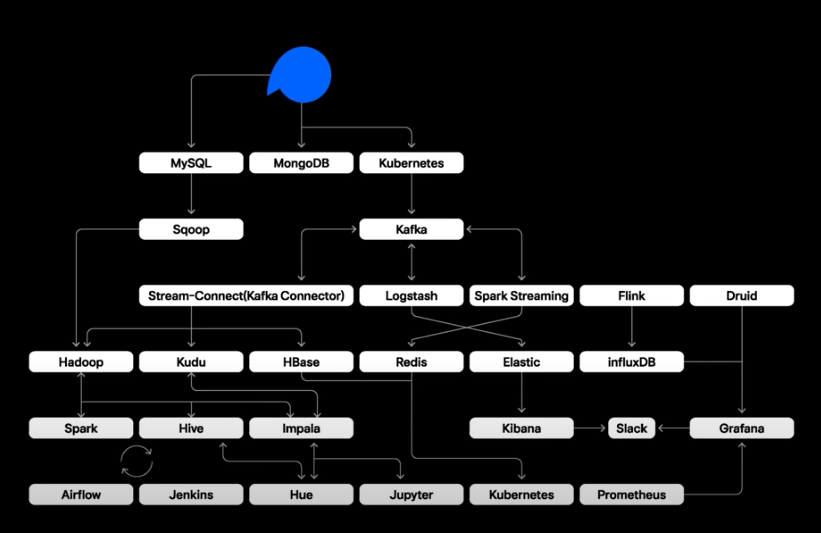
 <데이터 흐름도>
<데이터 흐름도>
1. 데이터 정의
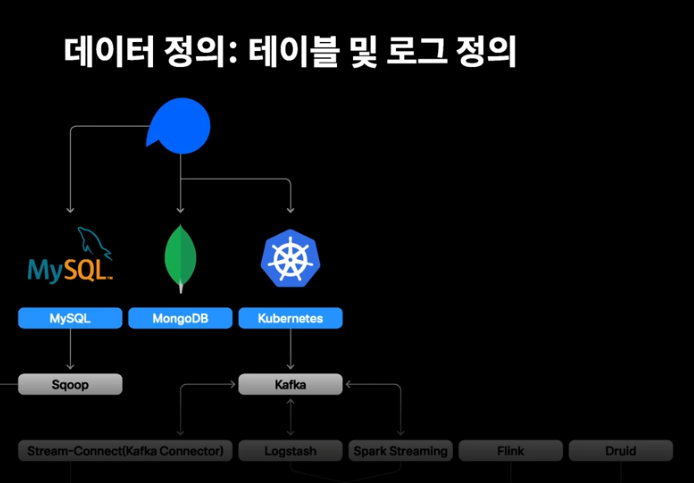
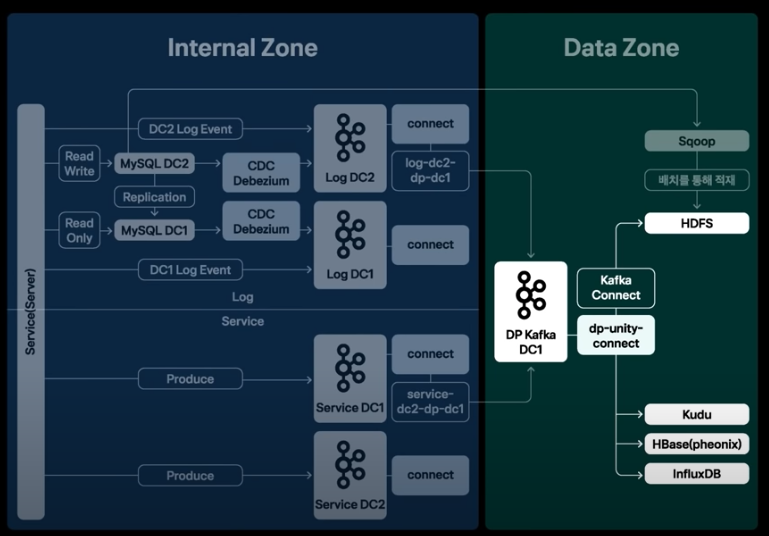
- db와 서비스 API의 로그를 Extract하는 과정
- 로그를 입수하는 과정에서 여러 휴먼에러가 있었고 히스토리를 찾기 어려웠다.
