
Logstash
- 다양한 소스에서 데이터를 수집하여 변환한 후 자주 사용하는 저장소로 전달하는 기능
- 플러그인 기반
- 파이프라인을 구성하는 각 요소들은 전부 플러그인 형태
- 기본 플러그인 외에도 수많은 커뮤니티 플러그인이 있음
- 플러그인 개발을 위한 프레임워크와 플러그인을 관리 할 수 있는 기능도 제공
- 모든 형태의 데이터를 처리
- 플러그인들의 조합으로 다양한 형태의 데이터를 입력받아 가공한 다음에 저장이 가능
- 성능
- 자체적 내장 메모리, 파일 기반의 큐를 통해 안정성이 높고 처리속도가 빠르다
- 메모리 사용:
- 엘라스틱서치는 데이터 처리를 위해 메모리를 활용합니다. 메모리는 데이터를 빠르게 읽고 쓸 수 있는 장점이 있어서 검색 및 색인 작업의 속도를 향상시킵니다. 엘라스틱서치는 자주 사용되는 데이터나 검색에 많이 참조되는 데이터를 메모리에 캐시하여 빠른 응답 속도를 제공합니다.
- 파일 기반 큐 사용:
- 데이터를 안정적으로 처리하고 저장하기 위해 엘라스틱서치는 파일 기반 큐를 사용합니다. 파일 기반 큐는 데이터를 일시적으로 저장하고 처리하는 데 사용되는 구조입니다. 엘라스틱서치는 데이터를 인덱싱하거나 검색 요청을 처리하는 동안에도 파일 기반 큐를 활용하여 안정성을 유지합니다. 이는 예기치 않은 문제가 발생할 경우에도 데이터의 일관성과 안전성을 보장합니다.
- 메모리 사용:
- 벌크 인덱싱 및 파이프라인 배치크기 조정을 통한 병목현상을 방지한다
- 성능 최적화가 가능하다
- 자체적 내장 메모리, 파일 기반의 큐를 통해 안정성이 높고 처리속도가 빠르다
- 안정성
- ES의 장애상황에 대응하기 위한 retry로직이나 오류가 발생한 도큐먼트를 따로 보관하는 Dead-Letter-Queue를 내장하고있다
Pipeline
-
개요
- 데이터를 입력받고 실시간으로 변경하고 변경한 데이터를 다른시스템에 전달
- input, output이 필수 구성요소
- Filter는 Optional
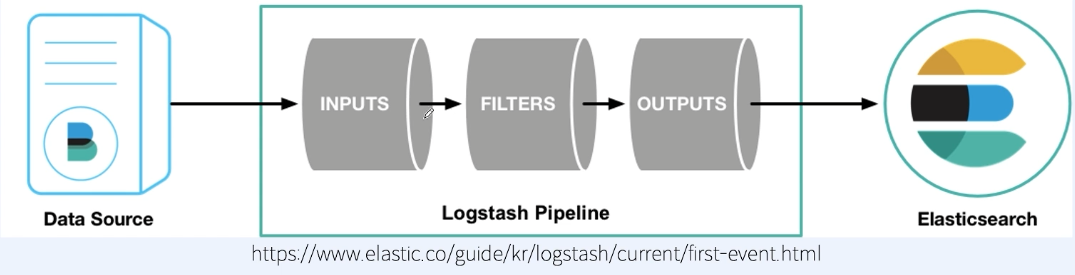
-
Input
- 외부에서 데이터를 받아오는 영역
- 자주 사용하는 플러그인
- file: 경로 지정한 파일을 읽는 방식
- syslog: 리눅스 시스템에서 시스템로그를 읽음 (port514)
- redis: redis에 있는 데이터를 읽는 방식
- beats: beats에서 데이터를 읽는 방식
-
Filter
- 입력 받은 데이터를 조건에 맞게 가공
- 자주 사용하는 플러그인
- grok
- grok패턴(정규식 비슷)을 사용하여 메시지를 구조화된 형태로 분석
- 대부분의 텍스트 포맷을 처리할 수 있음
- mutate: 필드이름 변경, 삭제, 추가
- gsub: 가장 상단에서 grok에 보낼 메시지를 미리 전처리할 작업이 있을때 사용
- date
- 문자열을 지정한 패턴의 날짜형으로 변경
- 실제 로그파일에 찍힌/적힌 시간으로 엘라스틱에 적재하기 위해 원하는 filed로 재설정
- grok
-
Output
- 입력과 필터를 거친 데이터를 Target대상으로 보내는 단계
- 자주사용하는 플러그인
- elasticsearch
- elasticsearch indexing을 수행
- 시계열 데이터 세트 (로그, 이벤트, 지표) 비시계열 데이터 모두 전송이 가능
- file: 파일에 output데이터를 저장
- kafka: kafka topic에 데이터를 전송
- elasticsearch
Kibana
-
개요
- ES데이터를 시각화
- elastic stack을 탐색
- 저장된 데이터를 분석 및 시각화
- 데이터 패턴 및 동향 파악 -> 인사이트 획득
- 여러 그래프와 차트를 한눈에 볼 수 있는 화면제공
- 데이터와 성능을 실시간 모니터링
-
구성요소
- Discover: 데이터 확인
- Visualize: 데이터 시각화
- Dashboard: 시각화 차트 모아보기
- Setting: 인덱스 등록 및 설정

Data Analytics Engineer