필수과제1) Custom Model
Hook
Hook이란?
Tensor / Model에 거는 hook으로 패키지화된 코드에서 다른 프로그래머가 custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스
Hook의 종류
-
Tensor / Model에 적용하느냐에 따른 분류
-
Forward, Backward에 적용하느냐에 따른 분류
--> Tensor는 backward만, Model은 forward/backward 둘 다 있음 -
프로그램 실행 전/후에 불러오느냐에 따른 분류
--> Forward시에만, pre_hook/hook으로 나뉨 -
각각 hook마다 argument가 다르기 때문에 document를 참고해서 선언해야함
어떻게 등록?

등등 torch.register를 사용해서 등록
return해주는 건 hook에서 변경한 값만! 혹은 pass 써주면 return 고려 안해도 됨
torch.gather
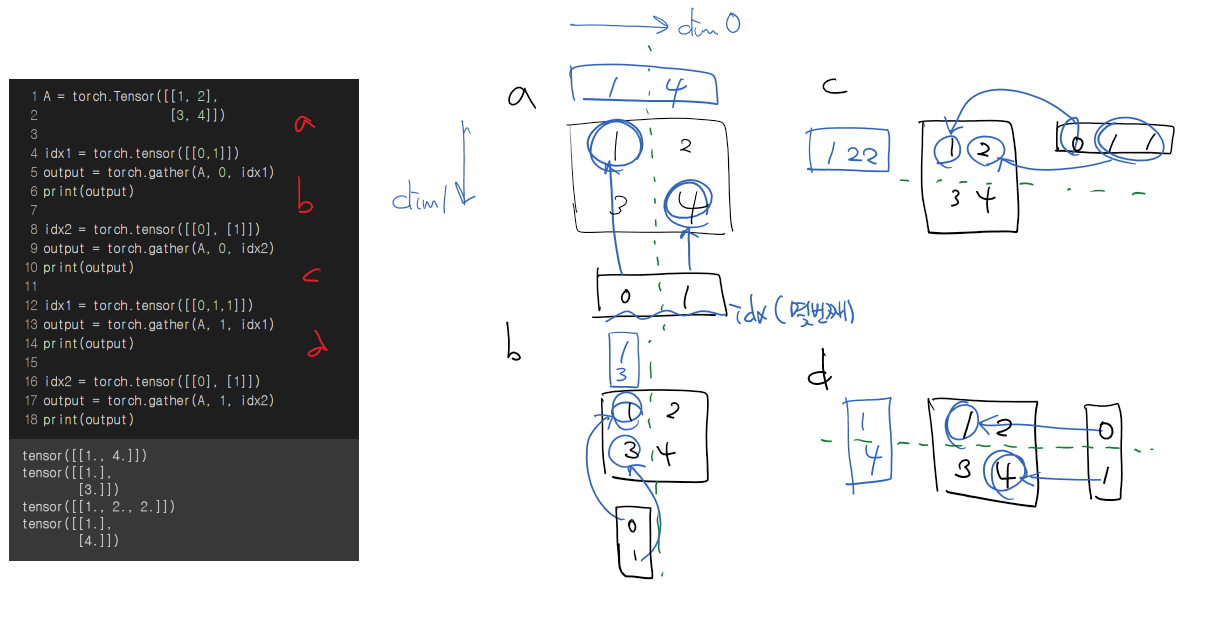
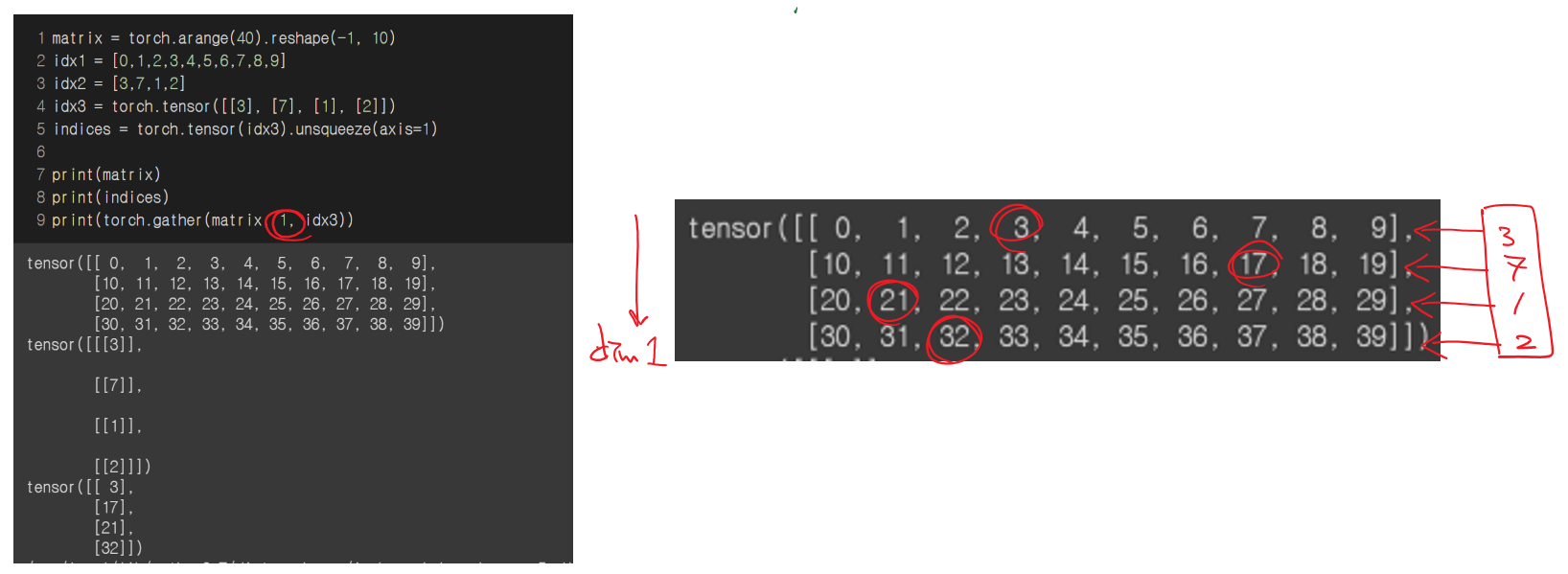
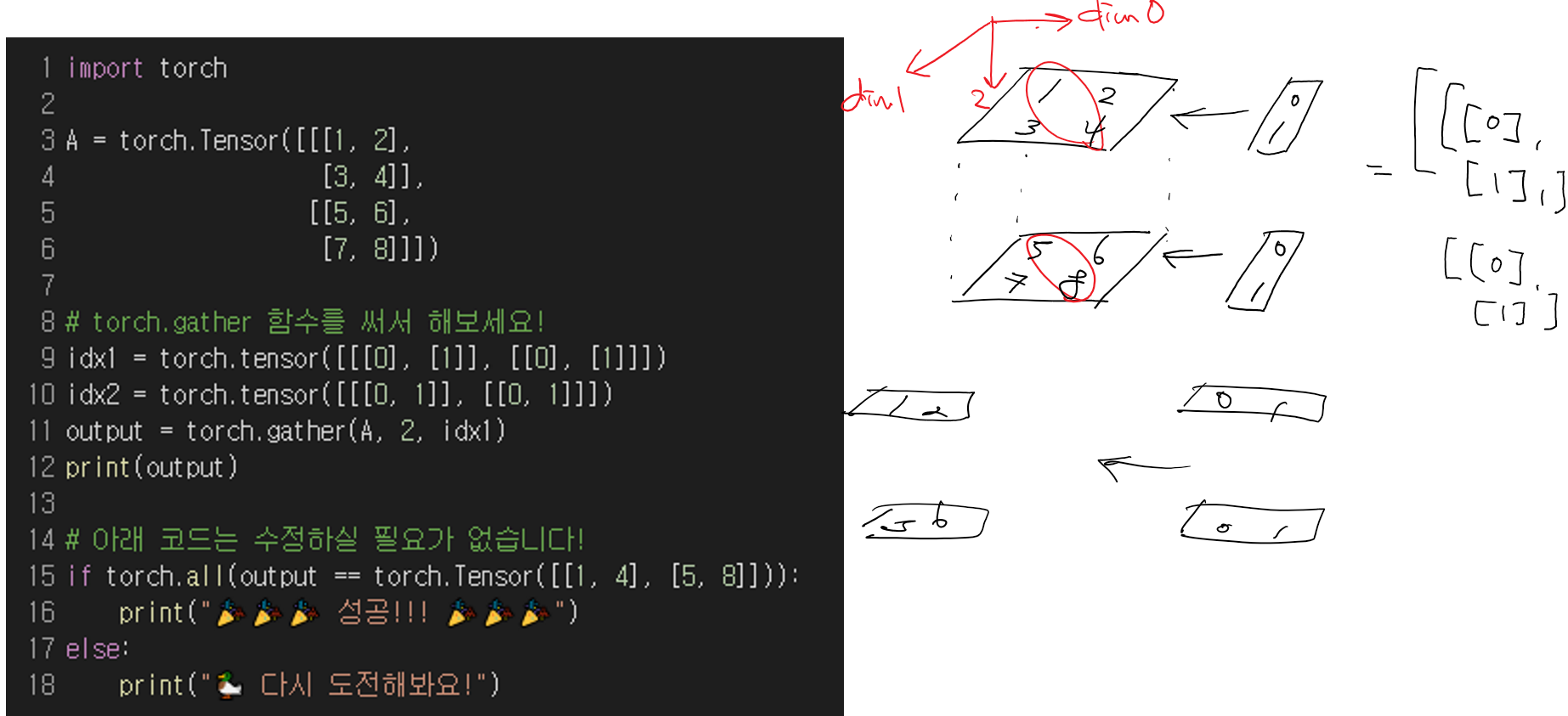
gather: 내가 원하는 원소들 뽑기 위해 사용- dim은 최고차원으로 두고 계산하는 것이 편리하다
- dim을 제외한 다른 부분은 크기가 동일해야함
-
shape는 C H W 순서(rank 순서와 같음)
그런데 dim은 W H C 순서로 고정인듯 -
dim 결정되면 남은것 중 가장 높은 dim을 기준으로 연산하는 것 같음
e.g. dim=2로 설정하면 나머지 연산은 dim=1, dim=0 순서를 기준으로 하는 등
apply
apply: Model을 구성하는 모든 module에 동일한 함수를 적용