- 로그 정의 시스템 개발 (서비스별 로그를 정의하고 검색 및 관리 할 수 있는 툴)
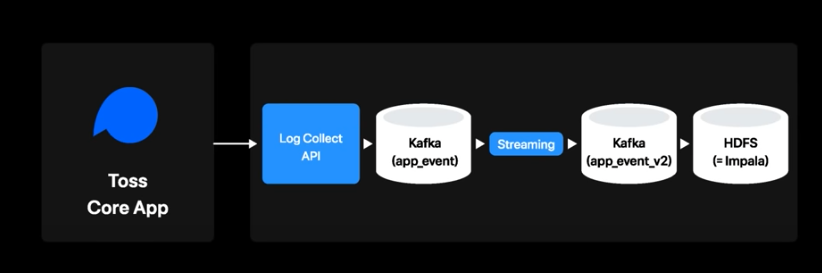
- kafka에 적재된 토픽 로그들은 스트리밍 처리를 통해 로그센터에 정의된 스키마와 비교하여 valid체크를 수행
- 로그에 이상이 있는경우 slack으로 자동알림
2. 데이터 수집 및 저장
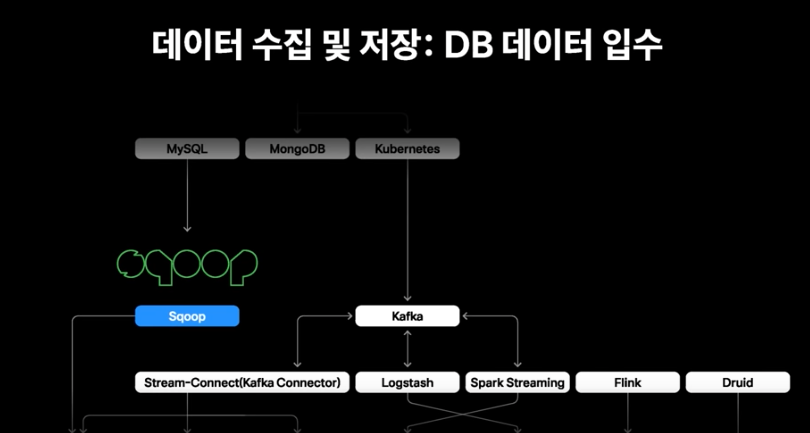
- Mysql: sqoop을 통해 적재
- MongoDB : hive mongo storage handler를 통해 적재
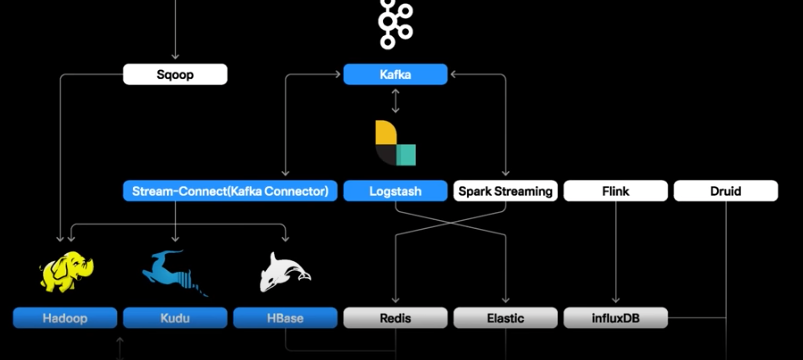
- HDFS, Kudu, HBase등에 적재된다.
