
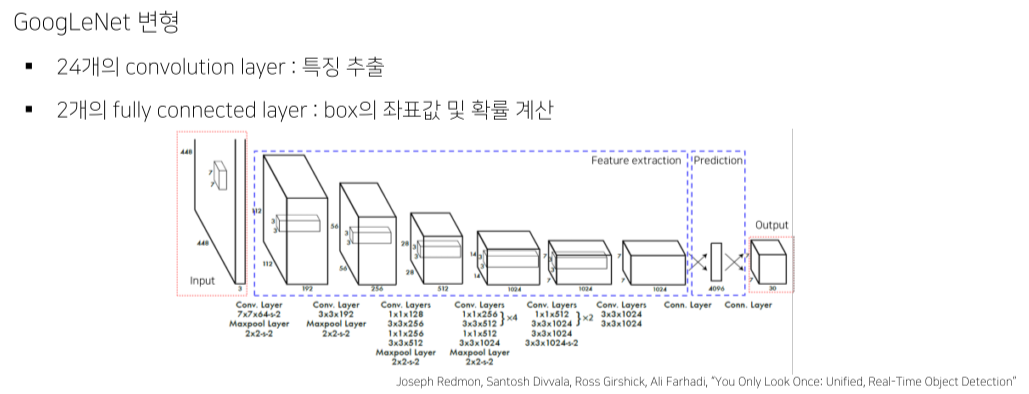
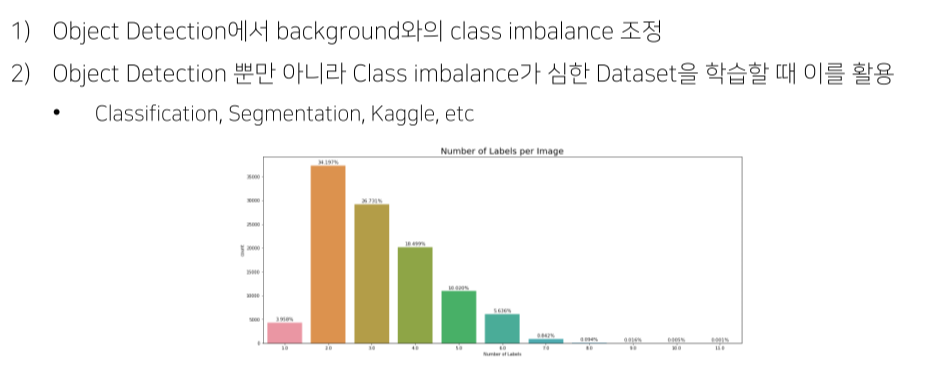
1강) Object Detection Overview
개요

- Object detection: classification + bounding box
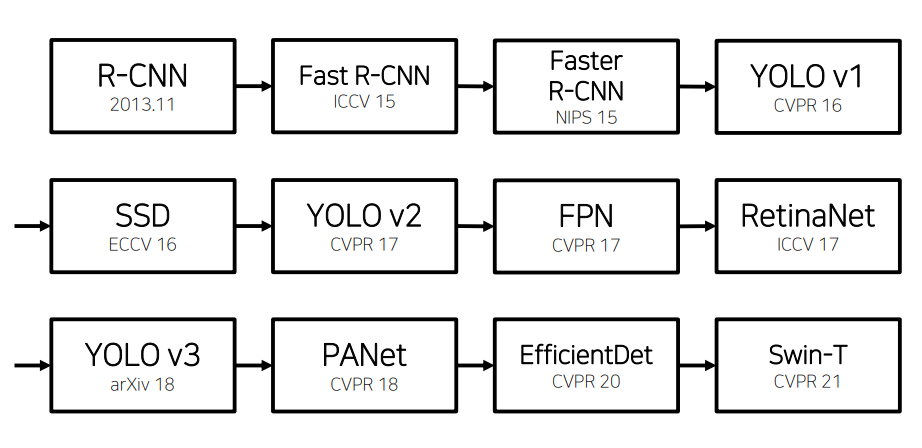
- Object detection model의 역사
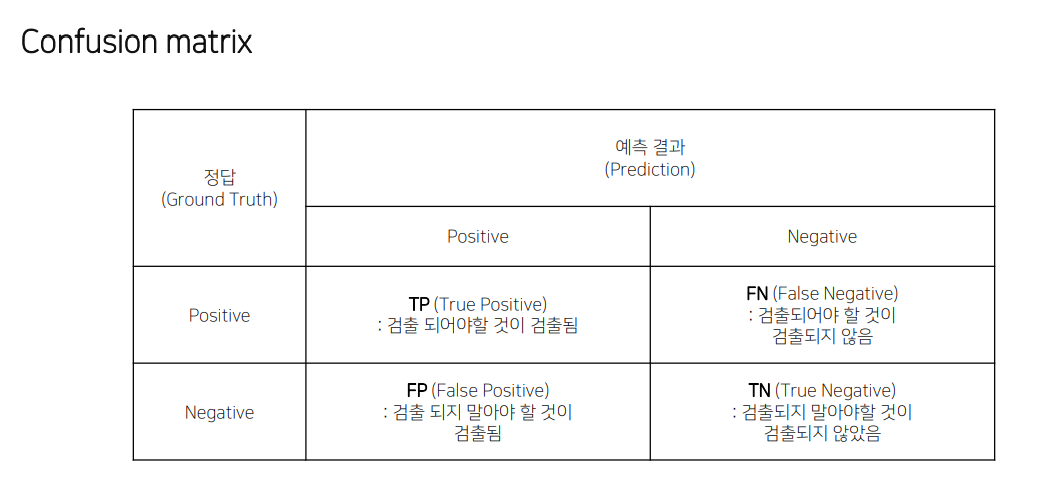
Evaluation
mAP
mean average precision, 성능 측정
각 AP의 평균
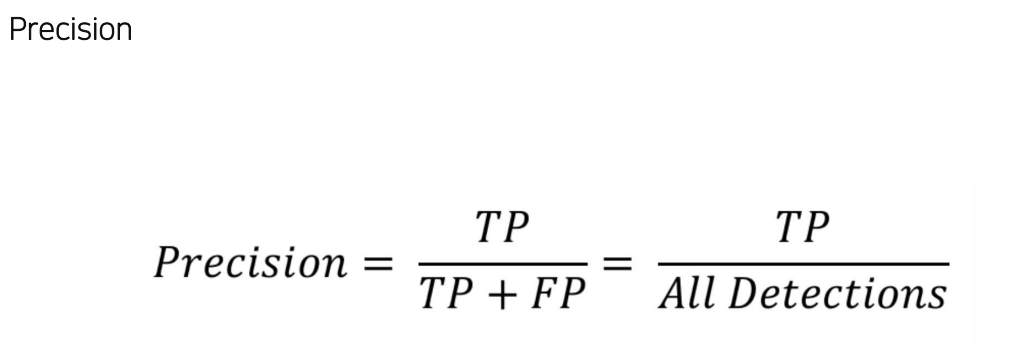
- 모든 positive라고 예측한 것 들 중에서 맞은 비율

- 정답을 맞춘 비율

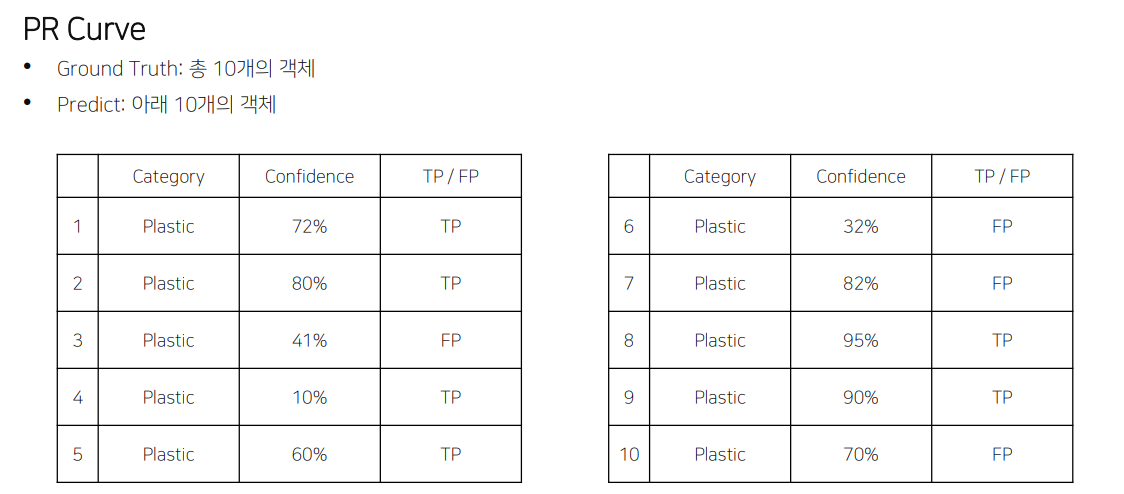
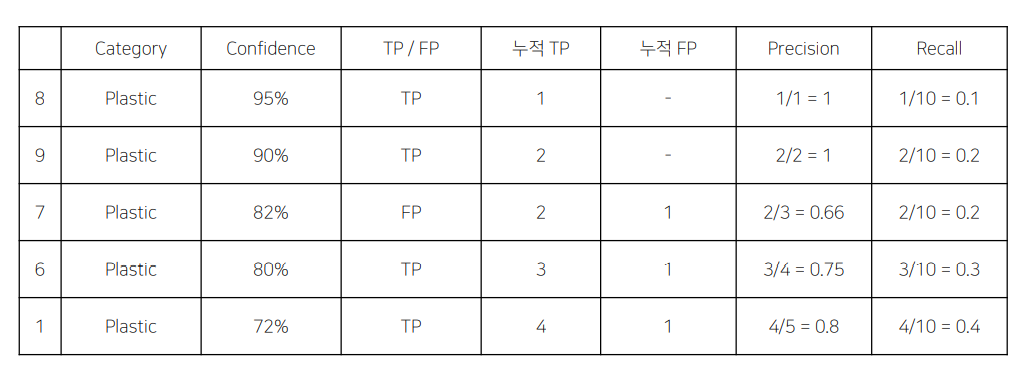
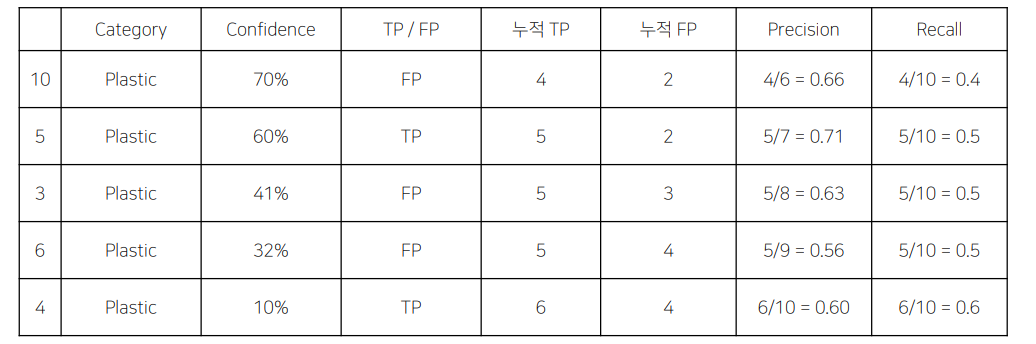
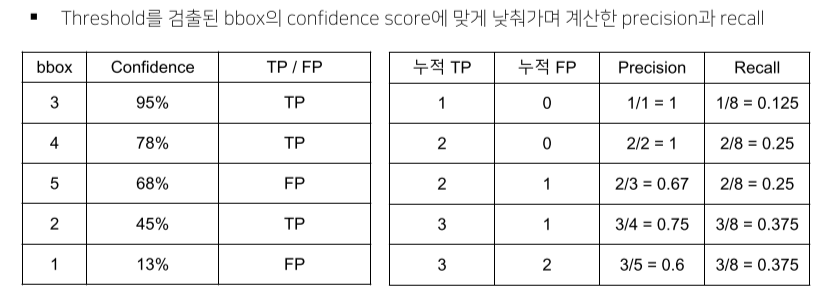
- Confidence score를 기준으로 내림차순 정렬 후 누적 TP, NP를 계산
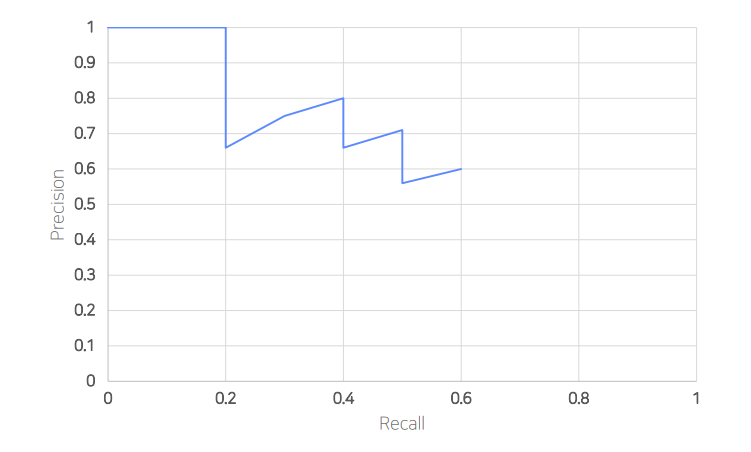
- 이후 Precision-Recall graph를 그림
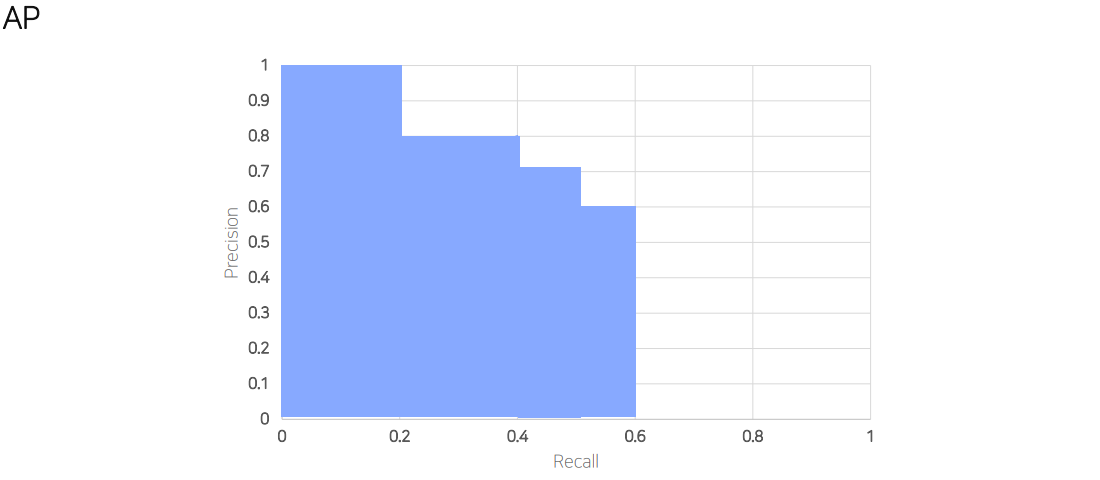
- 그래프의 아래 면적 = AP
- 0~1 사이의 값을 가짐

- 모든 class의 AP의 평균
-
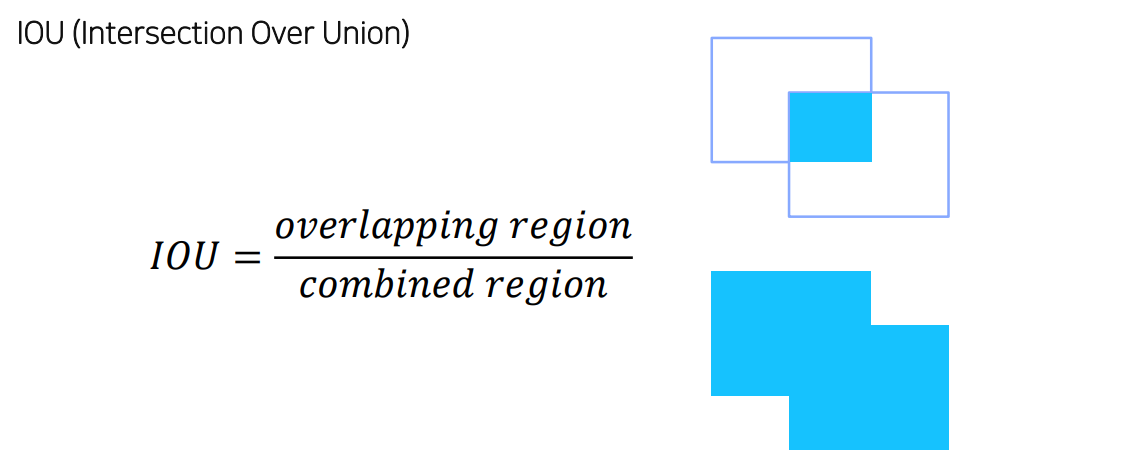
Bbox의 정확도를 판별하기 위한 기준
-
GT, estimated output의 겹친 넓이 / 전체 넓이
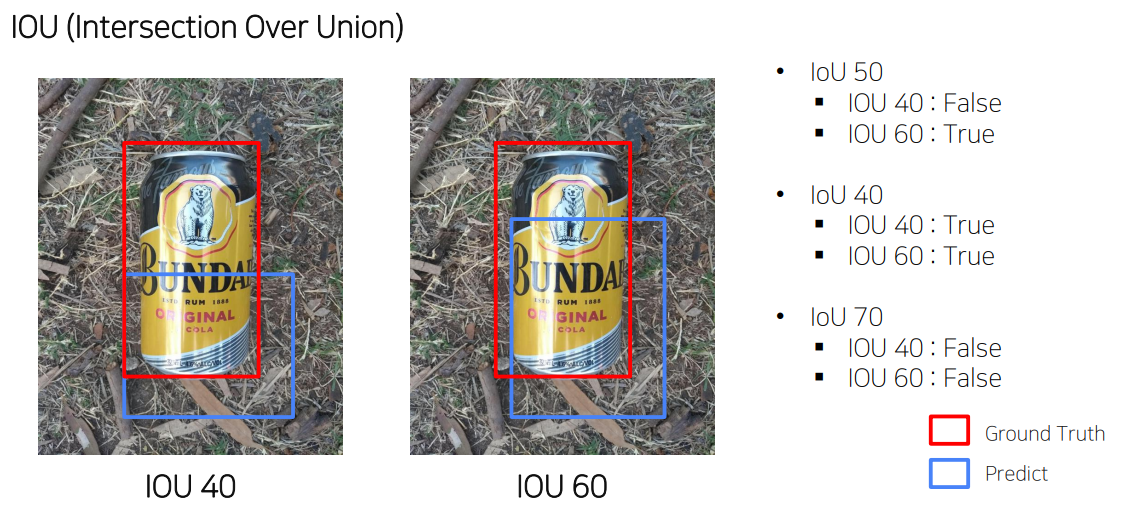
- IOU 기준에 따라 True, False가 결정됨
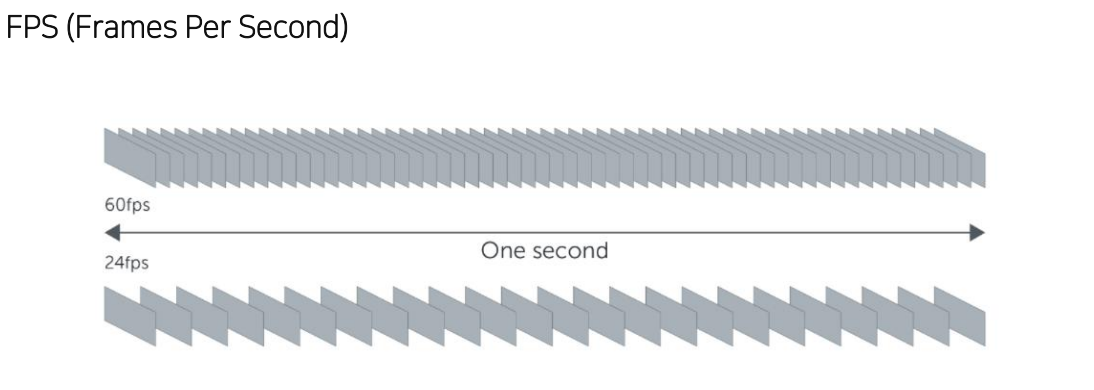
FPS
속도 측정
클수록 빠른 모델
FLOPs
연산량의 횟수
작을수록 빠른 모델
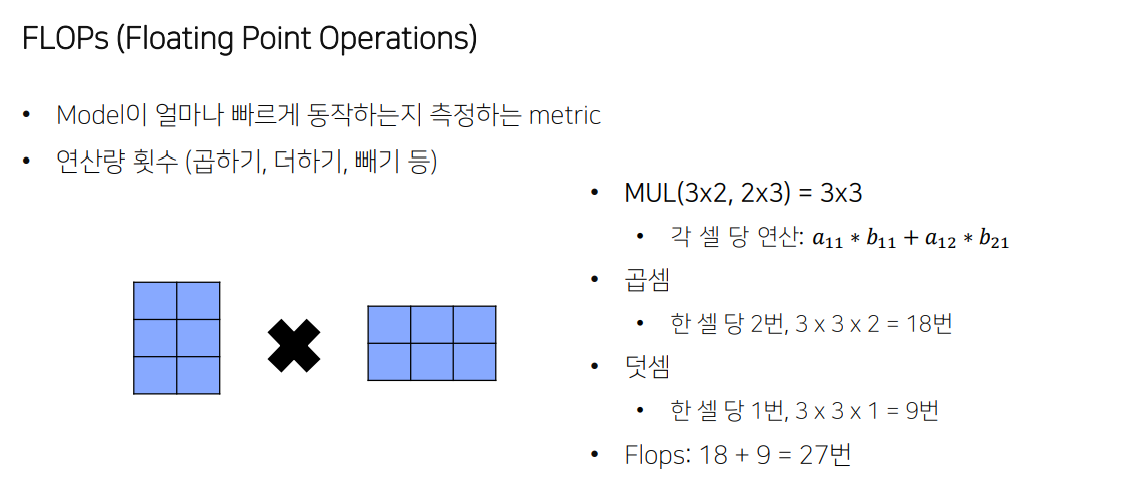
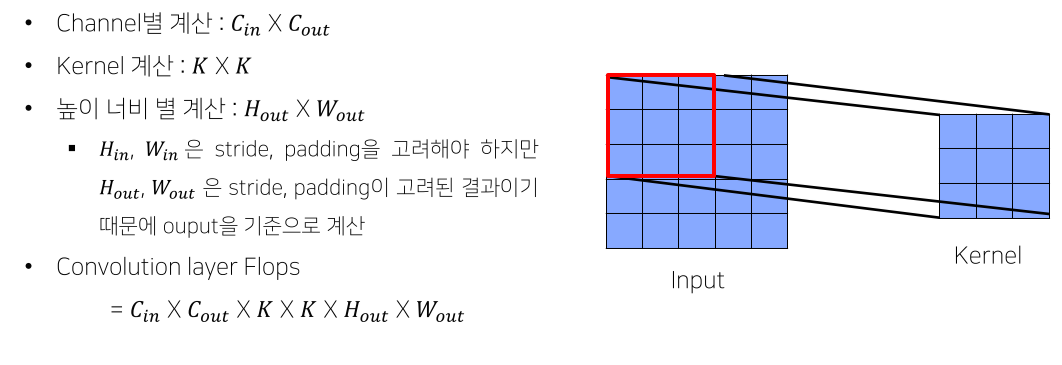
- 덧셈은 보통 FLOPs에선 생략하는 편
라이브러리


- 많은 연구가 MMDetection 기반



커리큘럼


2강) 2 Stage Detectors

- 사람의 인식 방법을 본따서
- 객체의 위치를 특정
- 해당 객체가 무엇인지를 예측
- 2가지 단계로 나뉘기 때문에 2-stage detector라고 부름
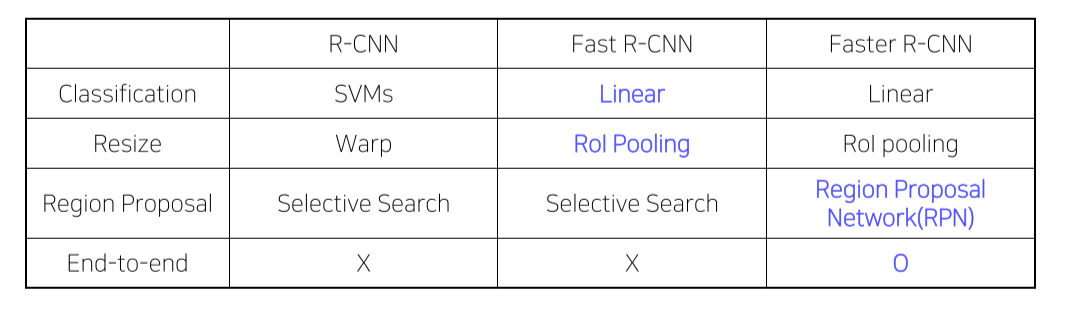
R-CNN
Overview
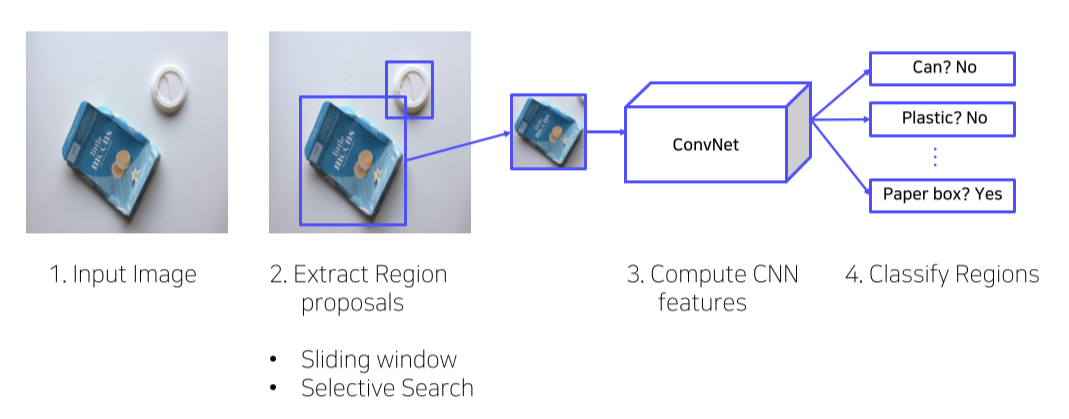
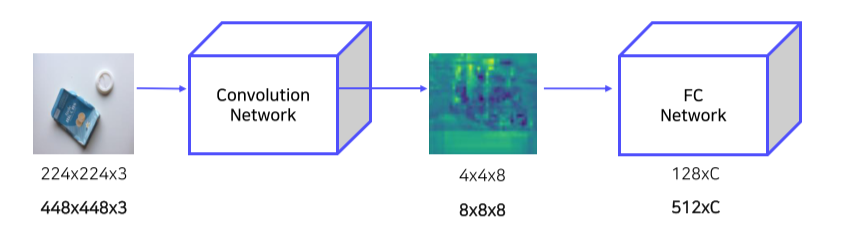
- Bbox를 찾아 고정된 size로 mapping한 후 CNN의 input으로 넣어 semantic feature vector(map)을 얻음
이를 이용해 classify

