1. BERT 개요
- 2018년 여러 NLP task에서 SOTA를 기록한 모델
- 그림1과 같이 semi-supervised learning step과 특정 처리를 위한 supervised training으로 나뉜다.
 (그림1)
(그림1)
* Example: Sentence Classification
- BERT를 이해하는데 있어서 가장 쉬운방법은 single text를 classification하는 것이다. (그림2)
- 그림2는 pre-training(semi-supervised)된 BERT모델에 classification을 fine-tuning(supervised training)한 형식이다.
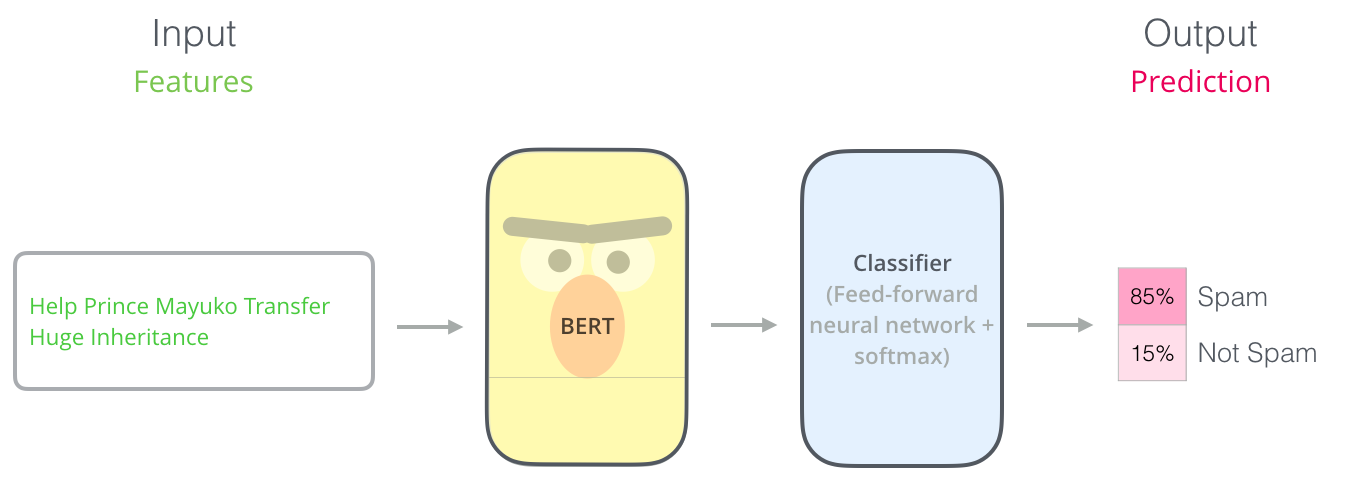 (그림2)
(그림2)
2. Model Architecture
(Sentence Classification을 예시로한 전체적인 구조)
1) BERT는 size에 따라서 base와 large모델로 나뉘게 된다.(그림3)
- BERT BASE: 다른 transformer 모델들과의 비교를 위해 만들어진 모델
- BERT LARGE: SOTA모델을 위해 만든 모델
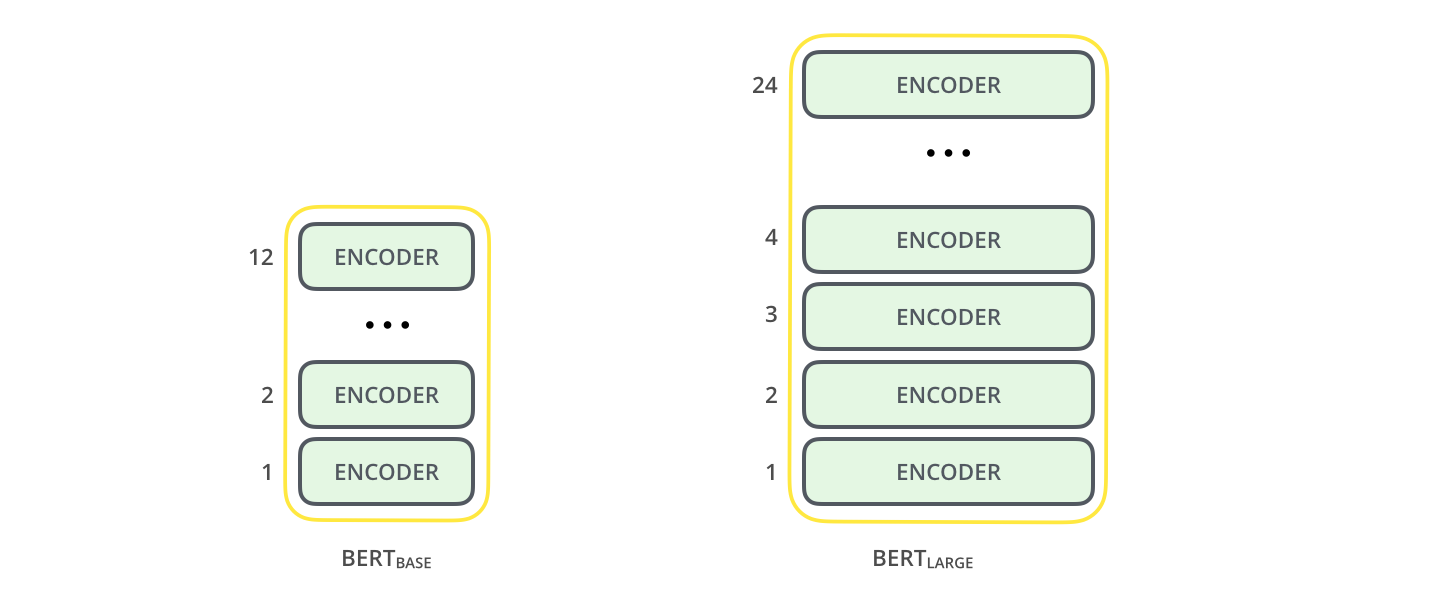 (그림3)
(그림3)
2) BERT는 Transformer Encoder stack만을 이용한 모델이다.(그림4)
 (그림4)
(그림4)
3) Model Inputs (그림5)
- [CLS]로 시작 임베딩임을 알린다.
- Encoder는 stack으로 계속 쌓일 수 있으며 계속 self-attention된다.
