Kafka?
- streaming을 처리하기위한 분산 platform
- high-performance
- 제조,은행,텔레콤등 많은 큰 회사들이 사용한다.
1. 기본구조
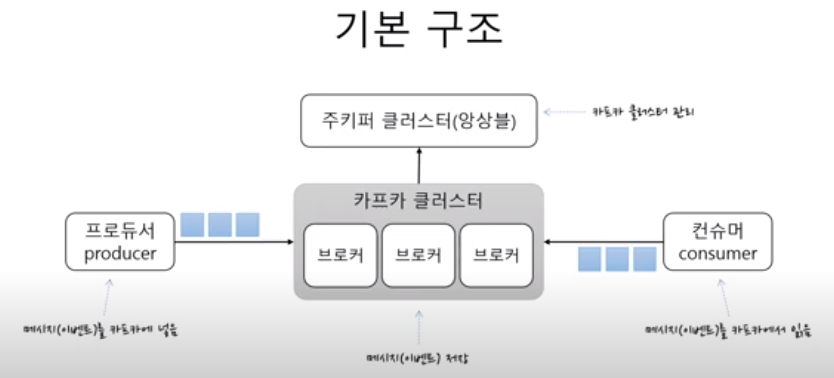
1) 전체구조
- 카프카 클러스터
- 메시지를 저장하는 저장소
- 여러개의 브로커로 구성되어있다.
- 브로커(각각의 서버)
- 이중화처리
- 메세지를 나눠서 저장
- 장애시 대체
- 브로커(각각의 서버)
- 주키퍼
- 카프카 클러스터를 관리
- 프로듀서
- 카프카 클러스터에 메시지를 보냄
- 컨슈머
- 카프카에서 메시지를 읽음
2) 토픽과 파티션
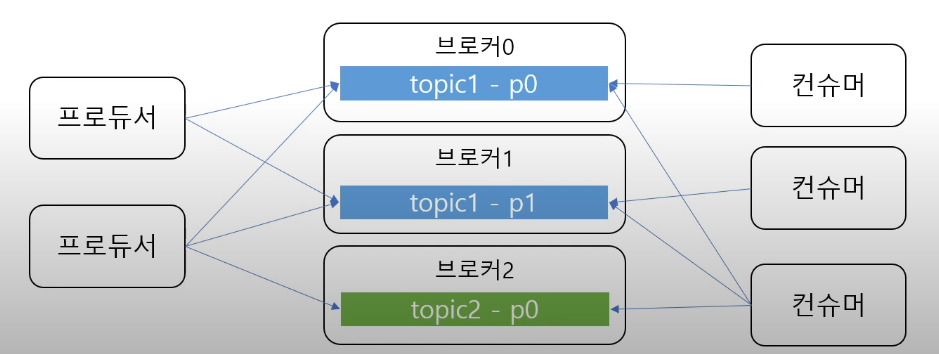
- 토픽: 메시지를 구분하는 단위(폴더와 비슷한 역할)
- 뉴스 토픽, 주식 토픽 등 메시지를 알맞게 구분하기위해 사용
- 한개의 토픽은 한개 이상의 파티션으로 구성
- 파티션: 메시지를 저장하는 물리적인 파일
- 프로듀서와 컨슈머는 토픽을 기준으로 메시지를 주고받는다.
3) 파티션과 오프셋, 메시지 순서

- 파티션은 추가만 가능한(append-only) 파일
- 각 메시지 저장 위치를 offset이라고 한다.
- 프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가 된다.
- 컨슈머는 오프셋 기준으로 메시지를 순서대로 읽는다.
- 메시지는 삭제되지 않는다.
- 설정에 따라 일정 시간이 지난 뒤 삭제된다.
4) 여러 파티션과 프로듀서
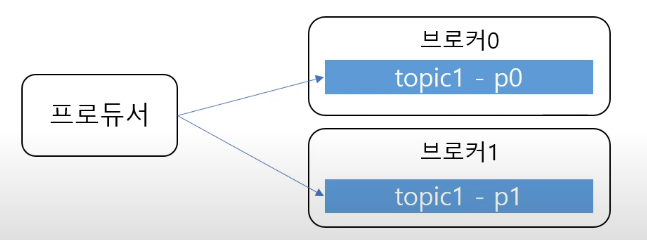
- 프로듀서는 라운드로빈 또는 key로 파티션을 선택한다.
- 같은 key를 갖는 메시지는 같은 파티션에 저장 -> 칻은 키는 순서 유지
5) 여러 파티션과 컨슈머
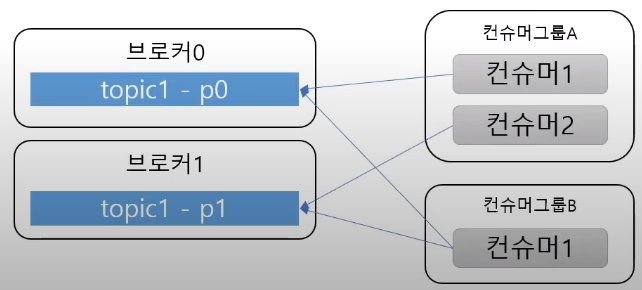
- 컨슈머는 컨슈머 그룹에 속한다.
- 한개의 파티션은 컨슈머그룹의 한개 컨슈머만 연결이 가능
- 즉, 컨슈머 그룹에 속한 컨슈머들은 한 파티션을 공유할 수 없음
- 한 컨슈머그룹 기준으로 파티션의 메시지는 순서대로 처리된다.
- 순서보장
6) 성능
-
파티션 파일은 OS 페이지캐시 사용
- 파티션에 대한 파일 IO를 메모리에서 처리
- 서버에서 페이지캐시를 Kafka에만 사용해야 성능에 유리
-
Zero Copy
- 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사
-
컨슈머 추척을 위해 브로커가 하는일이 비교적 단순
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않음
- 프로듀서, 컨슈머가 직접 해야한다.
- 브로커는 컨슈머와 파티션 간 매핑관리
- 메시지 필터, 메시지 재전송과 같은 일은 브로커가 하지 않음
-
묶어서 보내기, 묶어서 받기(batch)
- 프로듀서: 일정 크기만큼 메시지를 모아서 전송가능
- 컨슈머: 최소 크기만큼 메시지를 모아서 조회가능

-
처리량 증대(확장)가 쉽다.
- 1개 장비의 용량한계 -> 브로커 추가, 파티션 추가
- 컨슈머가 느림 -> 컨슈머 추가(+파티션 추가)

7) 리플리카 - 복제
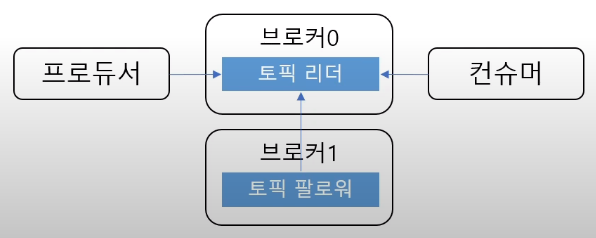
- 리플리카: 파티션의 복제본
- 복제수 만큼 파티션의 복제본이 각각 브로커에 생김
- 리더와 팔로워로 구성
- 프로듀서와 컨슈머는 리더를 통해서만 메시지 처리
- 팔로워는 리더로 부터 복제
- 장애 대응
- 리더가 속산 브로커 장치에 다른팔로워가 리더가됨.
Reference

Data Analytics Engineer