- 단순히 window slide하는 것은 너무 많은 시간을 소모하기 때문에(대부분은 배경이라 무쓸모) 더이상 사용하지 않음

-
Image의 texture, color 등을 이용해 영역을 나누는
selective search를 이용 -
Selective Search에서사용하는 segmentation 방법 https://blog.naver.com/laonple/220925179894
-
Greedy Algorith 사용한영역병합방법 https://blog.naver.com/laonple/220930954658
Pipeline
-
입력 이미지 받기
-
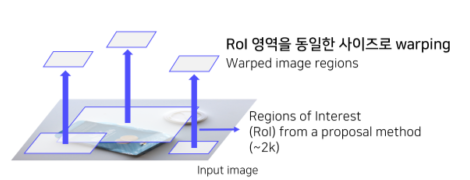
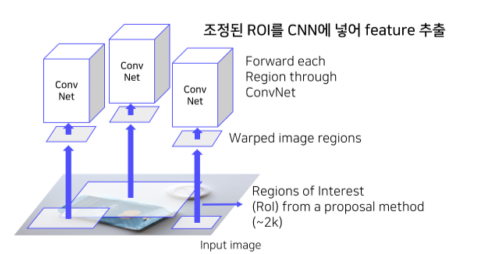
Selective Search를통해약 2000개의 RoI(Region of Interest)를추출
- RoI(Region of Interest)의 크기를 조절해 모두 동일한 사이즈로 변형
- CNN의 마지막인 FC layer의 입력 사이즈가 고정이므로 이 과정 수행
(Input image size에 따라 feature map size가 달라지고, fc layer size는 고정이기 때문에 CNN에 넣기 전에 size 조절을 해주는 것)
- CNN의 마지막인 FC layer의 입력 사이즈가 고정이므로 이 과정 수행
4) RoI를 CNN에넣어, feature를 추출
- 각 region마다 4096-dim feature vector 추출 (2000x4096)
- Pretrained AlexNet 구조활용
- AlexNet 마지막에 FC layer 추가
- 필요에따라 Finetuing 진행
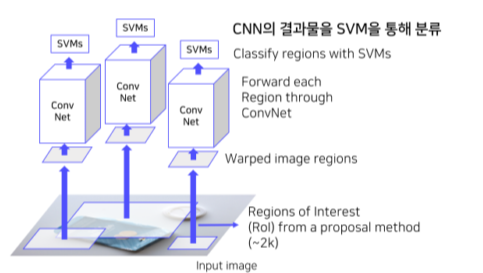
5-1) CNN을 통해 나온 feature를 SVM에 넣어 분류 진행
- Input
- 2000 x 4096 features
- Output
- Class (C+1) + Confidence scores
- 클래스개수(C개) + 배경여부(1개)
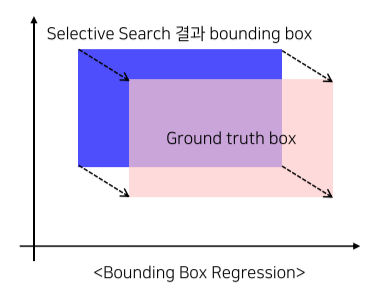
5-2) CNN을 통해 나온 feature를 regression을 통해 bounding box를 예측
Training
- AlexNet
- Domain specific finetuning
- Dataset 구성
- IoU > 0.5: positive samples
- IoU < 0.5: negative samples
- Positive samples 32, negative samples 96
- Linear SVM
- Dataset 구성
- Ground truth: positive samples
- IoU < 0.3: negative samples
- Positive samples 32, negative samples 96
- Dataset 구성
- Hard negative mining
- Hard negative: False positive
- 배경으로 식별하기 어려운 샘플들을 강제로 다음 배치의 negative sample로 mining 하는 방법
- Bbox regressor
- Dataset 구성
- IoU > 0.6: positive samples
x, y, w, h를 얼마나 바꿀건지를 학습
Negative sample은 bbox가 없어서 학습x
- IoU > 0.6: positive samples
- Dataset 구성
- Loss function
- MSE Loss
Shortcomings
1) 2000개의 Region을 각각 CNN 통과
--> 너무 많은 연산
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로학습
--> End-to-End X
SPPNet
R-CNN의 한계점
-
Convolution Network의 입력 이미지가 고정되어 있음
이미지를 고정된 크기로 자르거나(crop) 비율을 조정(warp)해야함 -
RoI(Region of Interest)마다 CNN통과
하나의 이미지에 대해서 2000번 CNN을 통과해야함 → 시간이 오래 걸림
Overall architecture
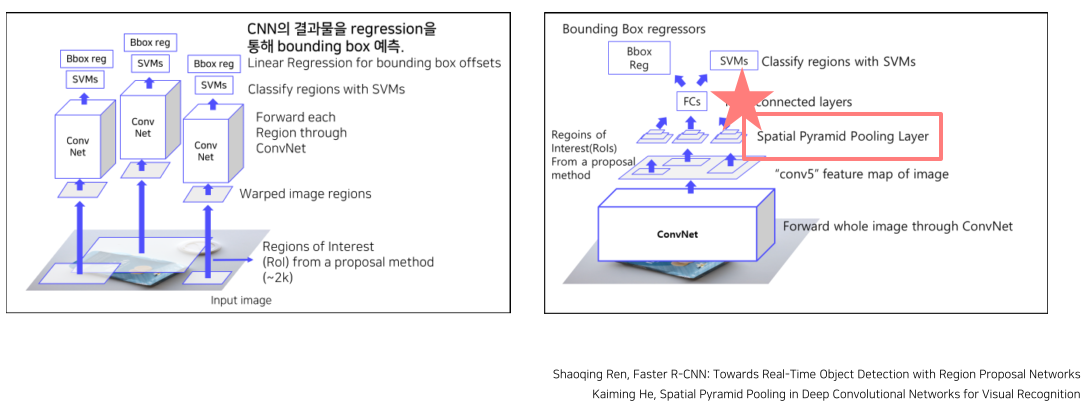
-
SPPNet은 1개의 CNN을 통과해 feature map으로부터 region을 뽑아냄
-
Region은 warp(resize)하지 않고 spp로 고정된 size의 feature vector로 resize
SPP, spatial pyramid pooling
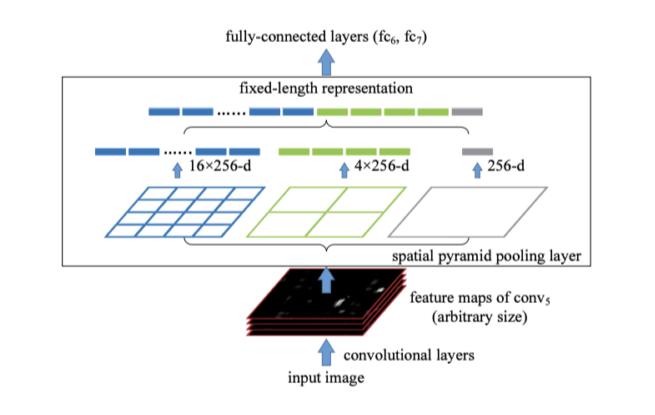
- 전체 image를 output size만큼 bin을 만들어 global pooling을 진행
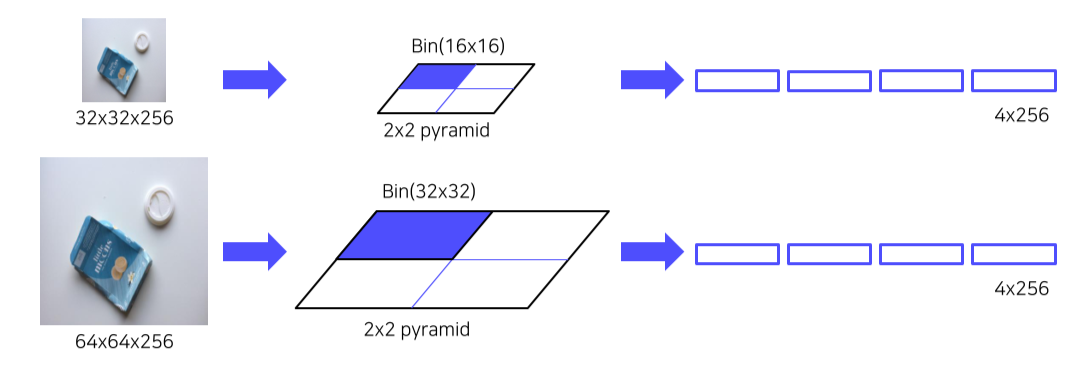
- ROI size가 얼마든 binning을 해서 고정된 size의 feature vector를 출력할 수 있음
Shortcomings
1) 2000개의 Region을 각각 CNN 통과
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로학습
4) End-to-End X
Fast R-CNN
Pipeline
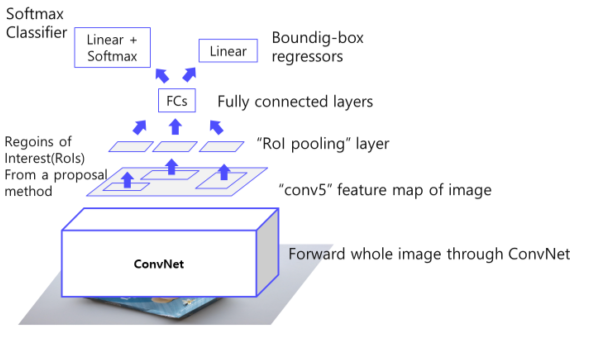
- 이미지를 CNN에 넣어 feature 추출 (CNN을 한번만 사용)
VGG16 사용

- RoI Projection을통해 feature map 상에서 RoI를 계산
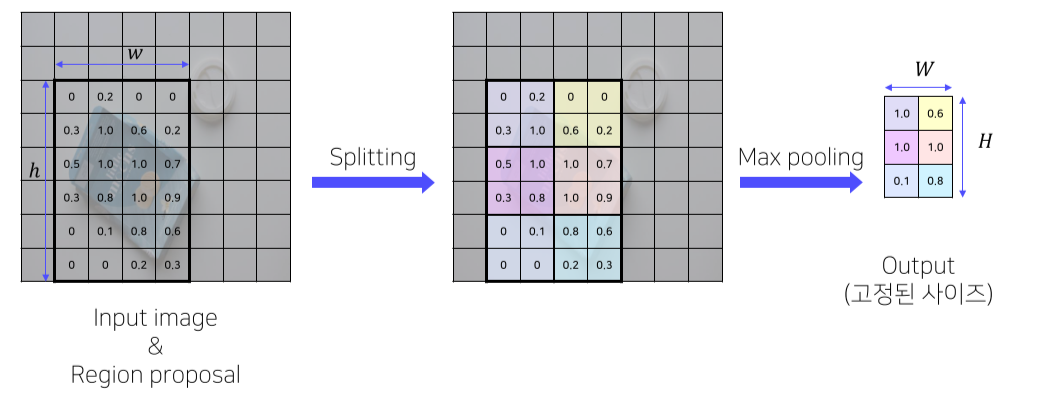
-
RoI Pooling을 통해 일정한 크기의 feature가 추출
• 고정된 vector 얻기위한 과정
• SPP 사용
• pyramid level: 1
• Target grid size: 7x7 -
Fully connected layer 이후, Softmax Classifier과 Bouding Box Regressor
• 클래스개수: C+1개
• 클래스 (C개) + 배경 (1개)
Training
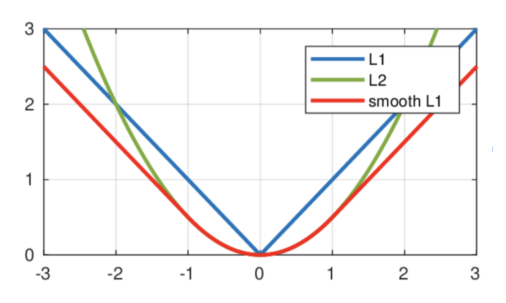
- multi task loss 사용
- (classification loss + bounding box regression)
- Loss function
- Classification : Cross entropy
- BB regressor : Smooth L1
(L1, L2보다 outlier에 덜 민감하기 때문에!)
- Dataset 구성
- IoU > 0.5: positive samples
- 0.1 < IoU < 0.5: negative samples
- Positive samples 25%, negative samples 75%
- Hierarchical sampling
- R-CNN의 경우 이미지에 존재하는 RoI를 전부 저장해 사용
- 한 배치에 서로 다른 이미지의 RoI가 포함됨
- Fast R-CNN의 경우 한 배치에 한 이미지의 RoI만을 포함
- 한 배치 안에서 연산과 메모리를 공유할 수 있음
Shortcomings
1) 2000개의 Region을 각각 CNN 통과
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로학습
4) End-to-End X
--> 거의 end-to-end인데 selective search는 CPU 상에서 돌아가기 때문에 학습 가능한 알고리즘이 아님
Faster R-CNN
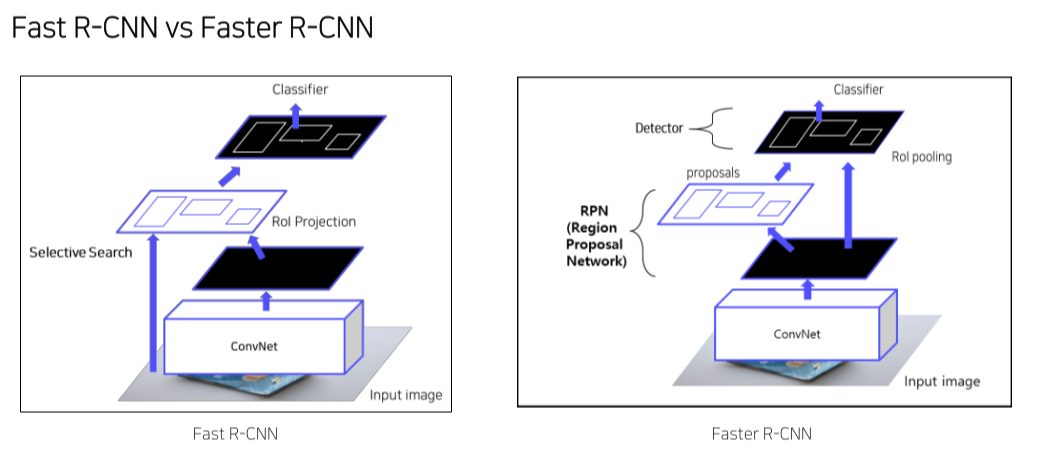
- Selective search를 RPN으로 대체해 end-to-end로 만듬
Pipeline
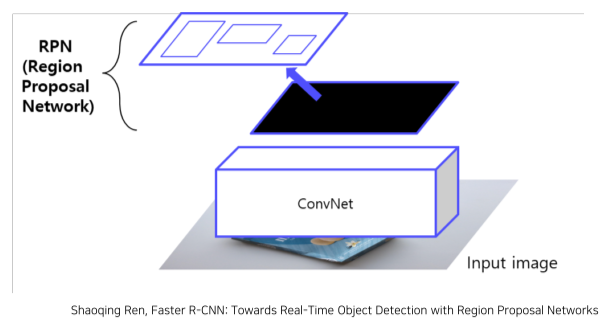
- 이미지를 CNN에 넣어 feature maps 추출 (CNN을 한번만 사용)
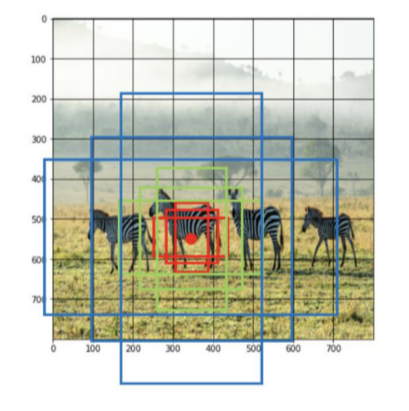
- RPN을 통해 RoI 계산
• 기존의 selective search 대체
• Anchor box 개념 사용
• 각 cell마다 다양한 size, scale을 가진 k개의 anchor box를 미리 설정
• RPN은 anchor box가 객체를 포함하고 있는지 아닌지를 판단하고, 포함하고 있다면 더 정확하게 resize, 위치 조정 등을 함
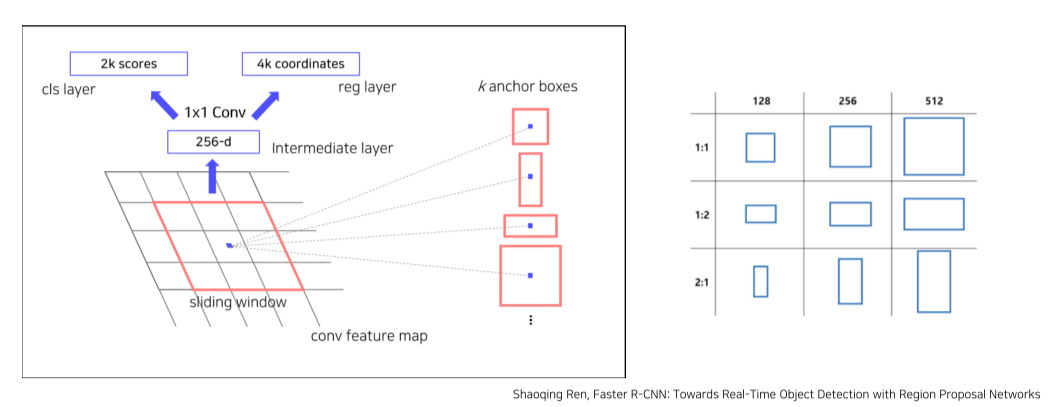
- anchor box가 k개
--> object / bg를 판별하는 cls layer == parameter가 2k개
--> x, y, w, h를 판별하는 reg layer == parameter가 4k개
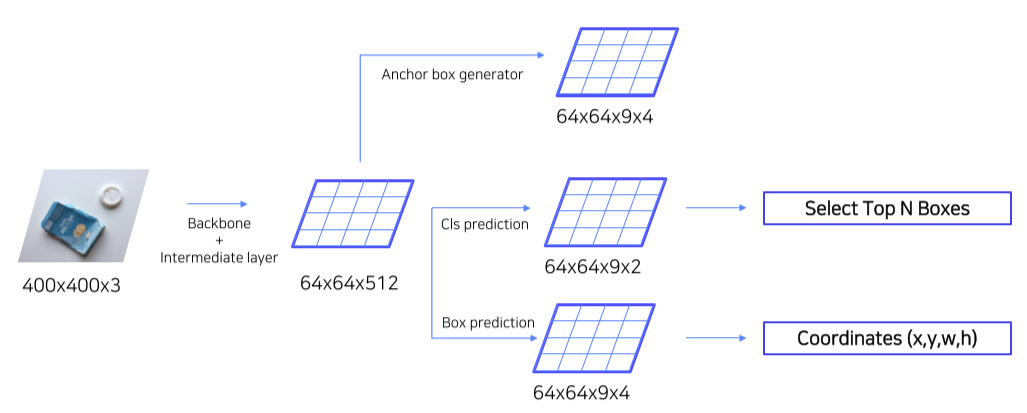
- Input image에 대한 feature map이 64x64x512로 나왔을 경우,
- Anchor box generator: 각각 64x64 pixel에 대해 9개의 anchor box를 만들고, 각각 anchor box는 x, y, w, h를 가짐
- Cls prediction: 각 9개의 anchor box가 객체를 포함하는지/안 하는지
- Box prediction: 각 anchor box의 x, y, w, h를 미세조정
NMS
- 유사한 RPN Proposals 제거하기 위해 사용
- Class score를 기준으로 proposals 분류
- IoU가 0.7 이상인 proposals 영역들은 중복된 영역으로 판단한뒤 제거
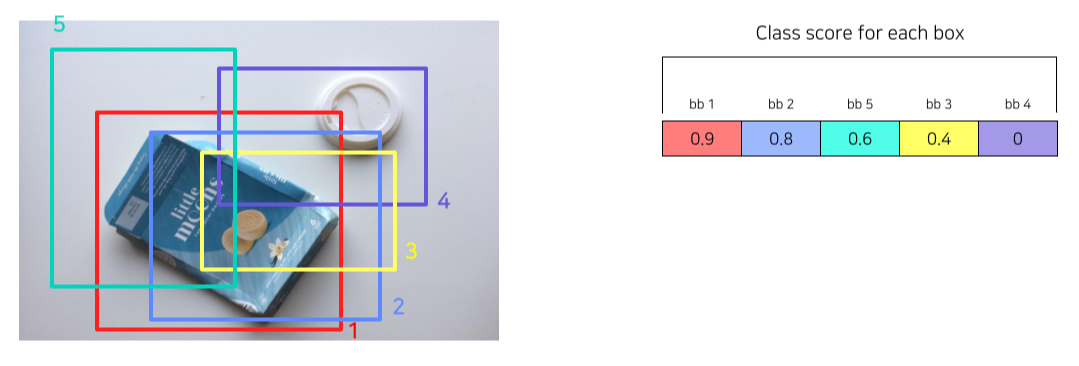
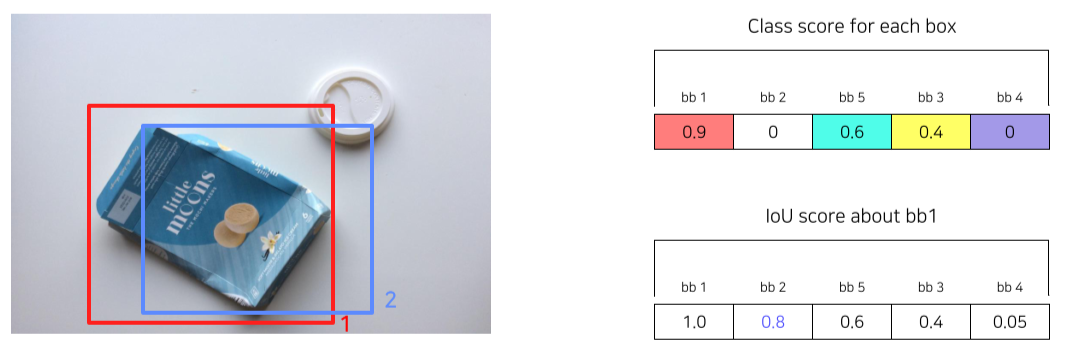
- class score가 제일 높은 bb1와 IOU가 0.7 이상이므로 제거
Training
Region Proposal Network (RPN)
- RPN 단계에서 classification과 regressor 학습을 위해 앵커박스를 positive/negative samples 구분
- 데이터셋구성 • IoU > 0.7 or highest IoU with GT: positive samples
- IoU < 0.3: negative samples
- Otherwise : 학습 데이터로사용 X
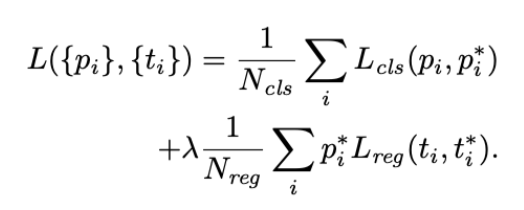
- Loss 함수
- : 번째 anchor box가 객체를 포함하고 있는지(1) 아닌지(0)에 대한 지표
- Regression은 객체를 포함하고 있을 때에만 학습
Region proposal 이후
- Fast RCNN 학습을 위해 positive/negative samples로 구분
- 데이터셋구성
- IoU > 0.5: positive samples → 32개
- IoU < 0.5: negative samples → 96개
- 128개의 samples로 mini-bath 구성
- Loss 함수
- Fast RCNN과동일
- RPN과 Fast RCNN 학습을위해 4 steps alternative training 활용
- Step 1) Imagenet pretrained backbone load + RPN 학습
- Step 2) Imagenet pretrained backbone load + RPN from step 1 + Fast RCNN 학습
- Step 3) Step 2 finetuned backbone load & freeze + RPN 학습
- Step 4) Step 2 finetuned backbone load & freeze + RPN from step 3 + Fast RCNN 학습
- 학습과정이 매우 복잡해서, 최근에는 Approximate Joint Training 활용
Result
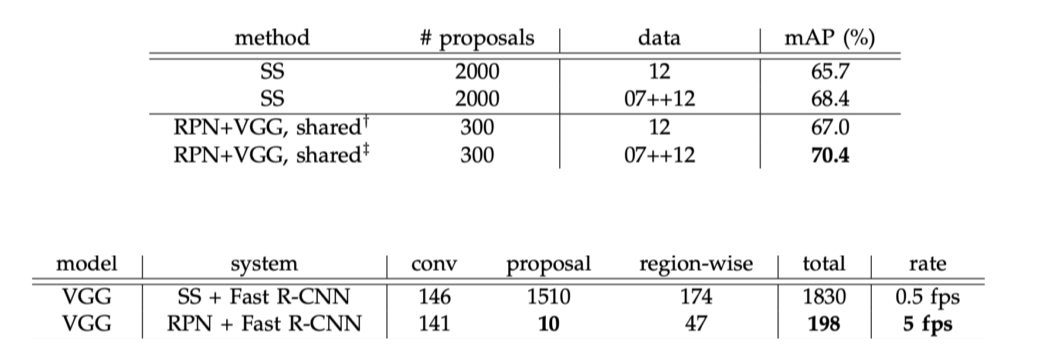
Shortcomings
1) 2000개의 Region을 각각 CNN 통과
2) 강제 Warping, 성능 하락 가능성
3) CNN, SVM classifier, bounding box regressor, 따로학습
4) End-to-End X
하지만 2 stage라서 real time으로 사용하기엔 무리가 있음
Summary
Reference
1) Hoya012, https://hoya012.github.io/
2) 갈아먹는 Object Detection, https://yeomko.tistory.com/13
3) Deepsystems, https://deepsystems.ai/reviews
4) https://herbwood.tistory.com
5) https://towardsdatascience.com/understanding-region-of-interest-part-1-roi-pooling-e4f5dd65bb44
6) https://ganghee-lee.tistory.com/37
7) https://blog.naver.com/laonple
8) https://arxiv.org/pdf/1311.2524.pdf (Rich feature hierarchies for accurate object detection and semantic segmentation)
9) https://arxiv.org/pdf/1406.4729.pdf (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
9) https://arxiv.org/pdf/1504.08083.pdf (Fast R-CNN)
10) https://arxiv.org/pdf/1506.01497.pdf (Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
3강) Object Detection Library
통합된 라이브러리 부재
실무/캐글에서는 MMDetection, Detectron2를 주로 사용
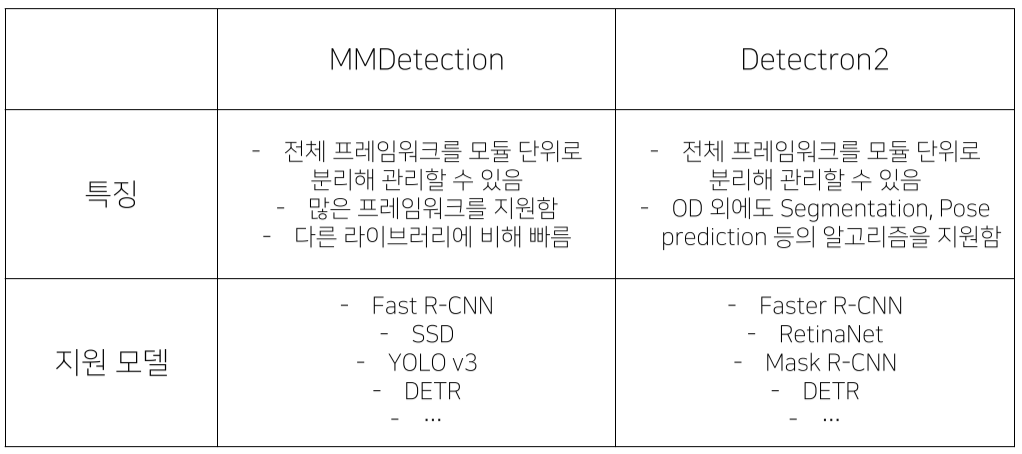
MMDetection
PyTorch 기반의 Object Detection 오픈소스 라이브러리
Custom하기 위해서는 라이브러리에 대한 완벽한 이해가 필요해 난이도가 있는편

Pipeline
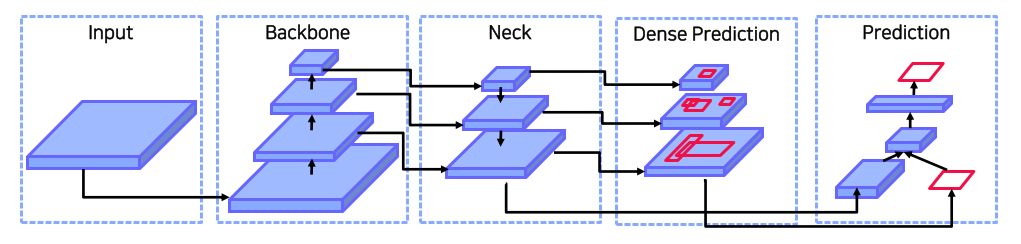
-
2 stage detector라서 cls / bbox head가 따로 있음
-
Neck: feature map과 비슷한 역할
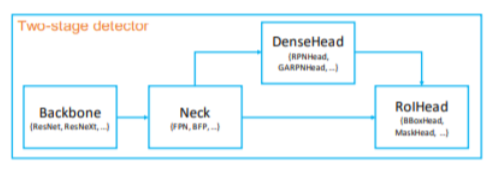
- 2 Stage 모델은 크게 Backbone / Neck / DenseHead / RoIHead 모듈로 나눌 수 있음
- Backbone: 입력 이미지를 feature map으로 변형
- Neck: backbone과 head를 연결, feature map을 재구성 (ex. FPN)
- DenseHead: feature map의 dense location을 수행하는 부분
- RoIHead: RoI feature를 입력으로 받아 box 분류,
좌표 회귀 등을 예측하는 부분
-
각각의 모듈 단위로 커스터마이징
-
이러한 시스템은 config 파일을 이용해 통제됨
Config File
구조
- configs를 통해 데이터셋부터 모델, scheduler, optimizer 정의 가능
- 특히, configs에는 다양한 object detection 모델들의 config 파일들이 정의돼 있음
- 그중, configs/base/ 폴더에 가장 기본이되는 config 파일이 존재
- dataset, model, schedule, default_runtime 4가지 기본 구성 요소 존재
- 각각의 base/ 폴더에는 여러 버전의 config들이 담겨있음
- Dataset – COCO, VOC, Cityscape 등
- Model – faster_rcnn, retinanet, rpn 등
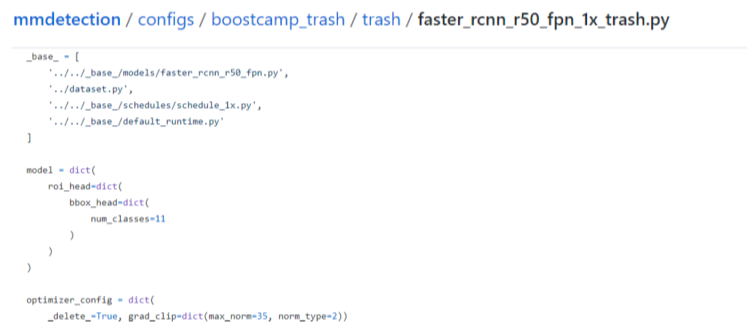
- 틀이 갖춰진 config를 상속받고, 필요한 부분만 수정해 사용
Dataset
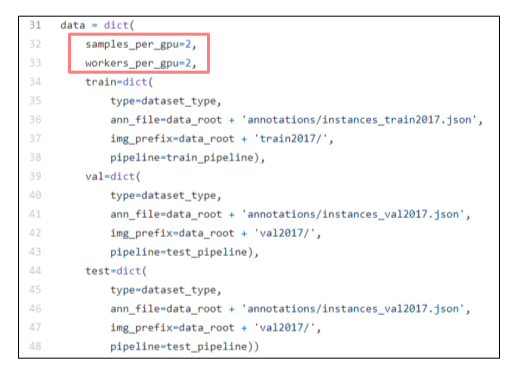
- samples_per_gpu: GPU 1개 당 올라갈 image sample의 갯수
- workers_per_gpu: GPU 1개 당 CPU의 갯수
- train / val / test
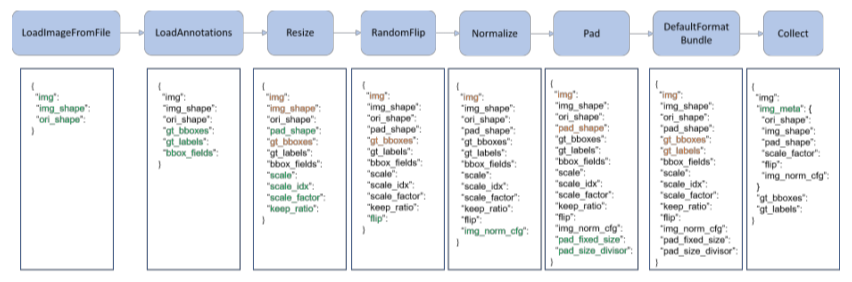
- data pipeline
Model
2 stage model hyper-parameter
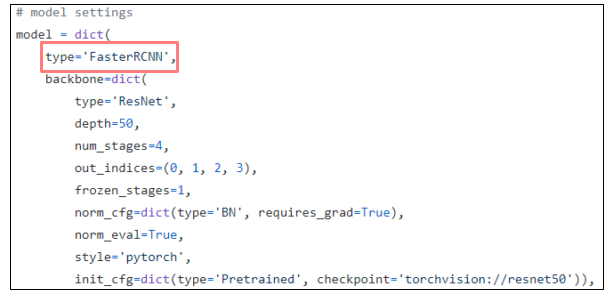
-
type: 모델 유형
Ex. FasterRCNN, RetinaNet… -
backbone: 인풋 이미지를 feature map으로 변형해주는 네트워크
Ex. ResNet, ResNext, HRNet… -
neck: Backbone과 head를 연결, Feature map을 재구성
Ex. FPN, NAS_FPN, PAFPN, …

