OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 논문 리뷰
Pose Estimation
목록 보기
2/3

오늘은 BlazePose의 대조군이기도 하고 오픈소스로 유명한 OpenPose를 리뷰해볼 예정이다. BlazePose와는 정반대로 multi-person에서 real-time inference가 가능하게 만들었다는 점이 주목할만한 점.
아마 2017년에 CVPR에서 발표한 후 몇 가지 성능 개선과 OpenPose를 공개하며 2019년에 다시 논문을 낸 것으로 알고 있다. 수식 및 레퍼런스가 자세해서 읽기에는 좋았지만 양이 너무 많아 읽는데만 일주일은 걸린 것 같다..
0. Abstract
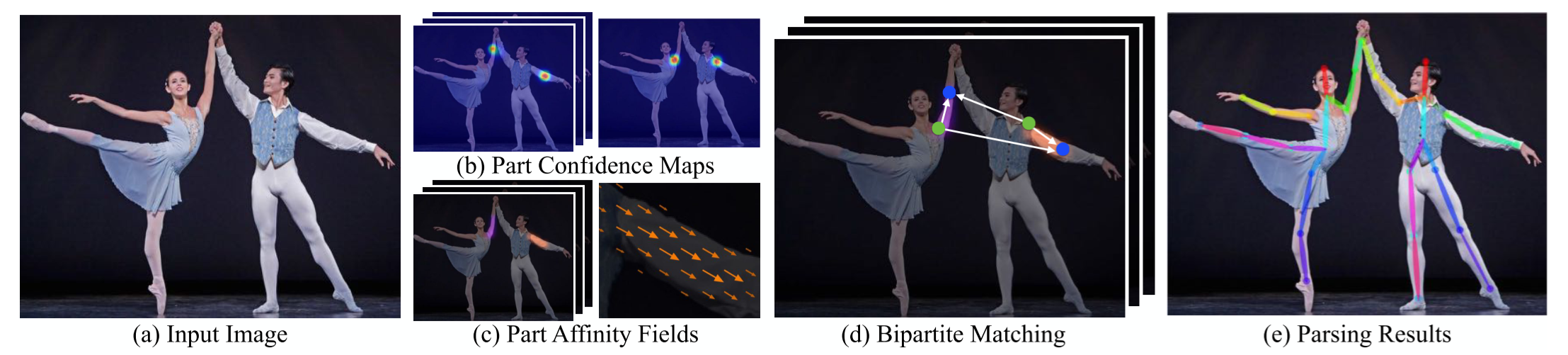
- Part Affinity Fields(PAFs)라는 비모수적 표현(nonparametric representation)을 이용해 각 신체 부위를 연결시키는 bottom-up 방식을 제안
- 사람 수에 상관 없이 real-time으로 high accuracy 달성
- PAF와 body part location을 모두 refine하는 것보다 PAF만 refine하는 것이 runtime performance, accuracy가 올라감
- Body keypoint뿐만 아니라 foot keypoint도 동시에 detect하는 모델을 개발해 따로 돌리는 것보다 inference time을 줄이고 accuracy는 유지
- OpenPose라는 오픈소스 라이브러리 배포
1. Introduction
- 용어 정리
- Body part: keypoint의 기준이 되는 각 관절
- Limb: body part와 part를 연결한 선
(사지?, 골격? 중 적당한 대체어가 없어 limb라고 쓰는게 나을듯..)
- Multi-Person pose estimation은 많은 어려움이 있음
- 불특정 다수가 랜덤한 위치, 크기로 등장
- 사람 간 겹침, 가려짐의 문제로 발생하는 occlusion, limb articulation 때문에 각 body part를 연결하기 어려움
- 사람이 늘어날수록 runtime complexity도 증가
- 일반적으로는 Top-down 방식을 사용
- Top-down: Person detector로 detect 후 각 사람마다 single-person pose estimation을 적용
