오늘은 FlatFileItemReader로 파일을 일고 FlatFileItemWriter로 파일 쓰는 실습을 진행해보자
1. FlatFileItemReader 알아보기
FlatFileItemReader이란?
FlatFileItemReader는 Spring Batch에서 텍스트 파일을 읽기 위해 제공하는 기본 ItemReader로, 고정 길이, 구분자 기반, 멀티라인 등 다양한 텍스트 파일 형식을 지원한다.
이를 통해 대규모 데이터 처리 시에도 효율적이고 간편하게 텍스트 파일을 다룰 수 있다.
FlatFileItemReader의 특징
-
간단하고 효율적인 구현
FlatFileItemReader는 설정이 간단하고 사용이 쉬워 대규모 데이터 처리를 효율적으로 수행할 수 있다. -
다양한 텍스트 파일 형식 지원
고정 길이, 구분자 기반, 멀티라인 등 다양한 형식의 텍스트 파일을 읽을 수 있어 폭넓은 텍스트 파일 처리 시 유용하다. -
확장 가능성
토크나이저, 필터 등을 사용해 기능을 확장할 수 있어 커스터마이징이 용이하다.
사용 예시)
고정 길이 텍스트 파일이나 구분자 기반 CSV 파일, 멀티라인 파일 등 다양한 텍스트 파일 데이터 처리에 주로 사용된다.
장점: 간단한 설정과 효율적인 데이터 처리, 다양한 파일 형식 지원
단점: 복잡한 데이터 구조를 다루기에는 적합하지 않다.
FlatFileItemWriter 주요 구성 요소
Resource: 읽을 파일 지정LineMapper: 각 라인을 Item으로 변환LineTokenizer: 각 라인을 토큰으로 분리FieldSetMapper: 토큰을 Item의 속성에 매핑SkippableLineMapper: 오류 발생 시 라인 건너뛰기LineCallbackHandler: 라인별로 추가 처리ReadListener: 읽기 이벤트 처리 (시작, 종료, 오류)
2. FlatFileItemWriter 알아보기
FlatFileItemWriter란?
FlatFileItemWriter는 Spring Batch에서 제공하는 ItemWriter 인터페이스를 구현한 클래스로, 데이터를 텍스트 파일로 출력하는 데 사용된다.
FlatFileItemWriter의 장점과 단점
장점
간편성: 텍스트 파일로 데이터를 출력하는 간편한 방법을 제공한다.
유연성: 다양한 설정을 통해 원하는 형식으로 출력 파일을 생성할 수 있다.
성능: 대량의 데이터를 빠르게 출력할 수 있다.
단점
형식 제약: 텍스트 파일 형식만 지원한다.
복잡한 구조: 복잡한 구조의 데이터를 출력할 경우 설정이 복잡해질 수 있다.
오류 가능성: 설정 오류가 발생할 경우 출력 파일이 손상될 수 있다.
FlatFileItemWriter의 주요 구성 요소
Resource: 출력 파일 경로를 지정LineAggregator: Item을 문자열로 변환HeaderCallback: 출력 파일의 헤더 작성FooterCallback: 출력 파일의 푸터를 작성Delimiter: 항목 사이 구분자 지정AppendMode: 기존 파일에 데이터를 추가할지 여부 지정
2. Spring batch 실습 구현하기
실습 순서
FlatFileItemReader를 사용해 customer.csv 파일을 읽고 Customer 객체로 매핑.(실습1)FlatFileItemWriter를 활용하여 Customer 데이터를 customer_new.csv 파일에 작성.(실습1)CustomerLineAggregator를 통해 각 Customer 아이템을 문자열로 변환.(실습2)CustomerHeader와CustomerFooter콜백을 통해 파일의 헤더와 푸터를 설정.(실습2)AggregateCustomerProcessor를 사용해 데이터를 집계하여 총 고객 수와 나이의 합계를 출력.(실습2)
Spring batch 실습 1
FlatFileItemReader로 csv 형식의FlatFile을 읽고FlatFileItemWriter로 이 파일을 읽어 탭으로 구분된 파일을 새로 작성하는 배치를 구현해보자
1. Customer 모델 생성하기
resources/static 디렉토리에 customer.csv파일을 추가해주었다.
unclebae,40,Male
superman,45,Male
WonderWoman,30,Female그 후 Customer 클래스를 작성해주었다.
