
AI를 사용해서 AI로 생성된 이미지를 판별하는게 생각보다 쉽지 않음.. 이번 논문은 작년 11월에 CVPR에 올라온 논문으로 기존 논문에서 제시한 방법들이 효과적인지 검증해보는 review paper에 가깝다. 무려 데이터셋이랑 코드도 공식으로 제공되고 있음. 이 논문을 시작으로 다른 방법들도 조사하고 구현해봐야될듯.
0. Abstract
지난 10년 동안 GAN과 더 최근에는 diffusion model과 같은 방법을 통해 synthetic media를 만드는 데 상당한 진전이 있었음. DM은 TTV(text-to-visual)생성을 가능하게 하여 다양한 분야에서 악의적인 공격에 사용될 수 있음. 이 연구는 DM에 의해 생성된 synthetic 이미지를 실제 이미지와 구별하는 것이 얼마나 어려운지 이해하고 소셜 네트워크에서 이미지 압축 및 크기 조정이 포함된 어려운 시나리오에서 현재 detector의 작업 적합성을 평가하는 것을 목표로 함.
1. Introduction

DM을 이용한 합성 미디어는 photorealistic하기 때문에 쓰임새가 많지만 오용되기도 쉬움. 이를 방지하기 위해 다양한 연구 방법이 나왔음
- 이미지의 그림자나 반사된 이미지 상의 asymmetry를 찾는 방법
- 이후 명암, 빛 등 global semmantic inconsistency를 찾는 방법까지 발전
- 하지만 GAN, DM의 발달로 inconsistency를 찾기 어려워짐
- 최근 SOTA detector들은 인간의 눈에 보이지 않는 영역을 탐색함
- Synthetic visual data는 생성 단계에서 spatial-domain에 필연적으로 특정 trace를 남김
- 생성 architecture마다 고유한 trace가 다름
- 또한 GAN은 upsampling 과정에서 frequency-domain에서 특정 spectral peak를 남김
하지만 StyleGAN3 같은 정교한 architecture가 나옴에 따라 SOTA detector도 trace를 찾기 어려워짐 + trace가 너무 빈약해 이미지에 조금만 손상(resize 등)이 가도 성능이 떨어짐.
최근(2022) NVIDIA에서 StyleGAN3 이미지를 판별하는 대회에서 긍정적인 결과가 나왔으나 이는 ideal한 환경에서 실험됨. 본 연구는 DM generated image의 artifact도 GAN과 같은지, 현 SOTA detector들이 어디까지, 어떤 이미지에 효과가 있는지 알아보고자 하는 것이 목적.
2. Background
Synthetic image를 판별하는데 중요한 조사 결과를 소개.
-
Augmentation과 train dataset의 다양성은 모델의 robustness를 높여줌. 하지만 resize는 생성 단계에서 만들어진 high-frequency trace를 제거하기 때문에 피해야함. 이를 위해 다음과 같은 방법이 있음.
- Resize를 하지 않고 local patch 단위로 잘라서 학습
- Fusion을 이용해 최종 판단은 whole image를 보고 내림
- 첫 layer에서 downsampling을 피함
-
Local patch에 집중하면서도 local-global context 유지하는 것이 중요함.
-
대형 데이터셋에 pre-train시키는 것은 중요하지만 원본 이미지 대신 residuals(아마 중요하지 않은 이미지..?)를 학습시키거나 너무 심한 augmentation은 도움이 되지 않았음.
3. Artifact analysis
GAN 생성물은 architecture(layer의 타입과 수)에 따라 특유의 trace(fingerprint)가 남음. Fingerprint는 어떤 GAN인지 찾기 위해 이미지가 파이프라인을 거쳐 PRNU 패턴이 추출됨.
PRNU 패턴: Photo Respond Non Uniformity 패턴.
빛이 있을때 pixel별로 다른 감도(gain)을 가지면서 발생하는 FPN(fixed pattern noise)
- Image가 denoising filter 를 거침
- 원본 image에서 제거해 noise residual을 구함
- Residual의 평균을 내 fingerprint를 구함

본 연구에서는 1000개 이미지의 residual의 평균을 낸 후 Fourier transform을 적용함.
GAN 모델은 공통적으로 강한 peak가 나타남. GLIDE, Latent Diffusion, Stable Diffusion 등의 DM 모델들도 공통적인 fingerprint가 보여 동일한 detector가 효과있을 것으로 보이지만 다른 DM 모델들은 peak이 별로 보이지 않음.
