주의자.
행동: 확률이 가장 높은 단어 하나만 무조건 선택합니다.
결과: 답변이 매우 논리적이고 사실에 기반하며, 항상 똑같은 질문에는 똑같은 대답을 내놓습니다. (결정론적, Deterministic)
Temperature가 높음 (1에 가까움):
성격: 예술가, 이야기꾼, 자유로운 영혼.
행동: 확률이 조금 낮더라도 다양한 단어를 선택해 봅니다.
결과: 답변이 다채롭고 창의적이지만, 없는 말을 지어내거나(Hallucination) 엉뚱한 소리를 할 가능성이 커집니다.
이번 챕터에서는 두뇌에게 '손과 발(Tool Calling)'을 달아주고, 두뇌가 내뱉는 말을 우리가 원하는 '정해진 양식(Structured Output)'으로 깔끔하게 정리하는 법을 배웁니다. 이것은 AI를 단순한 챗봇에서 실전 금융 에이전트로 진화시키는 가장 중요한 단계입니다.
제4장: 도구 호출 (Tool Calling) - 에이전트에게 손을 달아주기
1. 개념: LLM은 실시간 주가를 모른다
여러분이 "지금 삼성전자 얼마야?"라고 물으면, 학습 시점이 지난 모델은 모릅니다. 모델이 할 수 있는 최선은 "주가 조회 도구를 써야겠군"이라고 판단하는 것입니다.
Tool Calling(Function Calling)은 모델이 직접 코드를 실행하는 것이 아닙니다. 모델은 "이 함수를, 이 파라미터로 실행해줘"라고 요청(Request)만 하고, 실제 실행은 우리 시스템이 담당합니다.
2. 실전 코드: 주가 조회 도구 만들기
가상의 주식 조회 함수를 만들고 모델에 연결해 보겠습니다.
from langchain.tools import tool
from langchain.chat_models import init_chat_model
# 1. 도구(Tool) 정의: 실제로는 yfinance 같은 라이브러리를 씁니다.
@tool
def get_stock_price(ticker: str) -> str:
"""
특정 주식 종목(ticker)의 현재 가격을 조회합니다.
입력값은 'AAPL', '005930' 같은 티커 심볼이어야 합니다.
"""
# 실제 API 호출을 가정 (예시 데이터)
mock_data = {
"AAPL": "185.50 USD",
"TSLA": "240.30 USD",
"005930": "75,000 KRW"
}
price = mock_data.get(ticker, "데이터 없음")
return f"{ticker}의 현재 가격은 {price}입니다."
# 2. 모델 초기화 및 도구 바인딩 (Binding)
model = init_chat_model("openai:gpt-4o")
model_with_tools = model.bind_tools([get_stock_price])
# 3. 모델 호출
query = "애플(AAPL)이랑 테슬라(TSLA) 지금 얼마야?"
response = model_with_tools.invoke(query)
# 4. 모델의 판단 확인 (실행 결과가 아니라, 실행 요청이 들어있음)
print(f"모델의 응답 타입: {type(response)}")
for tool_call in response.tool_calls:
print(f"도구 호출 요청: {tool_call['name']}")
print(f" 인자(Args): {tool_call['args']}")실행 결과 예상:
도구 호출 요청: get_stock_price
인자(Args): {'ticker': 'AAPL'}
도구 호출 요청: get_stock_price
인자(Args): {'ticker': 'TSLA'}보시다시피 모델은 똑똑하게 두 종목을 각각 조회해야 한다고 판단하여 병렬(Parallel) 호출을 요청했습니다.
3. 시각화: 도구 호출의 흐름 (The Loop)
이 과정이 어떻게 돌아가는지 Mermaid 다이어그램으로 명확히 봅시다.