3. 데이터 추출, 가공, 적재(ETL): 배치 프로세싱
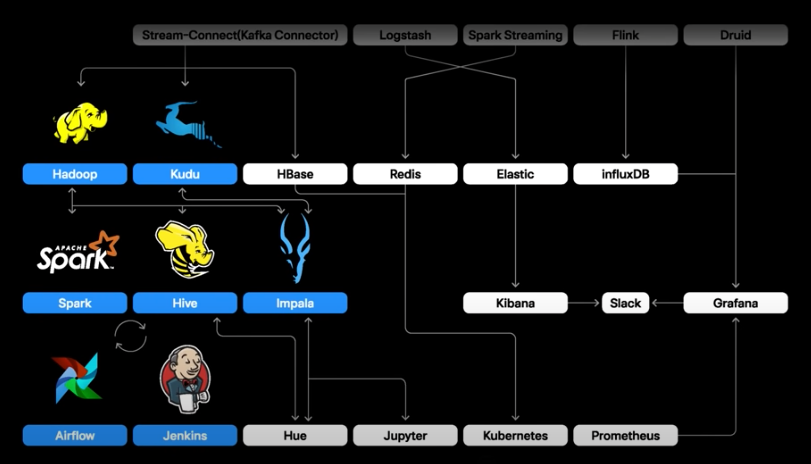
- spark, hive, impala로 분석하고 airfow 및 jenkins로 workflow를 관리
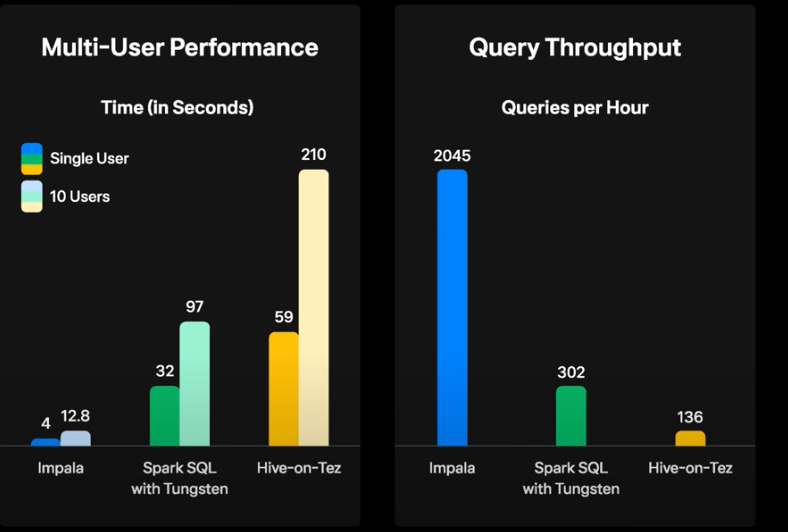

- 주로 EDA, ETL시 Impala를 이용 (가장 속도가 빠르다.)
- SQL의 제한적인 부분이나 복잡도 높은 처리는 Spark을 사용
- 대용량의 경우 Hive사용
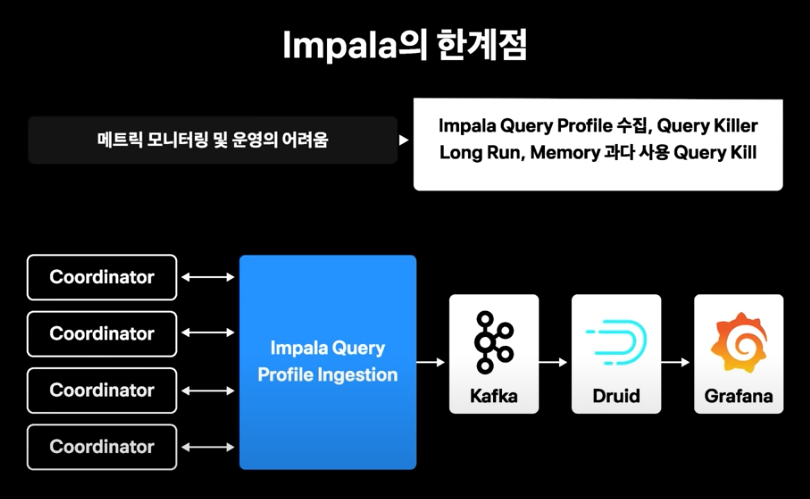
- 클러스터 통합 메트릭을 제공하지 않기 때문에 전체 클러스터 사용량에 대한 메트릭을 수집하기 어려웠음
- 각 코디네이터에서 제공하는 쿼리 프로파일을 수집해서 kafka로 적재하고 druid supervisor를 이용해 druid로 실시간 적재된 데이터를 grafana로 모니터링
- long run 쿼리나, 전체 클러스터에서 사용하는 리소스가 과다한경우 우선 차단 시스템 개발