4. Detection Performance
- 실험 대상
- GAN: ProGAN, StyleGAN2, StyleGAN3, BigGAN, EG3D
- Transformer: Taming Transformer, DALL-E Mini, DALL-E 2, GLIDE
- Diffusion model: Latent Diffusion, Stable Diffusion, ADM(Ablated Diffusion Model)
- TTI를 위한 COCO language prompt
- Real data: COCO, ImageNet, UCID
- Train
1. ProGAN 이미지 362k개, 20 카테고리- Latent Diffusion 이미지 200k개, 5 카테고리
- Test
- 각 모델별로 synthetic image 1000개 + 실제 이미지 5000개
- Detector
- Spec: frequency analysis
- PatchForensics: local patch analysis
- Wang2020: Resnet50 with blurring and compression augmentation
- Grag2021: Wang2020 backbone but with avoid downsampling in the first layer and intense augmentation
- 평가 방법
- AUC, acc threshold=0.5
Generalization and robustness
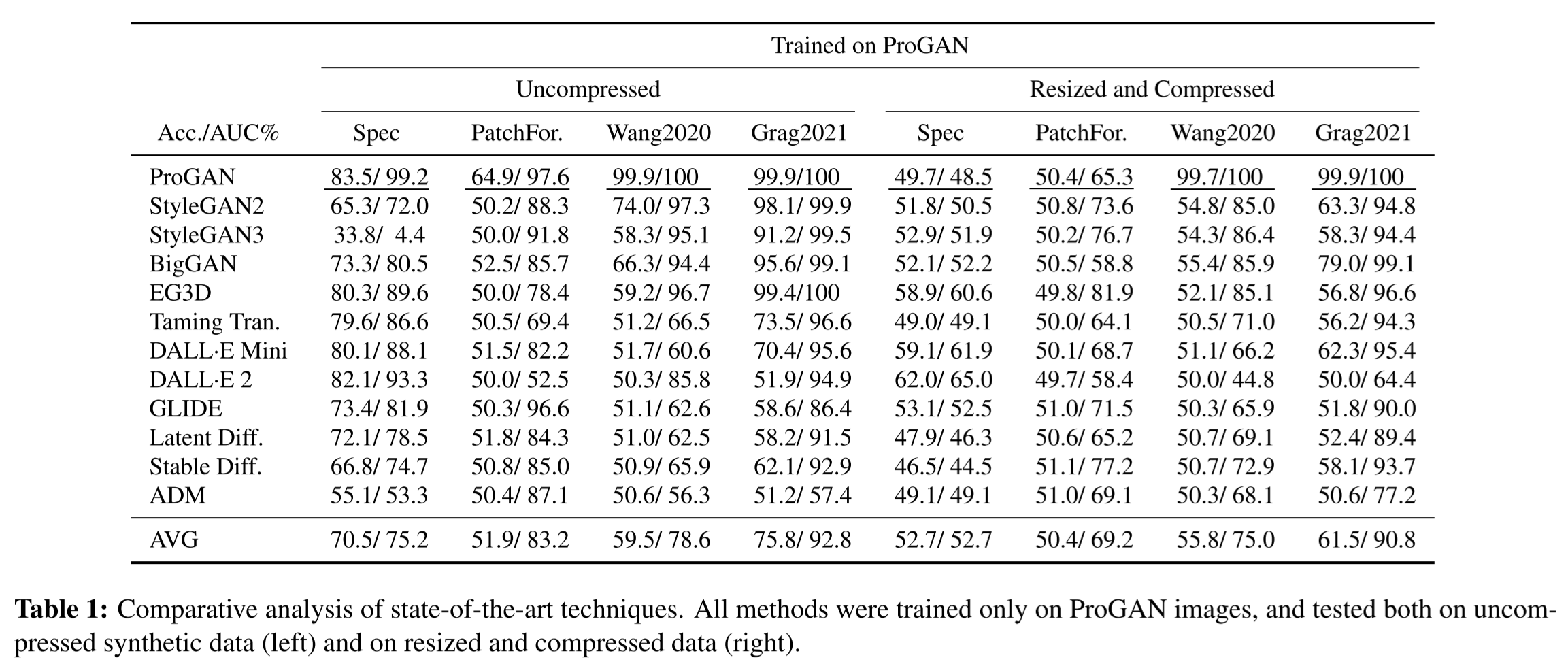
-
PNG 포맷의 압축되지 않은 synthetic image로 실험
- 실제 이미지는 항상 압축된 JPEG라 trace가 남아 구분이 쉬워 성능이 올라감