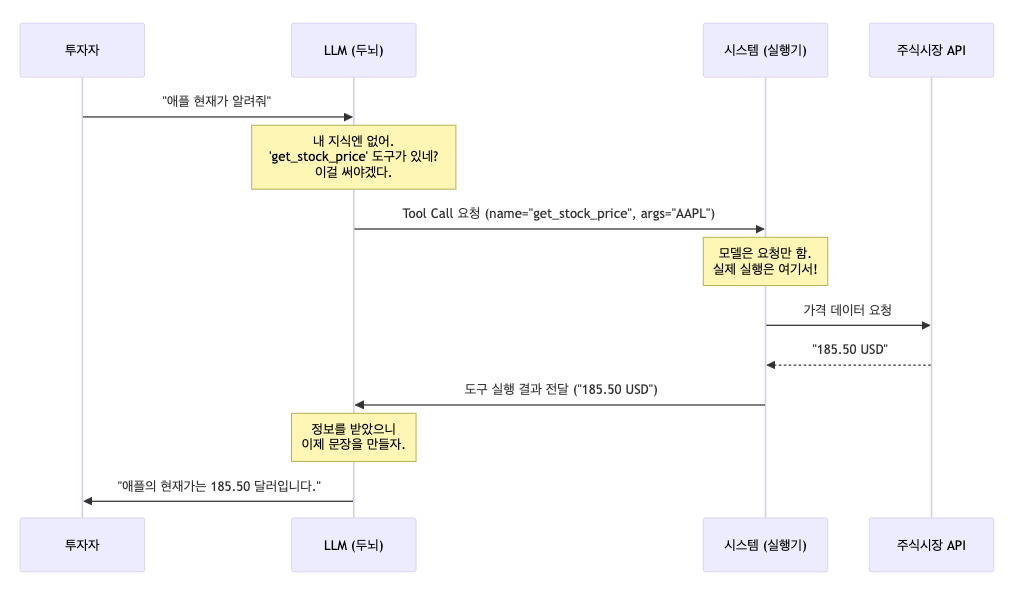
제5장: 구조화된 출력 (Structured Output) - 정해진 양식으로 보고받기
1. 개념: 주절거리는 텍스트 대신 깔끔한 JSON
금융 데이터 처리에 있어 가장 큰 적은 "불확실한 텍스트"입니다.
- 나쁜 예: "음, 뉴스를 보니 애플 분위기가 좋아요. 매수하는 게 좋을 것 같네요. 목표가는 아마 200불?"
- 좋은 예:
{"ticker": "AAPL", "sentiment": "bullish", "target_price": 200}
LangChain의 with_structured_output을 사용하면 모델이 Pydantic 객체나 JSON으로만 답하도록 강제할 수 있습니다.
2. 실전 코드: 뉴스 감성 분석기
주식 뉴스를 읽고 핵심 정보를 추출하는 구조화 모델을 만들어 봅시다.
from pydantic import BaseModel, Field
from typing import Optional
# 1. 원하는 출력 양식(Schema) 정의 - 주문서 양식 만들기
class MarketSentiment(BaseModel):
"""금융 뉴스에서 추출한 시장 심리 및 데이터"""
ticker: str = Field(..., description="주식 티커 심볼 (예: AAPL, NVDA)")
sentiment_score: int = Field(..., description="긍부정 점수 (0: 매우 부정 ~ 10: 매우 긍정)")
key_event: str = Field(..., description="주가 변동의 핵심 원인 요약")
action: str = Field(..., description="추천 행동 (매수/매도/관망)")
# 2. 모델에 구조화 강제 적용
structured_llm = model.with_structured_output(MarketSentiment)
# 3. 분석할 뉴스 텍스트
news_text = """
엔비디아(NVDA)가 예상을 뛰어넘는 4분기 실적을 발표했습니다.
데이터센터 매출이 폭발적으로 증가하며 주가는 시간외 거래에서 5% 급등 중입니다.
전문가들은 AI 붐이 지속될 것으로 보고 목표가를 상향 조정하고 있습니다.