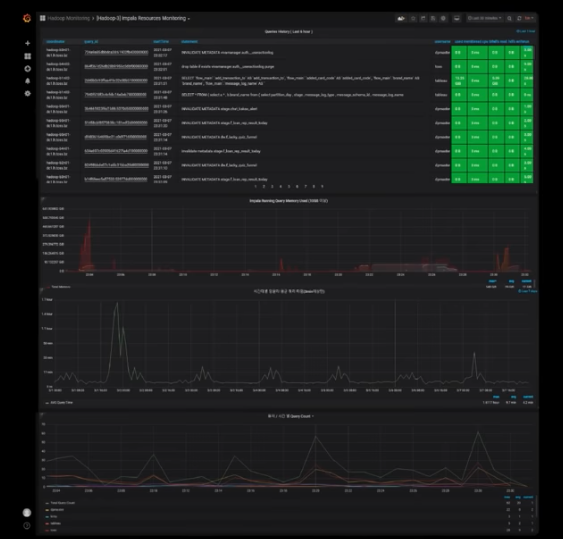 <Grafana 대시보드>
<Grafana 대시보드>
- 쿼리 히스토리와 리소스를 모니터링 가능하도록 구성
- 이러한 기술을 이용하여 ETL로 Impala를 주로 사용함
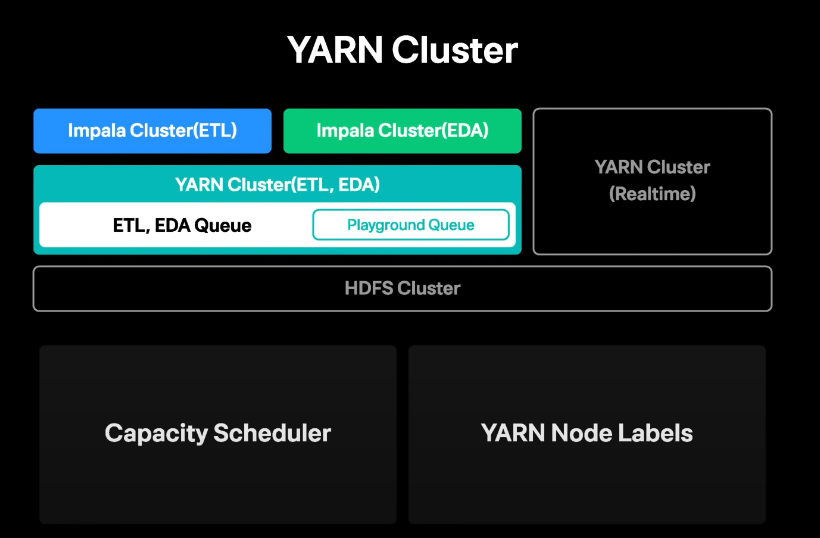

- 간단한 배치작업의 경우 젠킨스 사용
- Dpendency가 복잡한 주요 ETL의 경우 Airflow 사용
3-1. 리얼타임 프로세싱
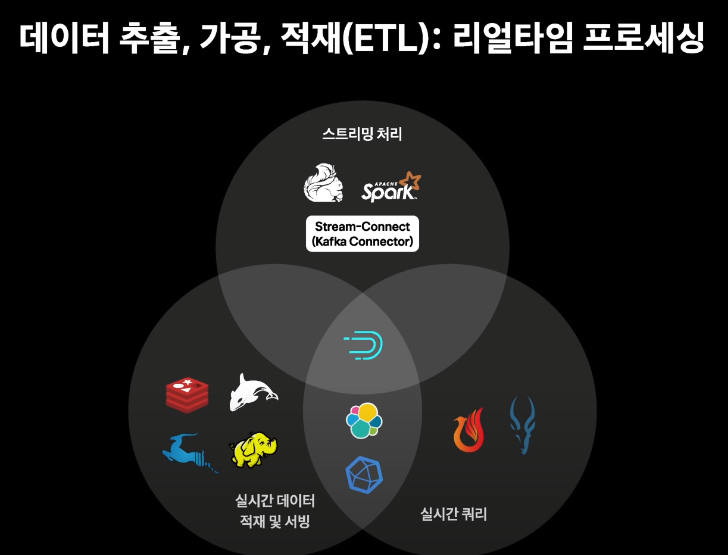
- 스트리밍처리에는 Flink, Spark Streaming, Druid를 사용
- 실시간 데이터 적재 및 서빙으로는 InfluxDB, Redis, HBase, Hadooop, Kudu, ES, Druid 등이 활용
- 실시간 쿼리엔진으로는 Druid, ES, InfluxDB, Impala+Kudu 조합으로 사용
