
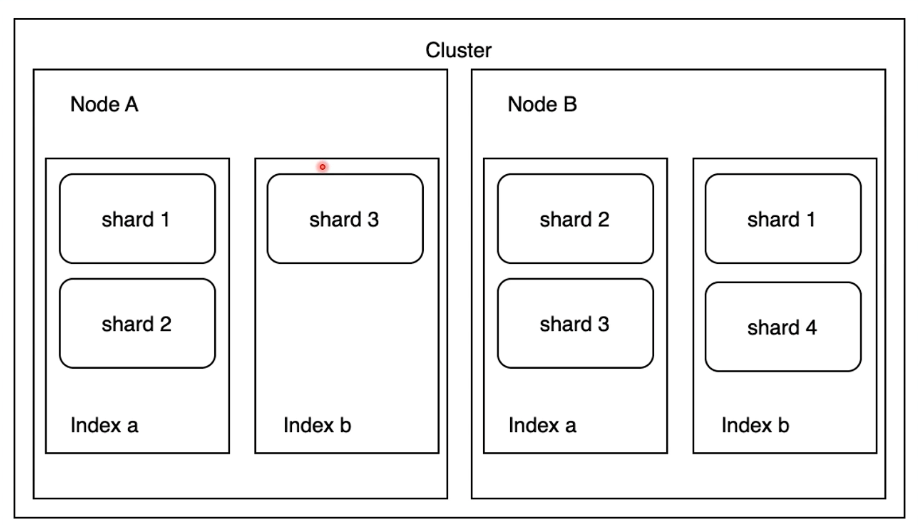
클러스터
- 노드의 집합
- 모든 노드를 포괄하는 통합 색인화 및 검색 기능을 제공
- 고유의 이름을 가짐
- 클러스터에 하나의 노드만 있는것도 가능
- 고유한 클러스터를 여러개 둘 수도 있음
노드
- ES를 구성하는 서버
- 데이터를 저장하고 클러스터의 Indexing 및 검색기능
- 노드에도 고유한 이름이 존재 (기본: UUID)
- 클러스터 이름을 통해 해당 클러스터에 속할 수 있음 (바인딩)
- 노드의 종류
마스터 노드
- 클러스터 상태 정보를 관리
- 지연이 없고 네트워크 가용성이 좋은 노드여야 한다
- 마스터 노드는 하나
- 최소 마스터 노드 대수 설정이 필요
- 클러스터의 상태 관리를 담당하는 노드들의 최소 개수를 보장하는 것이 중요
- Split Brain
- 마스터 후보 노드간 네트워크가 단절되었을때 각각의 마스터 후보가 마스터로 승격되어 두개의 클러스터로 나뉘어 독립적으로 동작하는 현상
- 양쪽 클러스터에서 각각 데이터 쓰기, 업데이트가 이루어지면 네트워크가 복구되어도 마스터가 따로 존재하기 때문에 데이터 비동기 문제로 데이터의 문제가 발생된다
- 방지
- discovery.zen.minimum_master_nodes
- (master_eligible_nodes/2) +1 로 설정
- 마스터 노드 후보 개수를 홀수로
- split brain이 발생 후 네트워크가 복구 되었을때
- 투표를 통해 두 클러스터중 하나를 선택
- 선택된 클러스터 기준으로 데이터를 맞춤
- 짝수 노드인경우 반반으로 나뉘어 결과가 도출되지 않음
- n/2+1조건을 통해 조건을 넘지 못하는 분리된 클러스터는 동작하지 못하게 하고 나머지 클러스터는 운영되도록
- 짝수개로 설정해 놨다면 둘다 중지된다
- discovery.zen.minimum_master_nodes
- 클러스터가 1개의 노드로 이뤄져있으면 1개의 노드가 마스터 노드가 된다
- 기존 마스터 노드가 다운이되면, 다른 마스터 후보 노드중 하나가 마스터노드로 선출이 되어 마스터 노드의 역할을 대신 수행
- 마스터 후보노드들은 처음부터 마스터 노드의 정보들을 공유하고있기 때문에 즉시 마스터 역할의 수행이 가능
- 노드와 샤드의 개수가 많은상황이면, 일부 노드만 마스터노드 옵션을 true로 하여 부하를 줄이도록 하는게 좋음
데이터 노드
- 문서가 저장되는 노드, 샤드가 배치된다
- 인덱싱 작업에 리소스를 많이 소모하므로 리소스 모니터링이 필수적
- 인덱싱 작업이 많은 데이터를 처리하면 CPU 사용량이 증가할 수 있습니다. 이를 모니터링하면 CPU 부하가 과도하게 높아지는 문제를 파악하여 추가적인 리소스 할당이 필요한지 판단할 수 있습니다.
- 또한, 인덱싱 작업이 디스크 I/O를 많이 사용한다면 디스크 용량이 부족한지 확인하고 대응할 수 있습니다.
- 마스터 노드와 분리하는 것을 추천
- 인덱싱할 문서가 적다면 괜찮음
- 마스터 후보 노드들
- node.data:false로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 설정이 가능
코디네이팅 노드
- 들어온 요청을 분산시켜주는 노드
- round-robin방식을 사용
인제스트 노드
- 색인 전에 데이터를 처리한다
- 데이터 포맷 변경을 위해서 스크립트로 파이프라인을 구성할 수 있다

Data Analytics Engineer