- 하지만 train에서의 acc threshold가 다른 데이터셋에선 말썽이라 성능이 안 나오는 경우도 존재
-
IEEE VIP Cup에서 사용한 실제 환경을 모방함
- 매 test마다 랜덤한 위치, 사이즈를 크롭해 200x200으로 resize 후 JPEG factor 65~100으로 compress
- 대부분의 경우 성능이 저하했고, 특히 peak가 약했던 DALL-E 2와 ADM에서 더 감소
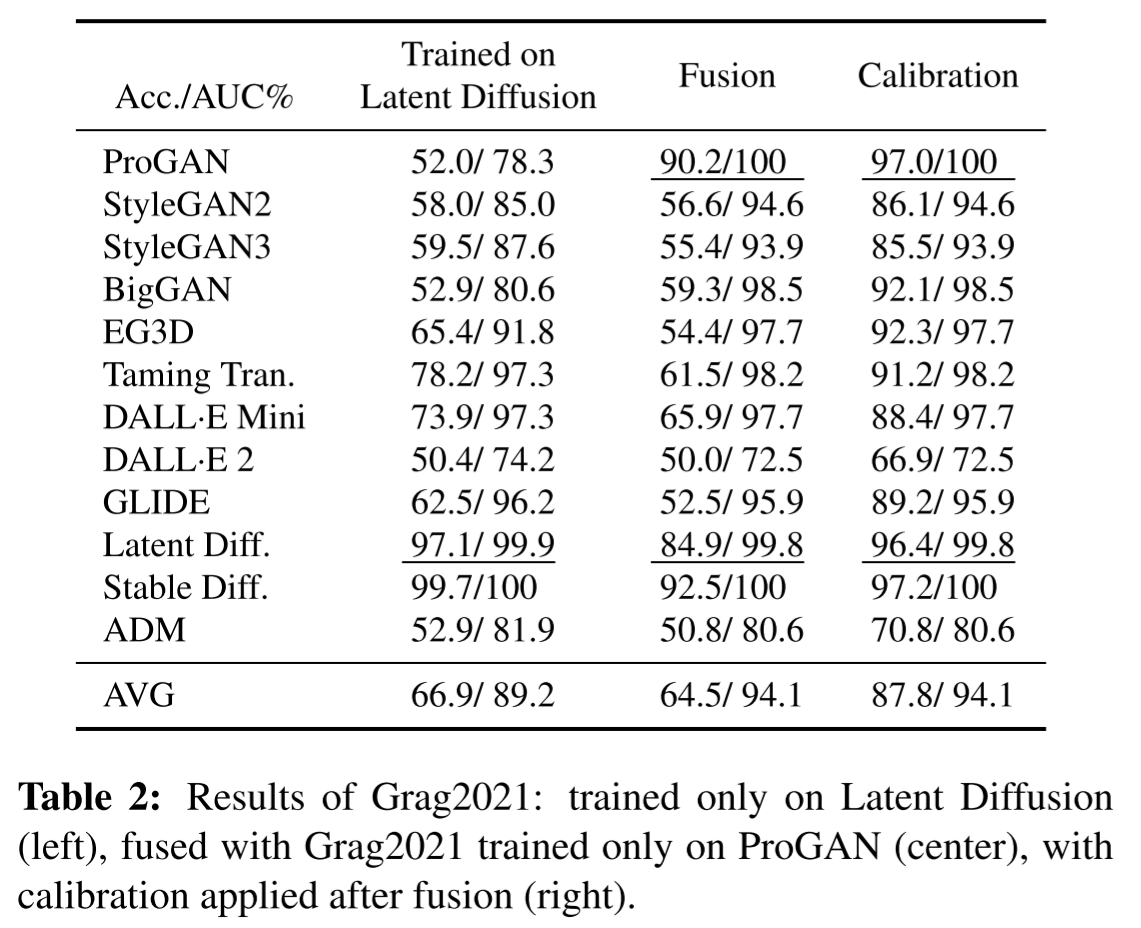
- 가장 성능이 잘 나온 Grag2021을 ADM 이미지에 학습시켜 실험
- ADM뿐만 아니라 artifact가 비슷한 Stable Diffusion에도 성능이 매우 잘 나옴
Fusion and calibration
-
Grag2021을 Latent Diffusion과 ProGAN에 학습 시킨 결과물의 fusion(simple average)를 냈더니 GAN 성능은 상승, DM에서의 정확도는 여전히 낮음
-
Platt scaling method로 calibration 시도
- Platt scaling method: 모델의 결과값을 다시 한 번 Logistic Regression에 태워서 값을 보정- 성능은 올라갔지만 여전히 train에서 나오지 않은 artifact들이 있는 이미지는 찾지 못했음
5. Conclusion
이 연구는 Diffusion model로 생성된 synthetic 이미지를 검출하는 데 초점을 맞춤. DM 이미지는 독특한 fingerprint(artifact/trace)를 가지고 있지만, SOTA detector의 성능은 특정 모델과 forensic trace에 따라 크게 다르다는 것을 발견함. 일반화는 여전히 과제로 남아 있으며 DM 이미지 감지 문제를 해결하기 위해 추가 분석이 필요함.