- 실시간 가공, 집계, 이상징후감지, 데이터서비스 모니터링, OLAP등을 수행
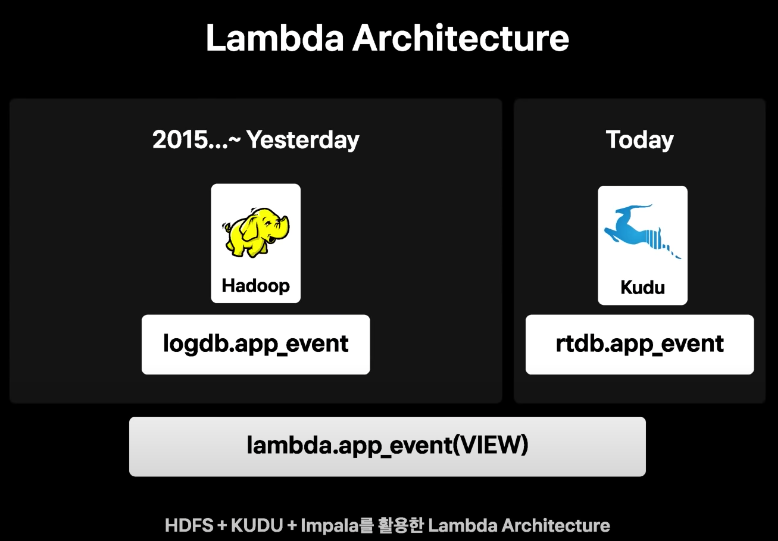
- impalasms HDFS에 실시간으로 적재되는 데이터와 싱크가 되지 않기때문에 오늘 데이터만 kudu db에 넣어 조회하도록함
4. 데이터 분석(EDA)
4-1. Query & Code 기반 데이터분석
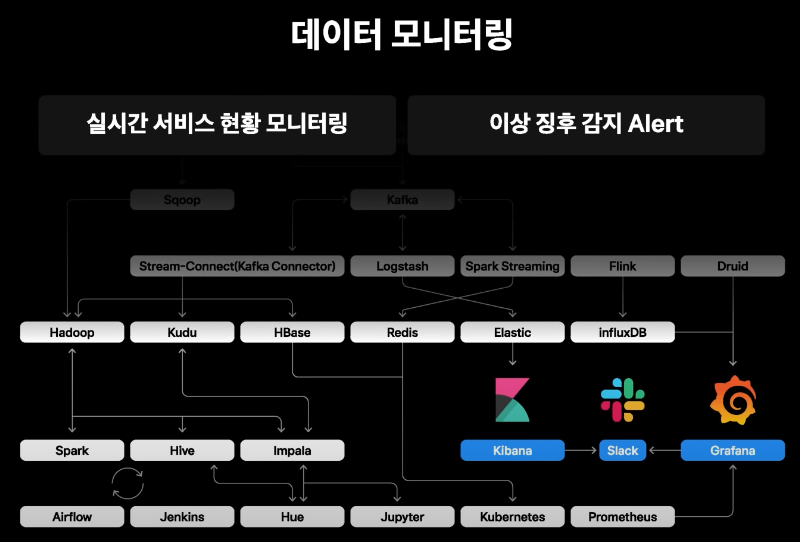
- 하둡 에코시스템이나 서비스메트릭스
- Druid, InfluxDB, Elasticsearch 등을 datasource로 kibana나 grafana를 이용하여 모니터링하고 slack으로 alerting수행
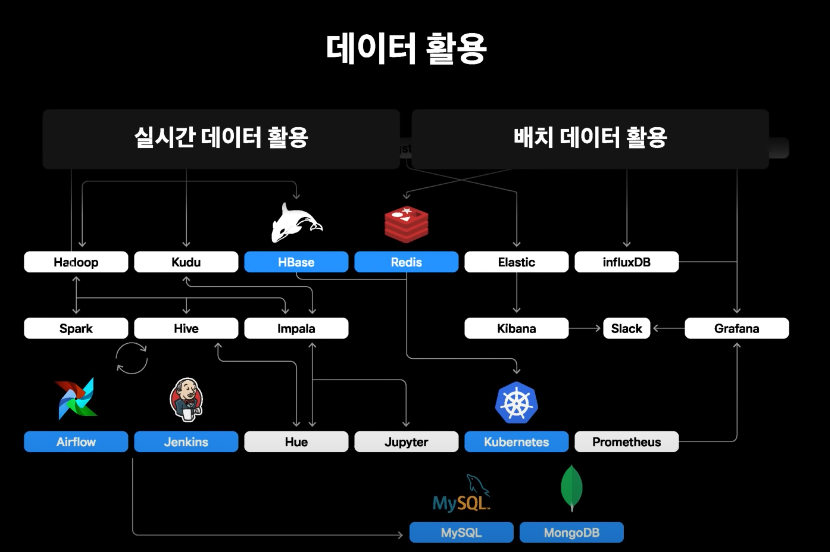
- 배치데이터는 mysql or mongodb에 주기적으로 적재하여 어플리케이션에 활용
5. 데이터 모니터링
Reference

Data Analytics Engineer