- Detect에 실패할 경우 보완할 방법이 없고, 사람 수에 비례해 느려진다는 단점이 있음
- Bottom-up 방식은 detect 실패에 robust하고 사람 수에 영향을 받지 않는다는 장점이 있으나 초기 모델은 한 이미지 당 수 분이 걸려 cost적 이점이 없었음
- 우리는 Part Affinity Fields(PAFs)를 이용한 bottom-up 방식을 제안
- PAFs: limb의 위치와 방향을 표현하는 2d vector field
- PAF는 적은 computational cost로도 greedy parse를 위한 충분한 global context를 제공
- PAF는 2017년 논문에도 제시한 개념이나 이번 버전에서는 몇가지 새로운 contribution을 달성
- PAF는 refine하고 body part prediction은 제거해 speed 200%, accuracy 7% 개선
- Body와 foot keypoint를 동시에 학습하면서 성능, 속도는 유지한 새로운 모델 제시 & 15k의 annotated foot dataset 배포
- Vehicle keypoint estimation에 바로 적용할 수 있을 정도로 general
- Real-time으로 body, foot, hand, facial keypoint detection이 가능한 OpenPose라는 오픈소스 라이브러리 배포
2. Related Work
2.1. Single Person Pose Estimation
- 기존 human pose estimation은 각 local body part와 part-part간 공간 의존성(spatial dependency)을 추론
- Tree-structured graphical model: kinematic chain을 이용해 근접한 part간 관계를 모수적으로 표현
- Non-tree model: occlusion, symmetry, lon-range relationship을 고려하기 위해 tree structure에 추가적인 edge로 보강
- Local body part observation을 위해선 CNN을 사용
- CNN을 pose estimation을 할 경우엔 receptive field를 늘려서 part간 상관관계를 반영하려고 시도
