0. Abstract
LoRA는 PEFT(Parameter Effecient Fine-Tuning)의 기법 중 하나이다. Pre-trained model의 weight는 고정한 채로, 몇 개의 dense(fc) layer만 학습시켜 downstream task의 연산량을 줄일 수 있다. GPT-3을 기준으로 parameter는 10000배, GPU 메모리는 3배를 줄일 수 있다. 또한 inference 과정에서 추가적인 latency가 없음
- PEFT: 모델의 모든 파라미터를 튜닝하는 것이 아닌 일부 파라미터만을 튜닝함으로써 모델의 성능을 적은 자원으로도 높게 유지하는 방법론
- Downstream task: pre-trained model을 사용해, 어떤 문제를 해결하기 위해 fine-tuning 하는것
- Upstream task: Pre-train model을 학습시키는것
- Latency: 어떤 요청의 시작부터 완료까지 걸리는 시간
1. Introduction
LLM은 기본적으로 pre-trained model을 특정 task에 맞게 fine-tuning을 시킴. 하지만 fine-tuning에서 모든 weight를 다시 학습시키면 GPT-2, GPT-3, RoBERTa 등 큰 모델의 경우 학습에 몇 달이 걸림.
이전 연구에서 over-parameterized model들은 low intrinsic dimension에 기반하고 있다는 사실에 기반해, 저자는 학습 과정에서도 모델은 low intrinsic rank을 갖고 있을 것이라 가정함.
LoRA는 기존 pre-trained weight는 고정하고, 몇 개의 dense layer만 rank decomposition matrices를 최적화하는 방식으로 학습시키기로 함.
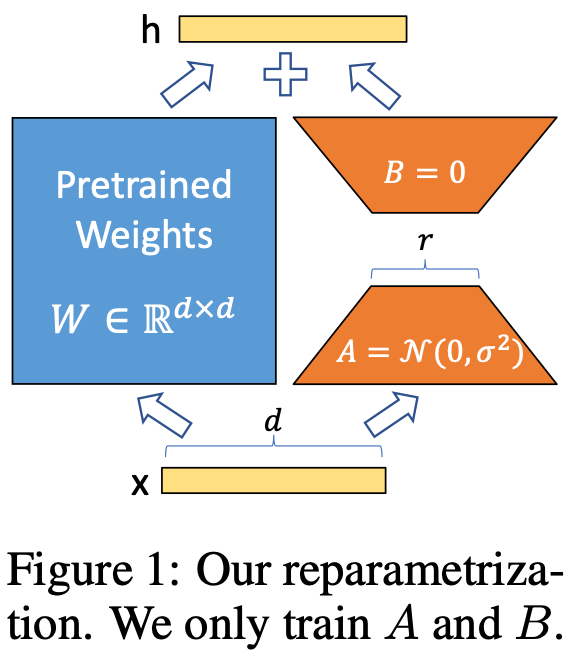
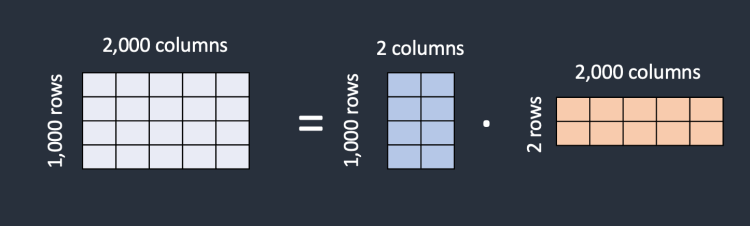
위 그림처럼 기존 pre-trained weight 는 고정하고 low rank decomposition된 weight 만 학습시켜 에 더해줌. 의 크기는 보다 작아 time, computational cost를 최대 3배까지 줄일 수 있음. 또한 task에 따라 LoRA module()만 바꿔주면 되기 때문에 storage requirement, task-switching overhead를 줄일 수 있음. 이 외에도 추가적인 inference latency가 없다, 다른 기법들과 함께 적용이 가능하다는 장점이 있음.