- rpn_head: Region Proposal Network
Ex. RPNHead, Anchor_Free_Head, …- Anchor_generator
- Bbox_coder
- Loss_cls
- Loss_bbox
-
roi_head: Region of Interest
Ex. StandardRoIHead, CascadeRoIHead, … -
bbox_head
-
train_cfg
-
test_cfg
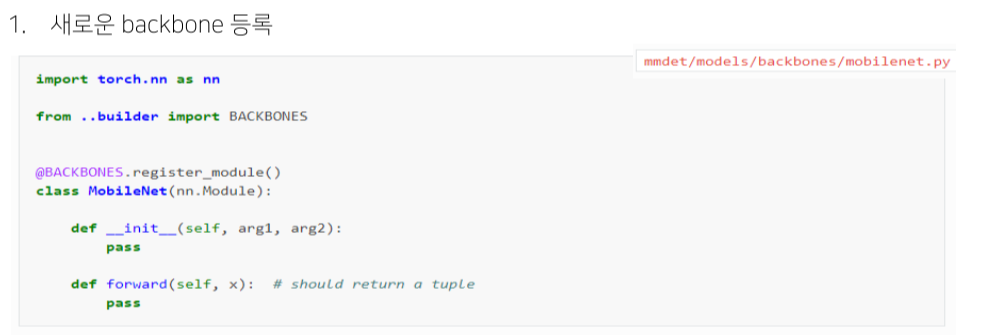
Custom model 등록

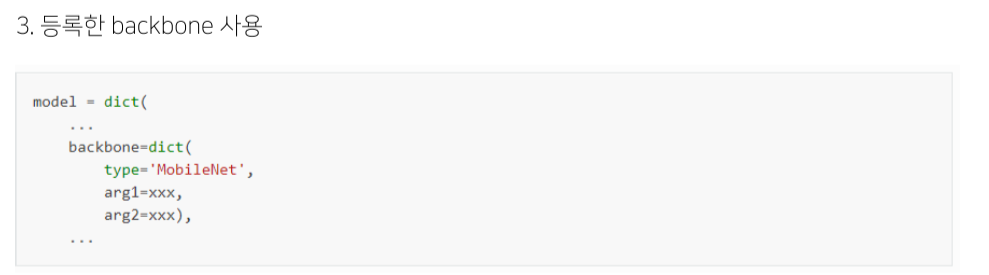
Runtime setting
Scheduler, lr, weight save 등 train할 때 필요한 부분을 세팅
-
optimizer
Ex. SGD, Adam, … -
Training schedules
- learning rate
- runner: scheduler 동작 조건 설정
Detectron2
Facebook AI Research의 Pytorch 기반 라이브러리
Object Detection 외에도 Segmentation, Pose prediction 등 알고리즘도 제공

Pipeline
Setup Config -> Setup Trainer -> Start Training
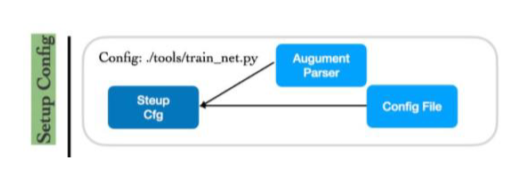
- Setup Config
- Config를 load하고 필요에 따라 argparser로 수정
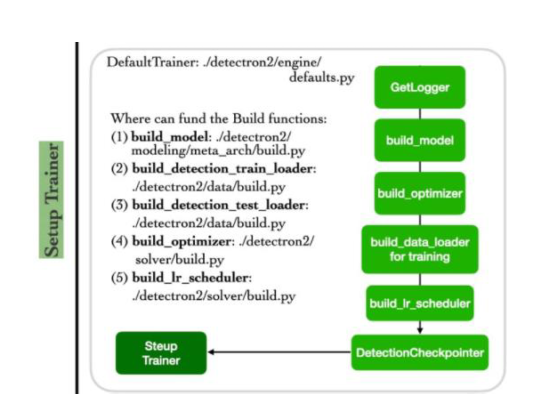
- Setup Trainer
- build_model
- build_detection_train/test_loader
- build_optimizer
- build_lr_scheduler
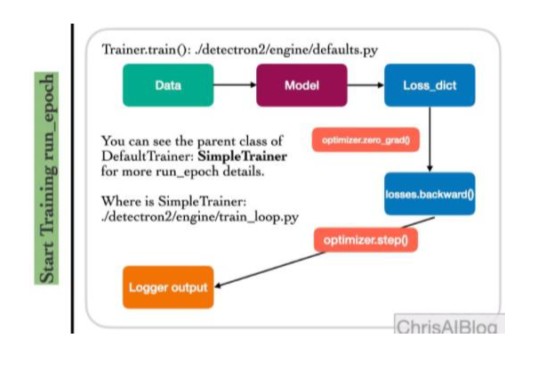
- Start Training
구조
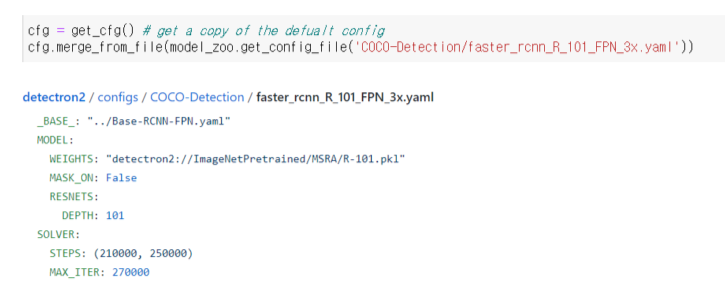
- MMDetection과 유사하게 config 파일을 수정, 이를 바탕으로 파이프라인을 build하고 학습
- 틀이 갖춰진 기본 config를 상속받고, 필요한 부분만 수정해 사용
- 디폴트 컨피그를 불러온 후, 기본적인 내용이 채워진 yaml 형식의 config 파일로 채움
Dataset
Config
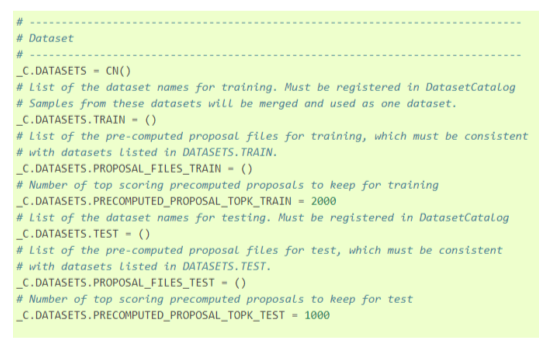
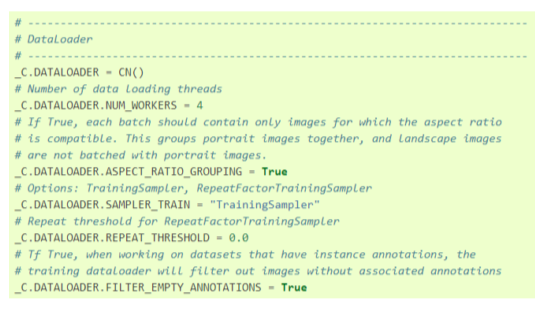
- 데이터셋, 데이터로더와 관련된 config
- TRAIN, TEST에 각각 등록한 train 데이터셋과 test
데이터셋의 이름을 입력
Dataset 등록

- 커스텀 데이터셋을 사용하고자 할 때는 데이터셋을 등록
- (옵션) 전체 데이터셋이 공유하는 정보 (ex. class명, 파일디렉토리등)을 메타 데이터로 등록할 수 있음

- config 파일에 train 데이터셋과 test(val) 데이터셋을 명시해 사용할 수 있도록 함
Data augmentation

- augmentation 정보가 담긴 mapper 정의
Model
- Config: BACKBONE, FPN, ANCHOR_GENERATOR, RPN, ROI_HEADS, ROI_BOX_HEAD
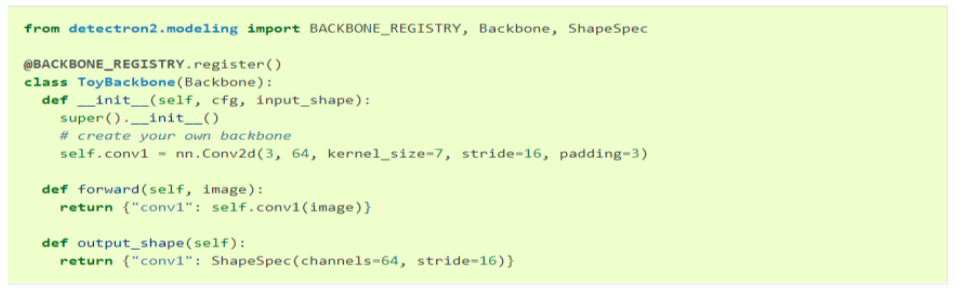

- Custom backbone 추가해 사용 가능
Solver
- MMDetection의 runtime과 같은 역할
- LR_SCHEDULER, WEIGHT_DECAY, CLIP_GRADIENTS
Reference
1) “MMDetection : Open MMLab Detection Toolbox and Benchmark”
2) https://github.com/open-mmlab/mmdetection
3) https://christineai.blog/category/computer-vision/object-detection
4) https://github.com/facebookresearch/detectron2
5) https://detectron2.readthedocs.io/en/latest/
6) Alexey Bochkovskiy, Chien-Yao Wang, Hong-yuan Mark Liao, YOLOv4: Optimal Speed and Accuracy of Object Detection
4강) Neck
2 stage model 에서 backbone의 마지막 feature map 뿐만 아니라 중간 feature map도 사용하는 방법
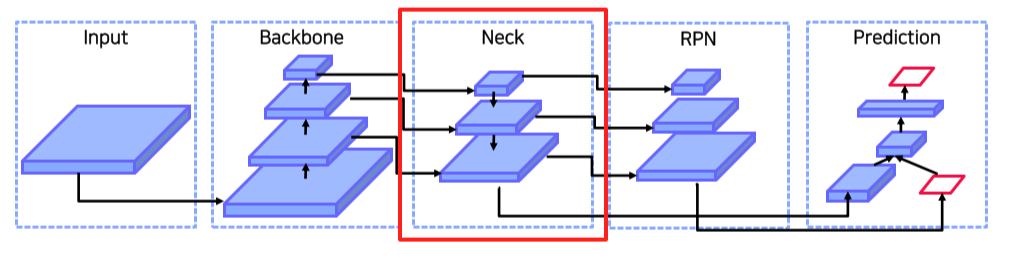

- 다양한 크기의 feature map을 사용해 여러 크기의 물체를 탐지할 수 있음
- 작은 객체는 (backbone을 별로 통과하지 않은)low level feature map에서, 큰 객체는 high level feature map에서 검출
- backbone을 별로 통과하지 않으면 각 node에서 다루는 kernel size(?)가 작기 때문에 작은 공간 밖에 보지 못함
- low level은 semantic info가 부족한 반면 local info는 많고,
high level은 local info는 없는 반면 semantic info는 많아서 둘을 섞음
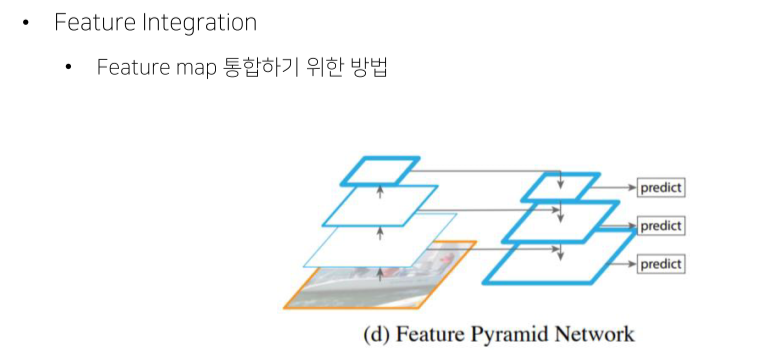
FPN, Feature Pyramid Network

-
이전까지는 input image를 크기별로 조절해서 사용하거나,

-
feature map을 그대로 사용하거나,

- 중간중간의 feature map을 그대로 사용했었음
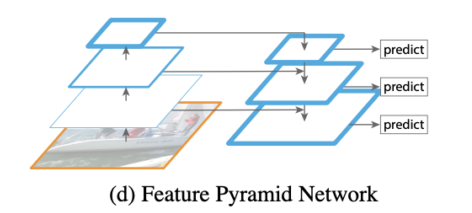
- FPN은 high level에서 low level로 semantic 정보를 전달하기 위해 top-down path way를 추가
- Low level = early stage = bottom
- High level = late stage = top
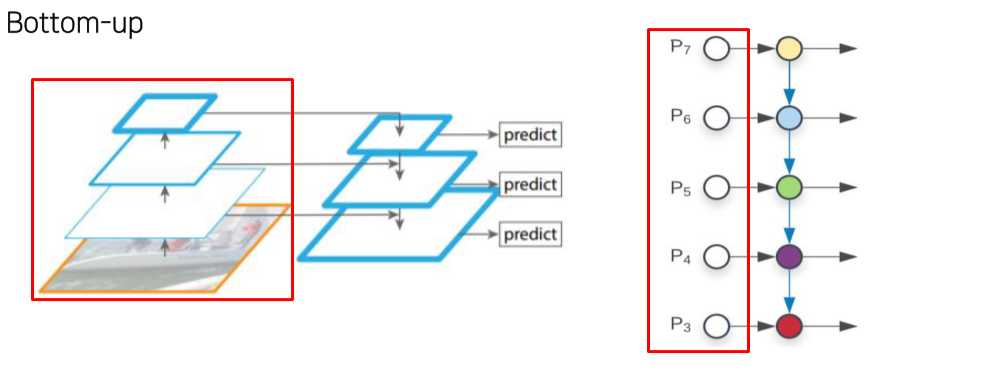
- 일반적인 NN과 같음
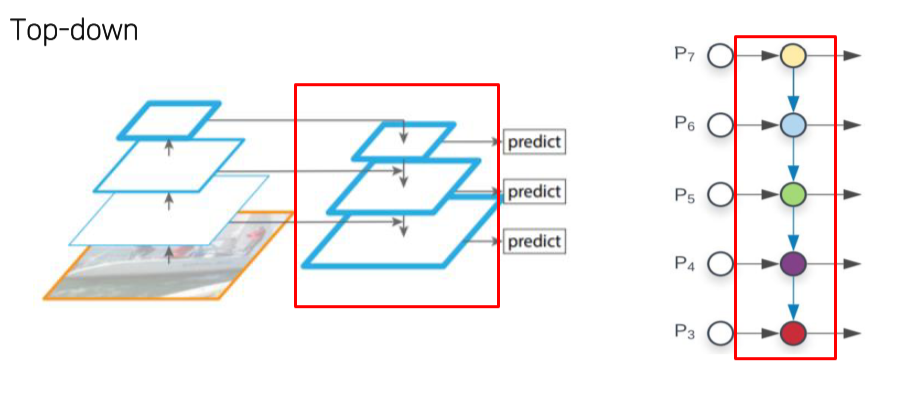
- High level feature를 low level로 전달
Lateral Connections
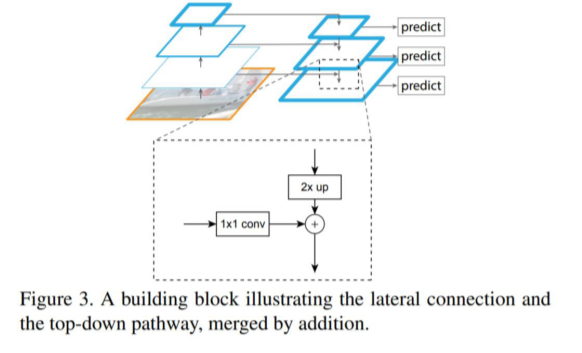
- Top-down에서 온 feature map은 2x를, bottom-up에서 온 feature map은 1x1 conv를 해서 전달
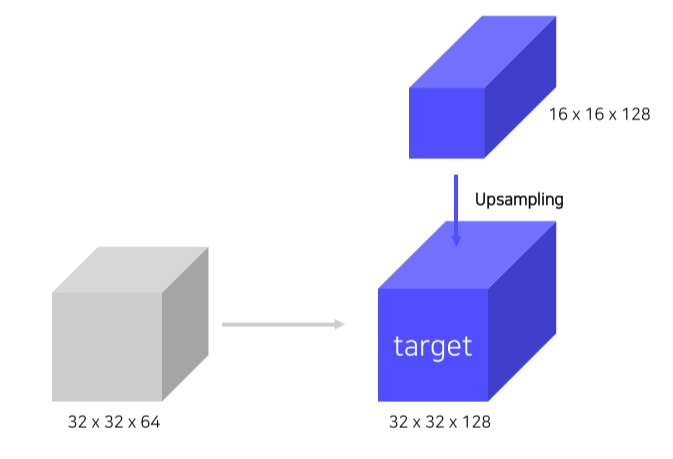
- Top-down에서 온 feature map은 2x upsampling
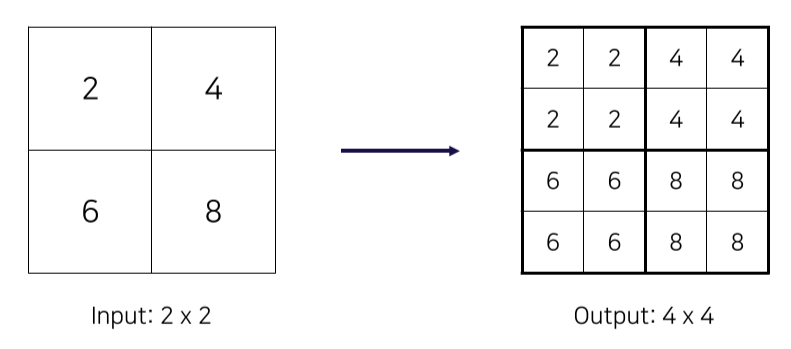
- Upsampling은 Nearest Neighbor Upsampling을 이용
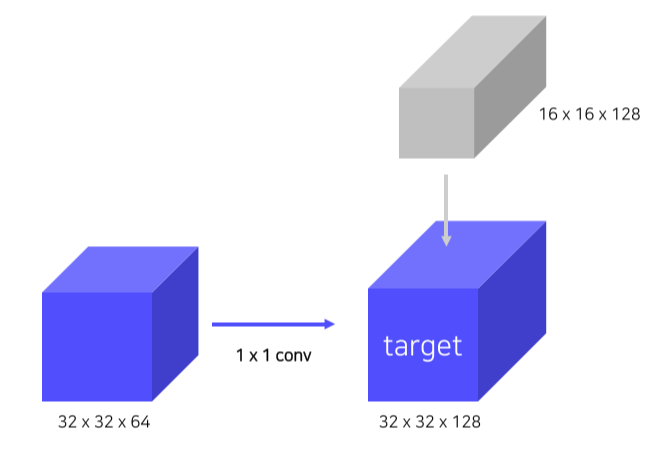
- Bottom-up에서 온 feature map은 1x1 conv로 channel 수를 맞춰줌
Pipeline
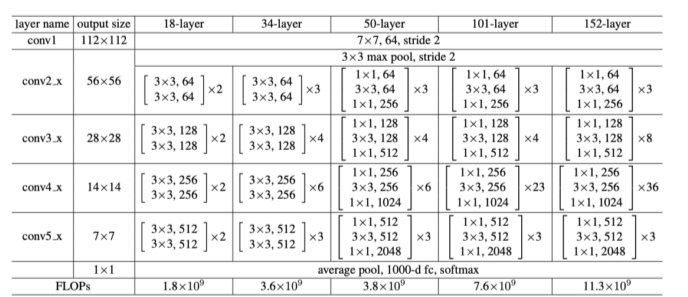
-
Backbone은 ResNet
-
총 4가지 stage가 존재, stage는 maxpooling layer로 feature size가 변할때를 기준
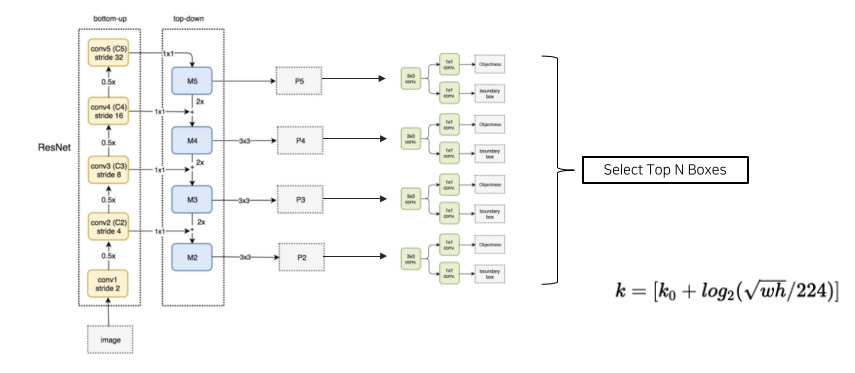
-
각 stage마다 feature를 뽑아서 나온 feature map을 RPN에 통과시켜 상위 N개의 ROI를 구한후, NMS를 적용해 최종적으로 1000개의 bbox를 구함
-
Bbox가 몇번째 stage에서 나온건지 구하기 위해 오른쪽 수식을 사용
- 은 4번째 stage를 기본으로 함
- width, height가 작으면 작을수록 수식의 값이 작아지고, 이는 low level을 활용한다는 것을 의미
Contribution
- 여러 scale의 물체를 탐지하기 위해 설계
- 이를 달성하기 위해서는 여러 크기의 feature를 사용해야할 필요가 있음
Summary
- Bottom up(backbone)에서 다양한 크기의 feature map 추출
- 다양한 크기의 feature map의 semantic을 교환하기 위해 top-down 방식 사용