@Getter //Lombok
@Setter //Lombok
public class Customer {
private String name;
private int age;
private String gender;
}2. FlatFileItemReader 생성
@Bean
public FlatFileItemReader<Customer> flatFileItemReader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("FlatFileItemReader")
.resource(new ClassPathResource("./customer.csv"))
.encoding(ENCODING)
.delimited()
.delimiter(",")
.names("name", "age", "gender")
.targetType(Customer.class)
.build();
}
resource: 읽을 파일을 지정 (customer.csv)
encoding(ENCODING): 파일의 인코딩 설정
delimited(): 구분자로 구분된 파일임을 설정
delimiter(","): 데이터 구분자를 쉼표로 설정
names("name", "age", "gender"): CSV 필드를 name, age, gender 속성에 매핑
targetType(Customer.class): Customer 클래스 타입으로 매핑
3. FlatFileItemWriter 생성
@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv"))
.encoding(ENCODING)
.delimited()
.delimiter("\t")
.names("Name", "Age", "Gender")
.build();
}
resource: 출력 파일을 지정 (output/customer_new.csv)
encoding(ENCODING): 파일 인코딩 설정
delimited(): 구분자로 구분된 파일임을 설정
delimiter("\t"): 데이터 구분자를 탭으로 설정
names("Name", "Age", "Gender"): Customer 객체 필드를 Name, Age, Gender에 매핑
output 디렉토리에 (설정한 출력 경로 : ./output/customer_new.csv)에 배치 이후 생성되는 새로운 파일을 저장하기 위해 프로젝트 루트에 output 디렉토리를 생성해주었다.
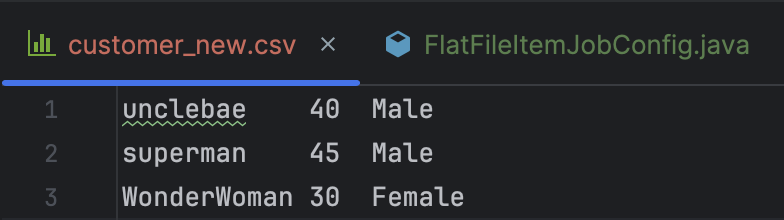
4. 실습 1 실행 결과 확인..!
여기까지 작성한 후 실행 결과를 확인해보면

우리가 설정한 출력 경로 output 디렉토리에 기존 쉼표로 구분되어 있었던 csv파일이 탭으로 구분된 파일로 새로 작성된 것을 확인할 수 있다.
Spring batch 실습 2
이번 실습에서는
FlatFileItemWriter를 통해 파일에 Header와 Footer를 추가하고, 데이터 집계를 처리하여 전체 고객 수와 나이 합계를 푸터에 출력해보자
5. CustomerLineAggregator 작성하기
CustomerLineAggregator는 LineAggregator 인터페이스를 구현하여 각 Customer 객체를 FlatFileItemWriter에서 처리할 수 있는 문자열 형식으로 변환하는 역할을 한다.
public class CustomerLineAggregator implements LineAggregator<Customer> {
@Override
public String aggregate(Customer item) {
return item.getName() + "," + item.getAge();
}
}aggregate 메서드를 구현하여 Customer 객체의 name과 age 속성을 쉼표로 구분된 문자열 형식으로 변환한다.