- 이러한 방법은 모두 single person을 가정한 방법이라 사람이 있을법한 위치와 크기가 주어져있음
2.2. Multi-Person Pose Estimation
- Top-down 방식은 먼저 사람을 찾은 후 각 사람마다 pose estimation을 적용
- Single-Person method를 바로 적용 가능하나,
- Early commitment 문제(detection failure)와 사람 간 spatial dependecy를 고려하지 못한다는 단점이 있음
- Bottom-up 방식은 part detection 후보를 메긴 후 각 사람과 연결
- Person detection에 의존하지 않으나,
- Fully connected graph를 푸는 것은 NP-hard 문제라 이미지 당 수 시간이 걸린다는 단점이 있음
- 이전 연구에서 우리는 여러 사람의 keypoint(part) 간 비정형 쌍 관계(unstructured pairwise relationships)를 표현하는 벡터장인 PAF를 제시
- 이후 관련 연구는 모두 각 keypoint를 어떻게 사람에 연결시킬지에 대한 방법에 대한 연구
3. Method
- : Part(keypoint)의 개수
- : Limb의 개수
- : Body part 위치에 대한 confidence map
- : Part 사이의 연관관계를 표현하는 PAF의 집합
- (vector라서)
- 크기의 input image 입력
- Network가 와 을 출력
- 와 를 greedy inference로 parsing해서 각 사람에 대한 keypoint의 위치를 출력
3.1. Network Architecture
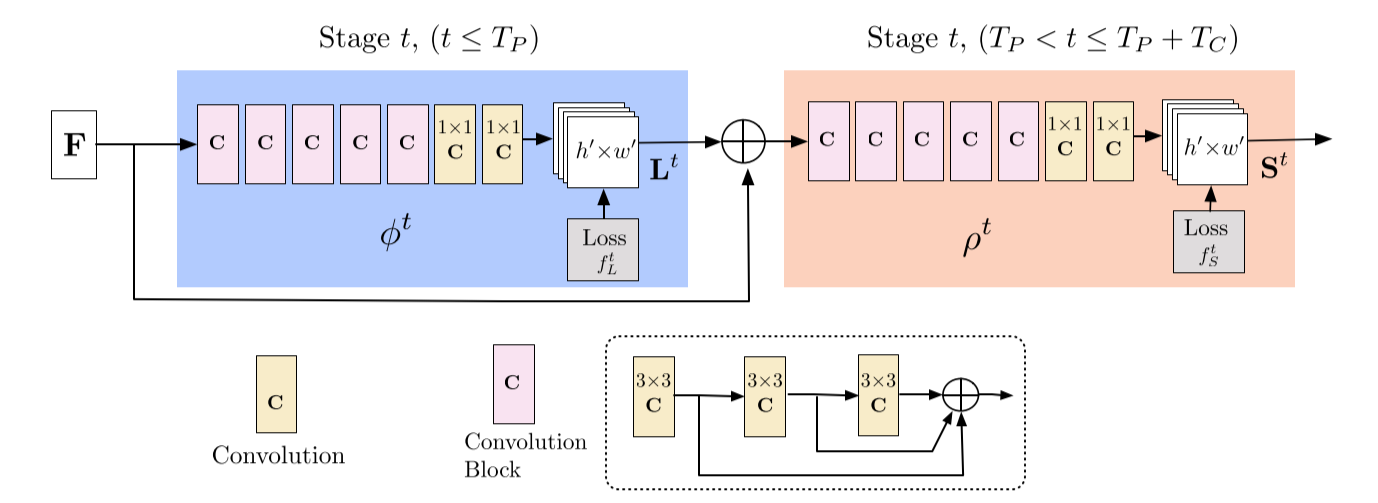
- 파란색 모듈에서는 PAF를 예측하고 베이지색 모듈에서는 CM(confidence map)을 예측
- 각 stage마다 intermediate supervision을 이용해 예측을 반복하면서 예측값을 refine
- Intermediate supervision: Stacked HR에서 등장한 개념으로, 최종 prediction에서만 loss를 구하는 것이 아니라 중간에서 추가적으로 HR module에서 heatmap을 만들어 GT와 비교해 loss를 구해 적용함으로써 틀린 부분을 보다 정교하게 보정
