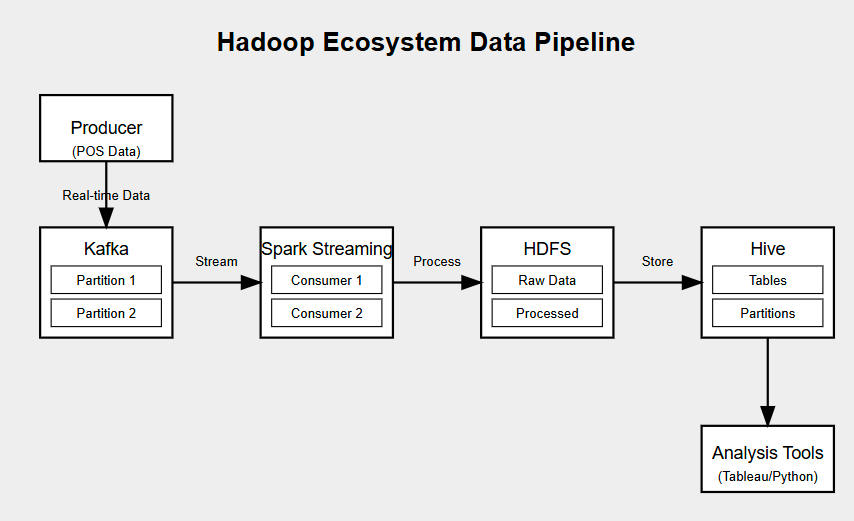
전체 하둡 에코시스템 기반의 데이터 파이프라인
-
데이터 생성 (Producer)
- 전국 POS 단말기에서 실시간 거래 데이터 발생
- 초당 평균 1,000건의 거래 데이터 생성
- JSON 형태로 데이터 전송
-
메시지 큐잉 (Kafka)
- Topic: store_transactions
- Partition 1: 수도권 지역 데이터
- Partition 2: 비수도권 지역 데이터
- 메시지 보관 기간: 7일
- 복제 계수: 3
-
실시간 처리 (Spark Streaming)
- Consumer Group: spark-streaming-group
- Consumer 1: 수도권 데이터 처리
- Consumer 2: 비수도권 데이터 처리
- 처리 주기: 10초 (micro-batch)
-
저장소 (HDFS)
- Raw Data: 원본 데이터 저장
/retail/raw/yyyy/mm/dd/HH/ - Processed: 처리된 데이터 저장
/retail/processed/yyyy/mm/dd/
- Raw Data: 원본 데이터 저장
-
데이터 웨어하우스 (Hive)
- 테이블: retail_transactions
- 파티션: 일자별
- 저장 포맷: Parquet
- 압축 방식: Snappy
-
분석 도구 연동
- Tableau: 리포트 생성
- Python: 데이터 분석
- 일일 배치 처리: 23:00 실행
GCP와 비교
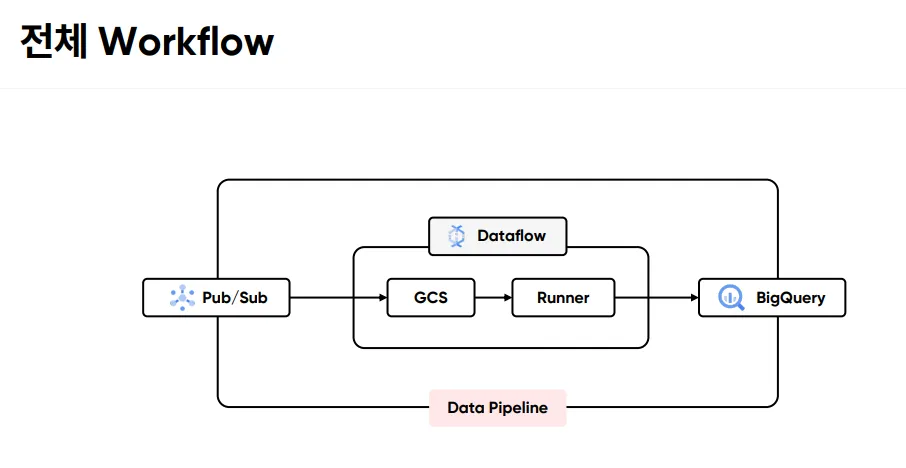
하둡 에코시스템과 이 GCP(Google Cloud Platform) 기반 워크플로우를 비교:
- 위 그림에서 GCS 왼쪽에도 Runner가 달려있어 Reciever 역할을 해야한다.
-
메시지 수집 단계 비교
[GCP] Pub/Sub : 완전 관리형 메시징 서비스 [Hadoop] Kafka : 자체 관리 메시징 시스템- Pub/Sub: 자동 스케일링, 관리 불필요
- Kafka: 직접 브로커 관리, 파티션 설정 필요
-
데이터 저장 단계 비교
[GCP] GCS : 클라우드 스토리지 [Hadoop] HDFS : 분산 파일 시스템예시: 일일 100GB 데이터 저장 시
- GCS: 자동 확장/축소, 바로 사용 가능
- HDFS: 물리적 용량 계획, 노드 관리 필요
-
데이터 처리 단계 비교
[GCP] Dataflow : 관리형 Apache Beam [Hadoop] Spark : 분산 처리 엔진예시: 시간당 100만건 처리 시
- Dataflow Runner: 자동 워커 조정
- Spark: 클러스터 리소스 직접 관리
-
데이터 웨어하우스 비교
[GCP] BigQuery : 서버리스 DW [Hadoop] Hive : 데이터 웨어하우스예시: 일일 리포트 생성 시
- BigQuery: SQL 작성만으로 실행
- Hive: 클러스터 리소스 고려 필요
주요 차이점:
1. 관리 방식
- GCP: 완전 관리형 서비스 (운영 부담 ↓)
- Hadoop: 자체 관리 필요 (커스터마이징 ↑)
-
비용 구조
- GCP: 사용한 만큼 지불
- Hadoop: 초기 인프라 투자 필요
-
확장성
- GCP: 자동 스케일링
- Hadoop: 수동 확장 관리
-
개발 복잡도
[GCP 예시 코드] # Python Pub/Sub publish_client.publish(topic_path, data) [Hadoop 예시 코드] # Kafka Producer producer.send(topic, key, value) producer.flush() -
모니터링/운영
- GCP: 통합 대시보드 제공
- Hadoop: 각 컴포넌트별 모니터링 구축
결론적으로:
- GCP는 빠른 구축과 적은 운영 부담이 장점
- Hadoop은 세밀한 제어와 커스터마이징이 장점
선택 기준:
1. 운영 인력이 부족하면 → GCP
2. 비용 최적화가 중요하면 → Hadoop
3. 빠른 구축이 필요하면 → GCP
4. 상세한 커스터마이징이 필요하면 → Hadoop

시리즈를 기반으로 작성하였습니다.