 (그림5)
(그림5)
4) Model Outputs
- 각 위치에서 hidden_size(BERT Base의 경우 768)크기의 벡터를 출력한다.
- 위 예시로 봤을때 [CLS]의 출력에만 초점을 맞춘다. (그림6)
 (그림6)
(그림6)
3. Model Pre-training
1) Masked Language Model (그림7)
- BERT는 forward와 backward 양쪽을 동시에 학습하고자 하였다.
- 15% 를 랜덤으로 [MASK]로 두었으며 이를 학습 시켰다.
- 이를 “masked language model”이라 한다.
- 이 외에도 fine-tuning이 더 잘 되도록 [MASK]가 아닌 아에 다른 단어를 넣기도 하였다.
 (그림7)
(그림7)
2) Two-sentence Tasks (그림8)
- 두개의 문장이 [SEP]로 구분된다
- 첫번째 문장 다음으로 오는 문장이 두번째 문장인지에대해 학습한다.
 (그림8)
(그림8)
4. Task specific-Models
- Pre-training된 BERT모델은 그림9와 같은 Task를 할 수 있다.
 (그림9)
(그림9)
5. BERT vs GPT vs ELMo
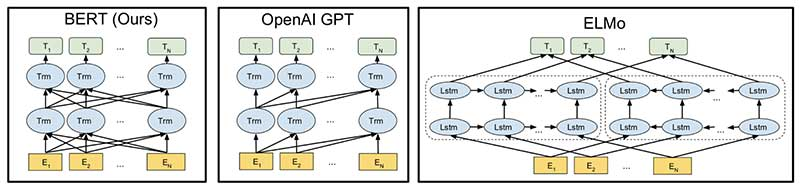
6. Reference
http://jalammar.github.io/illustrated-bert/
https://arxiv.org/pdf/1810.04805.pdf&usg=ALkJrhhzxlCL6yTht2BRmH9atgvKFxHsxQ

Data Analytics Engineer