- Convolutional kernel을 에서 으로 바꿔 receptive field를 유지하며 parameter 수를 줄임
- 각 convolutional kernel의 output은 concat
- Non-linearity layer를 3배로 늘려 high-low level feature를 유지
3.2. Simultaneous Detection and Association
- Image는 CNN(VGG-19의 초기 10 layer를 이용)에서 feature map 를 생성
- Stage1: 에서 CNN 을 통해 PAF 을 생성
- 이전 stage의 예측값 과 원본 를 concat해 refine된 예측값을 생성
- : t번째 stage의 CNN
- : 총 PAF stage의 수
- 번의 iteration이 끝난 후엔 가장 최신 PAF를 기준으로 CM detection이 실행됨
- : t번째 stage의 CNN
- : 총 CM stage의 수
- 2017년도 논문과 다른 점이라면 PAF, CM stage를 병렬에서 직렬로 바꿔 stage당 연산량을 절반으로 줄임
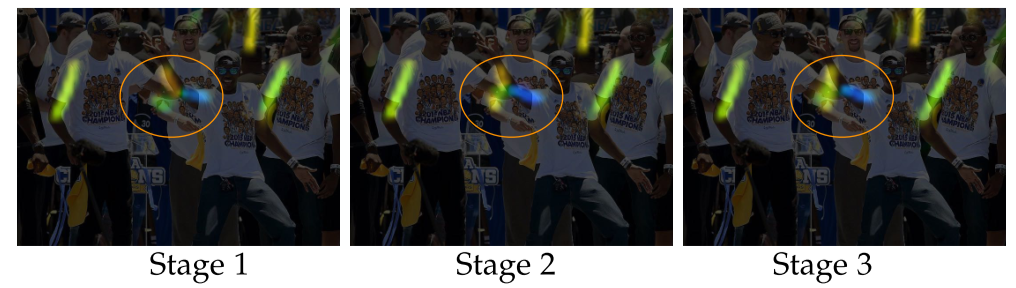
- PAF 예측값을 refine하는 것은 CM 예측값을 개선했으나 그 반대는 성립하지 않음
아마 PAF에서는 신체 부위를 예측해볼 수 있으나 part만 주어졌을 때는 연결짓기 어렵기 때문 - 위 사진에서 PAF는 refine으로 성능개선이 된 것을 확인 가능
- CNN을 학습시키기 위해 loss 를 사용
- : 번째 stage에서의 loss function
- : 번째 stage에서의 loss function
- : PAF의 GT
- : CM의 GT
- : binary mask, pixel 에서 annotation이 없을 경우 이 돼서 학습 도중 TP에 패널티를 주는 것을 방지
- 각 stage마다 intermediate supervision를 넣어 gradient vanishing problem을 해결
3.3. Confidence Maps for Part Detection
- 을 측정하기 위해 GT CM을 생성
- : 번째 사람, 번째 visible part의 픽셀 에서의 CM
- : 번째 사람, 번째 visible part의 GT
- : 분산을 조정
- GT CM은 각 사람별 heatmap을 max aggregation
