

📘 컬렉션이란
- 목록성 데이터를 처리하는 자료 구조 통칭
📚 List
- 배열과 비슷하지만 크기가 유연하고 더 편리한 기능을 많이 가지고 있음
- ArrayList, Vector, Stack, LinkedList를 많이 사용
1️⃣ ArrayList
생성자
- ArrayList() : 객체를 저장할 초기 공간이 10개인 리스트 생성
- ArrayList(Collection<? extends E> c) : 매개 변수로 넘어온 컬렉션 객체가 저장되어 있는 리스트 생성
- ArrayList(int initialCapacity): 매개 변수로 넘어온 initialCapacity를 저장 공간으로 가짐
메서드
boolean | add(E e)
void | add(int index, E element)
boolean | addAll(Collection<? extends E> c)
boolean | addAll(int index, Collection<? extends E> c)
void | clear()
Object | clone()
boolean | contains(Object o)
void | forEach(Consumer<? super E> action)
E | get(int index)
int | indexOf(Object o)
boolean | isEmpty()
Iterator<E> | iterator()
int | lastIndexOf(Object o)
ListIterator<E> | listIterator()
ListIterator<E> | listIterator(int index)
E | remove(int index)
boolean | remove(Object o)
boolean | removeAll(Collection<?> c)
boolean | removeIf(Predicate<? super E> filter)
protected void | removeRange(int fromIndex, int toIndex)
void | replaceAll(UnaryOperator<E> operator)
boolean | retainAll(Collection<?> c)
E | set(int index, E element)
int | size()
void | sort(Comparator<? super E> c)
Spliterator<E> | spliterator()
List<E> | subList(int fromIndex, int toIndex)
Object[] | toArray()
<T> T[] | toArray(T[] a)
void | trimToSize()List 주의점
//Shallow copy
ArrayList<String> list = new ArrayList<String>(originList);- 해당 문장은 새로 생성한 list가 originList의 값만 복사해서 사용하겠다는 것이 아니라 객체의 참조 주소값까지 사용하겠다는 뜻이 된다. 때문에 둘 중 하나에 자료를 넣고 삭제해도 같은 주소값에서 객체가 할당 되고 삭제 되기 때문에 문제가 발생할 수 있음
→ DeepCopy를 할 것 : arraycopy() 메서드 이용
2️⃣ Vector
- ArrayList 클래스와 사용법 거의 동일, 기능도 비슷
- ArrayList와 달리 Thread Safe함
3️⃣ Stack
- LIFO(Last In First Out) : 후입선출, 나중에 들어온 데이터를 가장 먼저 처리함
생성자
- Stack()
메서드
boolean | empty()
E | peek()
E | pop()
E | push(E item)
int | search(Object o)4️⃣ LinkedList
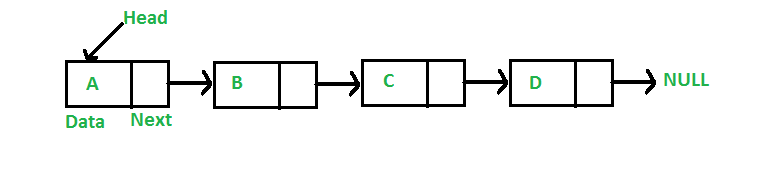
- ArrayLis와 다르게 엘리먼트와 엘리먼트 간의 연결을 이용해서 리스트 구현
- 데이터의 삭제와 삽입은 빠르고 인덱스 조회는 느림
- Queue와 Deque 인터페이스도 구현
Queue
- FIFO(First In First Out): 처음 들어온 데이터가 먼저 나가는 구조]
- 여러 스레드에서 들어오는 작업을 순차적으로 처리할 때 많이 사용
메서드
boolean | add(E e)
E | element()
boolean | offer(E e)
E | peek()
E | poll()
E | remove()Deque
- 맨 앞에 값을 넣거나 빼는 작업, 맨 뒤에 값을 넣거나 빼는 작업을 수행할 수 있음
📚 Set
- 순서에 상관 없이 어떤 데이터가 존재하는지를 확인하기 위한 용도로 많이 사용
- HashSet, TreeSet, LinkedHashSet이 주요 클래스
1️⃣ HashSet
- 순서가 전혀 필요 없는 데이터를 해시 테이블에 저장, Set 중에 가장 성능 좋음
생성자
- HashSet()
- HashSet(Collection<? extends E> c)
- HashSet(int initialCapacity)
- HashSet(int initialCapacity, Float loadFactor)
loadFactor: 데이터의 개수/ 저장 공간
메서드
boolean | add(E e)
boolean | addAll(Collection<? extends E> c)
void | clear()
boolean | containsAll(Collection<?> c)
boolean | equals(Object o)
int | hashCode()
boolean | isEmpty()
Iterator<E> | iterator()
boolean | remove(Object o)
boolean | removeAll(Collection<?> c)
boolean | retainAll(Collection<?> c)
int | size()
default Spliterator<E> | spliterator()
Object[] | toArray()
<T> T[] | toArray(T[] a)2️⃣ TreeSet