- (small object에 대한 점수)가 상당히 높지만, 은 별 차이 없는것을 확인할 수 있음
PANet
Path Aggregation Network
Problem in FPN
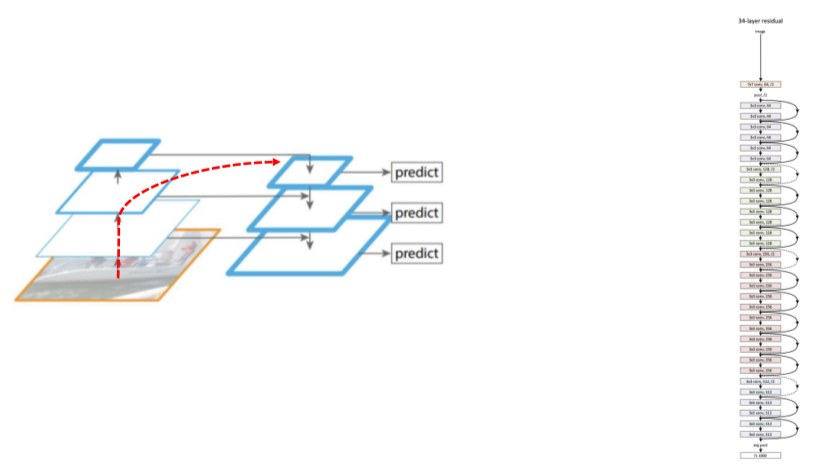
- Backbone이 너무 길어서 low level feature가 제대로 high level feature로 전달될지 보장을 못함
Bottom-up Path Augmentation
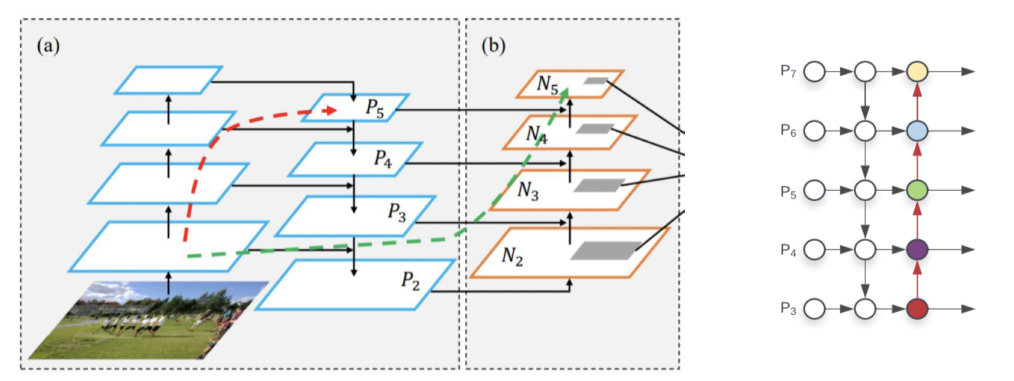
- 마지막 augmentation path는 stage를 4개만 통과하면 되기 때문에 low level info가 top level에 제대로 전달될 수 있음
Adaptive Feature Pooling
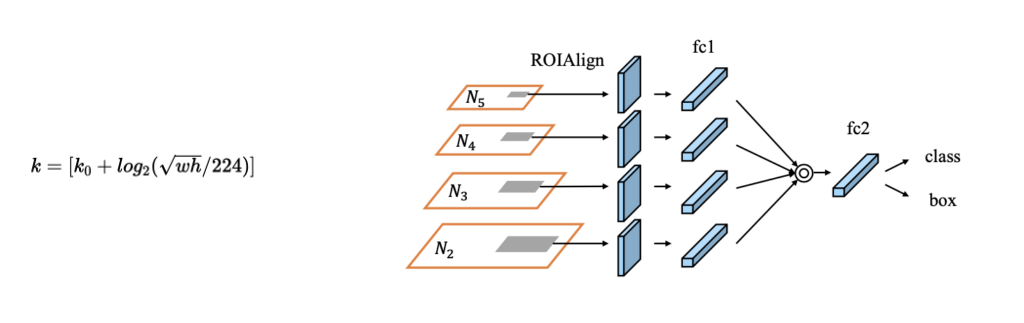
- 각 stage별로 ROI를 구하면 w,h가 애매한 ROI는 어떤 stage에서 왔는지 잘 구분하지 못함
- 그리고 stage마다 semantic, local info를 담고있는지가 다르기 때문에 그냥 모든 stage의 feature map을 이용
DetectoRS
RFP, Recursive Feature Pyramid
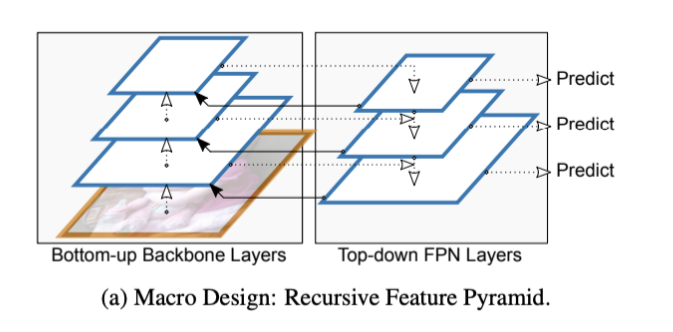
- Backbone도 neck의 정보를 이용해 다시 학습하게 만듬
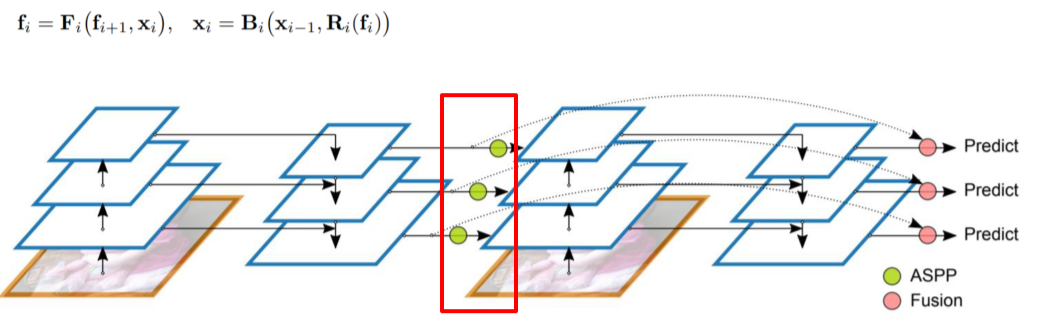
- High level info가 low level backbone에 전해질 수 있긴 하지만 연산량이 너무 많아져 느려진다는 단점이 있음
SAC, Switchable Atrous Convolution
ASPP
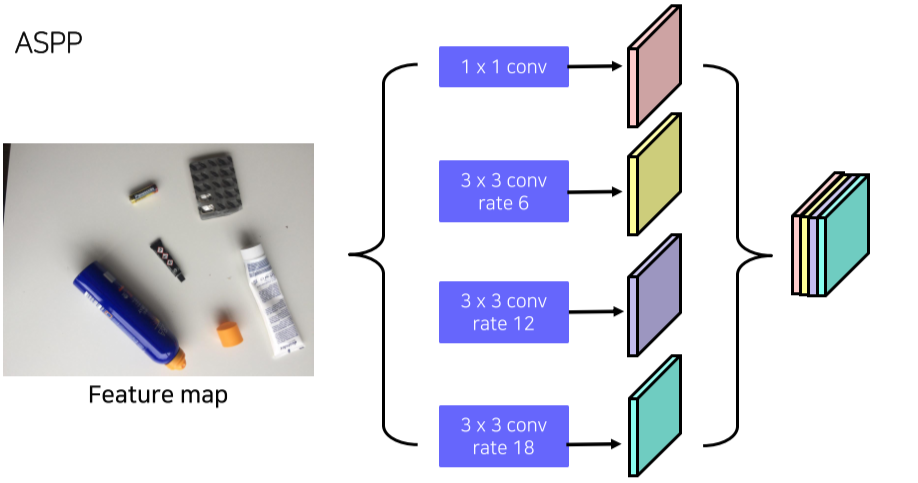
- Atrous Convolution으로 feature map의 크기를 키움
Atrous Convolution
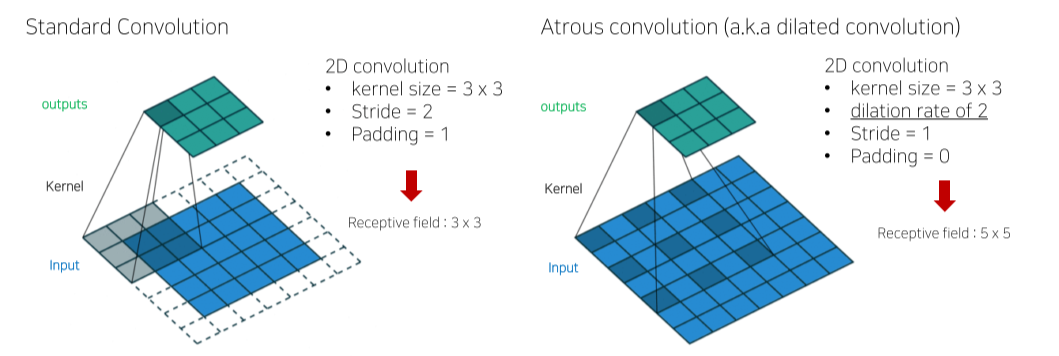
- kernel에 간격을 둬서 kernel size는 유지하면서 receptive field는 키울 수 있음
BiFPN
Bi-directional Feature Pyramid
Pipeline
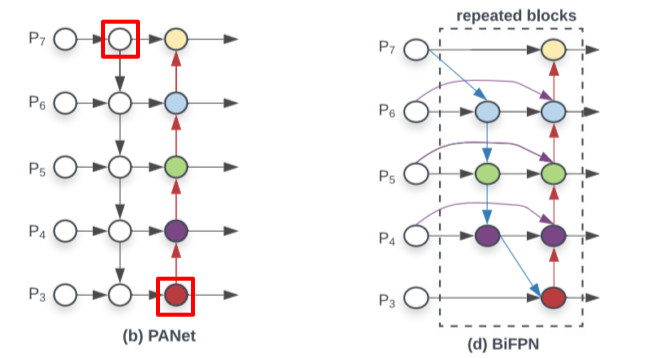
- 효율성을 위해 feature map이 한 곳에서만 오는 node를 제거
Weighted Feature Fusion
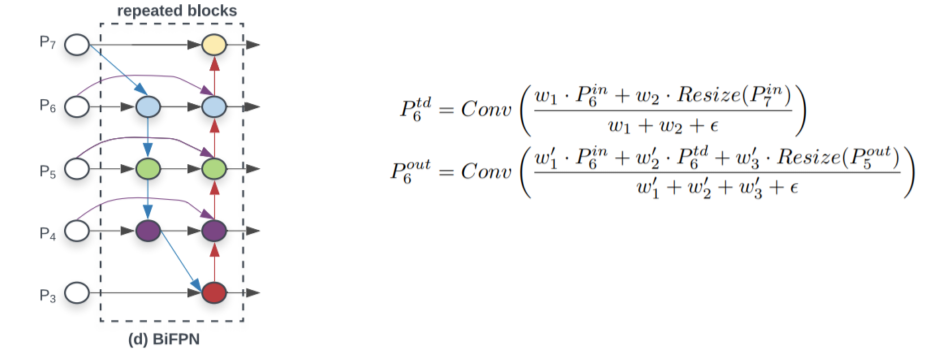
- FPN과 같이 단순 summation을 하는 것이 아니라 각 feature 별로 가중치를 부여한 뒤 summation
- 모델 사이즈의 증가는 거의 없음
- feature별 가중치를 통해 중요한 feature를 강조하여 성능 상승
NASFPN
Motivaion
- 기존의 FPN, PANet
- Top-down or bottom up pathway
- 단순 일방향(top->bottom or bottom ->top) summation 보다 좋은 방법이 있을까?
- 그렇다면 FPN 아키텍처를 NAS (Neural architecture search)를 통해서 찾자!
Architecture
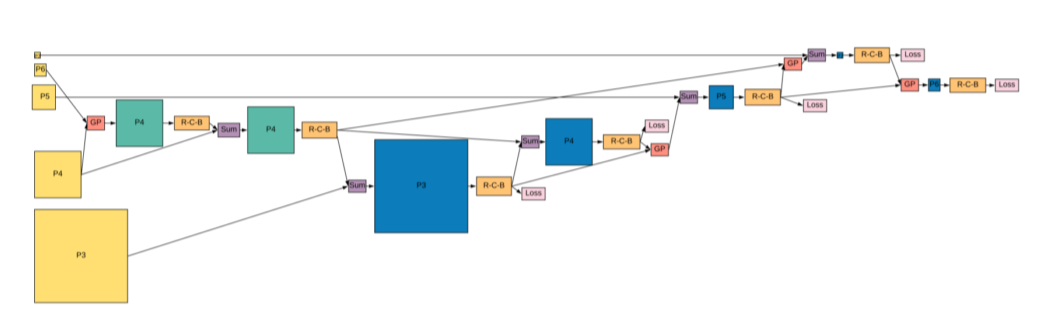
Search
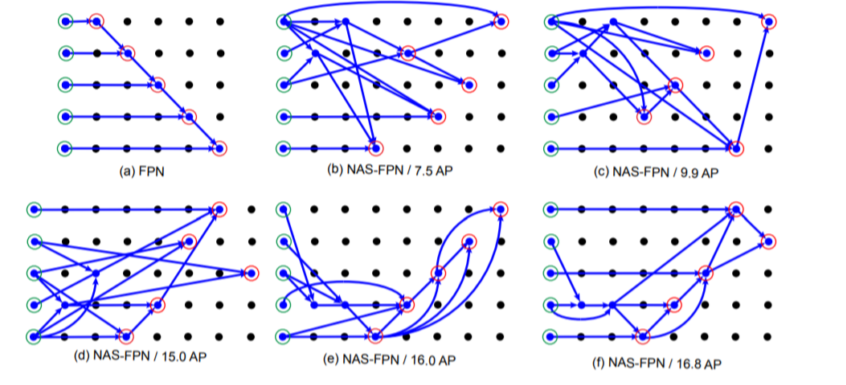
단점
- COCO dataset, ResNet 기준으로 찾은 architecture, 범용적이지 못함
- Parameter가많이소요
- High search cost
- 다른 Dataset이나 backbone에서 가장 좋은 성능을 내는 architecture를 찾기 위해 새로운 search cost
AugFPN
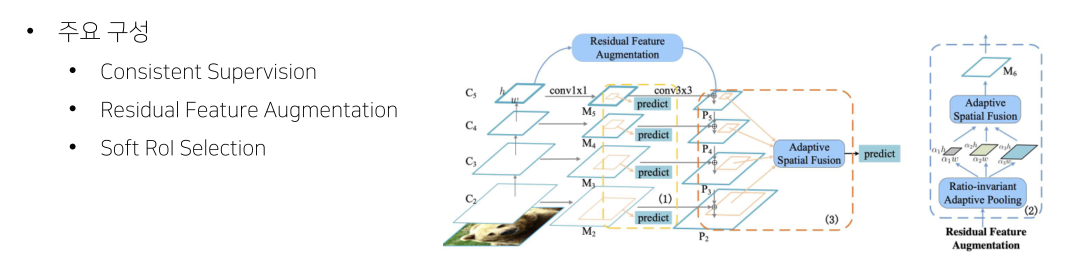
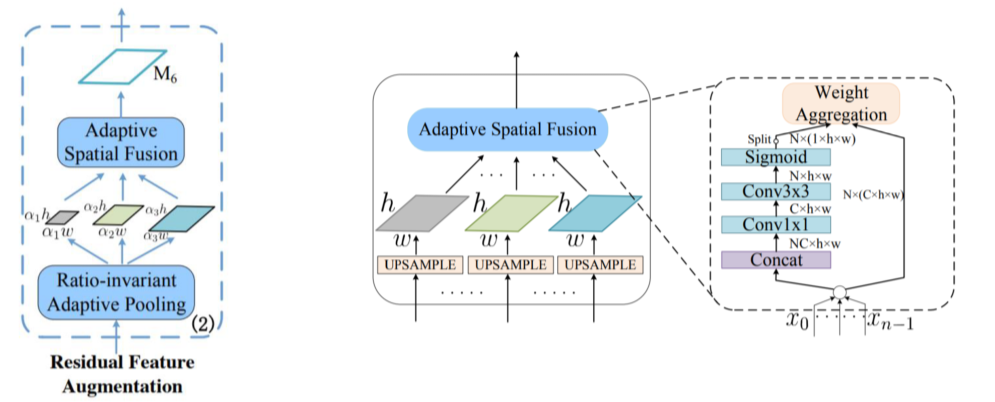
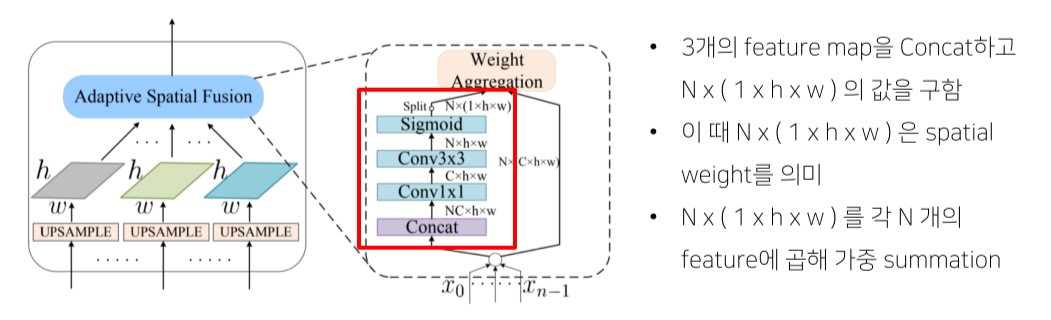
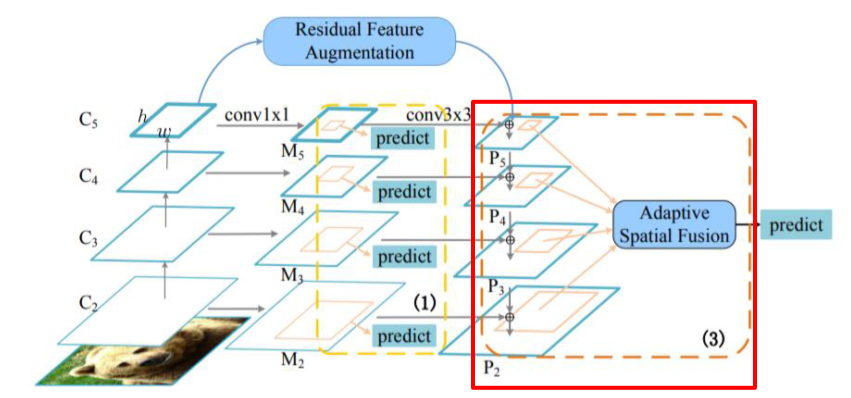
Residual Feature Augmentation
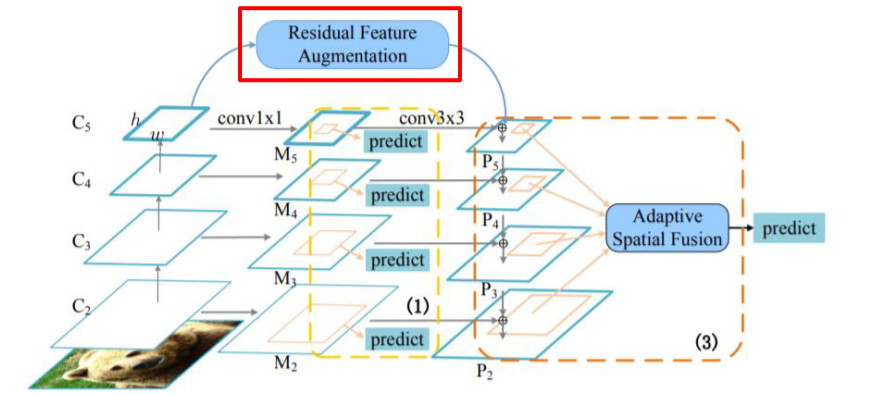
- 가장 높은 stage는 feature를 전달받지 못하기 때문에 정보 손실이 있는 점을 개선

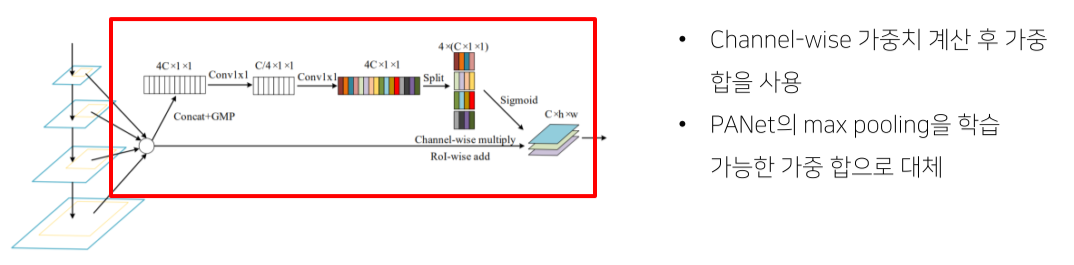
Soft RoI Selection
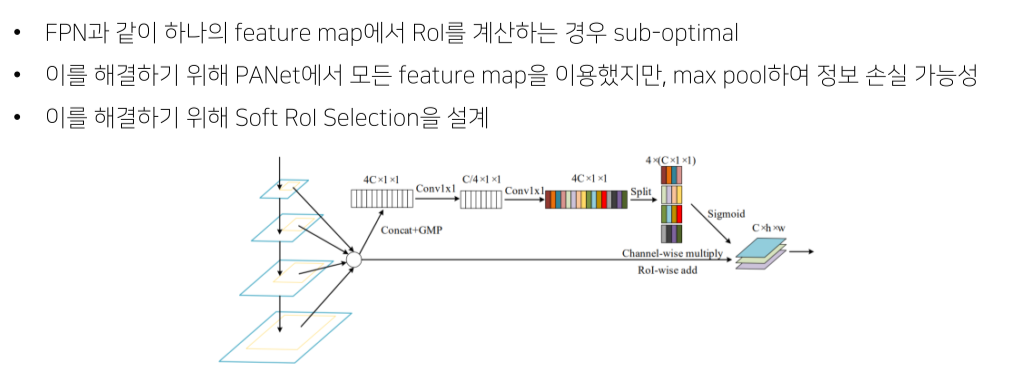
Feature map을 maxpooling하는 것은 정보손실이 심함, 그런데 그냥 더하는 것도 정보손실이 있기 때문에 weighted sum을 함
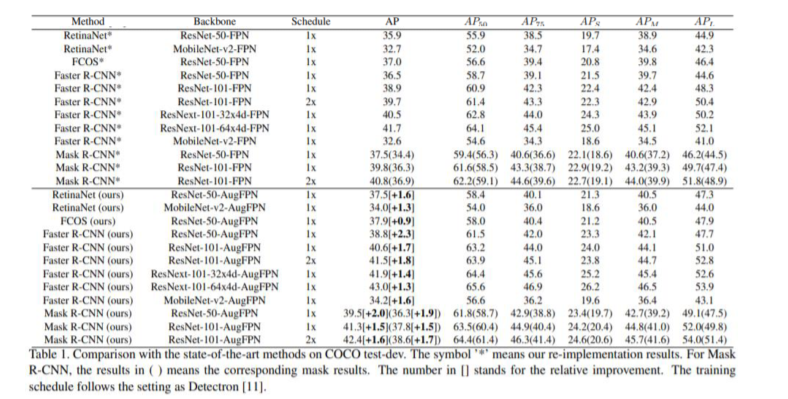
Experiment
Reference
1) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
2) Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie, “Feature Pyramid Networks for Object Detection”
3) Mingxing Tan, Ruoming Pang, Quoc V. Le, ‘EfficientDet: Scalable and Efficient Object Detection”
4) 갈아먹는 Object Detection, [7] Feature Pyramid Network
5) Siyuan Qiao, Liang-Chieh Chen, Alan Yuille, ‘DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution’
6) Golnaz Ghaisi, Tsung-Yi Lin, Ruoming Pang, Quoc V. Le, ‘NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection”
7) Chaoxu Guo, ‘AugFPN: Improving Multi-scale Feature Learning for Object Detection”
8) Jonathan Hui, Understanding Feature Pyramid Networks for object detection (FPN)
5강) 1 Stage Detectors
Background
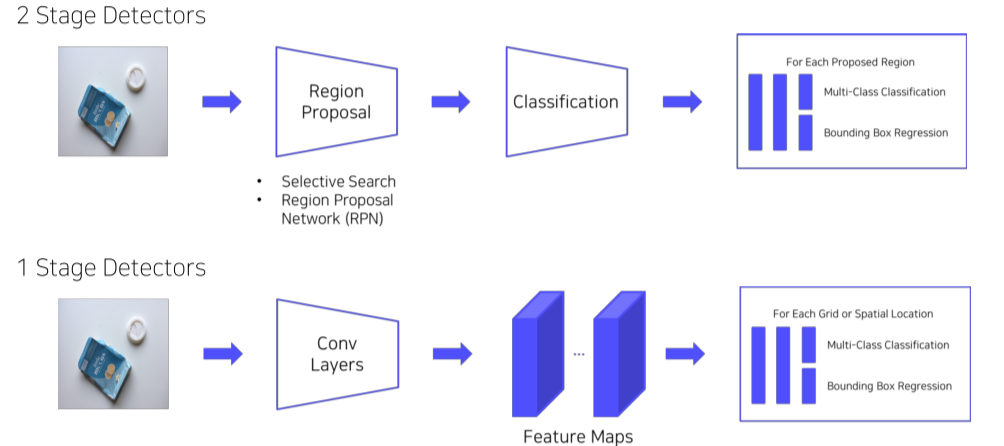
- 2 stage detector는 Localization, Classification을 따로 해서 속도가 느려서 real time으로 적용하기 어렵다는 단점이 있음

YOLO

접근 전략
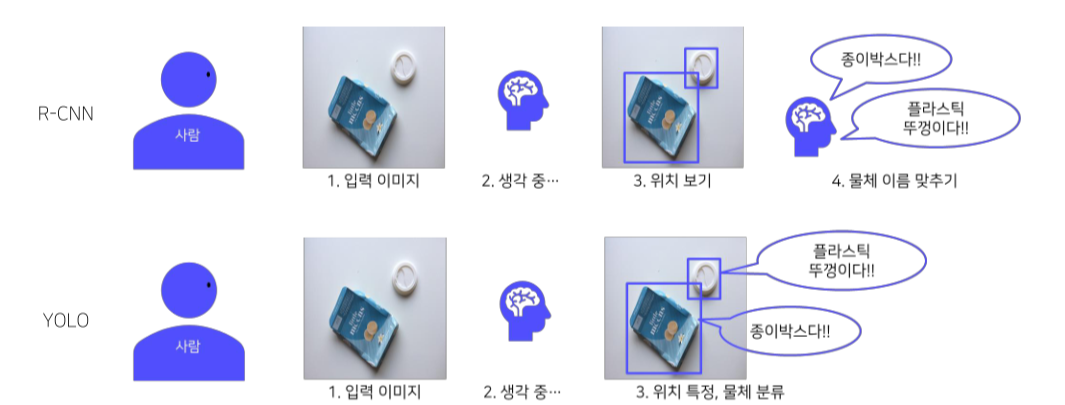
- Region Proposal 없음
- 전체 이미지에서 bounding box 예측과 클래스를 예측하는 일을 동시에 진행
- 이미지, 물체를 전체적으로 관찰하여 추론 (맥락적 이해 높아짐)
Pipeline
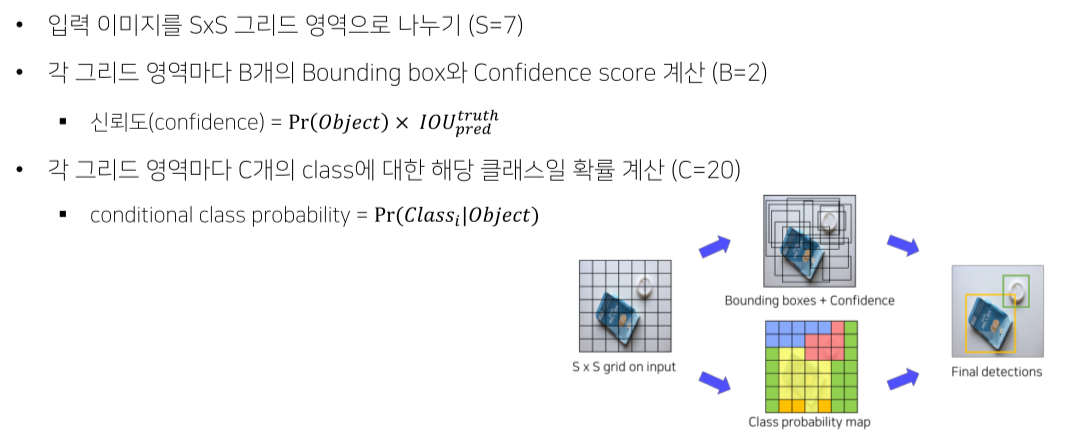
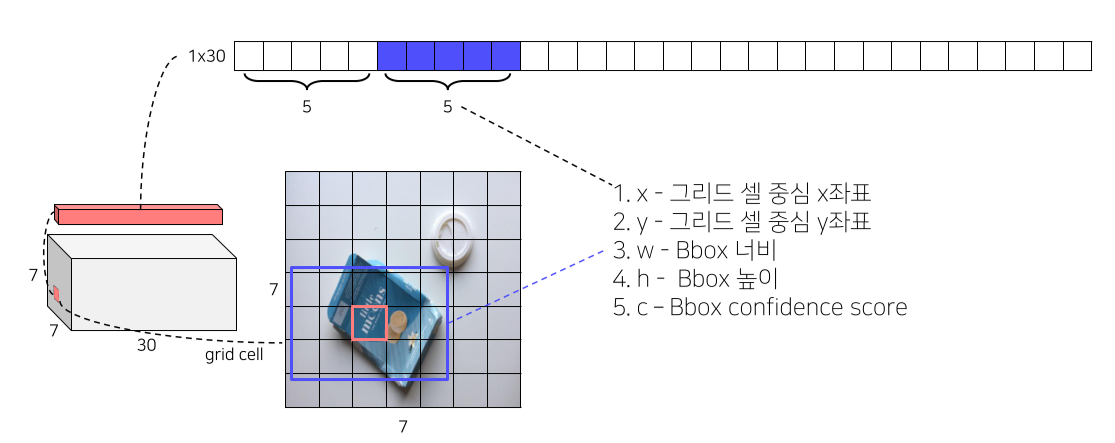
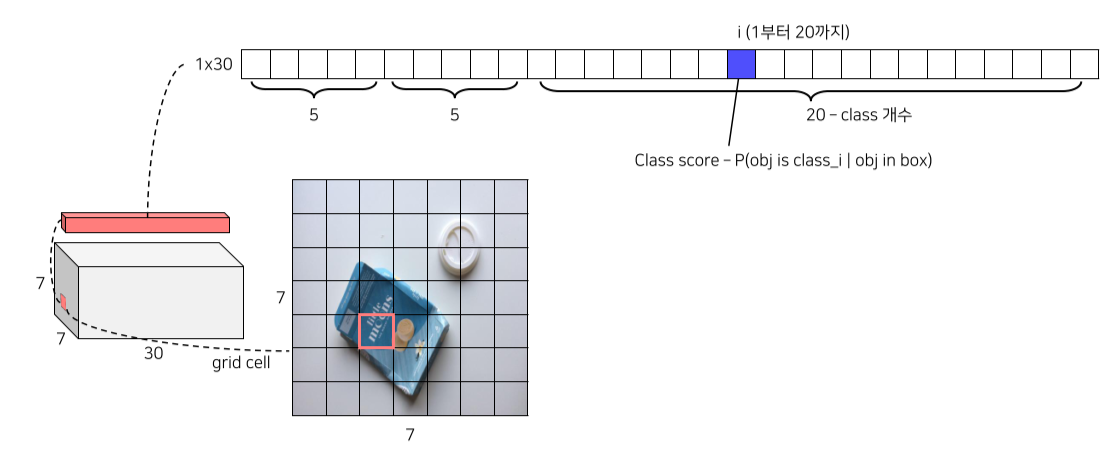
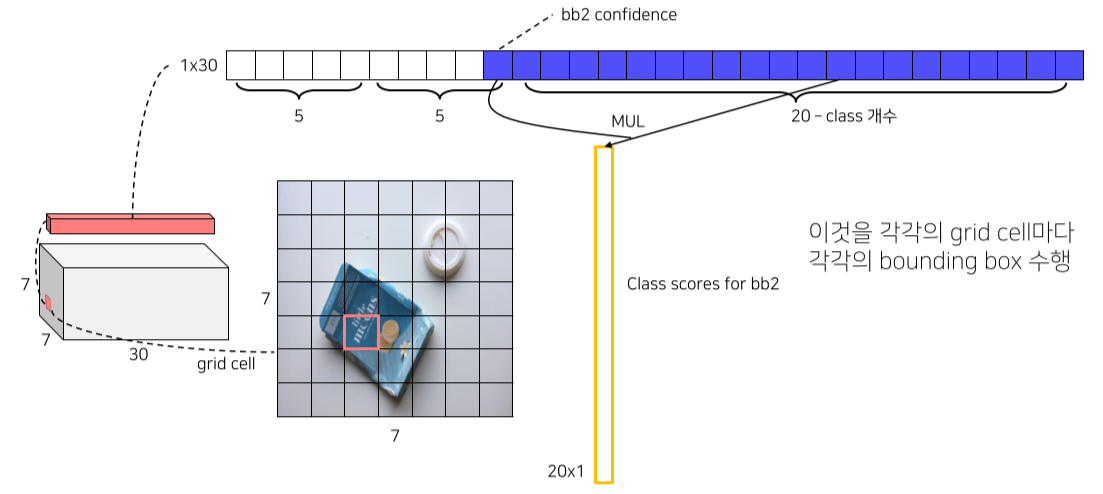
- 각 bbox의 confidence score를 class score와 곱해 최종 class score를 측정
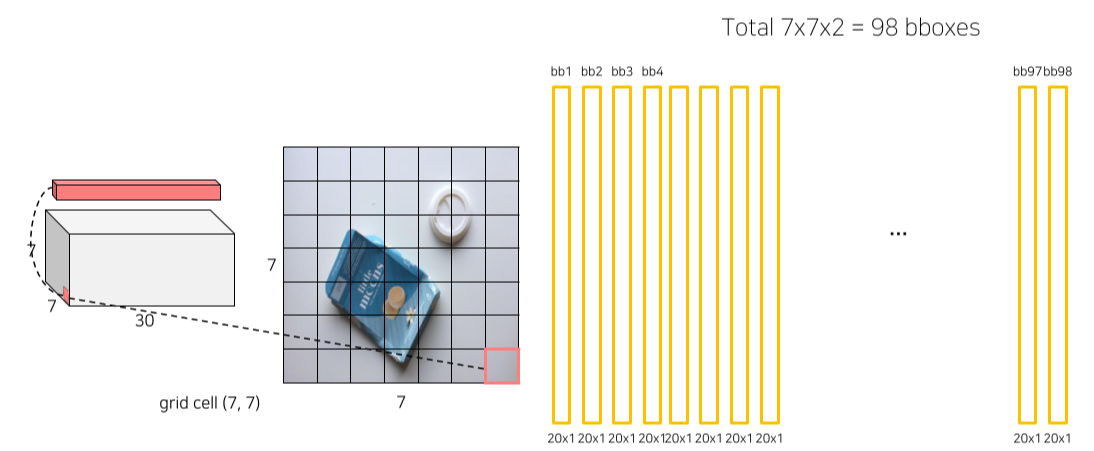
- 7x7 grid x 2 bbox = 98 score
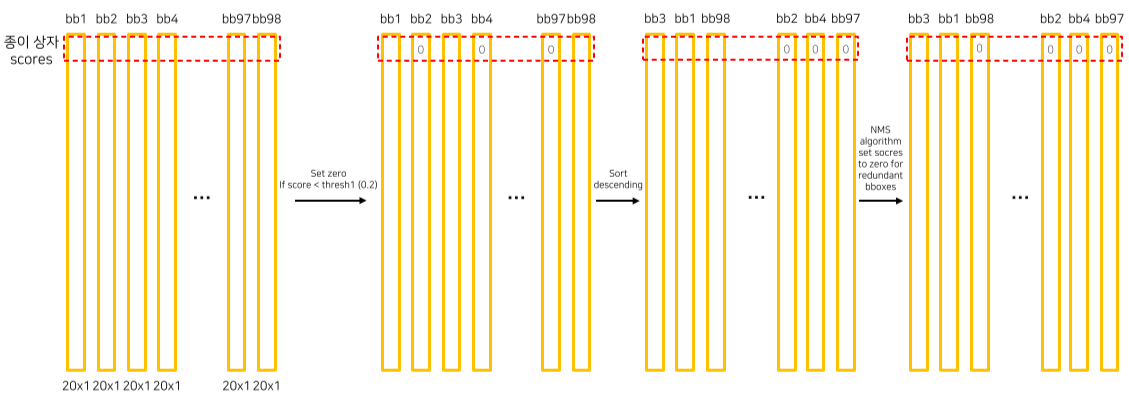
- Threshold 보다 작은 score = 0으로 만듬
- 내림차순으로 정렬
- NMS
Loss

- : 각 grid cell
- : 각 bbox
- : i번째 grid의 j번째 bbox가 obj를 포함하고 있을때
-
Localization loss: 에서 를 regression으로 계산
-
Confidence loss: object가 있을때, 없을때 모두 confidence loss를 계산
-
Classification loss: object가 있을때, 각 class에 대한 loss 계산
Result
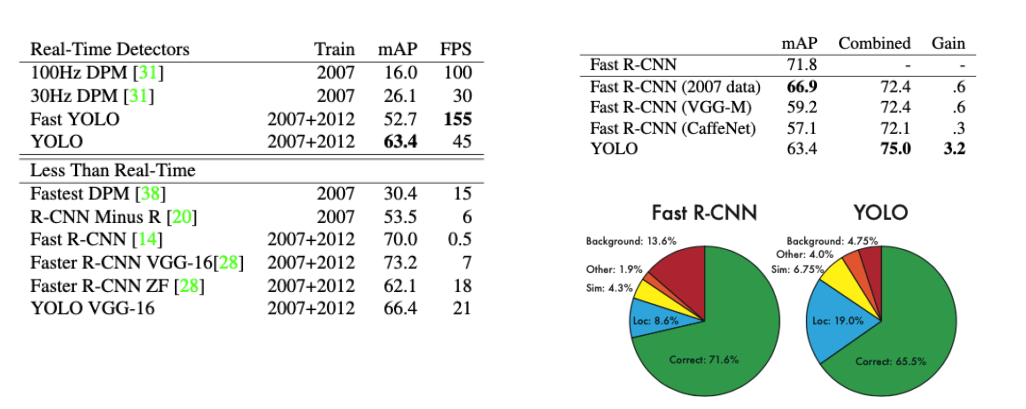
- Fast R-CNN보다 훨씬 빠름
- Background error를 잘 잡아내기 때문에 ensemble하는게 효과가 좋음
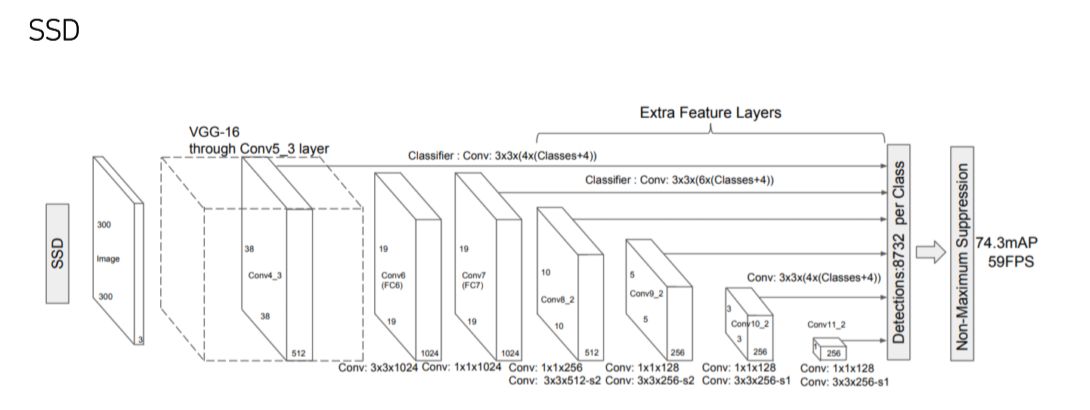
SSD