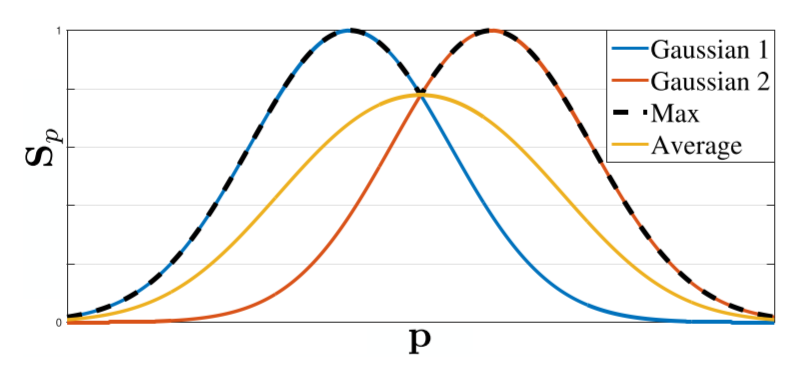
- 각 CM의 평균을 구하는 것이 아니라 max aggregation해서 각 peak의 특징이 분명하게 남아있을수 있게 함
- 테스트에는 CM을 예측한 후 NMS로 body part candidate를 구함
3.4. Part Affinity Fields for Part Association

- Part Association은 3.3.에서 찾은 body part를 같은 사람끼리 묶어주는 문제
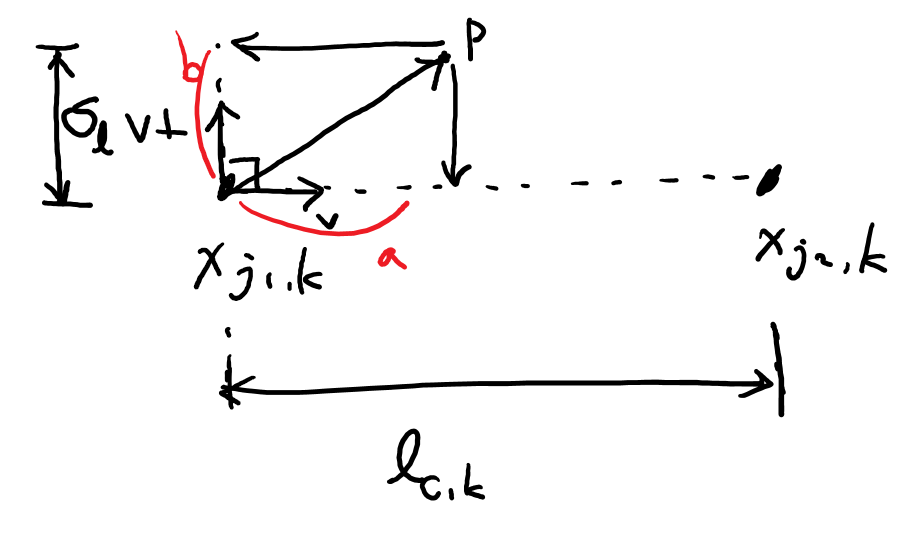
- 처럼 part간 midpoint를 추가적으로 만들어 연결하는 방법은 사람들이 뭉칠 경우 false association(초록선)일 발생할 가능성이 높음
- midpoint는 각 limb의 orientation이 아니라 position만 표현하고, limb가 가능한 범위를 single point로 한정하기 때문
- PAF는 limb가 가능한 범위에서 orientation과 location에 대한 정보를 모두 유지
- PAF: 각 limb에서 한 점에서 다른 점으로 뻗어나가는 방향을 표현하는 2D vector
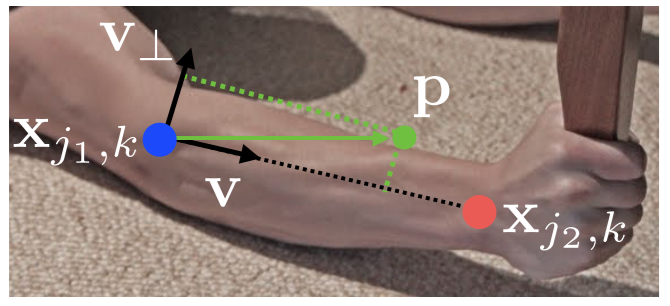
- : 점 에서의 PAF의 GT, 가 limb 위에 있을 경우 에서 로 향하는 unit vector가 되고, 아닐 경우 0
- : 번째 사람의 번째 limb에 대한 body part 의 GT position
- : limb 위에 있는 단위 벡터
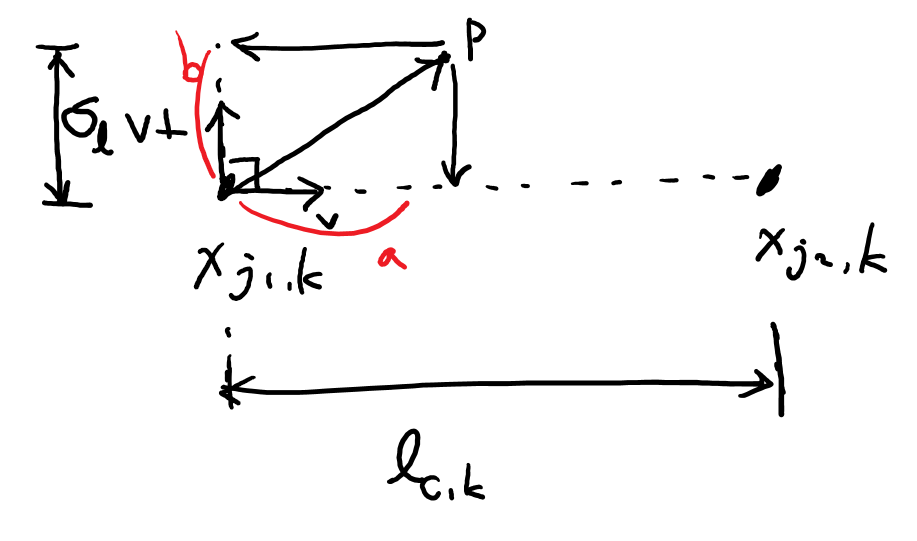
- 위 식은 의 threshold 범위
- : limb width를 정하는 hyperparameter
- :
- : 에 수직인 벡터
- 각 당 최종 PAF는 에서 겹치는 모든 사람의 벡터의 평균으로 나타냄
- PAF와 limb의 벡터 곱을 적분해서 confidence를 평가
- : candidate part location
- : 사이를 interpolate하는 점
3.5. Multi-Person Parsing using PAFs

- Body part를 연결하는 최적해를 찾는 것은 K-차원 matching 문제라 NP-Hard
- 본 연구에서는 2가지 완화점(relaxation)을 둬 computational cost를 줄이면서도 성능이 좋은 방법을 찾음