1.1. Terminologies and Conventions
- : Transformer의 input/output dimension size
- : Self-attention module의 query/key/value/output projection matrices
- : Pre-trained weight
- : Adaptation 중 accumulated된 gradient update
- : LoRA module의 rank
- 이전 연구의 convention을 사용하고 optimizer는 Adam을 이용
- Transformer MLP feedforward dimension
2. Problem Statement
LoRA는 agnostic하지만 본 논문에서는 language model에 집중함.
- agnostic: model에 구애받지 않고 해석이 가능함
- : 로 parameterized된 pre-trained model
- : context-target쌍으로 된 학습 데이터셋, 는 token sequence
Fine-tuning 과정에서 model은 으로 init.되고 objective를 maximize하기 위해 로 업데이트됨. 각 downstream task를 위해 매번 와 같은 크기의 를 학습해 엄청난 cost가 발생.
반면 위와 같은 LoRA 방식으로 fine-tuning할 경우 전체가 아니라 그보다 작은 를 찾아내는 방식으로 바뀌기 때문에 compute-/memory-effecient해짐. 는 최대 의 0.01%까지 작아질 수 있음.
3. Aren't Existing Solutions Good Enough?
기존에도 transfer learning에서 parameter-/compute-effecient를 위한 방법은 몇 가지가 있었음.
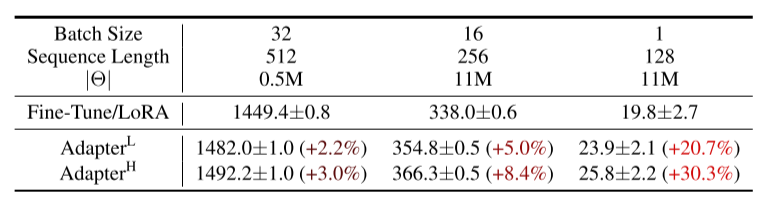
하지만 adapter layer를 추가하는 방식은 hardware parellelism이 없다면 작은 bottleneck layer만 추가해도 latency가 상당히 증가해 사용하기 어려웠음.
Prefix tuning은 optimize가 어려웠음.
4. Our Method
4.1. Low-Rank-Parameterized Update Matrices
는 고정하고 만 학습. 이후 와 는 같은 input 에 곱해진 후 output vector끼리 coordinate-wise하게 sum.
는 random Gaussian init., 는 zero-init.이라 또한 처음에는 zero-init. 는 로 scaling됨. 는 learning rate처럼 tuning해서 r과 같은 값으로 설정. 실제 코드에서는 보통 는 (8, 16)이나 (16,32)를 사용한다고 함.
...
# Actual trainable parameters
# define A, B
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
# initialize A, B
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
# pre-trained weight W_0 * x
result = nn.Embedding.forward(self, x)
if self.r > 0:
# BA * x
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
# W_0x + BAx
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
4.1.1. No Additional Inference Latency
LoRA를 이용하면 inference시 latency 성능 하락이 없음. 또한 다른 task에 사용할 경우엔 만 제외하고 로 학습한 다른 만 추가하면 되기 때문에 memory overhead가 낮음.
4.2. Applying LoRA to Transformer
본 논문에서는 trainable weight를 최소화하기 위해 LoRA를 attention weight만 적용하고 MLP module은 고정함. 이를 통해 GPT-3 175B를 기준으로 VRAM은 1.2TB에서 350GB, checkpoint size는 350GB에서 35MB로 줄임. 또한 학습 속도 또한 25% 정도 빨라짐.