red-black 트리: 각 노드의 색을 붉은 색이나 검은색으로 구분하여 데이터를 빠르고 쉽게 찾을 수 있는 이진 트리
- 저장된 데이터에 따라서 정렬
- 검색 성능이 높음
- HashSet보다 약간 성능이 느림
3️⃣ LinkedHashSet
- 연결된 목록 타입으로 구현된 해시테이블에 데이터 저장, 성능이 셋 중에 가장 나쁨
📚 Map
- Key-Value 값으로 이루어지고 중복되지 않음
- HashMap, TreeMap, LinkedHashMap이 유명한 클래스
1️⃣ HsahMap
- 가장 많이 사용됨
- 담을 데이터가 많은 경우 초기 크기 지정해주는 것이 좋음
- 기존값을 수정할 때도 put을 이용
생성자
- HashMap()
- HashMap(int initialCapacity)
- HashMap(int initialCapacity, float loadFactor)
- HashMap(Map<? extends K,? extends V> m)
메서드
void clear()
Object clone()
V compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
boolean containsKey(Object key)
boolean containsValue(Object value)
Set<Map.Entry<K,V>> entrySet()
void forEach(BiConsumer<? super K,? super V> action)
V get(Object key)
V getOrDefault(Object key, V defaultValue)
boolean isEmpty()
Set<K> keySet()
V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
V put(K key, V value)
void putAll(Map<? extends K,? extends V> m)
V putIfAbsent(K key, V value)
V remove(Object key)
boolean remove(Object key, Object value)
V replace(K key, V value)
boolean replace(K key, V oldValue, V newValue)
void replaceAll(BiFunction<? super K,? super V,? extends V> function)
int size()
Collection<V> values()2️⃣ TreeMap
- 저장하면서 키를 정렬
- 매우 많은 데이터를 사용할 때는 HashMap보다 느림
3️⃣ LinkedHashMap
- Key의 저장 순서를 보장
📚 컬렉션별 시간복잡도
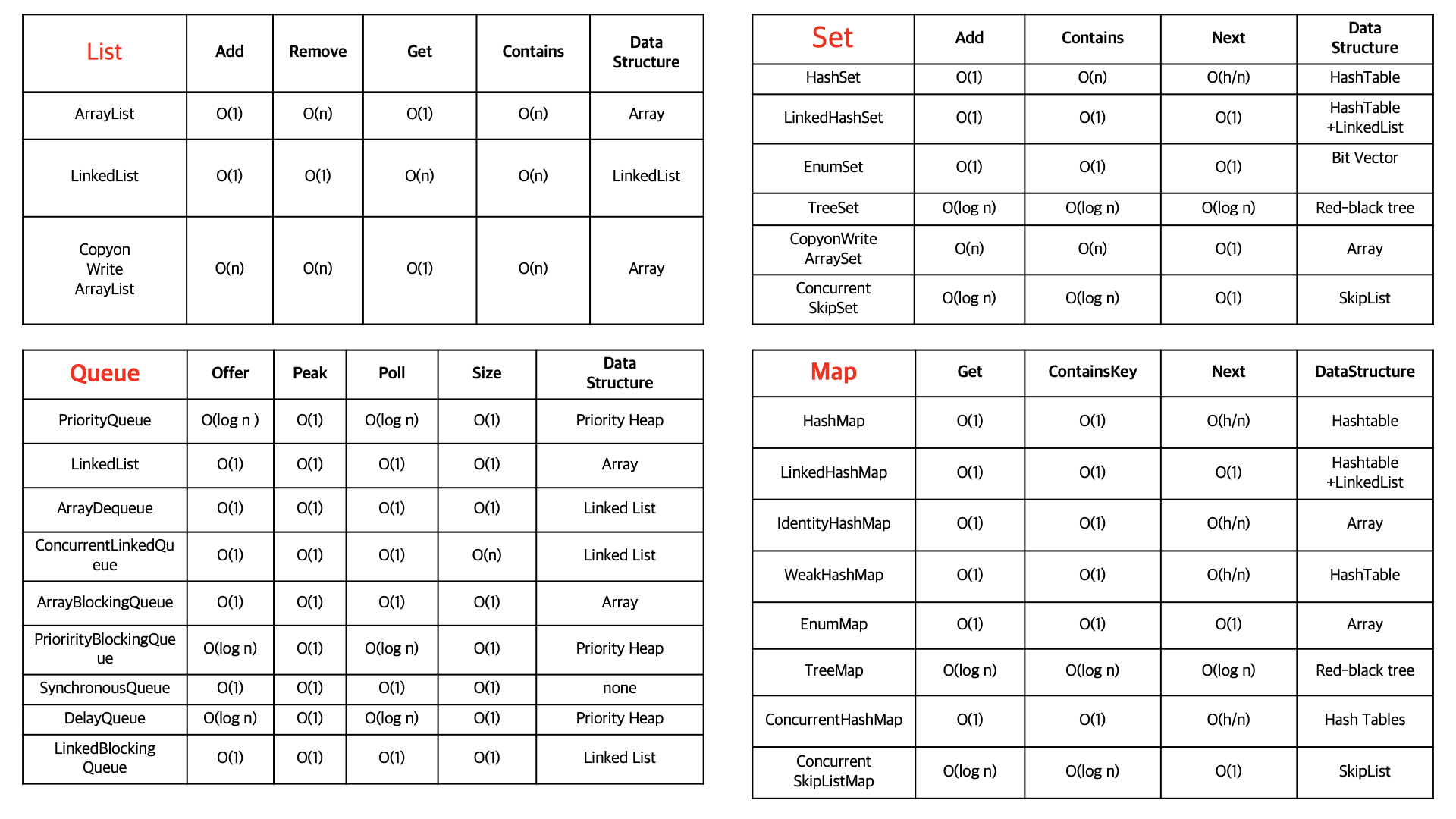
출처

배우고 활용하는 것을 즐기는 개발자, 한지연입니다!