
ElasticSearch?
- 텍스트, 숫자, Geosparial, 정형 및 비정형 데이터 등의 데이터에 대한 검색, 분석이 가능한 검색엔진 or information retrieval 라이브러리
- Apache Lucene을 기반으로 구축됨
- Rest API, 분산처리, 속도, 확장성의 특징
- ELK Stack
- 핵심 구성요소
- Elasticsearch
- Logstach
- Kibana
Apache Lucene
- 루씬은 확장 가능한 고성능 정보검색(Information Retrieval) 라이브러리 이다.
- 루씬은 소프트웨어 프로그램에 색인과 검색 기능을 간단하게 추가할 수 있도록 지워한다
- 하둡 개발자인 더그 커팅이 개발했다
- 이 라이브러리를 이용해 Elasticsearch, Solr이 실행된다
- Full Text 검색에 유용하다
- Full Text검색이란 긴 장문의 문자열 속에서 일부를 검색해도 나오는것을 의미
- 긴 문장에 대해 파싱하고 Analyzer가 분석해 검색에 필요한 인덱스를 생성한다
- Full Text검색이란 긴 장문의 문자열 속에서 일부를 검색해도 나오는것을 의미
-
파싱(parsing):
- 우선, 검색 엔진은 우리가 입력한 "과일"이라는 키워드를 작은 단위로 분리하여 처리해야 합니다. 예를 들어, "과일"이라는 단어는 단어 단위로 파싱될 수 있습니다.
-
인덱스 생성:
- 파싱된 단어인 "과일"은 검색을 빠르고 효율적으로 수행하기 위해 인덱스를 생성하는 과정을 거칩니다.
- 검색 엔진은 "과일"을 포함하는 문서, 웹 페이지, 또는 다른 데이터 소스를 인덱싱하여 특정 기준에 따라 구조화된 데이터로 만듭니다.
- 이 인덱스는 키워드 "과일"과 해당하는 문서나 데이터의 위치를 매핑하여 저장합니다.
-
검색 수행:
- 이제 우리가 "과일"이라는 키워드로 검색을 수행하면, 검색 엔진은 미리 생성한 인덱스를 활용하여 빠르게 관련된 결과를 찾을 수 있습니다.
- 인덱스를 통해 "과일"이라는 키워드와 관련된 문서나 데이터를 신속하게 찾아내고, 이를 우리에게 제시합니다.
이렇게 파싱된 데이터와 인덱스 생성은 검색 엔진이 키워드 검색을 빠르고 효율적으로 처리할 수 있도록 도와줍니다. 파싱은 입력된 데이터를 작은 단위로 분리하고 구조를 분석하는 과정이며, 인덱스 생성은 이러한 파싱된 데이터를 기반으로 효율적인 검색을 위한 데이터 구조를 생성하는 것입니다.
검색엔진
- 컴퓨터 시스템에 저장된 정보를 찾아주거나 웹검색을 도와주도록 설계된 정보검색 시스템 or 컴퓨터 프로그램
- 검색엔진을 사용하면 정보를 찾는데 필요한 시간을 최소화할 수 있다
- 문서수집: 검색하려는 대상 수집
- 문서정제:수집된 비정형 문서를 정형 데이터로 정제하고 가공
- 문서 데이터 색인: 정제된 문서를 빠르게 검색이 가능한 구조로 저장
- 문서검색: 문서 정보에서 검색어 찾기
정보검색 (Information Retrieval)
- 사용자가 입력한 키워드에 대해 적절한 문서를 찾는것
- 정보들은 대량의 문서 형태로 되어있음
- 검색 대상: 비정형/반정형 데이터
- SQL을 사용하지 않고 자연어를 사용
- 정답보다는 관련성을 찾아줌
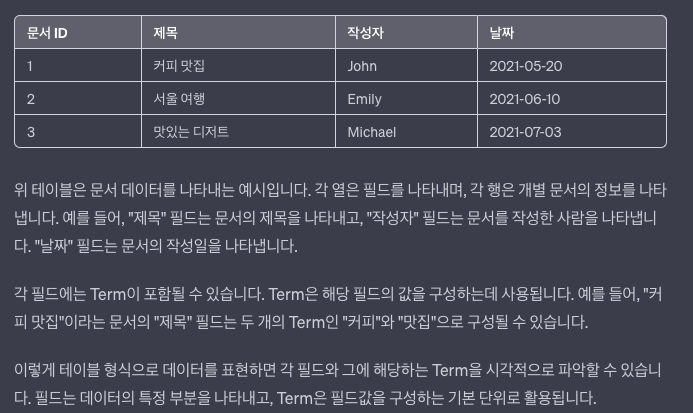
검색엔진 VS RDBMS
- 색인을 통해 검색
- 인덱싱
- RDBMS
- 컬럼기준, id같은 값을 활용해 인덱스를 생성
- 검색엔진
- 필드값을 분해하여 Term형태로 만들어 인덱스 생성
- 필드값을 분해하여 Term형태로 만들어 인덱스 생성
- 검색방법
- RDBMS
- 특정 단어 검색시 전체 컬럼 정보를 하나씩 비교하며 조회
- 검색엔진
- 미리 정의된 색인에서 조회
- RDBMS
- 검색대상
- RDBMS
- 구조화된 대상
- 검색엔진
- 구조화되지 않은 텍스트에 대해서도 검색이 가능
- RDBMS
- RDBMS
ES는 왜 필요할까?
- 단순검색엔진이 아니다
- 검색과 분석을 위한 플랫폼을 표방
- 수집 -> 처리 -> 분석
- 각 단계에 맞는 스택들을 개발
- Logstash (Beats)
- 데이터 수집
- Elasticsearch
- 데이터 처리
- Kibana
- 데이터 분석

Data Analytics Engineer