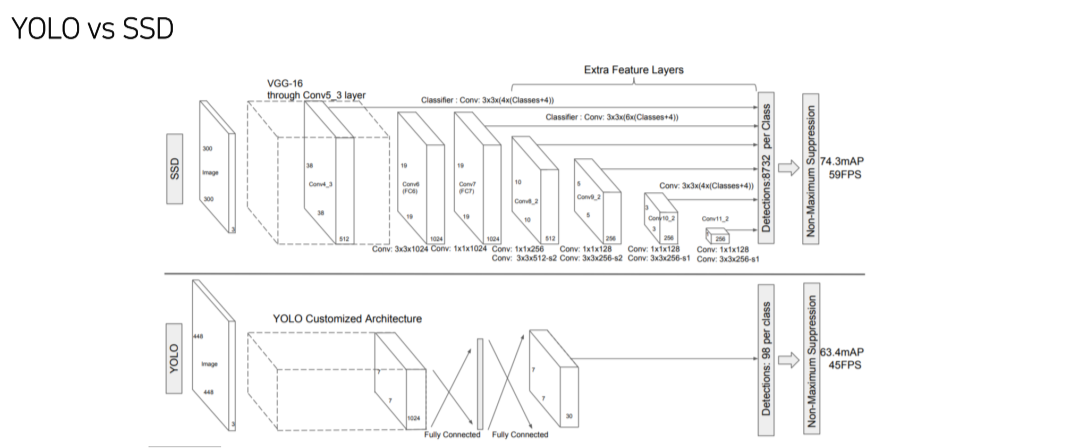
- 300x300 image를 사용
- FC layer 대신 1x1 conv로 속도를 높임
- Feature map으로부터 extra convolution을 진행해 추가로 feature map을 만들어 사용

Pipeline
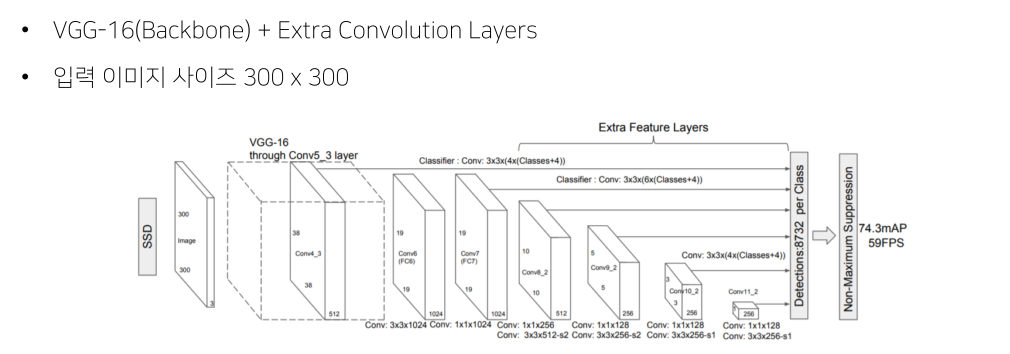
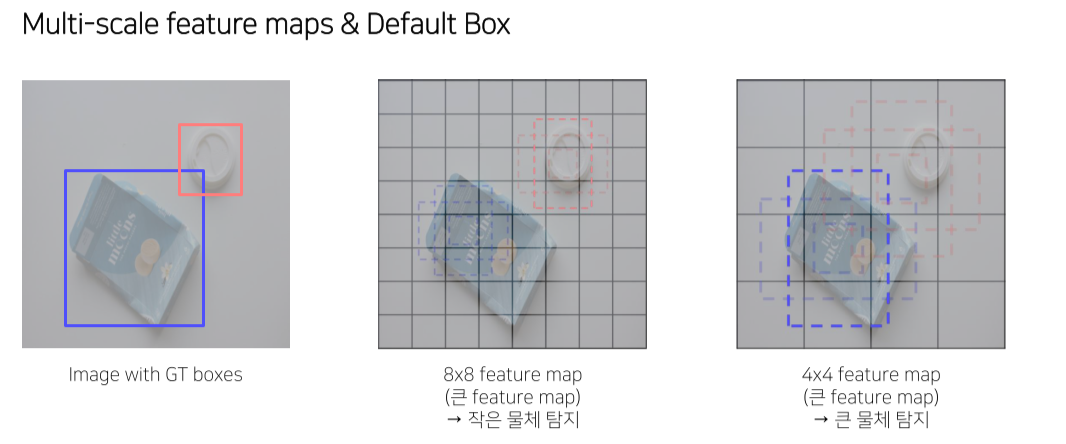
Multi-scale feature maps
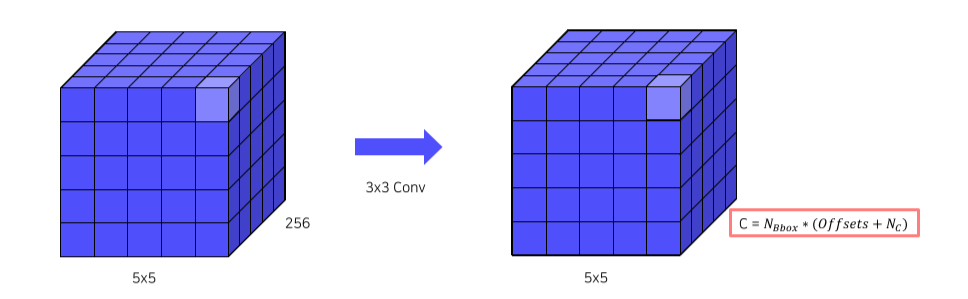
-
feature map을 어떻게 anchor로 사용하는지에 대한 설명
-
3x3 conv로 channel의 갯수를 변경
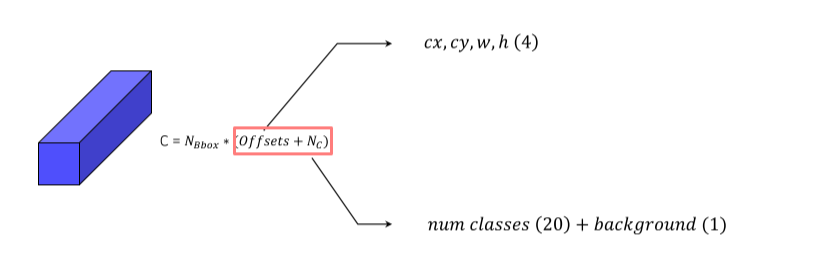
-
Output channel은 box 갯수 x 25
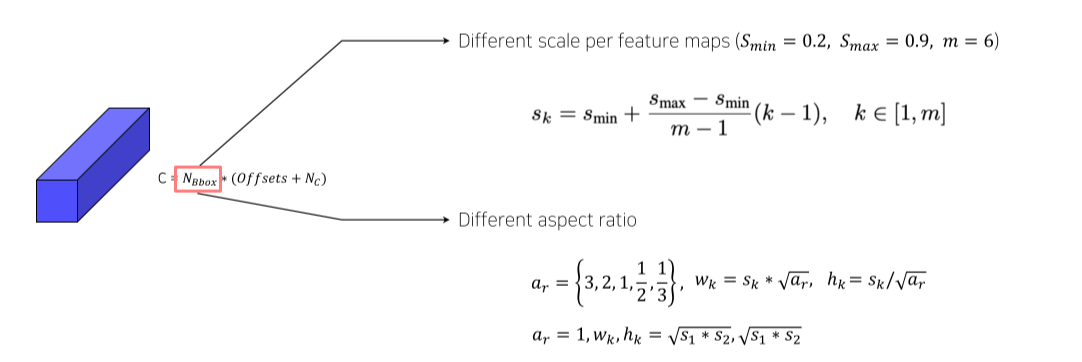
-
Anchor box는 aspect ratio, scale을 토대로 설정
Aspect ratio가 1일 경우에 한해 다음 stage와 중간 크기의 box를 1개 추가
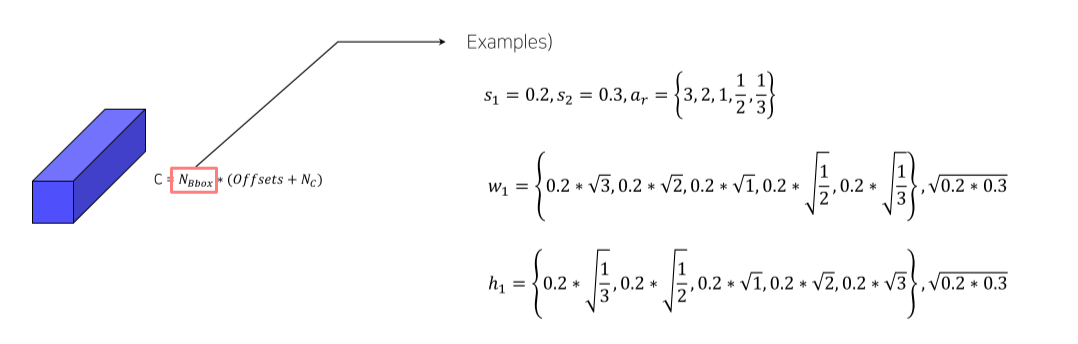
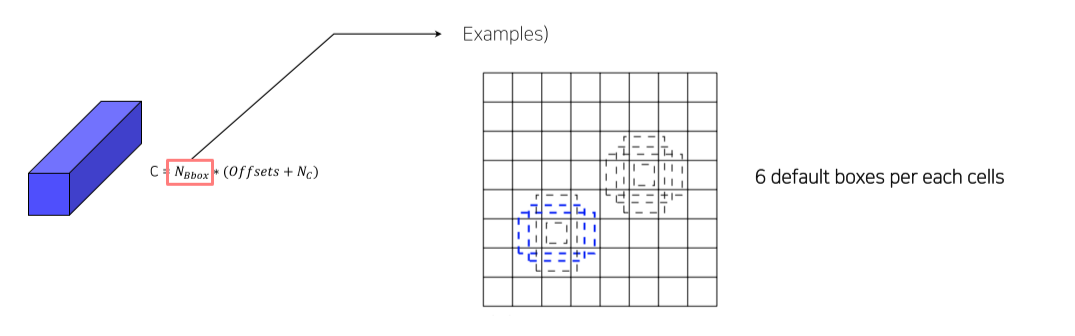
- 총 6개 box * 25 = 150 channel
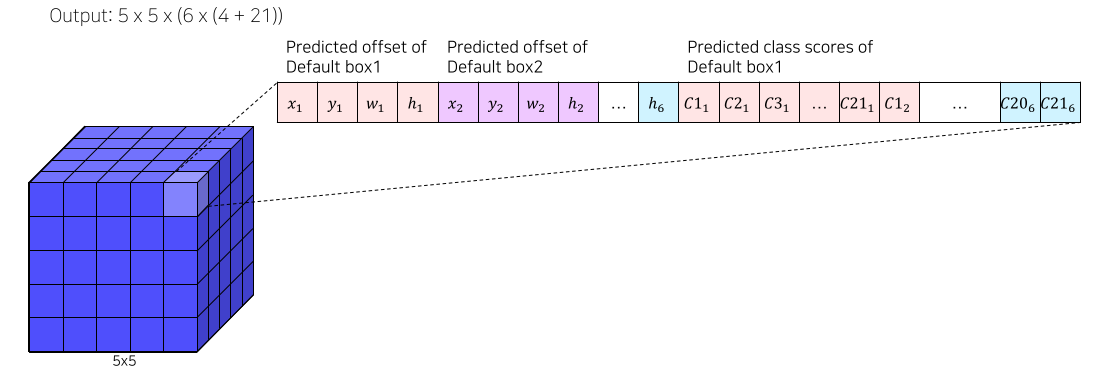
- 총 output은 5x5 pixel 각 pixel마다 box 6개 각 box의 좌표 4개 각 box의 class score 21개
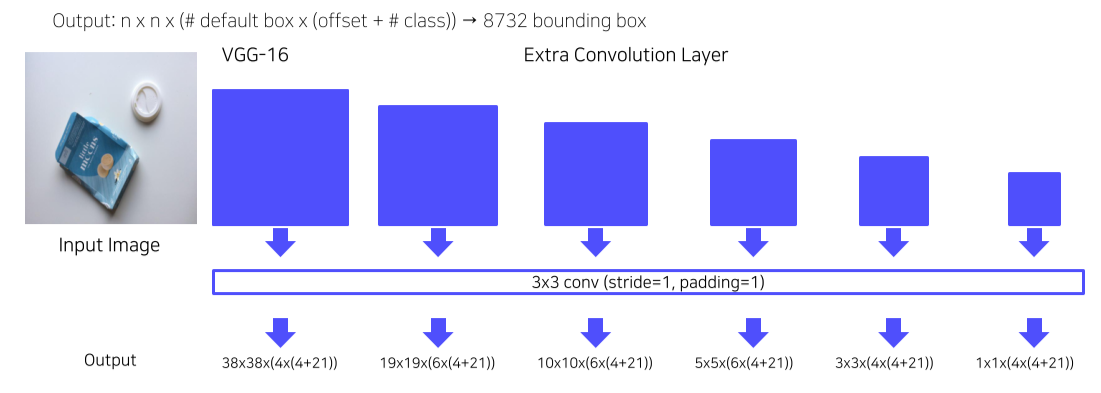
Training
- Hard negative mining 수행
- Non maximum suppression 수행

Result
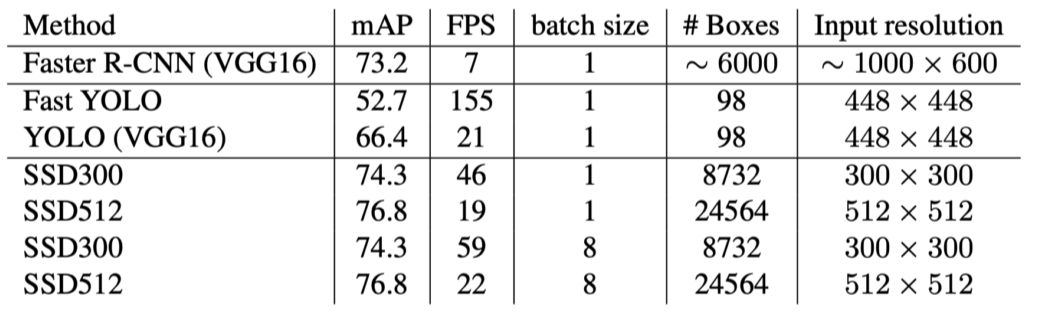
- YOLO 보다 빠르고 성능도 좋음
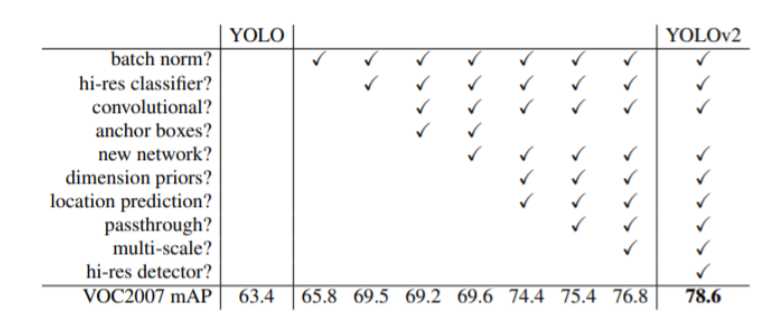
YOLO v2

Better


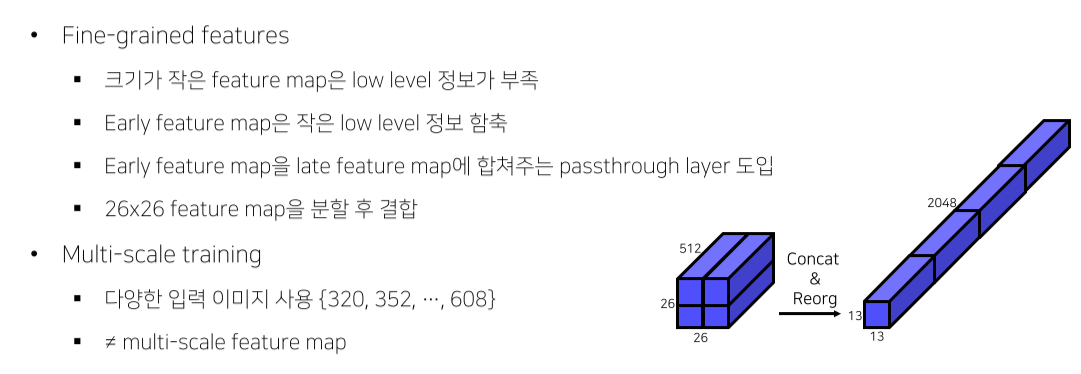
-
FC layer 제거해서 속도 개선
-
Anchor box로 어느정도 default를 줌
Faster

Result
Stronger

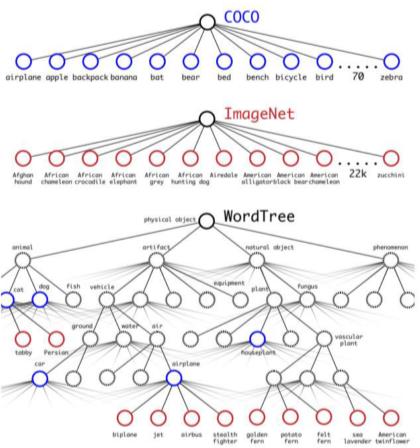
- Detection task는 coco dataset으로,
classification tastk는 imagenet dataset으로 돌렸는데
classification dataset에 대해서도 어느정도 detection을 했음
YOLO v3
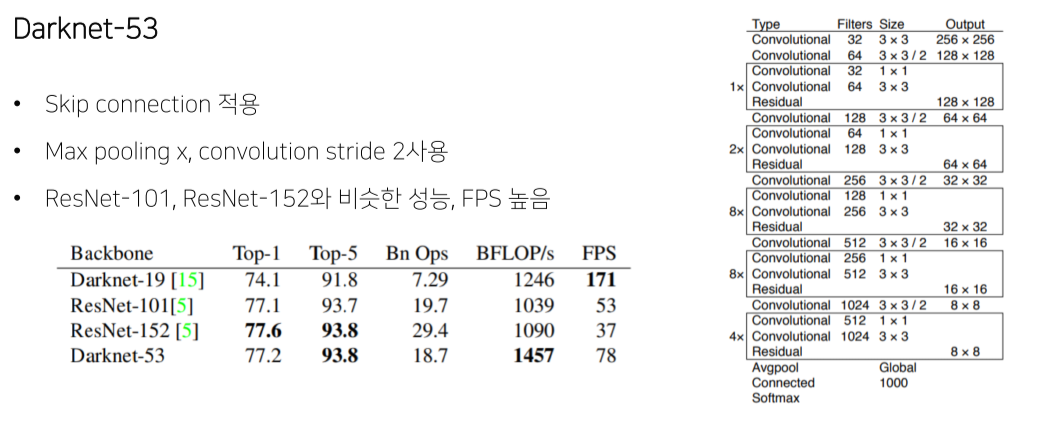
Multi-scale feature maps

RetinaNet
1 Stage Detector Problems

- Image 전체를 grid로 나눠서 판별하기 때문에 background를 포함할 확률이 굉장히 높음
Concept
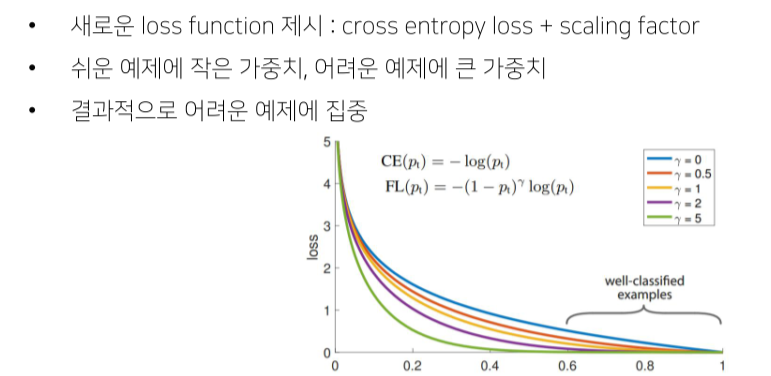
- loss가 큰(어려운) 문제에 대해서는 backward를 크게 해서 학습
Result
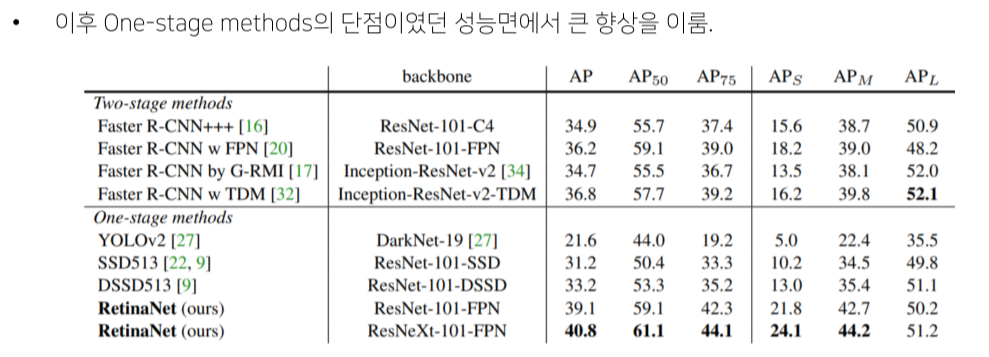
Focal loss
Summary
1 stage detector 연구동향및 paper Summary
- Anchor
- [DAFS] Dynamic Anchor Feature Selection for Single-Shot Object Detection [ICCV' 19]
- [FSAF] Feature Selective Anchor-Free Module for Single-Shot Object Detection [CVPR' 19]
- Multi-scale feature map
- M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network [AAAI' 19]
- Learning Rich Features at High-Speed for Single-Shot Object Detection [ICCV' 19]
- 경량화
- YOLOv4: Optimal Speed and Accuracy of Object Detection [arXiv' 20]
- Scaled-YOLOv4: Scaling Cross Stage Partial Network [CVPR’ 21]
Reference
1) Hoya012, https://hoya012.github.io/
2) 갈아먹는 Object Detection, https://yeomko.tistory.com/13 3) Deepsystems, https://deepsystems.ai/reviews
4) https://herbwood.tistory.com
5) https://arxiv.org/pdf/1506.02640.pdf (You Only Look Once: Unified, Real-Time Object Detection)
6) https://arxiv.org/pdf/1512.02325.pdf (SSD: Single Shot MultiBox Detector)
7) https://arxiv.org/pdf/1612.08242.pdf (YOLO9000: Better, Faster, Stronger)
8) https://pjreddie.com/media/files/papers/YOLOv3.pdf (YOLOv3: An Incremental Improvemen)
9) https://arxiv.org/pdf/1708.02002.pdf (Focal Loss for Dense Object Detection)
10) https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/object_detection
6강) EfficientDet
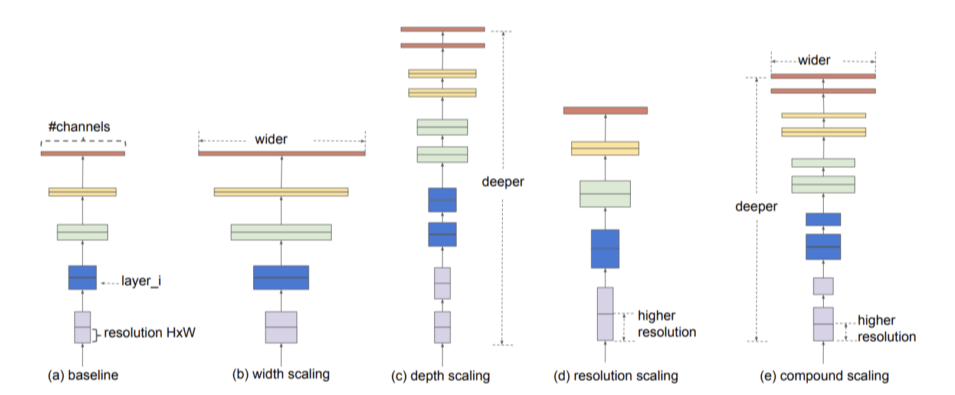
- 모델을 깊게 쌓으면 성능이 높아짐
하지만 깊게 쌓을수록 느려지기만 하고 성능 개선은 잘 안됨(tradeoff)
--> 어떻게 해야 '잘' 쌓을까?
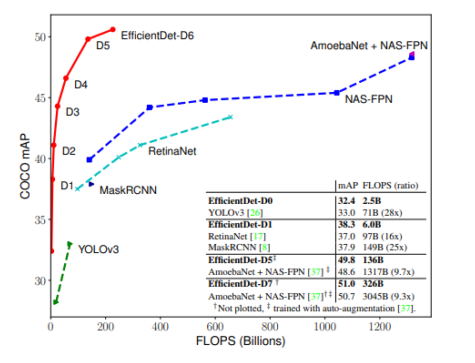
- width, depth, resolution의 모든 균형을 잘 맞춰서 크기를 키우면 FLOPs 대비 성능이 뛰어남
EfficientNet
등장배경


- 현업에서는 resource의 제한이 있기 때문에 무작정 model을 키울 수 없음
Baseline
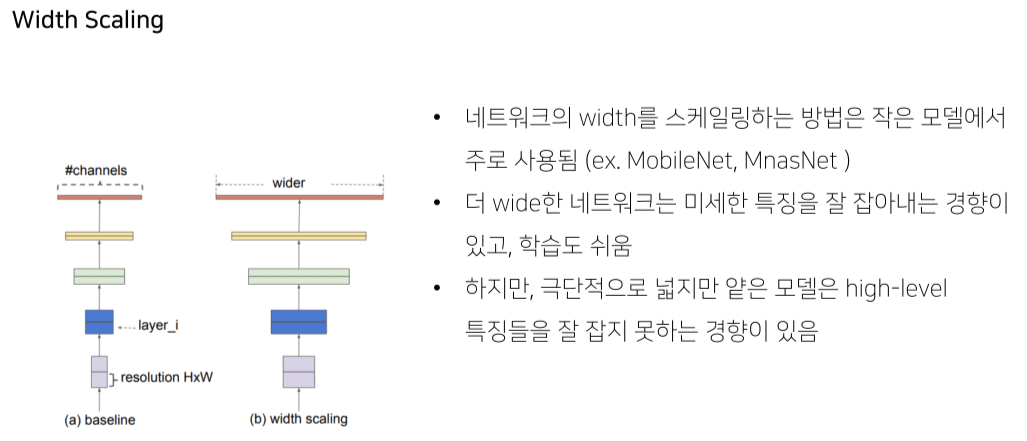
- 얕으면 semantic feature를 잘 잡아내지 못함
(충분히 깊지 않아 넓은 receptive field를 갖지 못하기 때문)


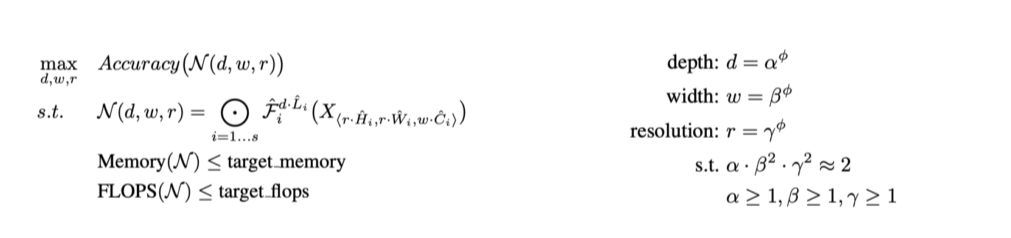
- Accuracy를 최대로 하는 를 찾는 것이 목표
하지만 동시에 target memory, flops를 설정해 그보다 작게 만듬