- (c)처럼 edge를 구성하는 최소의 개수만 선정
- 그래프를 bipartite로 분해
- 먼저 detection CM에 NMS를 적용해 part(keypoint)의 후보(candidate) 위치를 찾음
- Part candidate를 이용해 가능한 limb의 집합을 만들고, 각 limb는 의 PAF를 이용해 점수를 메김
- (c)처럼 K-차원의 최적 연결 방식을 찾는 것은 NP-Hard 문제라 논문에서는 greedy relaxation을 제안
- Fig 5b.처럼 part의 한 쌍만 두고 본다면 node는 각 part, edge는 weight를 의 인 모든 가능한 limb인 maximum weight bipartite graph matching으로 볼 수 있다
- Bipartite graph matching이라 어떤 두 edge도 같은 node를 공유하지 않음
- 는 두 edge가 node를 공유하지 않게 만듬
- 최적 matching을 찾기 위해 Hungarian algorithm을 사용
- : limb 에서 matching한 weight의 총 합
- : 중에서 에 해당하는 부분
- : 사이의 PAF
- : body part detection 후보
- : part 의 번째 후보
- : 각 part
- : 각 part 의 후보 수
- : 가 연결됐는지 0/1로 판정
- : 최적해
- 최종 는 각 limb type별 의 합
- 최종 limb connection으로 같은 part를 공유하는 limb끼리 모아 full-body pose를 생성
- OpenPose 모델은 귀-어깨, 팔목-어깨 등의 PAF를 많이 생성해 사람이 몰렸을 경우의 정확도를 올림
- 또한 connection을 구성할 때 PAF 점수 순으로 정렬하기 때문에 다른 사람과 연결할 가능성이 적어짐
4. OpenPose
- OpenPose는 신체, 발, 손, 얼굴 keypoint를 찾는 첫 real-time multi-person 오픈소스 라이브러리
4.1. System
- Mask R-CNN, AlphaPose와는 달리 여러 플랫폼, 하드웨어에서 돌릴 수 있으며 input도 사진, 영상, 웹캠 가능
- 3d keypoint pose detection, facial keypoint detection 등 여러가지 가능하다는 자랑 얘기..
- 1080ti 기준 22fps