5.Empirical Experiments
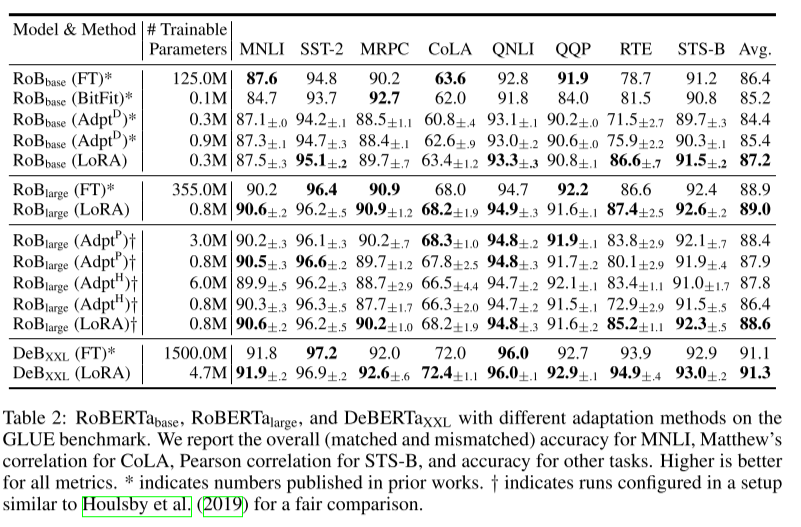
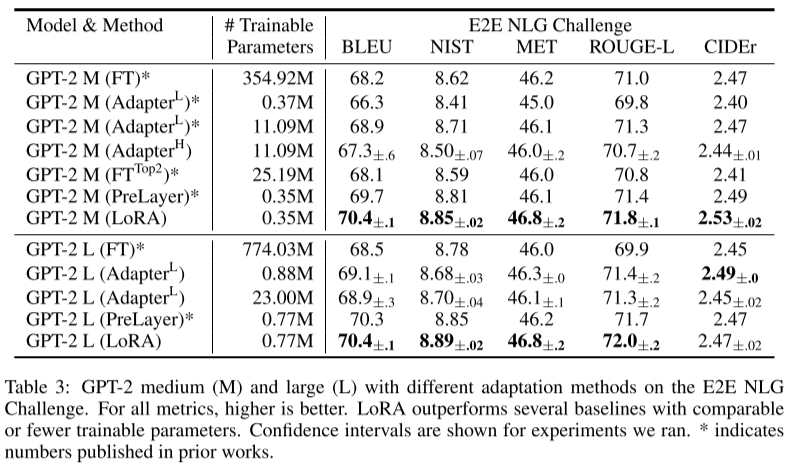
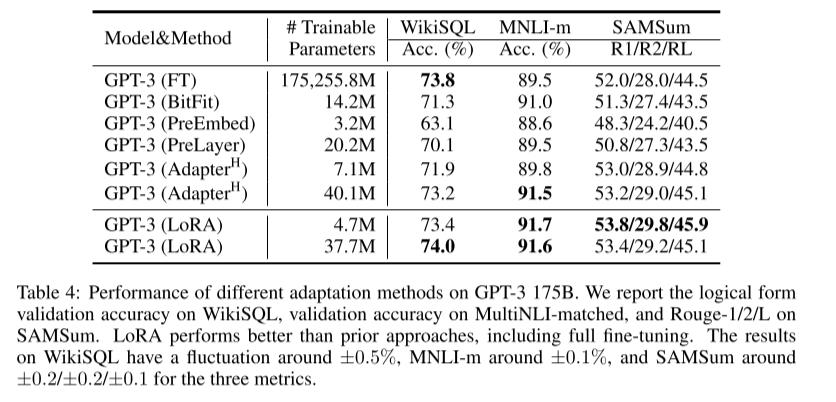
대부분의 경우에서 성능이 좋음
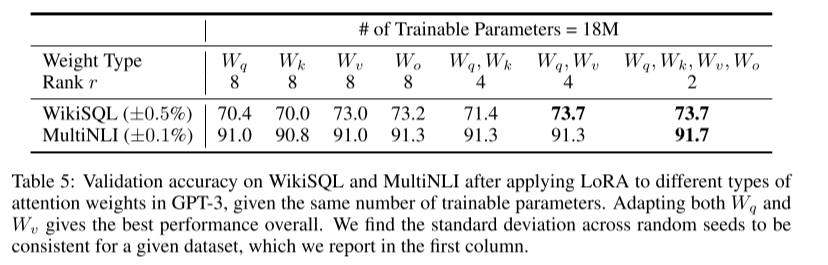
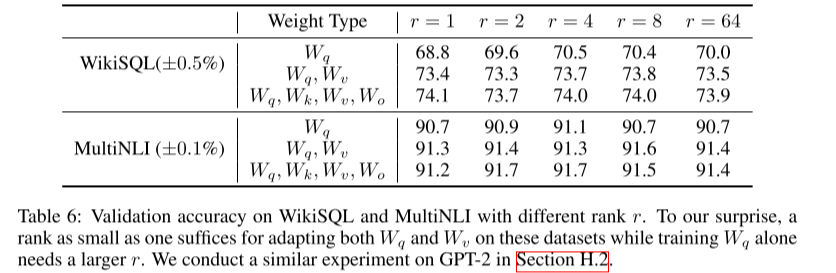
Transformer에서 한 projection matrix에 큰 r을 적용하는 것보다 모든 matrices에 작은 r을 적용하는 것이 더 성능이 좋았음.
+a) IA3
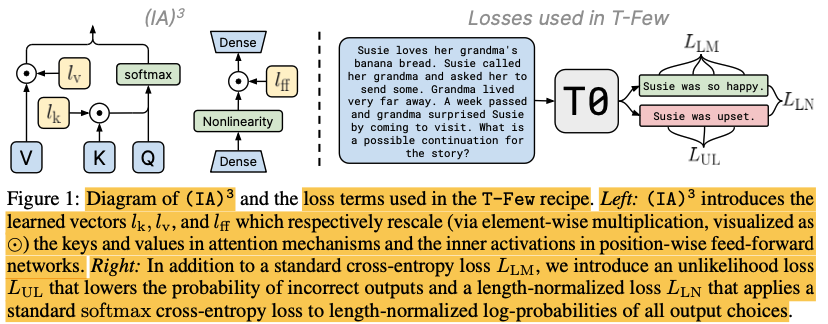
뉴럴네트워크의 Inner Activation을 줄이기도하고 늘리기도하는 어댑터를 중간에 삽입하는 방법론. 기존에 공개된 LoRA보다 적은 파라미터를 사용하면서 높은 성능을 내는 것으로 알려져있으며, GPT-3를 in-context learning 했을때 보다도 성능이 좋다 라고 주장하고 있음. 학습시간도 매우 짧아 A100 GPU 하나로 30분만에 튜닝할 수 있었다고 함.
+aa) LoRA 사용법
loralib설치
pip install loralib
# Alternatively
# pip install git+https://github.com/microsoft/LoRA- 기존
nn.Linear,nn.Embedding,nn.Conv2d를lora.~로 대체
# ===== Before =====
# layer = nn.Linear(in_features, out_features)
# ===== After ======
import loralib as lora
# Add a pair of low-rank adaptation matrices with rank r=16
layer = lora.Linear(in_features, out_features, r=16)- 학습 전, lora parameter만 학습 가능하게 설정
import loralib as lora
model = BigModel()
# This sets requires_grad to False for all parameters without the string "lora_" in their names
lora.mark_only_lora_as_trainable(model)
# Training loop
for batch in dataloader:
...- checkpoint를 저장할 때엔
state_dict가 LoRA parameter만 저장하게 함.
# ===== Before =====
# torch.save(model.state_dict(), checkpoint_path)
# ===== After =====
torch.save(lora.lora_state_dict(model), checkpoint_path)- checkpoint를 불러올 때엔
load_state_dict에서strict=False로 설정.
# Load the pretrained checkpoint first
model.load_state_dict(torch.load('ckpt_pretrained.pt'), strict=False)
# Then load the LoRA checkpoint
model.load_state_dict(torch.load('ckpt_lora.pt'), strict=False)Reference