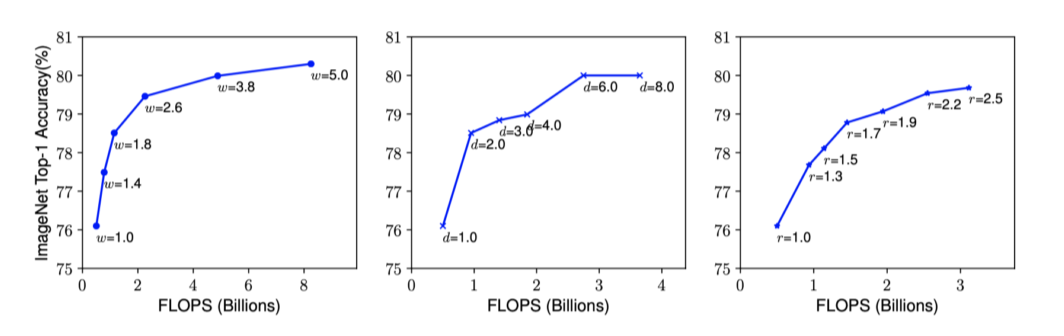
- 이 커질수록 정확도가 오르긴 하지만 상승폭이 줄어듬
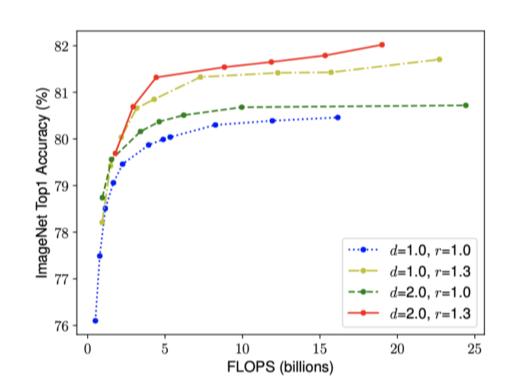
- 의 균형을 맞추는 것이 중요
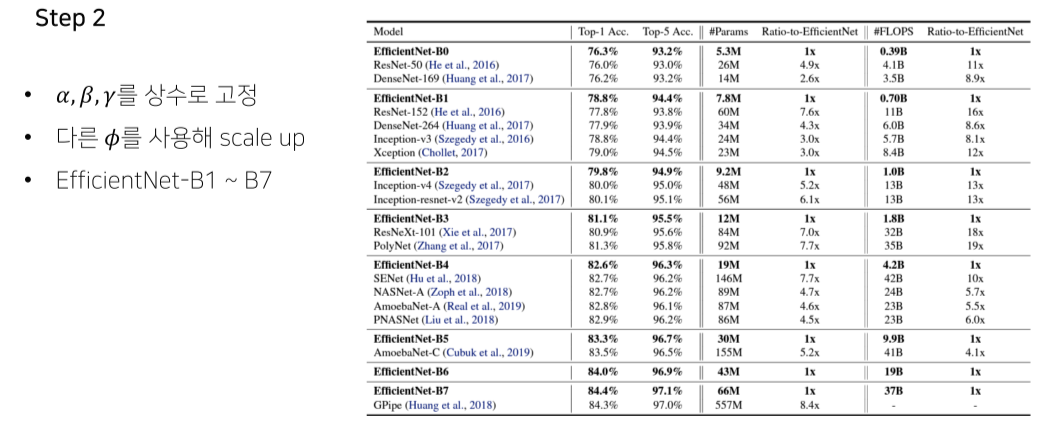
EfficientNet-B0

- grid search로 huristic하게 찾음
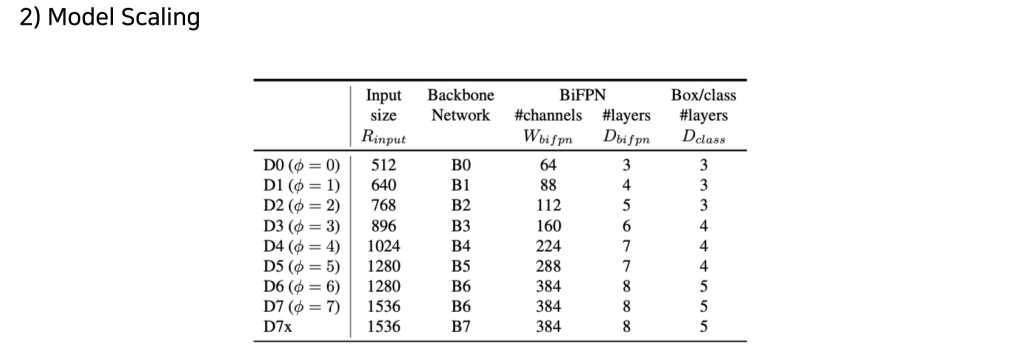
EfficientDet
EfficientNet의 알고리즘을 그대로 detection에 적용
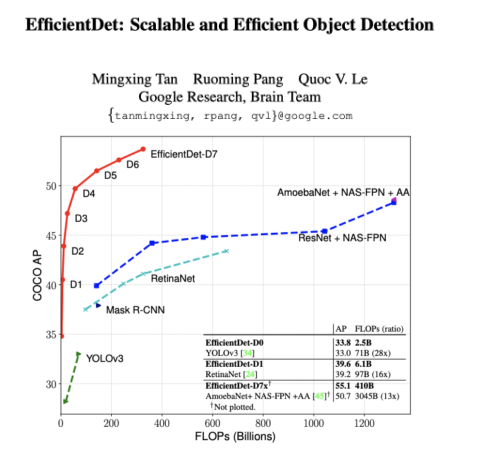
- 연산량(FLOPs) 대비 성능이 굉장히 좋음



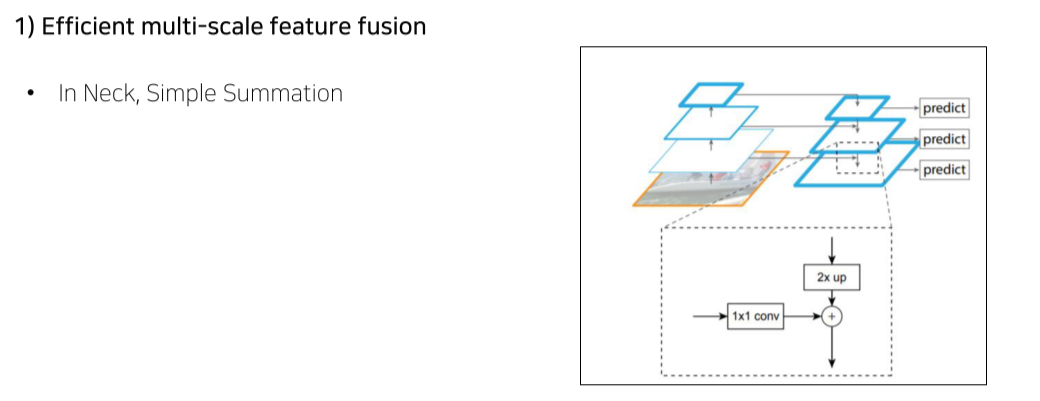
- 기존의 neck에서는 단순히 channel, resolution을 맞춰서 summation



- 이전에는 단순히 resize 후 summation

- BiFPN은 weighted summation



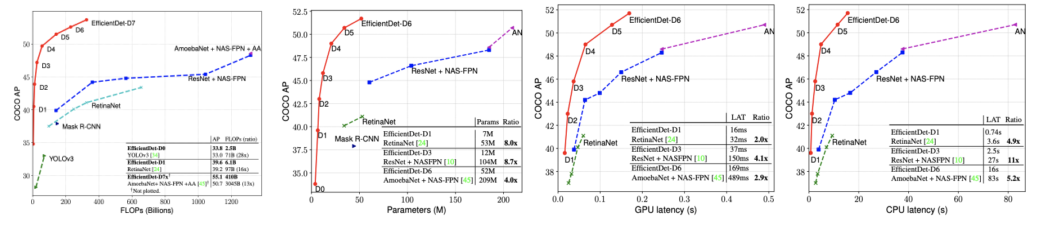
-
FLOPs에 비해 성능이 월등히 좋음
-
성능에 비해 model size, speed에서 월등히 이득
Reference
1) Mingxing Tan, Quoc V.Le , “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,” in CVPR 2019
2) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, 2015
3) Mingxing Tan, Ruoming Pang, Quoc V.Le , “EfficientDet: Scalable and Efficient Object Detection
4) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
5) Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie , “Feature Pyramid Networks for Object Detection”
6) https://github.com/toandaominh1997/EfficientDet.Pytorch/tree/fbe56e58c9a2749520303d2d380427e5f01305ba
7) Sergey Zagoruyko, Nikos Komodakis, Wide Residual Networks
7강) Advanced Object Detection 1
Cascade RCNN
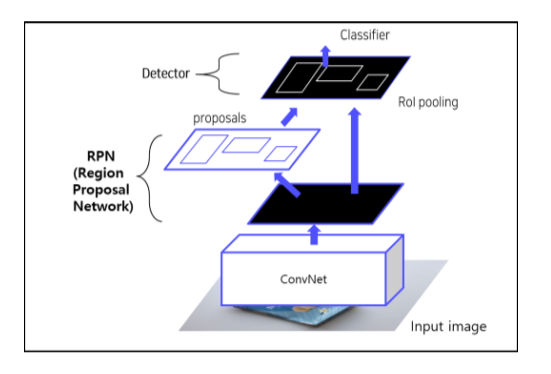
- Faster RCNN: CNN의 결과인 feature map에서 RPN으로 ROI를 뽑고, ROI를 feature map에 project해서 고정된 feature vector를 추출
이후 feature vector classification/regression head에 넣어 ROI의 위치와 class를 판별
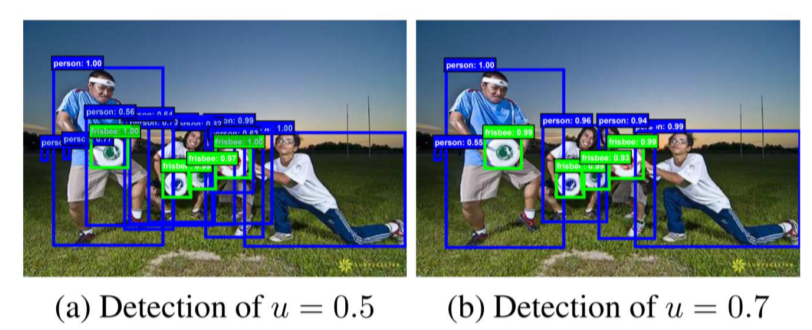
- IOU threshold 값에 따라 false positive, 성능의 차이가 많이 남
-
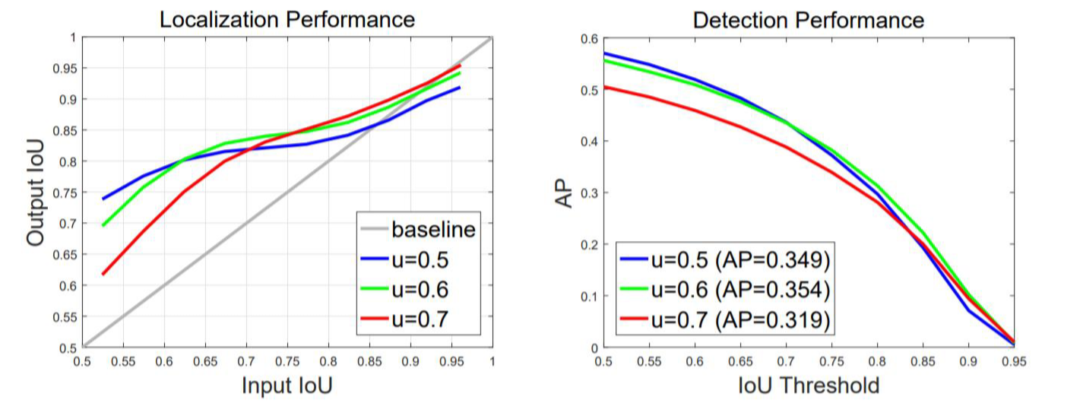
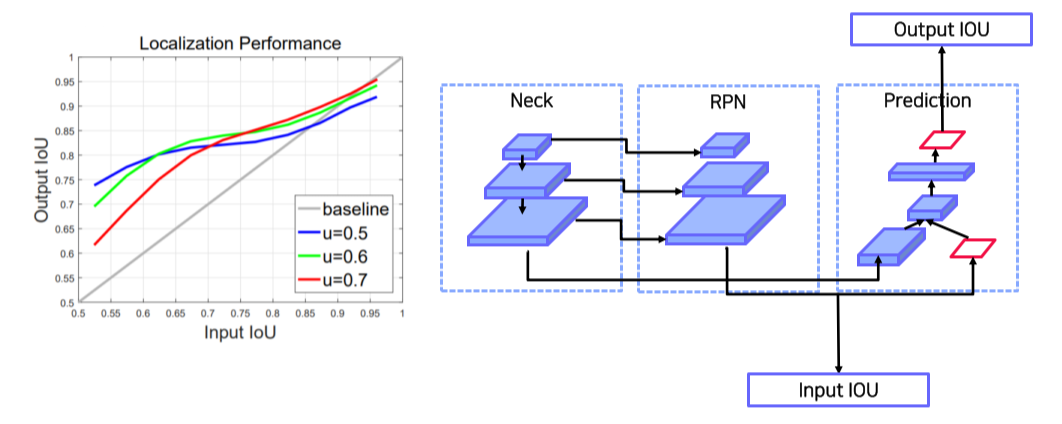
Input IOU: RPN의 결과가 GT와 어떤 관계를 가질까
-
Output IOU: prediction 결과가 GT와 어떤 관계를 가질까
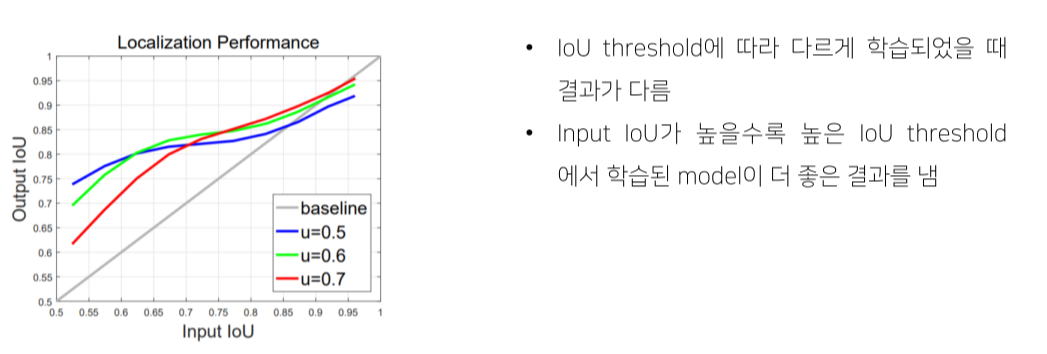
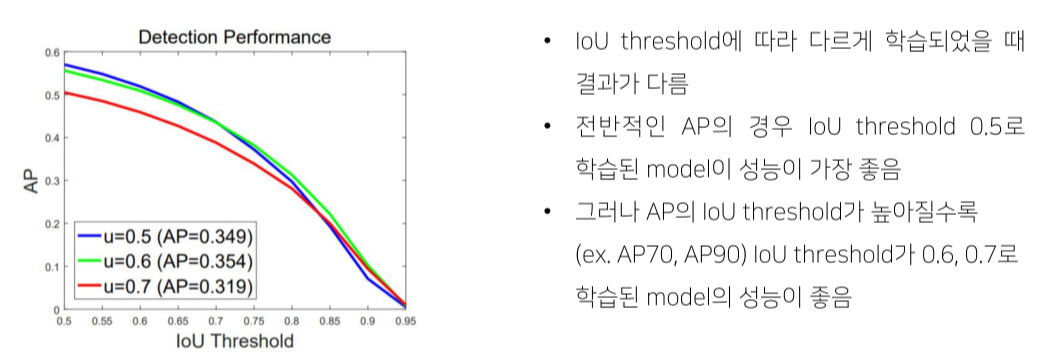

- 작은 IOU로 학습된 model은 작은 IOU를 갖는 box를 예측하는데 유리, and vice versa
--> IOU를 높여서만 학습하면 성능이 떨어짐
Method
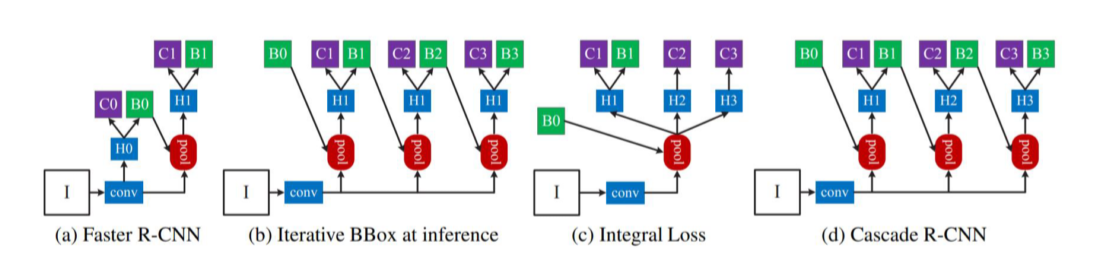
- I: input image
- conv: backbone network
- H: RPN의 결과
- C: class head
- B: bbox head
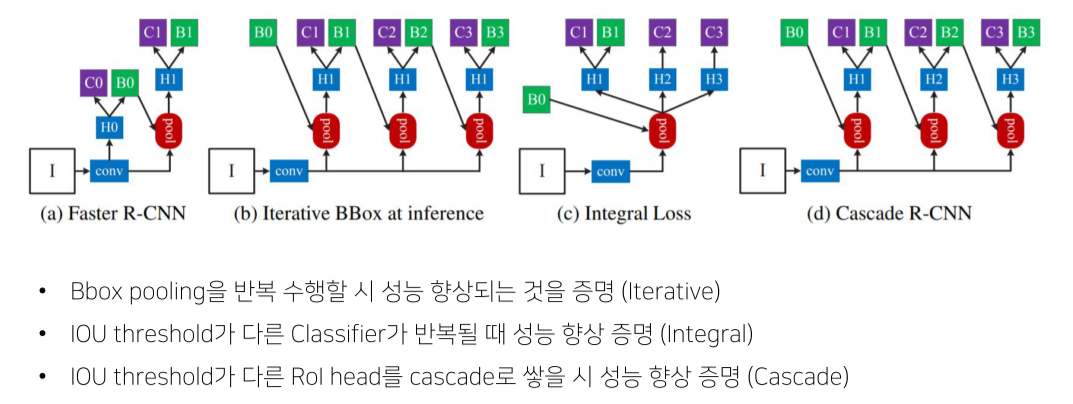
(a) Faster R-CNN
- RPN으로 C0, B0에서 각각 fore/background, bbox를 예측
- 예측 결과를 feature map에 pooling시켜 C1에서 어떤 class인지 예측
(b) Iterative BBox at inference
- projection-pooling을 여러번
- bbox head의 결과를 iterative하게 ROI projection에 이용
(c) Integral Loss

- ROI threshold가 다른 head를 여러개 구성
(d) Cascade R-CNN

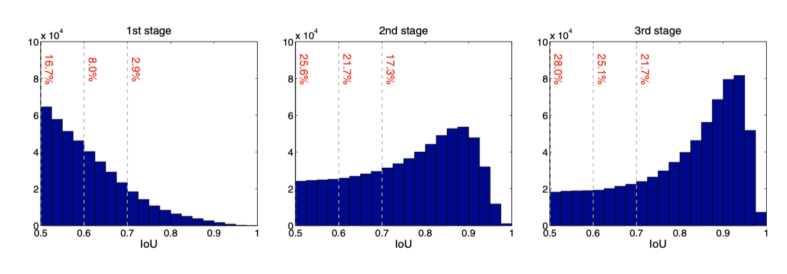
- 학습이 진행될수록 성능이 높아짐
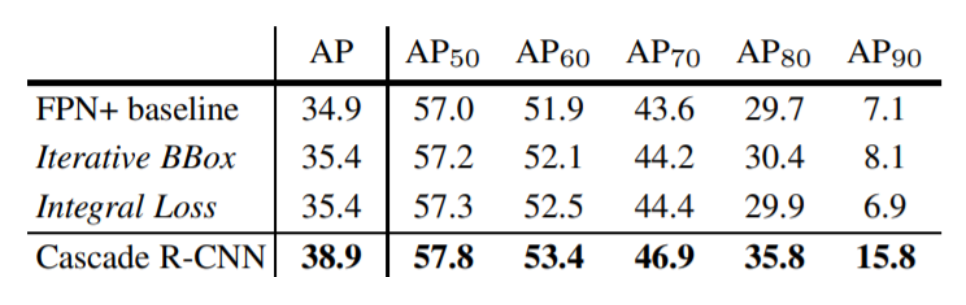
- AP90(IOU가 90일때) 성능 향상이 돋보임
Deformable Convolutional Networks (DCN)
- CNN의 문제점
- 일정한 패턴을 지닌 convolution neural networks는 geometric transformations에 한계를 지님
- 해결 방법
- Geometric augmentation

- Geometric invariant feature engineering
- 하지만 여전히 huristic하게 추가하지 augmentation이 아니면 잘 검증하지 못한다는 단점이 있음
- Geometric augmentation
- 제안하는 module
- Deformable convolution: convolution filter size를 정사각형이 아니라 다양한 size로
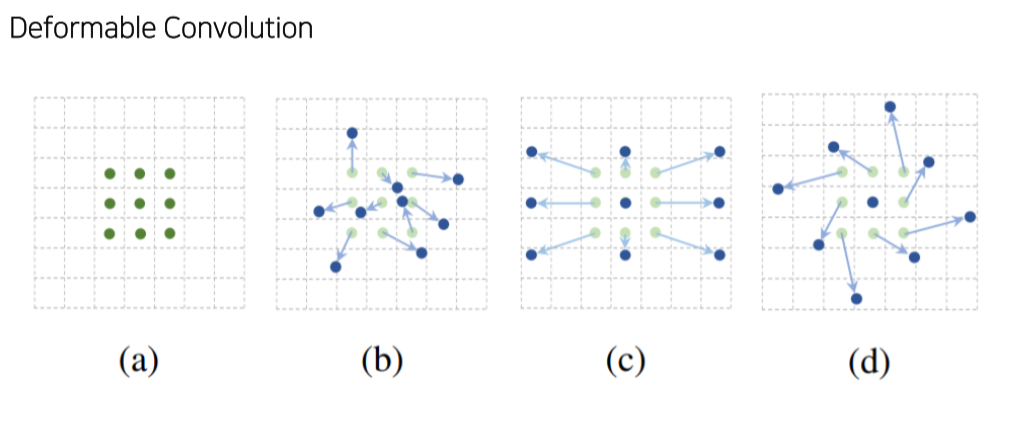
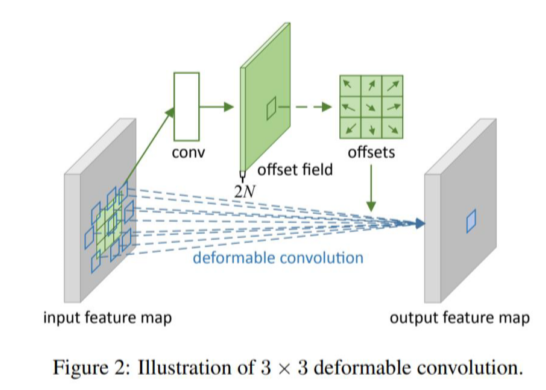
- Kernel size는 그대로 두고, 각 kernel의 pixel이 input image와 곱해지는 자리를 다르게 offset을 추가


- 각 위치의 offset만큼 중앙 에서 움직여서 input image와 연산
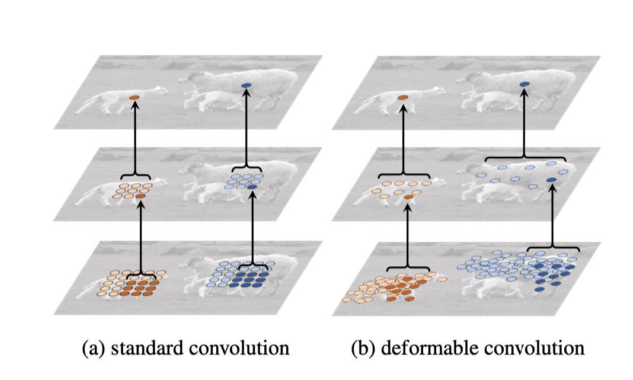

- 배경이 아니라 객체의 위치에서 conv를 수행하기 때문에 model이 객체에 대해 더 잘 학습할 수 있음
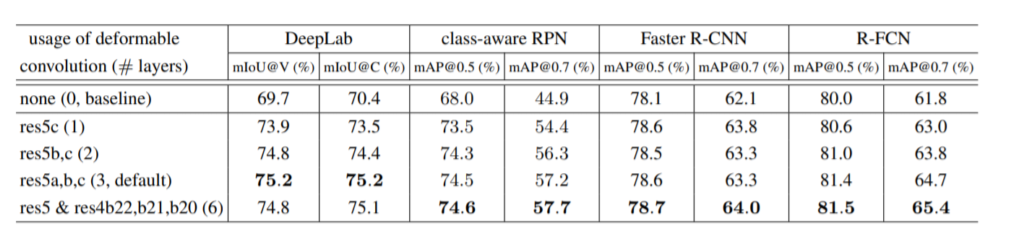
- 사소한 성능 향상
Transformer


DETR, End-to-End Object Detection with Transformer

- 기존엔 prediction 결과로 너무 많은 ROI가 나와서 NMS로 지웠음
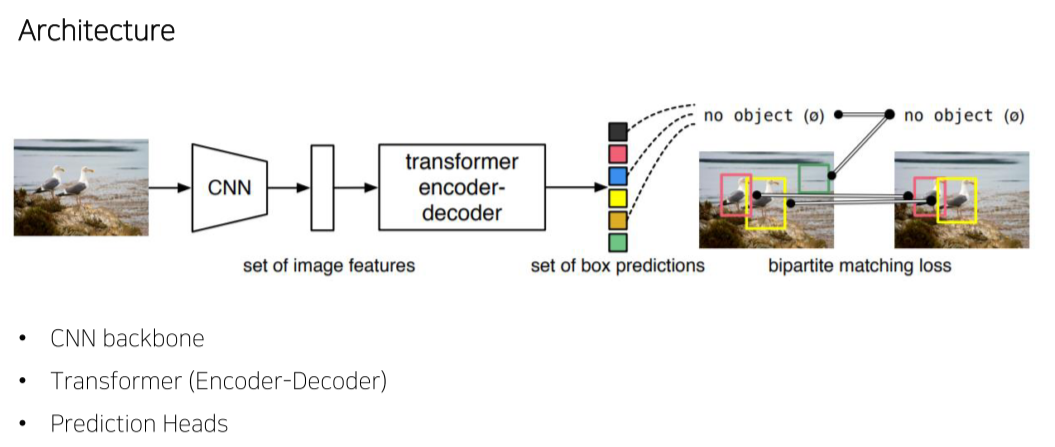
- 1-stage model
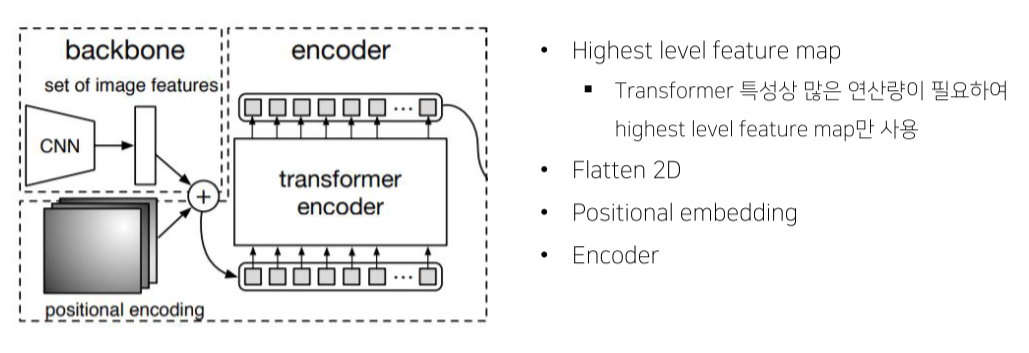
- 224 x 224 input image
- 7 x 7 feature map size
- 49 개의 feature vector 를 encoder 입력값으로 사용
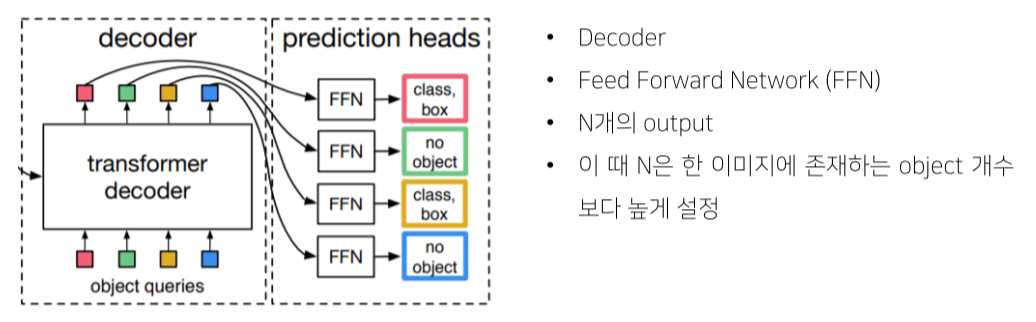
- Output vector의 word는 사람이 정함
- Output vector는 feed forward network를 통과해 class와 box를 예측