4.2. Extended Foot Keypoint Detection
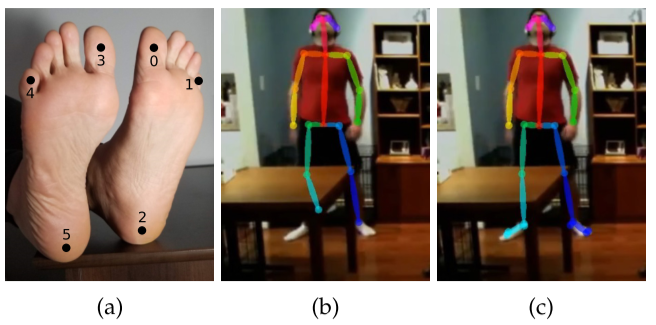
- 아바타나 3D 모델 만드는 그래픽 작업에서 foot keypoint가 없으면 발이 땅을 뚫거나 미끄러지는 등 candy wrapper effect가 발생
- MPII, COCO에 6개의 foot keypoint를 라벨링 후 학습해 다리 keypoint에 대한 정확도를 올림
- 골반 사이에도 keypoint를 추가해 상체가 가려져도 성능이 잘 나옴
5. Datasets and Evaluations
- COCO 2016 keypoint challenge에서 1등
5.1. Results on the MPII Multi-Person Dataset
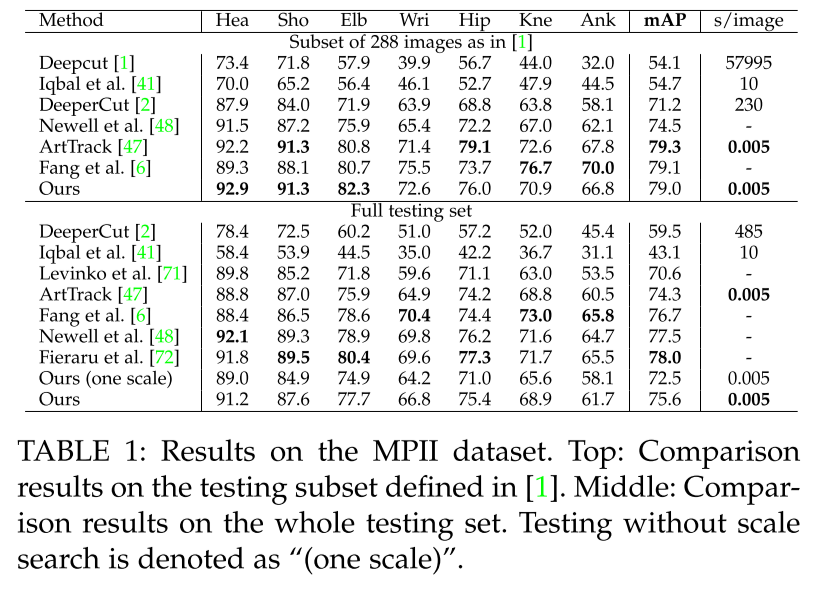
- Metric은 PCKh와 mAP를 이용
- 이전 SOTA보다 6배 빠르고 8.5% mAP 높음
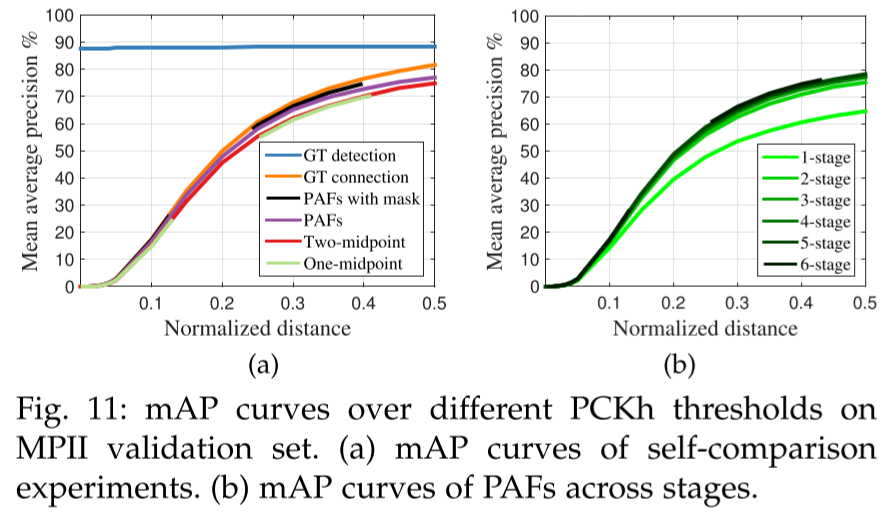
- One/two-midpioint 같이 모두 part 사이에 추가적인 중간 point를 추가해 limb의 정확도를 높이는 방식보다 PAF가 성능이 잘 나옴
5.2. Results on the COCO Keypoints Challenge
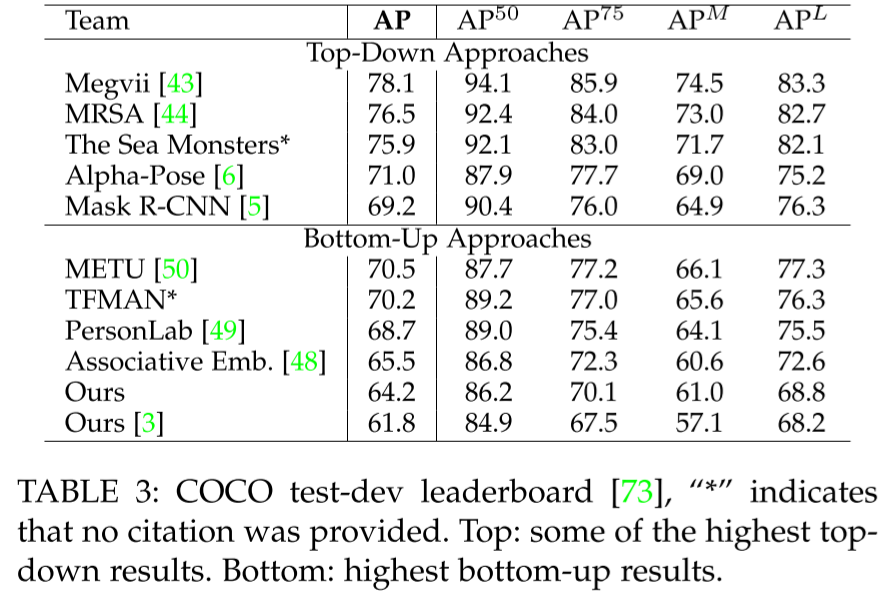
- COCO는 OKS를 기반으로 한 AP를 사용
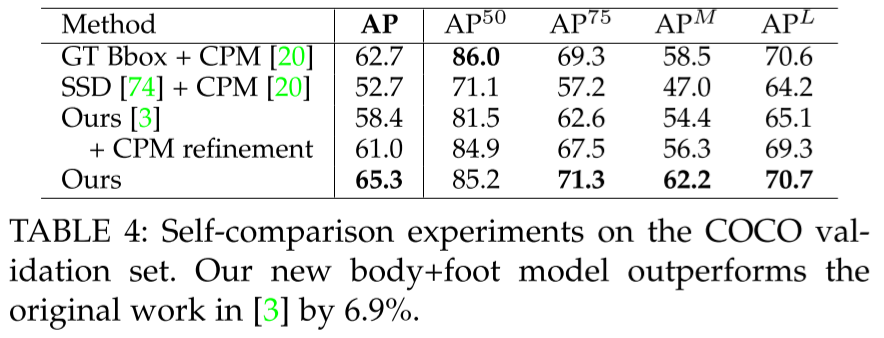
- CPM: Convolutional Pose Machine, PAF로 자세추정
- part는 GT, PAF는 CPM 사용하면 SOTA
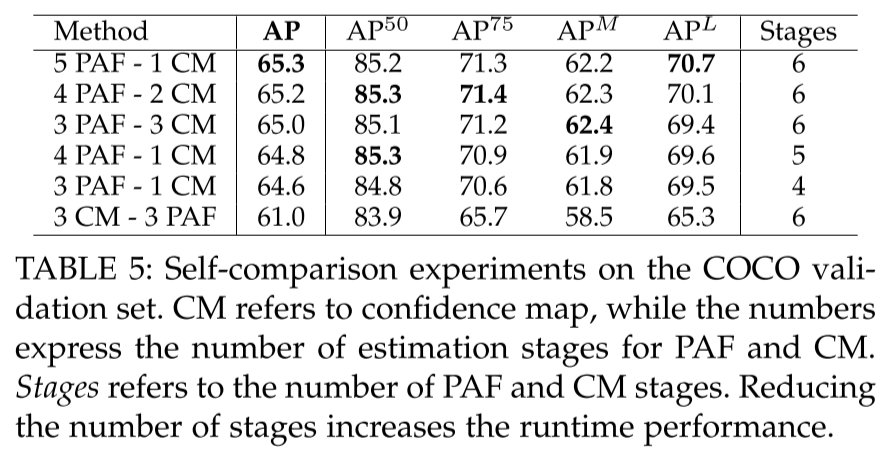
- PAF는 반복해서 refine하면 성능이 상승
- PAF는 채널 늘리면 TF 올라가고 acc 떨어지지만 CM은 acc 상승
- PAF를 먼저 하는게 무조건 이득, acc 4%p 상승
5.3. Inference Runtime Analysis
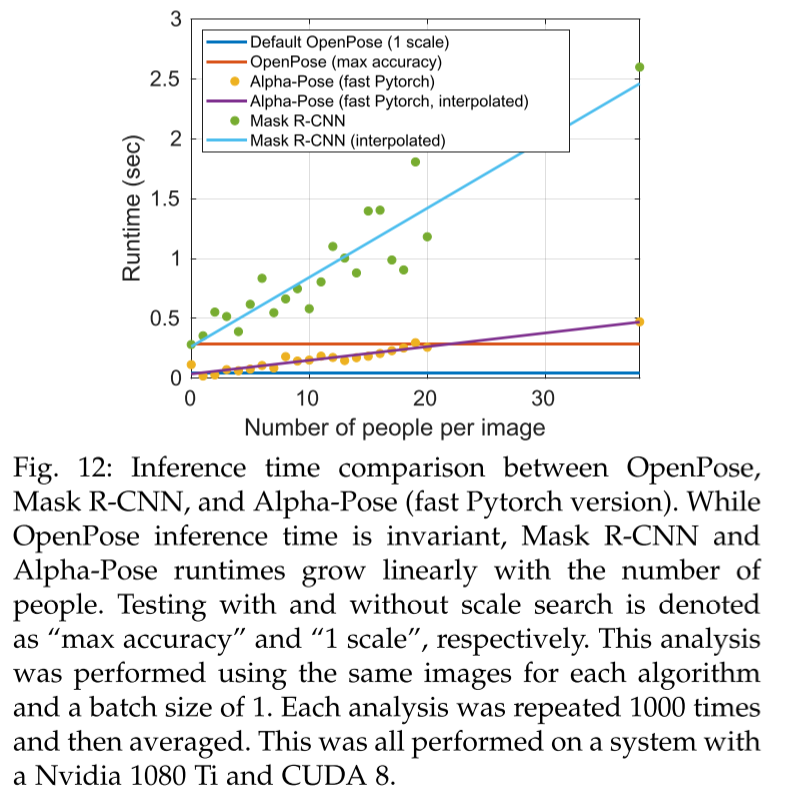
- Top-down은 detect한 사람에 비례해 속도라 느려지나 Bottom-up은 invariant
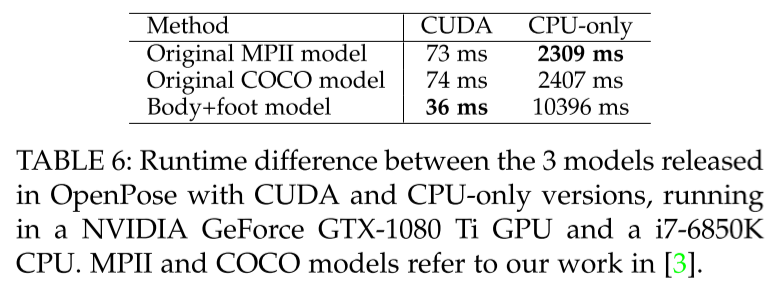