보통은 weight initialize에 사용된다- Postorder traverse 방식으로 각 module을 탐색
extra_repr
def extra_repr(self):
# (Optional)Set the extra information about this module. You can test
# it by printing an object of this class.
return 'input_features={}, output_features={}, bias={}'.format(
self.input_features, self.output_features, self.bias is not None
)__repr__: repr()로 __repr__ 메소드를 호출, formal string(''로 감싸져 해당 객체를 만들 수 있는 문자열)을 출력함
Module을 만들땐 module 이름을 써두는 것 같음extra_repr: module에 대한 추가정보를 전달 가능
functools.partial
functools.partial: 기존의 함수와 구현은 동일하고 parameter만 미리 정해준 새로운 함수를 생성- 미리 정할 parameter는 순서대로 입력하거나, 명시해서 특정 parameter를 설정해주거나 상관 없다
하지만 중간에 특정 parameter를 설정했다면 사용할때도 명시해주지 않으면 순서가 꼬여서 에러날 수 있음
*(asterisk)를 사용하면 parameter 사용할 때 좀 자유로움
def func_1(a, b, c):
return a + b * c
func_2 = partial(func_1, b=1)
func_2(10, c=8)
# a=10, b=1, c=8 --> 10 + 1 * 8 = 18
func_2 = partial(func_1, c=4)
func_2(10, 8)
# a=10, b=8, c=4 --> 10 + 8 * 4 = 42
func_2 = partial(func_1, 1)
func_2(10, 8)
# a=1, b=10, c=8 --> 1 + 10 * 8 = 81
필수과제2) Custom Dataset & DataLoader
Dataset
-
torchvision.dataset: torch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음-
CIFAR-10: CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
-
CIFAR-100: This dataset is just like the CIFAR-10, except it has 100 classes containing 600 images each. There are 500 training images and 100 testing images per class. The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
-
MNIST: 손으로 쓴 숫자들로 이루어진 대형 데이터베이스이며, 다양한 화상 처리 시스템을 트레이닝하기 위해 일반적으로 사용된다
-
-
torchtext.dataset: torch.utils.data.Dataset을 상속하는 텍스트 데이터셋의 모음- AG_NEWS:AG is a collection of more than 1 million news articles. News articles have been gathered from more than 2000 news sources by ComeToMyHead in more than 1 year of activity.