6. CustomerHeader 작성하기
CustomerHeader는 FlatFileHeaderCallback 인터페이스를 구현하여 출력 파일에 헤더를 추가하는 역할을 한다.
public class CustomerHeader implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
writer.write("ID,AGE");
}
}
writeHeader 메서드를 통해 ID와 AGE라는 제목이 출력 파일의 첫 줄에 추가된다.
7. CustomerFooter 작성하기
CustomerFooter는 FlatFileFooterCallback 인터페이스를 구현하여 출력 파일의 끝에 요약 정보를 추가하는 역할을 한다. ConcurrentHashMap을 사용해 고객 수와 나이 합계 같은 집계 결과를 출력한다.
@Slf4j
public class CustomerFooter implements FlatFileFooterCallback {
ConcurrentHashMap<String, Integer> aggregateCustomers;
public CustomerFooter(ConcurrentHashMap<String, Integer> aggregateCustomers) {
this.aggregateCustomers = aggregateCustomers;
}
@Override
public void writeFooter(Writer writer) throws IOException {
writer.write("총 고객 수: " + aggregateCustomers.get("TOTAL_CUSTOMERS"));
writer.write(System.lineSeparator());
writer.write("총 나이: " + aggregateCustomers.get("TOTAL_AGES"));
}
}writeFooter 메서드를 통해 총 고객 수와 총 나이 합계를 출력 파일의 끝 부분에 작성한다.
8. AggregateCustomerProcessor 작성하기
AggregateCustomerProcessor는 ItemProcessor 인터페이스를 구현하여 각 Customer 객체의 정보를 집계한다. 이를 통해 총 고객 수와 나이 합계를 계산한다.
@Slf4j
public class AggregateCustomerProcessor implements ItemProcessor<Customer, Customer> {
ConcurrentHashMap<String, Integer> aggregateCustomers;
public AggregateCustomerProcessor(ConcurrentHashMap<String, Integer> aggregateCustomers) {
this.aggregateCustomers = aggregateCustomers;
}
@Override
public Customer process(Customer item) throws Exception {
aggregateCustomers.putIfAbsent("TOTAL_CUSTOMERS", 0);
aggregateCustomers.putIfAbsent("TOTAL_AGES", 0);
aggregateCustomers.put("TOTAL_CUSTOMERS", aggregateCustomers.get("TOTAL_CUSTOMERS") + 1);
aggregateCustomers.put("TOTAL_AGES", aggregateCustomers.get("TOTAL_AGES") + item.getAge());
return item;
}
}process 메서드는 각 Customer 객체를 읽을 때마다 고객 수와 나이를 집계하고, 이를 aggregateCustomers 해시맵에 저장한다
9. FlatFileItemWriter 수정(실습 2 버전)
flatFileItemWriter 메서드에서 lineAggregator, headerCallback, footerCallback을 연결하기위해 기존의 코드에서 아래 코드로 수정해주었다.
@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv"))
.encoding(ENCODING)
.delimited()
.delimiter("\t")
.names("Name", "Age", "Gender")
.lineAggregator(new CustomerLineAggregator()) // LineAggregator 추가
.headerCallback(new CustomerHeader()) // HeaderCallback 추가
.footerCallback(new CustomerFooter(aggregateCustomers)) // FooterCallback 추가
.build();
}
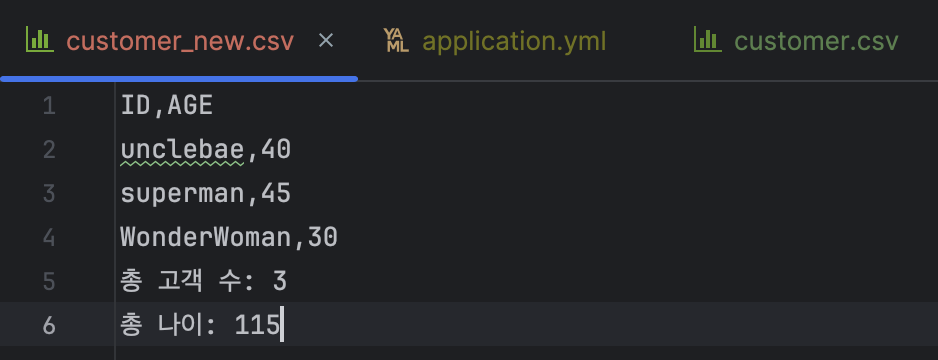
10. 실습 2 실행 결과 확인..!