"""
# 4. 호출 (결과는 문자열이 아니라 객체로 나옴)
result = structured_llm.invoke(news_text)
print(f"종목: {result.ticker}")
print(f"점수: {result.sentiment_score}/10")
print(f"요약: {result.key_event}")
print(f"판단: {result.action}")실행 결과:
종목: NVDA
점수: 9/10
요약: 예상 상회 실적 발표 및 데이터센터 매출 폭증
판단: 매수3. 시각화: 구조화된 데이터의 활용
구조화된 출력(Structured Output)이 왜 강력할까요? 텍스트가 데이터가 되기 때문입니다. 데이터가 되면 그래프를 그릴 수 있습니다.
여러 개의 뉴스를 분석하여 점수화한 뒤 시각화하는 파이썬 코드를 보겠습니다.
import matplotlib.pyplot as plt
# 가상의 구조화된 출력 결과 리스트 (여러 뉴스를 분석했다고 가정)
analysis_results = [
MarketSentiment(ticker="NVDA", sentiment_score=9, key_event="Earnings Beat", action="Buy"),
MarketSentiment(ticker="TSLA", sentiment_score=4, key_event="Price Cut Concerns", action="Hold"),
MarketSentiment(ticker="AAPL", sentiment_score=6, key_event="New Product Rumor", action="Hold"),
MarketSentiment(ticker="MSFT", sentiment_score=8, key_event="Cloud Growth", action="Buy")
]
# 데이터 분리
tickers = [r.ticker for r in analysis_results]
scores = [r.sentiment_score for r in analysis_results]
colors = ['red' if s < 5 else 'grey' if s < 7 else 'green' for s in scores]
# 시각화
plt.figure(figsize=(10, 5))
bars = plt.bar(tickers, scores, color=colors)
plt.axhline(y=5, color='black', linestyle='--', alpha=0.3)
plt.title("Market Sentiment Analysis by LLM Agent")
plt.ylabel("Sentiment Score (0-10)")
plt.ylim(0, 10)
# 막대 위에 점수 표시
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height,
f'{height}', ha='center', va='bottom')
plt.show()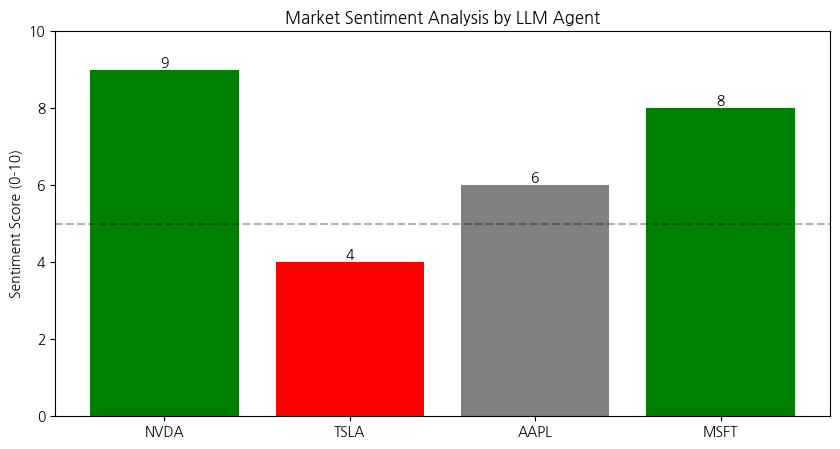
이 그래프는 LLM이 텍스트를 읽고 구조화된 데이터(숫자)로 변환해주었기에 그릴 수 있는 것입니다. 이것이 바로 자동화된 퀀트 분석의 기초가 됩니다.
요약 및 제언
- Tool Calling은 에이전트가 외부 세상(주식 시장, DB, 웹)과 소통하는 유일한 창구입니다.
bind_tools를 통해 모델에게 도구 사용법을 알려주세요. - Structured Output은 에이전트의 생각을 시스템이 이해할 수 있는 데이터로 바꾸는 번역기입니다.
with_structured_output과Pydantic을 사용해 데이터의 무결성을 보장하세요. - 이 두 가지를 결합하면, "뉴스를 읽고(Input) -> 도구로 현재가를 확인하고(Tool) -> 매매 전략을 JSON으로 출력하는(Structured Output)" 완전한 AI 주식 에이전트를 만들 수 있습니다.