map-style 형식
class CustomDataset(Dataset):
def __init__(self,):
'''
데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작
'''
pass
def __len__(self):
'''
Dataset의 최대 요소 수를 반환하는데 사용
'''
pass
def __getitem__(self, idx):
'''
데이터셋의 idx번째 데이터를 반환하는데 사용
'''
pass
dataset_custom = CustomDataset()Dataloader
참고: https://subinium.github.io/pytorch-dataloader/
num_workers
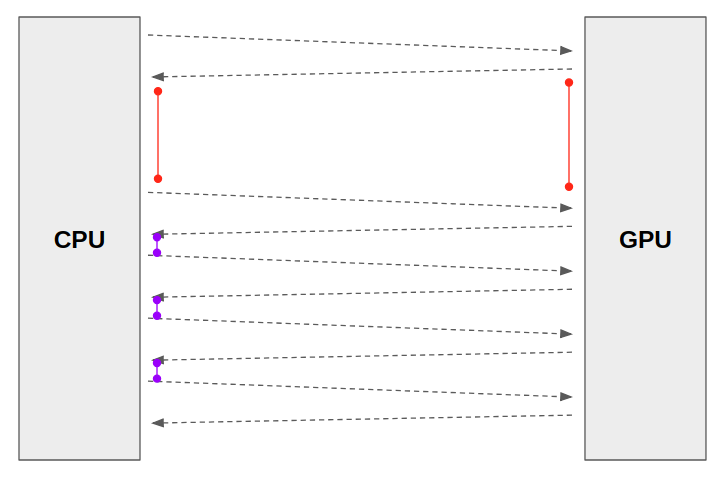
https://jybaek.tistory.com/799
- 데이터를 불러올때 사용하는 서브 프로세스(subprocess) 개수
CPU -> GPU로 task 보낼 때 몇 코어로 보내줄지 - 많을수록 좋은거 아님
batch_size
- 각 feature당 몇 sample씩 collate_fn에 넣을건지
- 전체 size가 10, batch_size=3이라면 sample엔 3/3/3/1개 들어감
drop_last
- batch_size로 나누다가 마지막 batch의 길이가 달라지면 달라진 그건 drop해버림
collate_fn
- map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능입니다.
- zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용
transform
데이터를 조건에 맞게 변형시킴(주어진 데이터들의 크기가 같지 않을 경우 동일하게 만든다던지)
참고: https://pytorch.org/vision/stable/transforms.html#
여러 개의 transform을 동시에 적용하는 방법
transforms.compose이용 +im = transform(im)으로 적용
선택과제1) Transfer Learning & Hyper-parameter Tuning
Transfer Learning
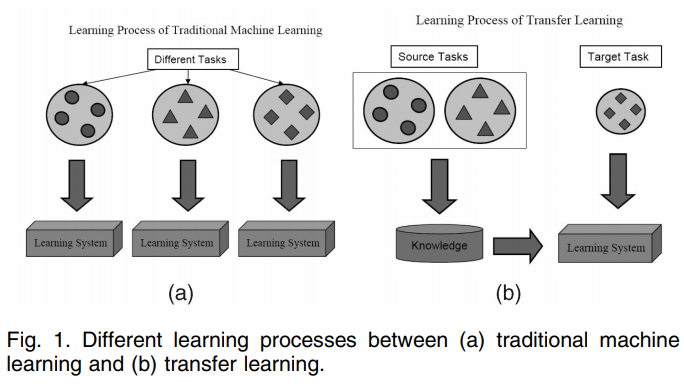
- 보통은 pre-trained model*을 사용하는 것을 의미
높은 정확도를 비교적 짧은 시간 내에 달성할 수 있다
* pre-trained model: 내가 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어있는 모델