- 한 image당 output word의 갯수만큼 object가 예측됨
Swin Transformer


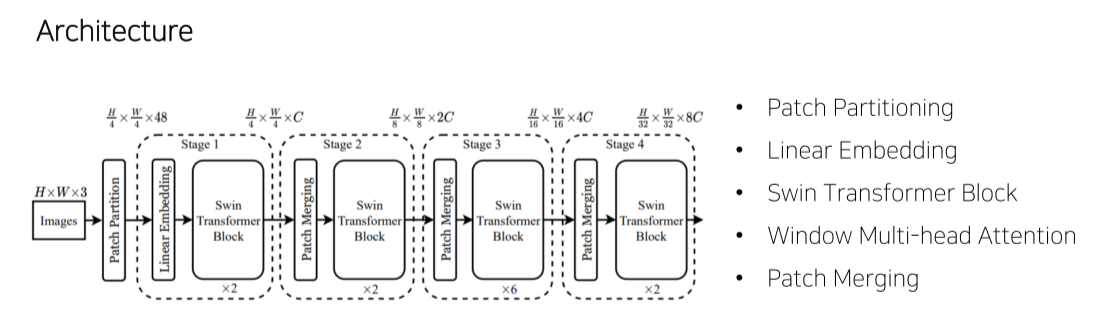
-
Transformer를 N개로 나눠 각 stage별로 transformer를 수행
-
stage를 넘어갈 때마다 feature map의 size를 줄임
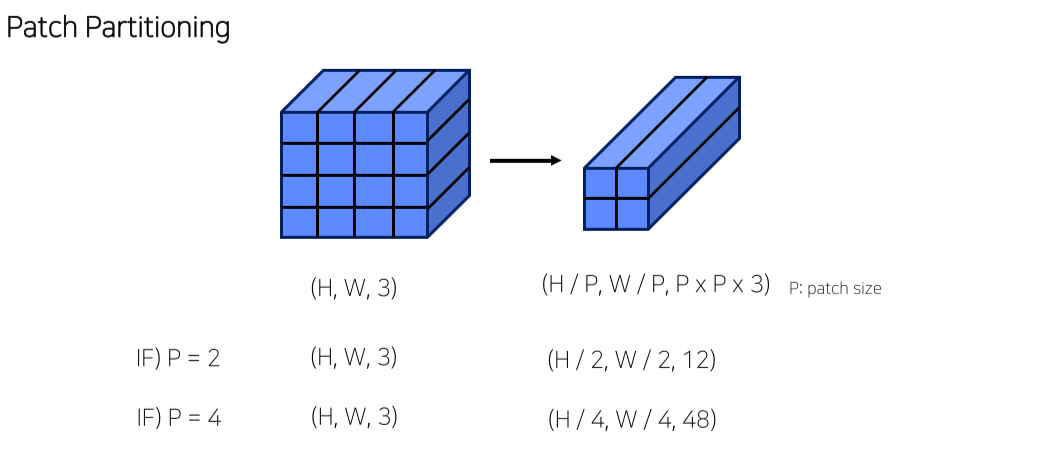
- image를 n개의 patch로 나눔
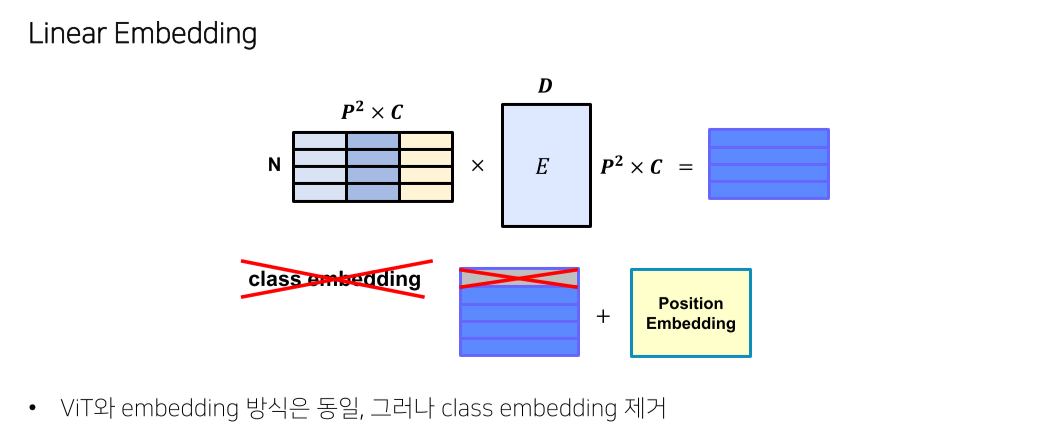
- Detection task라 class는 제거
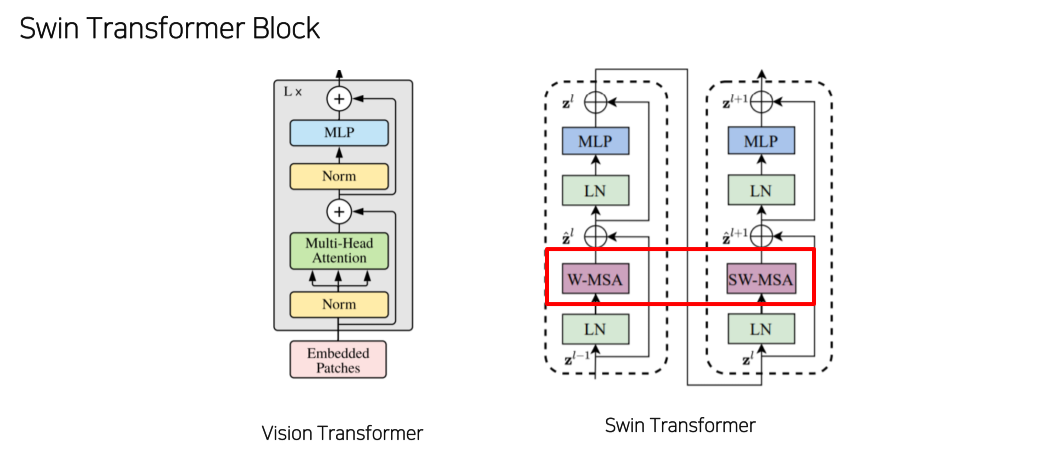
-
2개의 attention이 1개의 transformer로 묶임
-
Multi-head attention 대신 Window Multi-head self attention을 이용

- receptive field가 제한된다는 단점이 존재

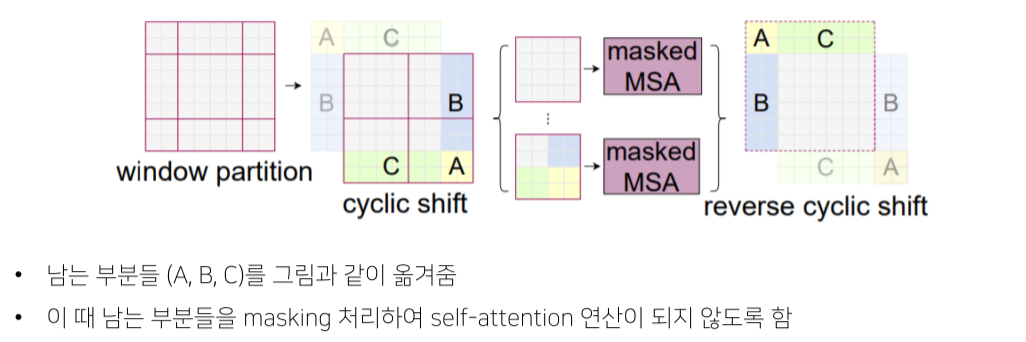
- Receptive field를 바꿔 W-MSA를 개선
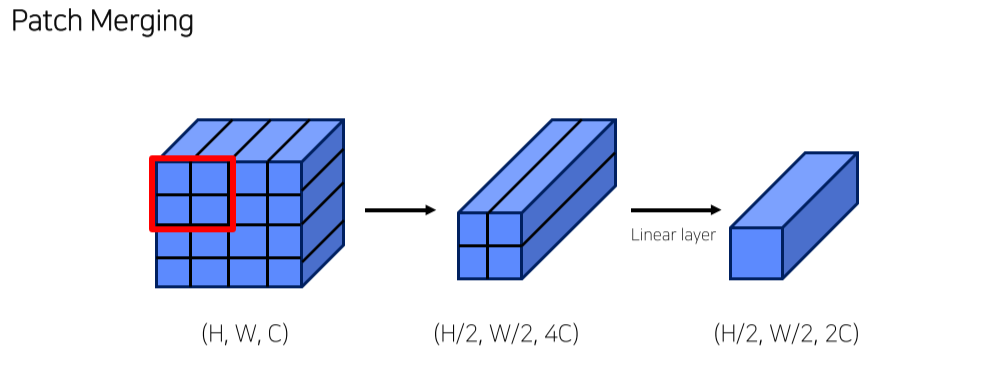
- Feature size를 줄이고 channel을 늘림

Reference
1) Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection”
2) Zhaowei Cai, Nuno Vasconcelos, “Cascade R-CNN: Delving into High Quality Object Detection”
3) David G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints”
4) Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, Yichen Wei, “Deformable Convolutional Networks”
5) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, “Attention Is All You Need”
6) Alexey Dosovitskiy, “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”
7) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko, “End-toEnd Object Detection with Transformers”
8) Ze Liu, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”
8강) Advanced Object Detection 2
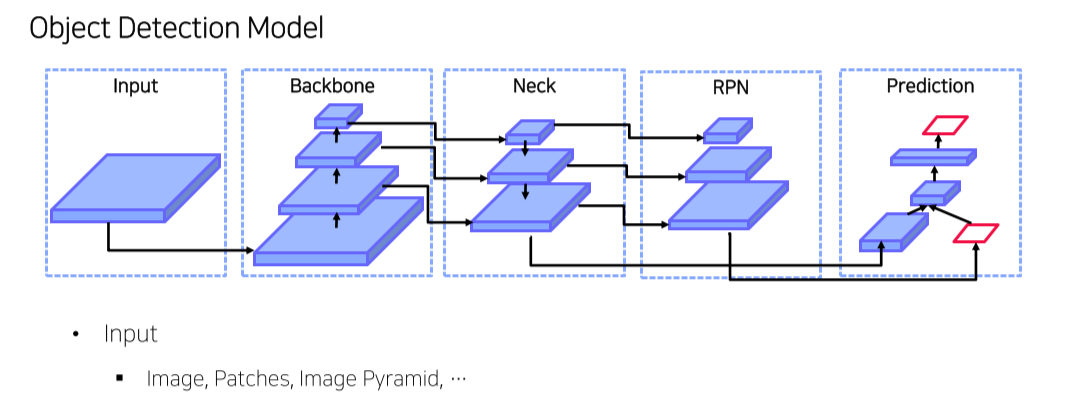
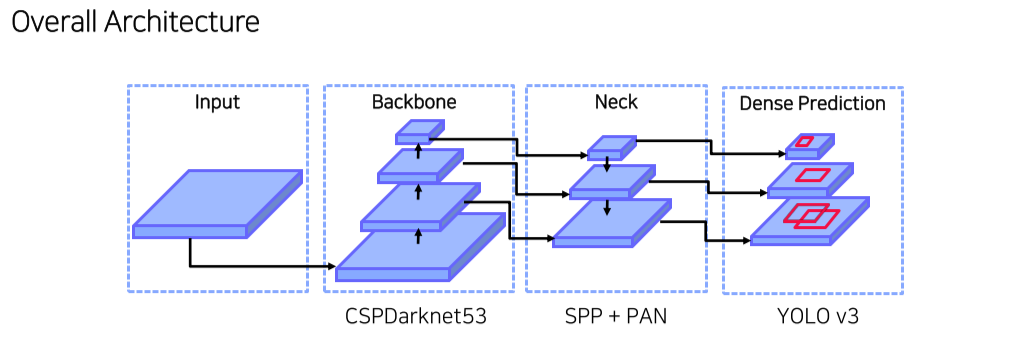
YOLO v4



- CPU 기반 model은 좀 더 경량화된 모델들


-
1-stage: RPN이 따로 없이 feature map의 각 pixel에 anchor box를 할당 후 바로 object의 class와 위치를 예측
-
2-stage: RPN이 feature map에서 object가 있을법한 위치를 추천해주면 이를 feature map에 projection한 뒤 ROI pooling을 통해 최종 class, box head에 vector를 넘겨줌
Bag of Freebies

-
Inference 비용을 늘리지 않고 정확도를 향상시키는 방법
-
Real time detection을 보장

- Cutout, cutmix, mixup 등

- Semantic Distribution Bias
- Hard negative mining: 어려운 배경을 강제로 batch에 더 많이 포함시키는 방법
- Focal loss: 어려운 예제는 gradient를 크게함
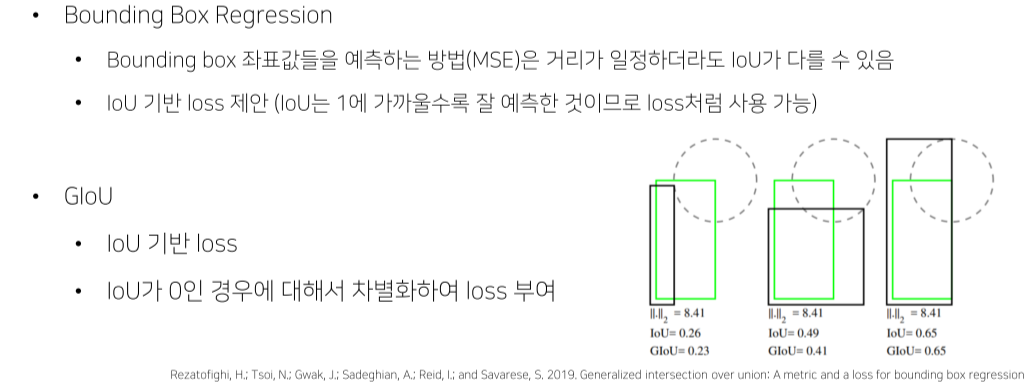
- Bbox끼리 멀수록 loss가 커야되는데 IOU는 하나도 안 겹치면 멀든 가깝든 다 0이기 때문에 이 부분을 고려
Bag of Specials

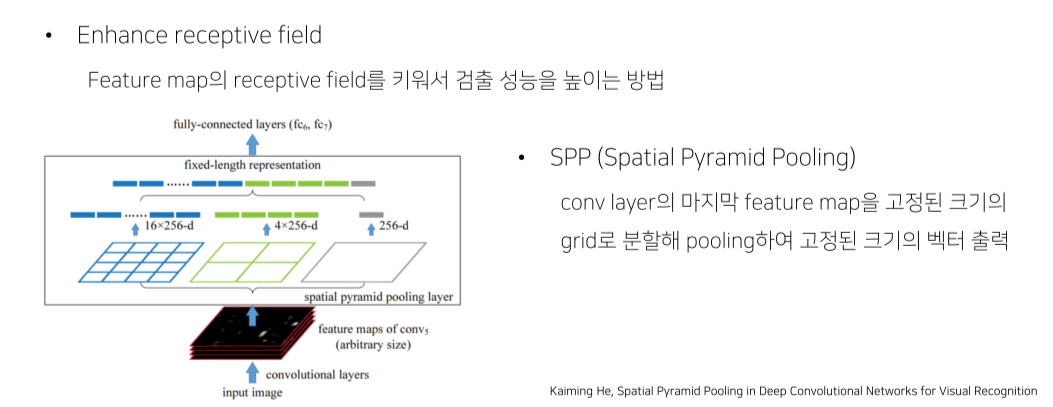
- SPP, ASPP, shifted window 등
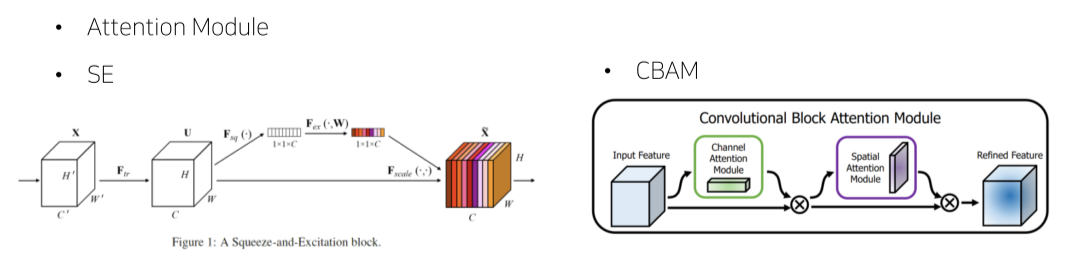
-
Global attention을 추가하는 방법
-
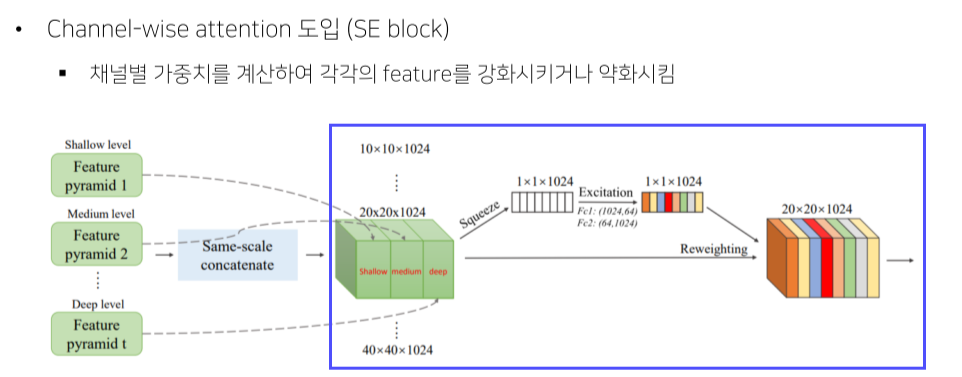
SE: feature map에 GAP 후 일련의 연산을 적용해 vector의 값이 0~1 사이가 나오게 함
이렇게 만들어진 feature map은 각 channel의 중요도를 나타냄
원래의 feature map과 곱해서 각 channel의 중요도를 반영 -
CBAM: channel에 spatial 정보를 추가해 중요한 channel에 집중할 수 있게 해줌
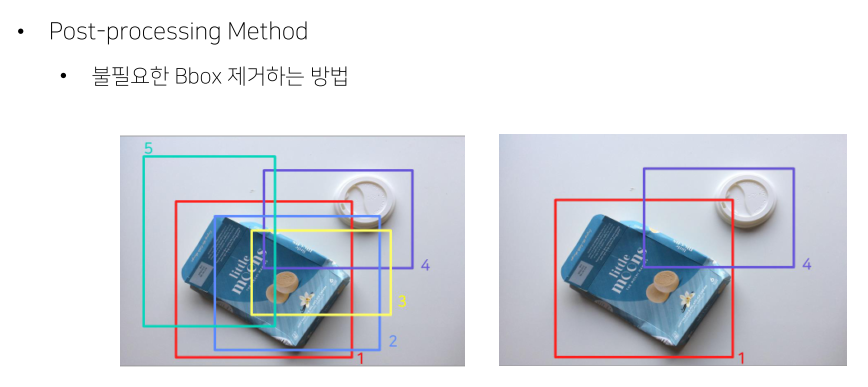


- backbone으로 Darknet에 CSPNet을 추가해서 사용
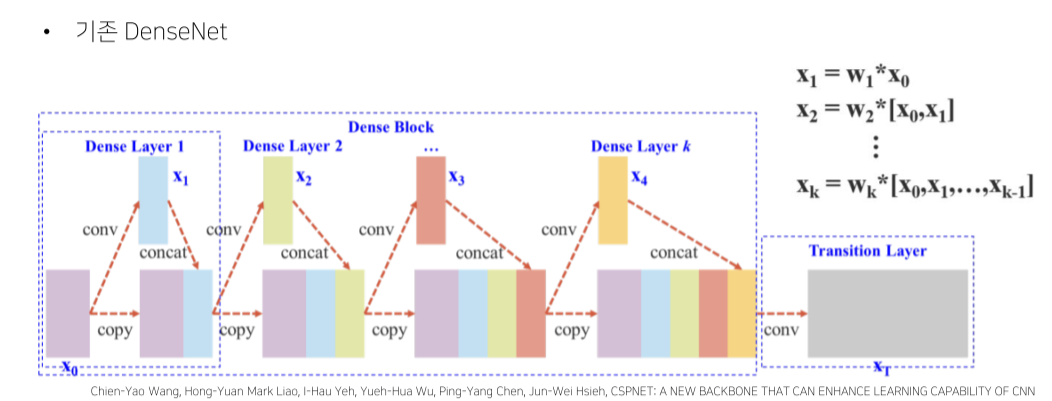
- DenseNet: eature map에 conv 연산을 해서 기존 feauture map에 channel dimension으로 concat

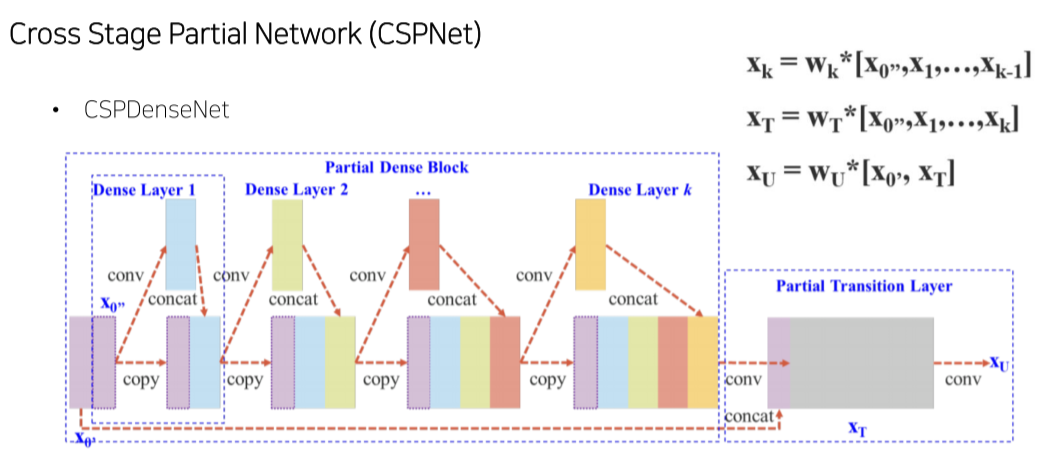
- CSPDenseNet: feature map의 일부만 사용

- Backbone을 크게 바꾸지 않고 적용이 가능해 유명한 model들의 성능을 향상시킬 수 있었다는 장점


-
Mosaic: cutmix는 2장을 합쳤던 반면 4장을 합쳐서 1개의 input으로 4개의 image를 볼 수 있어서 batch size가 커지는 효과
-
Self-Adversarial Training: 일부로 object를 제외한 image를 만들어 오작동을 유도
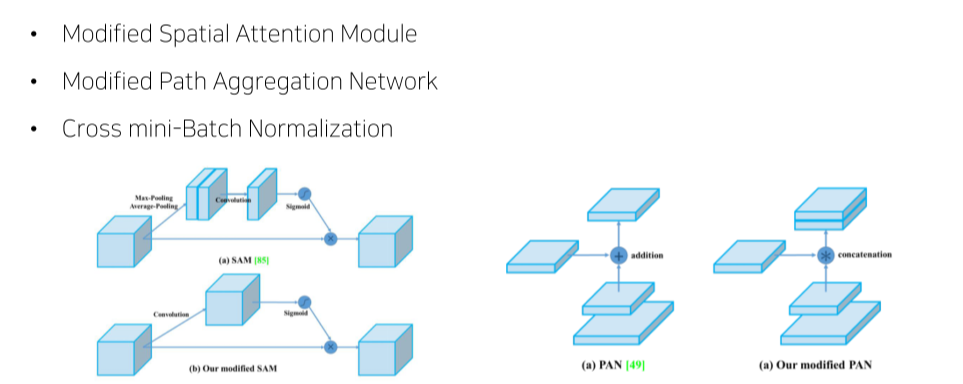
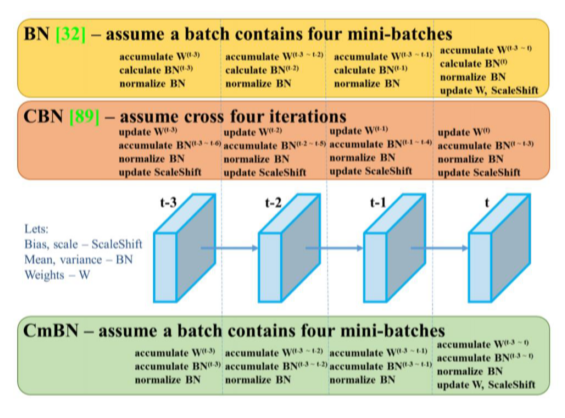
- Cross mini-Batch Normalization: 각 batch에서 BN을 계산하는 것이 아니라 accumulate해서 batch size가 커지는 효과

- 주의) YOLOv4의 실험은 해당 dataset과 model에만 적용되는 내용으로, 모든 detection task에 일반화 된다고 보기는 어려움
M2DET


- FPN이 single-level이라 갖는 한계
- object의 다양한 크기에 대응하기 위해 multi-scale feature pyramid를 이용했지만,
- object의 shape(외형, 복잡도)에 대해선 대응하지 못함
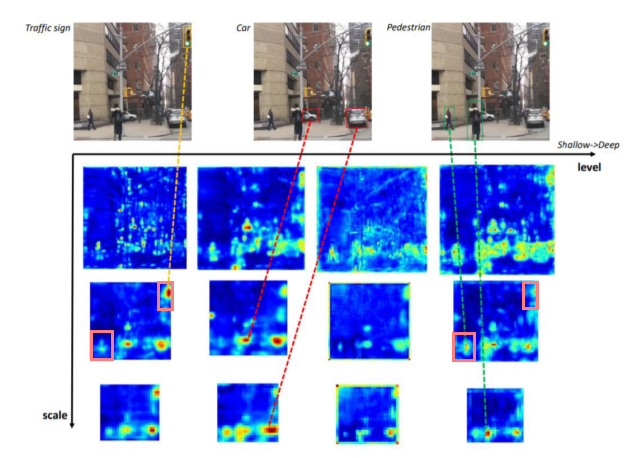
- Shallow stage(level)에서는 복잡한 object를 포착하지 못함

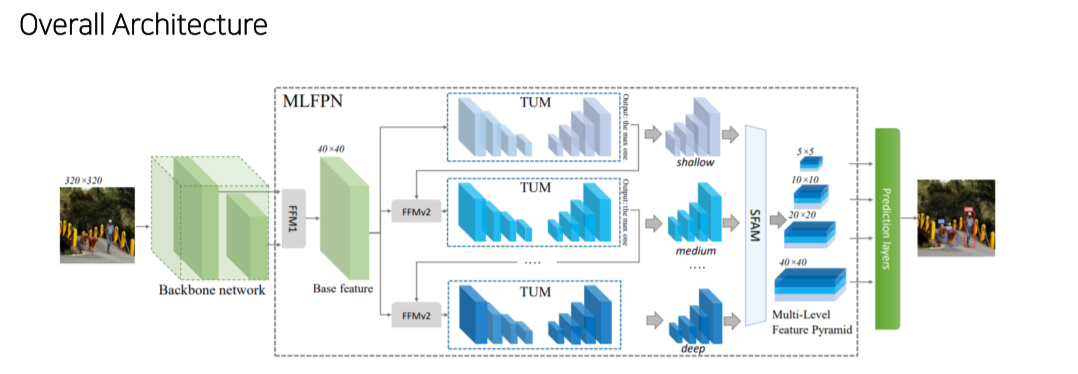
- 크게 backbone, MLFPN, SSD로 구성
- MLFPN은 FFM, TUM, SFAM으로 구성
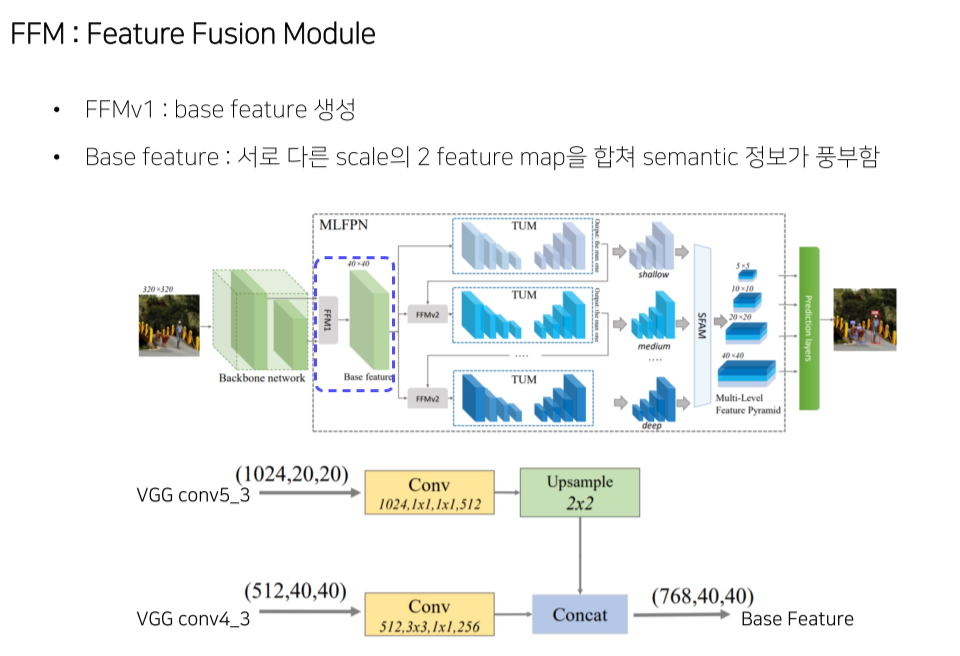
- FFM1: backbone에서 2개 feature map를 골라 concat해서 base feature map을 만듬
- TUM: unit encoder/decoder로 구성
Decoder의 결과는 multi-scale image
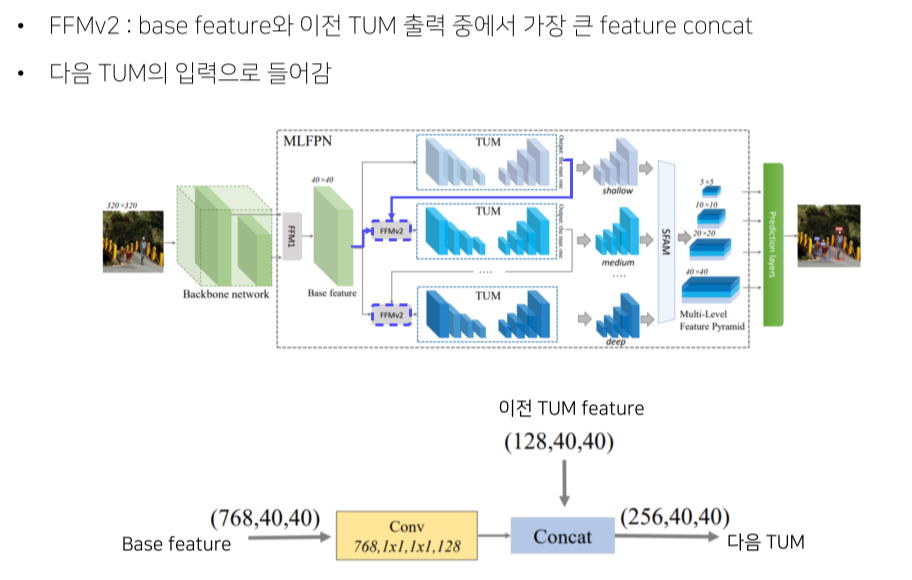
각 TUM의 결과는 각 level별 image - FFMv2: 이전 레벨의 가장 큰 feature map을 base feature map과 concat해서 TUM에 넣어줌
- SFAM: TUM의 결과를 적절하게 concat
- SSD: SFAM의 결과에 attention을 가해 feature map을 만들고 최종 image를 만듬
- MLFPN은 FFM, TUM, SFAM으로 구성
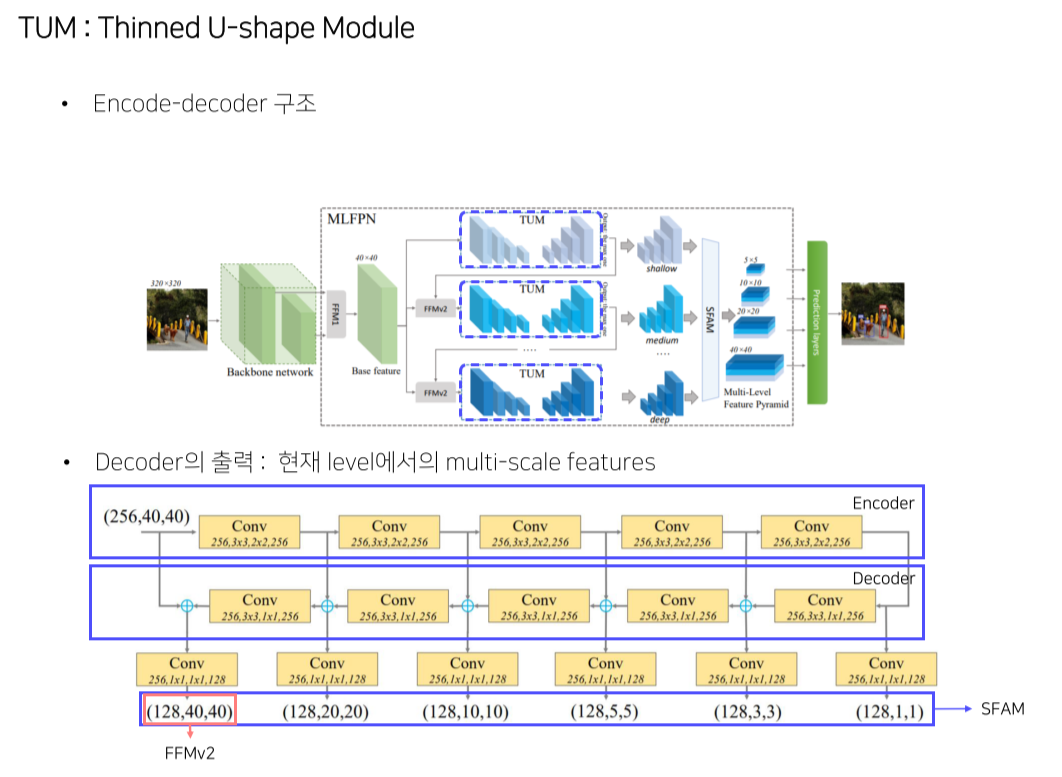
-
가장 큰 feature map은 다음 TUM의 입력으로 들어감
-
N개의 level에서 feature map을 추출해서 multi-level, 각 level에서 scale이 다양하기 때문에 multi-scale
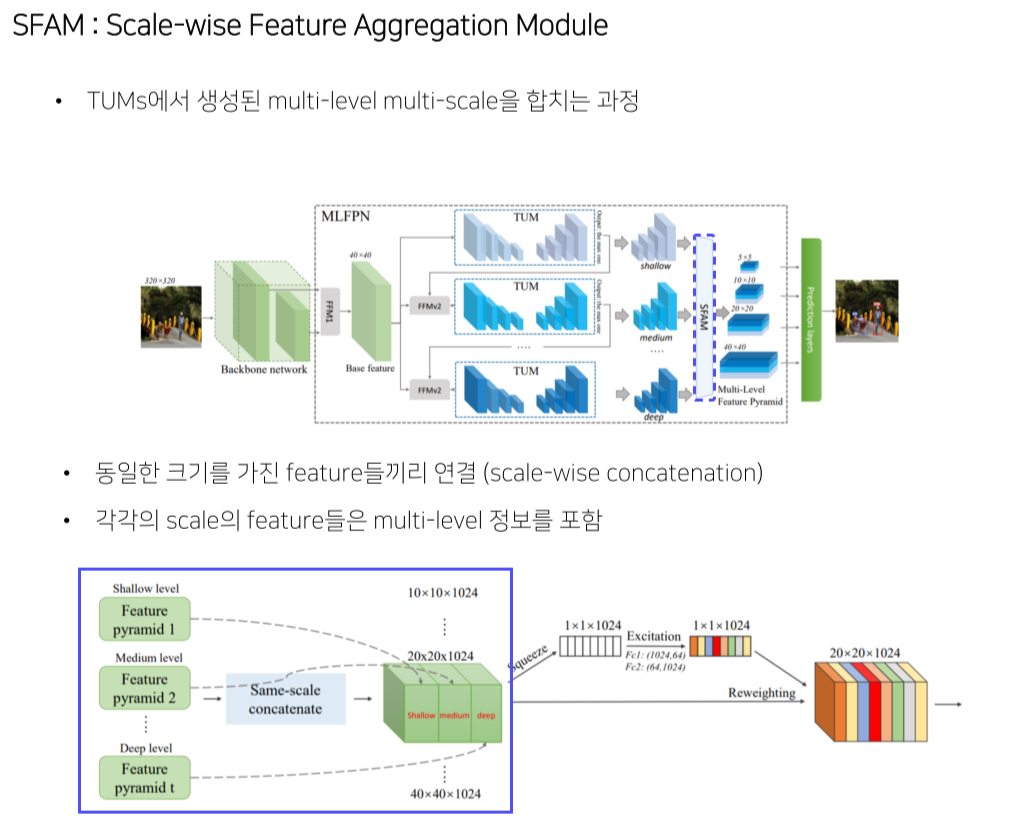
- 동일한 scale별로 concat해서 각 scale에서는 multi-level의 형태를 지니고 있음
- 이미 여러 scale의 feature map이 있어서 extra feature layer를 만들기 위한 계산이 필요x

