
group by를 통해 묶어준 후 묶인 데이터에 대해 순위를 정해줘야하는 상황이 있다.
예를들어 아래 강남구는 cnt가 높은것만 뽑아야한다
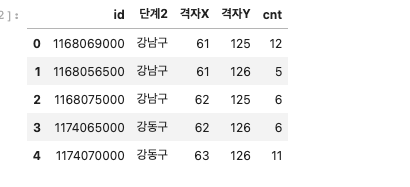
이런경우 sort_values를 통해 해결 할 수 있다.
df_xy.sort_values(['cnt'], ascending=[False]).groupby(['단계2']).cumcount()위 코드를 통해 각 그룹에 대한 랭킹이 지정된다.
df_xy[df_xy.sort_values(['cnt'], ascending=[False]).groupby(['단계2']).cumcount() + 1 == 1]최종적으로 group by 로 묶여있는 값들중 cnt가 가장 큰 값들만 가져왔다.
gooooood!

Data Analytics Engineer