Search Process
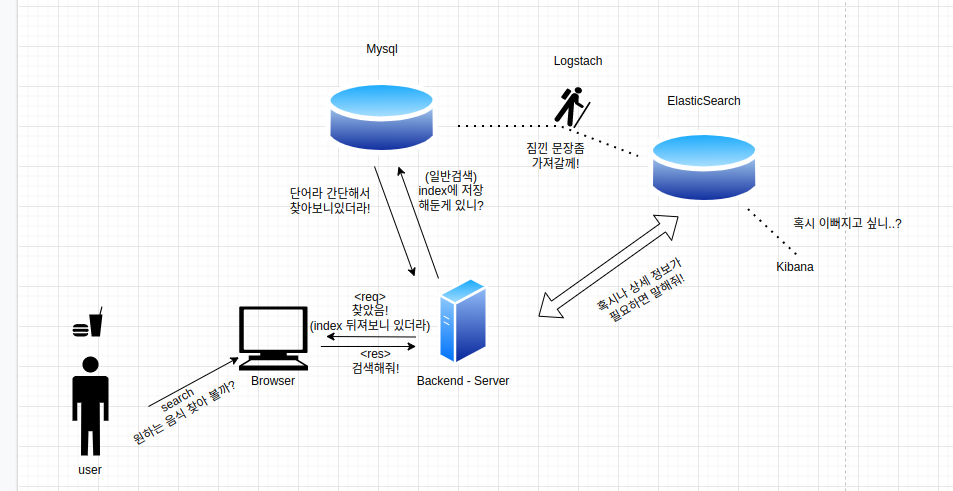
수업 시간 때 만든 ELK Stack을 통한 검색 프로세스에 대한 파이프라인을 만들었는데 부족한 부분이 많이 보인다...(Redis를 집어넣지 못했다)
원래라면 Mysql자리에 Redis가 있어야 하고 벡엔드 서버와 Logstash 사이에 Mysql이 들어와서 데이터를 저장하고 Logstash에 데이터를 풀링(polling)하는 역할을 집어 넣어줬어야 했다...
아쉬운 만큼 다시 현재 검색에 가장 최적화 되어 있다고 평가받는 ELK Stack을 통한 검색 프로세스에 대해 다시 복습해보겠다.
-
우선 유저에 의해 브라우저로 부터 검색 요청이 들어오면 백엔드에서 가장 먼저 Redis에 들어가서 검색어를 뒤진다.(Redis에는 등록해놓은 정보들에 관한 index/책갈피가 저장되어 있는데, index는 짧은 단어들로 구성되어 있어서 빠르게 찾을 수 있다.)
-
Redis에 유저가 찾는 정보가 있다면 Cache-hit(정보를 찾는데 성공)하였기 때문에 간단한 원리로 다시 브라우저에 찾은 데이터 결과를 보내줄 수 있다.
-
하지만 Redis에 유저가 요청한 정보를 찾을 수 없을 땐, Cache-miss(정보를 찾는데 실패)헀기 때문에, 백엔드에서는 Redis에서 방향을 틀어 Elasticsearch에서 검색어를 뒤지기 시작한다.
-
이 때 Elasticsearch에서는
이미 Logstash를 통해 Mysql이라는 데이터베이스에서 문장 검색용 데이터들을 Polling(도둑질?)해 저장되어 있는 상태이다.
*추가적으로 Kibana는 elasticsearch에 저장되어 있는 데이터들을 조회 할 때 그래프나 통계 등과 같은 데이터들을 시각화 해서 변형해주는 역할을 맏고 있다.
-
이 때 elasticsearch에서 찾은 데이터 즉 Redis에서는 못찾고 elasticsearch에서 찾게된 데이터는 이 후 빠르게 다시 찾을 수 있도록 key-value형태의 검색어-결과값 으로 저장되고 다시 찾게되면 Elasticsearch를 거치지 않아도 Redis에서 검색 프로세스가 완료되도록 설정된다(검색속도 향상을 위해).
-
결과적으로 조회된 데이터는 다시 백엔드를 거쳐 브라우저로 전달된다.