- OpenPose의 복잡도는 CNN processing이 , multi-person parsing time이 지만 parsing time 자체가 CNN processing의 1/100 정도
- 9명 기준 CNN은 36ms, parsing은 0.58ms
5.4. Trade-off between Speed and Accuracy
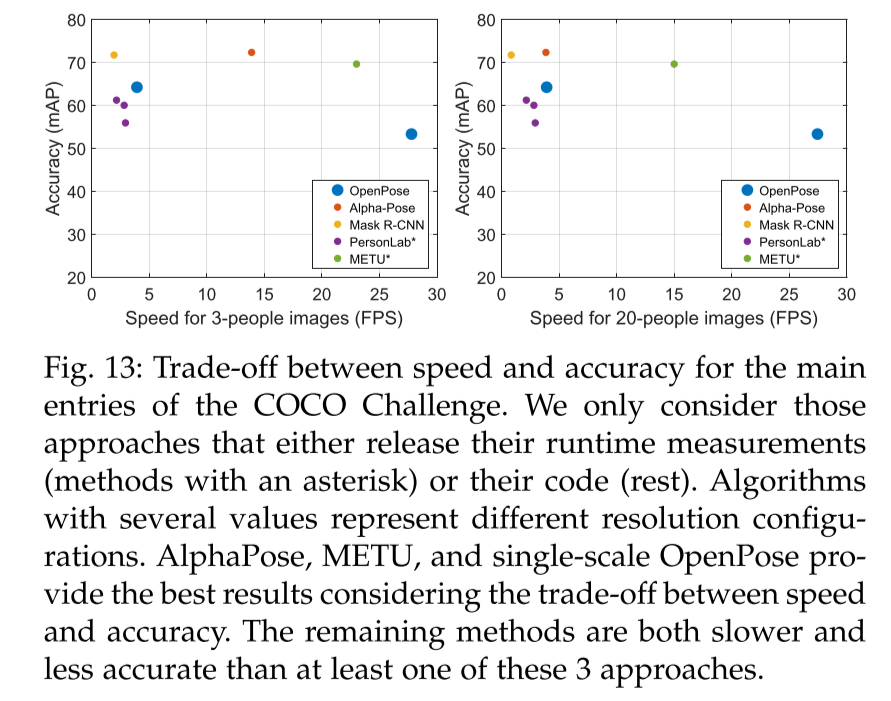
- Top-down은 각 사람을 crop해서 network의 input으로 넣어 느리지만 정확
- Botton-up은 이미지 자체를 입력하기 때문에 resolution이 떨어지고 fast, less accurate
5.5. Result on the Foot Keypoint Dataset

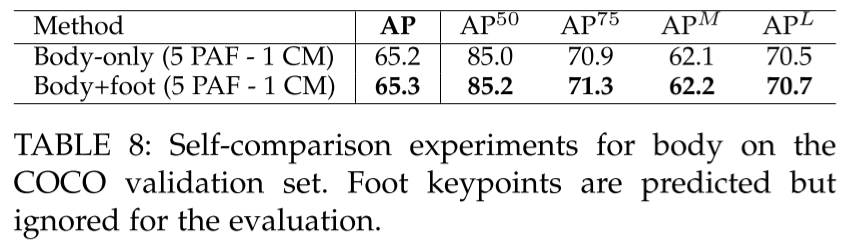
- Body 뿐만 아니라 foot detector도 추가했는데 성능을 유지
5.6. Vehicle Pose Estimation


- 다른 task에도 적용해 generalization
5.7. Failure Case Analysis

- 성능이 잘 안 나오는 경우
- 일반적이지 않은 자세나 위아래가 뒤집힐 경우
- Body occlusion
- 여러 사람이 겹칠 경우
6. Conclusion
- 이 논문에서 제시한 점
- PAF: keypoint를 연결하는 위치와 방향을 모두 표현하는 nonparametric representation
- Part detection과 association을 학습하는 모델
- 사람 수에 상관 없이 part를 연결하는 greedy parsing algorithm
- Body part location refinement보다 PAF refinement가 중요하다는 점
- Body, foot을 하나로 합친 모델
- 오픈소스 라이브러리 OpenPose
Reference
https://deep-learning-study.tistory.com/617
https://curt-park.github.io/2018-07-03/stacked-hourglass-networks-for-human-pose-estimation/
https://juhwakkim.github.io/2019/08/02/2019-08-02-Openpose-paper-review/

즐겁게 개발하기