CornerNet
Anchor-free model

- Feature map의 각 pixel마다 n개의 anchor box가 생성되는데 대부분은 background --> class imbalance

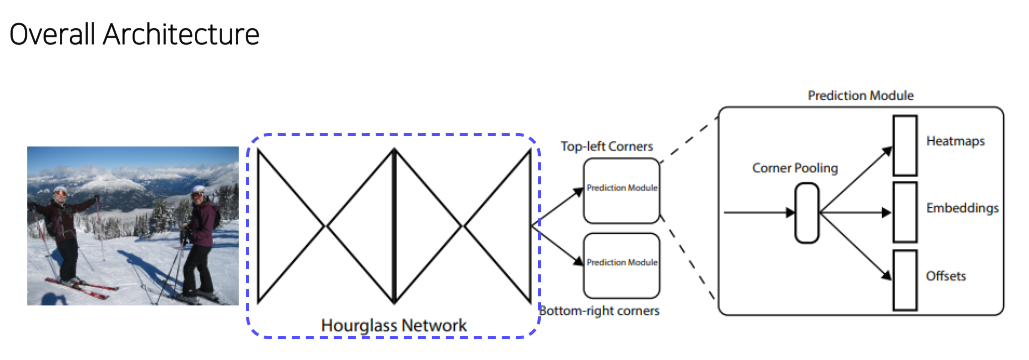
- Hourglass network로 feature map이 나와서 2개의 prediction head를 통과

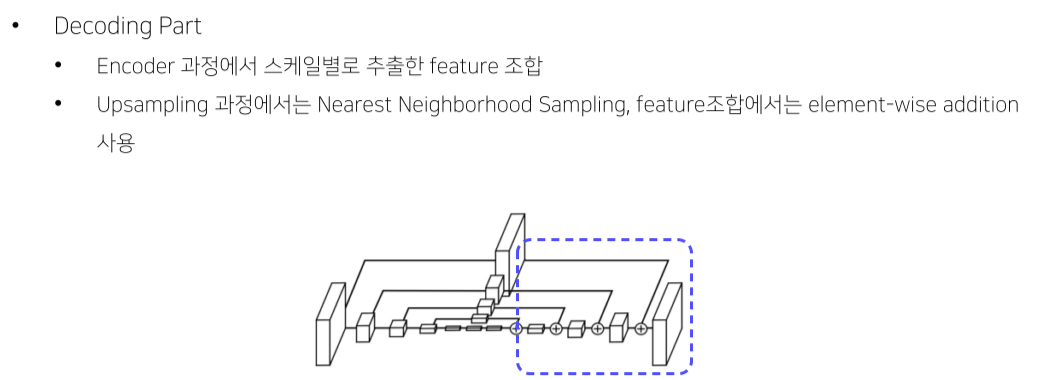
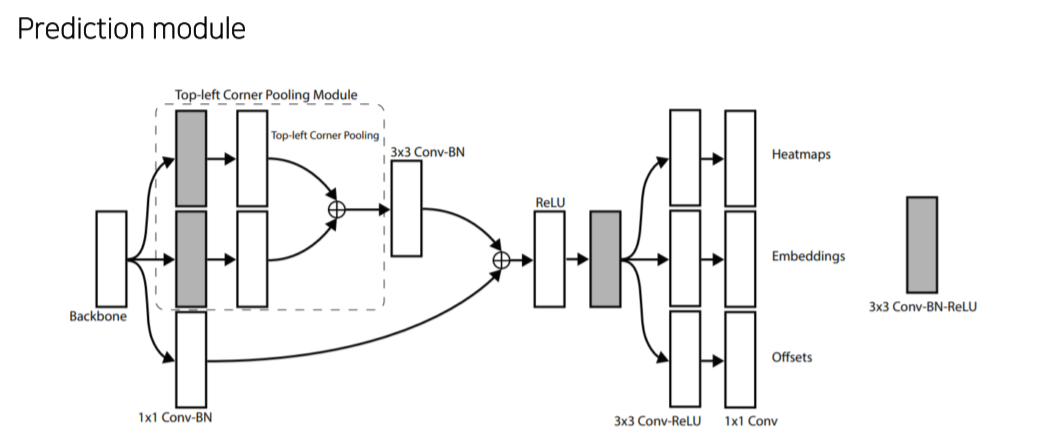
-
Backbone으로부터 top-left나 bottom-right를 예측
-
top-left, bottom-right의 mapping을 위해 embedding이 필요

Reference
1) Hoya012, https://hoya012.github.io/
2) https://herbwood.tistory.com
3) https://arxiv.org/pdf/2004.10934.pdf (YOLOv4: Optimal Speed and Accuracy of Object Detection)
4) https://arxiv.org/pdf/1911.11929.pdf (CSPNet: A New Backbone that can Enhance Learning Capability of CNN)
5) https://arxiv.org/pdf/1905.04899.pdf (CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features) 6) https://arxiv.org/pdf/1810.12890.pdf (DropBlock: A regularization method for convolutional networks)
7) https://arxiv.org/pdf/1811.04533.pdf (M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network)
8) https://arxiv.org/pdf/1808.01244.pdf (CornerNet: Detecting Objects as Paired Keypoints)
9) https://arxiv.org/pdf/1904.08189.pdf (CenterNet: Keypoint Triplets for Object Detection)
10) https://arxiv.org/pdf/1904.01355.pdf (FCOS: Fully Convolutional One-Stage Object Detection)
11) https://giou.stanford.edu/GIoU.pdf (Generalized intersection over union: A metric and a loss for bounding box regression)
12) https://arxiv.org/pdf/1406.4729.pdf (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
13) https://arxiv.org/pdf/1807.06521.pdf (Cbam: Convolutional block attention module)
14) https://arxiv.org/pdf/1612.03144.pdf (Feature Pyramid Networks for Object Detection)
15) https://arxiv.org/vc/arxiv/papers/1908/1908.08681v2.pdf (Mish: A Self Regularized Non-Monotonic Neural Activation Function)
9강) Ready for Competition
Review
- 1강
- mAP
- mAP가 어떻게 계산될 수 있는지 완벽하게 이해하고 있는가?
- 2강
- 2 Stage detectors: RCNN, SPP, FastRCNN, FasterRCNN
- SPP(RoI Pooling)에 대해 완벽하게 이해하고 있는가?
- RoI projection에 대해 완벽하게 이해할 수 있는가?
- Faster RCNN중 RPN에 대해 완벽하게 이해하고 있는가?
- Anchorbox에 이해하고 있는가?
- RPN의 역할에 대해 이해하고 있는가?
- Anchorbox에 이해하고 있는가?
- 3강
- Library: MMDetection, Detectron2
- MMDetection이든 Detectron2이든 Scratch든 새로운 모델에 대해 코드를 짤 수 있는가?
- 4강
- Neck module: FPN, PANet, RFP, BiFPN, NasFPN, AugFPN
- Neck의 역할에 대해 완벽하게 이해하고 있는가?
- FPN, PANet에 대해 완벽하게 이해하고 있는가?
- 5강
- Yolo, SSD, RetinaNet
- 2 stage와는 다르게 RPN이 없는 1 stage에서 어떻게 박스를 예측하는지 이해하고 있는가?
- Yolo v1에 대해 완벽하게 이해하고 있는가?
- 6강
- EfficientDet
- EfficientDet의 등장 배경 및 Compound scaling의 중요성에 대해 설명할 수 있는가?
- 7강
- Cascade, Deformable, Transformer
- Cascade, Deformable, Swin에 대해 설명할 수 있는가?
- 8강
- Yolov4, M2Det, CornerNet
- M2Det에 대해 설명할 수 있는가?
Competition
Metric

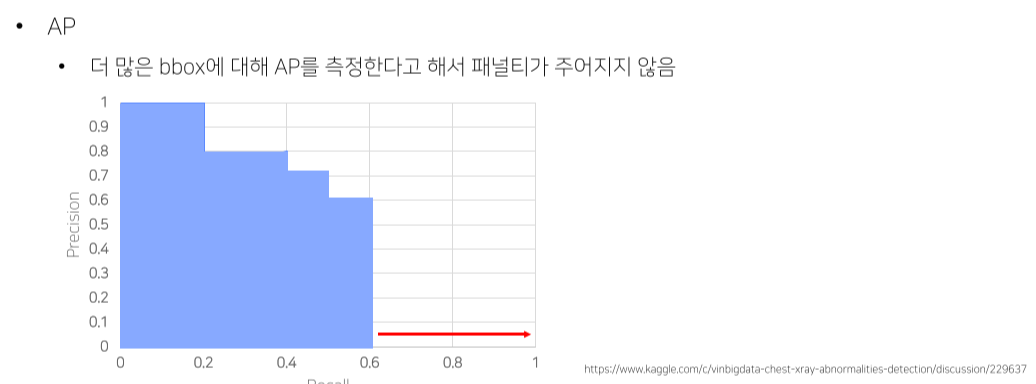
- 틀려도 성능 하락은 없는데, 그 중 1개라도 맞추면 성능은 올라가기 때문에 생기는 trick
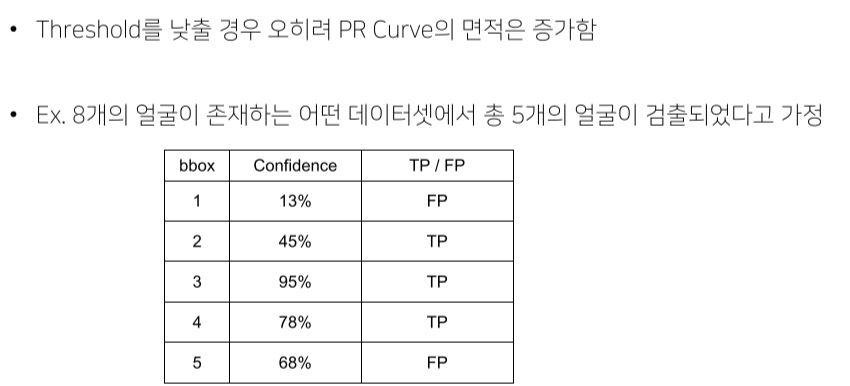
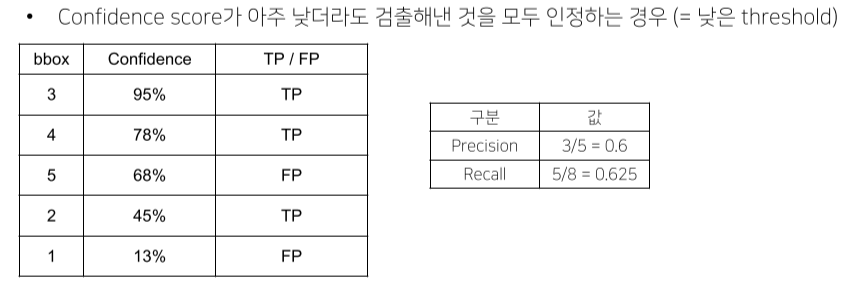
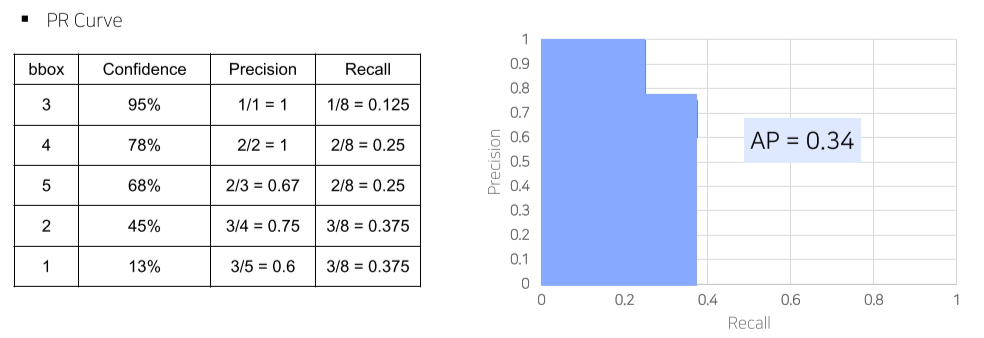
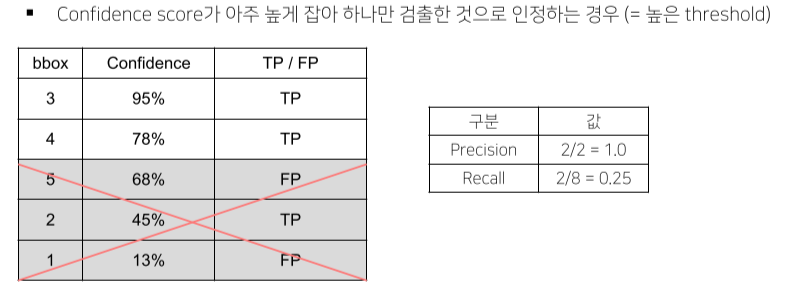
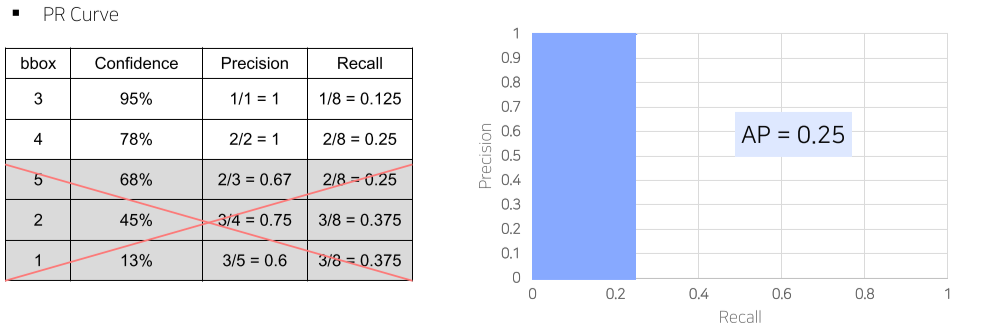

-
실제 연구에서는 대부분 0.05를 threshold로 mAP 평가
-
적용하는 분야의 특징에 따라 threshold나 평가 metric을 설정하는 것이 좋음
Pipeline

- 베이스라인의 대부분은 cross validation 구축하는데 시간이 걸림
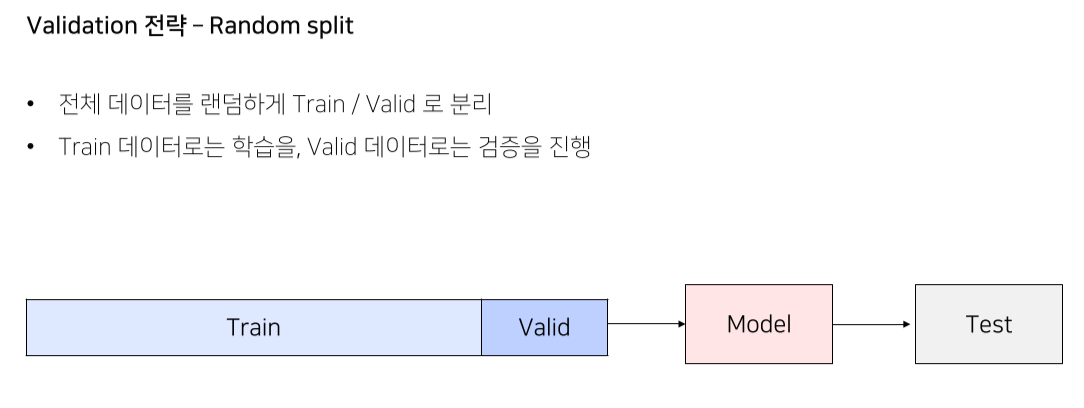
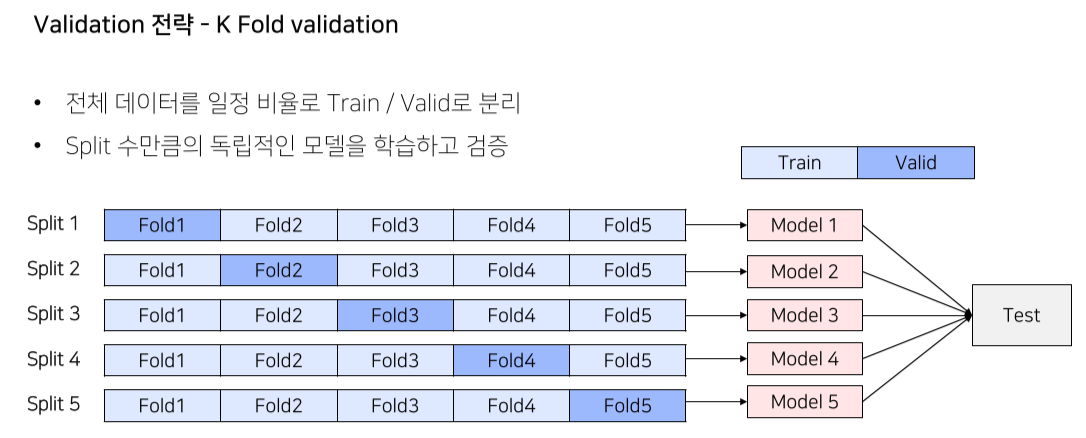
Validation set

성능올리기 위한 방법들

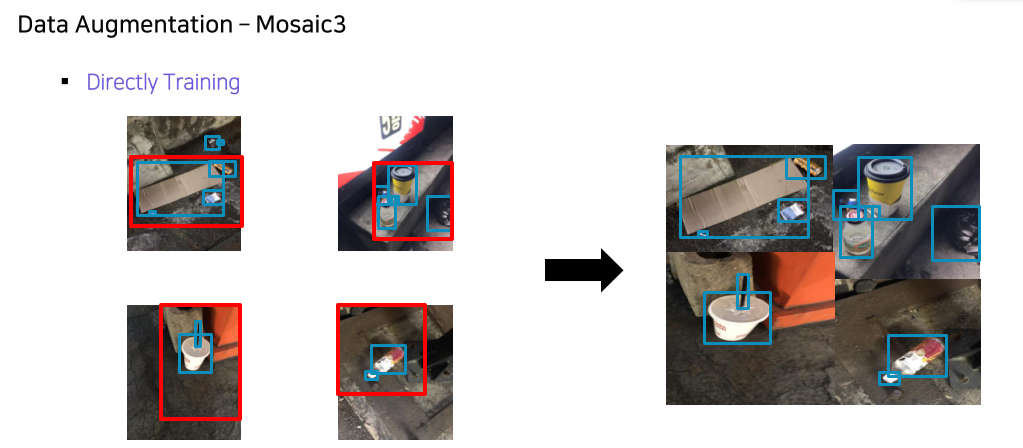
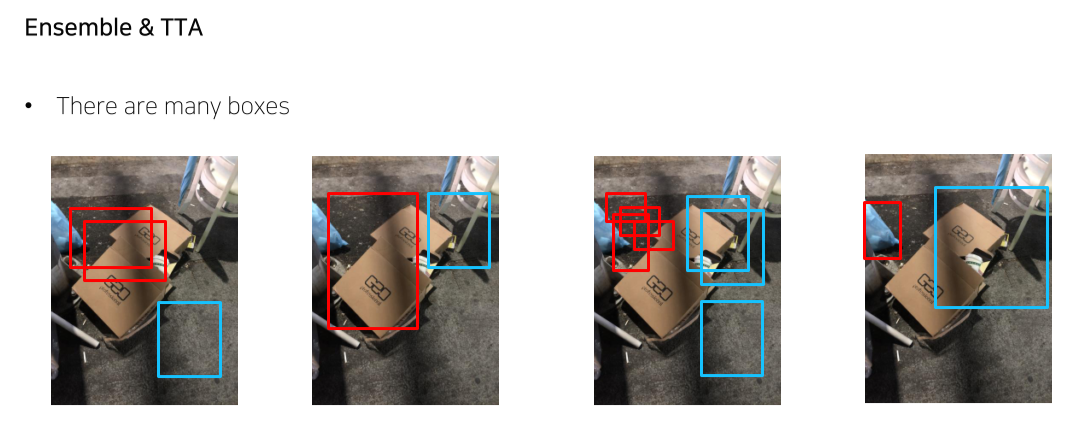
- 가장 높은 성능을 낼 수 있는 방법

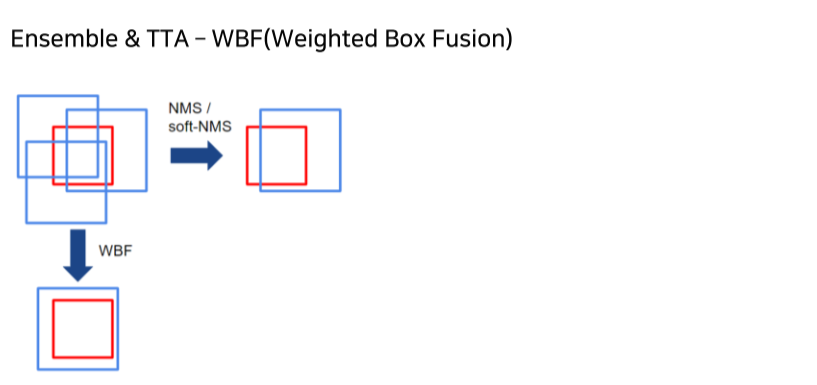
- NMS는 box의 위치가 바뀌지 않는 반면 WBF는 box의 위치가 바뀜

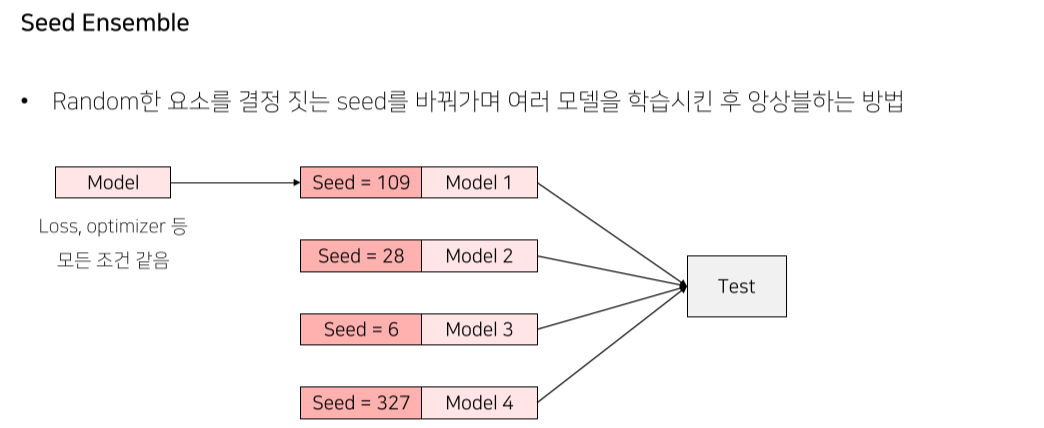

- 다양성이 추가될수록 더 robust해짐

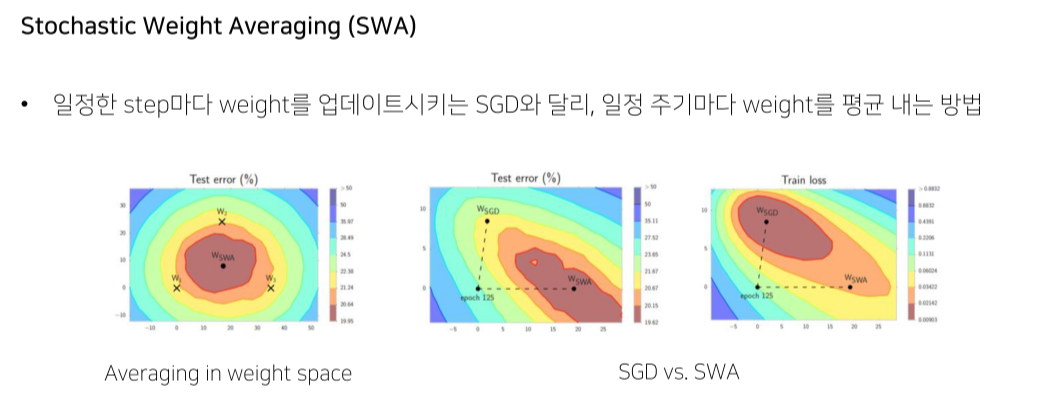
- local minima에 빠진 model의 빠졌을 때의 epoch을 기반으로 ensemble
Competition으로 성장하는 법
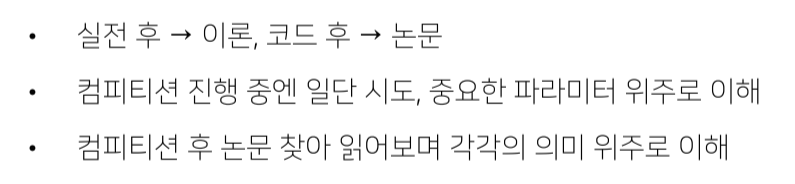
-
일단 시도 후 huristic하게 이해
-
Competition에서 model에 대해 단편단편적으로 이해한 것을 나중에 합쳐서 내것으로 만드는 것이 중요
Reference
1) https://www.kaggle.com/c/vinbigdata-chest-xray-abnormalities-detection/discussion/229637
2) https://github.com/albumentations-team/albumentations
3) Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo, “CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features”
4) Navaneeth Bodla, Bharat Singh, Rama Chellappa, Larry S. Davis, “Soft-NMS -- Improving Object Detection With One Line of Code” 5) Roman Solovyev, Weimin Wang, Tatiana Gabruseva, “Weighted boxes fusion: Ensembling boxes from different object detection models”
6) Izmailov, P. et al., “Averaging Weights Leads to Wider Optima and Better Generalization”
10강) Object Detection in Kaggle
Object detection 대회 소개
pdf를 참고할 것