설정한 CustomerHeader, CustomerLineAggregator, CustomerFooter대로 출력 파일이 생성된 것을 확인할 수 있다.
- Header: 출력 파일 첫 줄에 ID, AGE 출력
- Body: CustomerLineAggregator에서 각 Customer 객체가 쉼표로 구분되어 출력됩니다.
- Footer: 전체 고객 수와 나이 합계 출력
참고) 디렉토리 구조
참고) FlatFileItemJobConfig 전체 소스코드
package com.example.springbatch.jobs.flatfilereader;
import com.example.springbatch.jobs.models.Customer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.FlatFileItemWriter;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.builder.FlatFileItemWriterBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.concurrent.ConcurrentHashMap;
@Slf4j
@Configuration
public class FlatFileItemJobConfig {
public static final int CHUNK_SIZE = 100;
public static final String ENCODING = "UTF-8";
public static final String FLAT_FILE_CHUNK_JOB = "FLAT_FILE_CHUNK_JOB";
private final ConcurrentHashMap<String, Integer> aggregateCustomers = new ConcurrentHashMap<>();
@Bean
public FlatFileItemReader<Customer> flatFileItemReader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("FlatFileItemReader")
.resource(new ClassPathResource("static/customer.csv"))
.encoding(ENCODING)
.delimited()
.delimiter(",")
.names("name", "age", "gender")
.targetType(Customer.class)
.build();
}
/* 실습 1
@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv"))
.encoding(ENCODING)
.delimited()
.delimiter("\t")
.names("Name", "Age", "Gender")
.build();
}
*/
@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv"))
.encoding(ENCODING)
.delimited()
.delimiter("\t")
.names("Name", "Age", "Gender")
.lineAggregator(new CustomerLineAggregator())
.headerCallback(new CustomerHeader())
.footerCallback(new CustomerFooter(aggregateCustomers))
.build();
}
@Bean
public ItemProcessor<Customer, Customer> aggregateCustomerProcessor() {
return new AggregateCustomerProcessor(aggregateCustomers);
}
@Bean
public Step flatFileStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
log.info("------------------ Init flatFileStep -----------------");
return new StepBuilder("flatFileStep", jobRepository)
.<Customer, Customer>chunk(CHUNK_SIZE, transactionManager)
.reader(flatFileItemReader())
.processor(aggregateCustomerProcessor())
.writer(flatFileItemWriter())
.build();
}
@Bean
public Job flatFileJob(Step flatFileStep, JobRepository jobRepository) {
log.info("------------------ Init flatFileJob -----------------");
return new JobBuilder(FLAT_FILE_CHUNK_JOB, jobRepository)
.incrementer(new RunIdIncrementer())
.start(flatFileStep)
.build();
}
}
마무리
오늘은 Spring Batch를 활용해 FlatFileItemReader로 CSV 파일을 읽고 FlatFileItemWriter로 새로운 파일에 데이터를 작성해보고, 헤더, 푸터, 데이터 집계까지 추가하는 과정을 구현해보았다.
참고글 - [SpringBatch 연재 04] FlatFileItemReader로 단순 파일 읽고, FlatFileItemWriter로 파일에 쓰기
깃허브 - https://github.com/hysong4u/springbatch

확실히 이번 스터디에서 스프링배치에 대해 알아두면 나중에 취업을 하는 상황속에서 반드시 사용할거에요 ㅠㅠ 기초 잘 닦아두시길 ㅠㅠ