🙋♂️ HashTable이란?
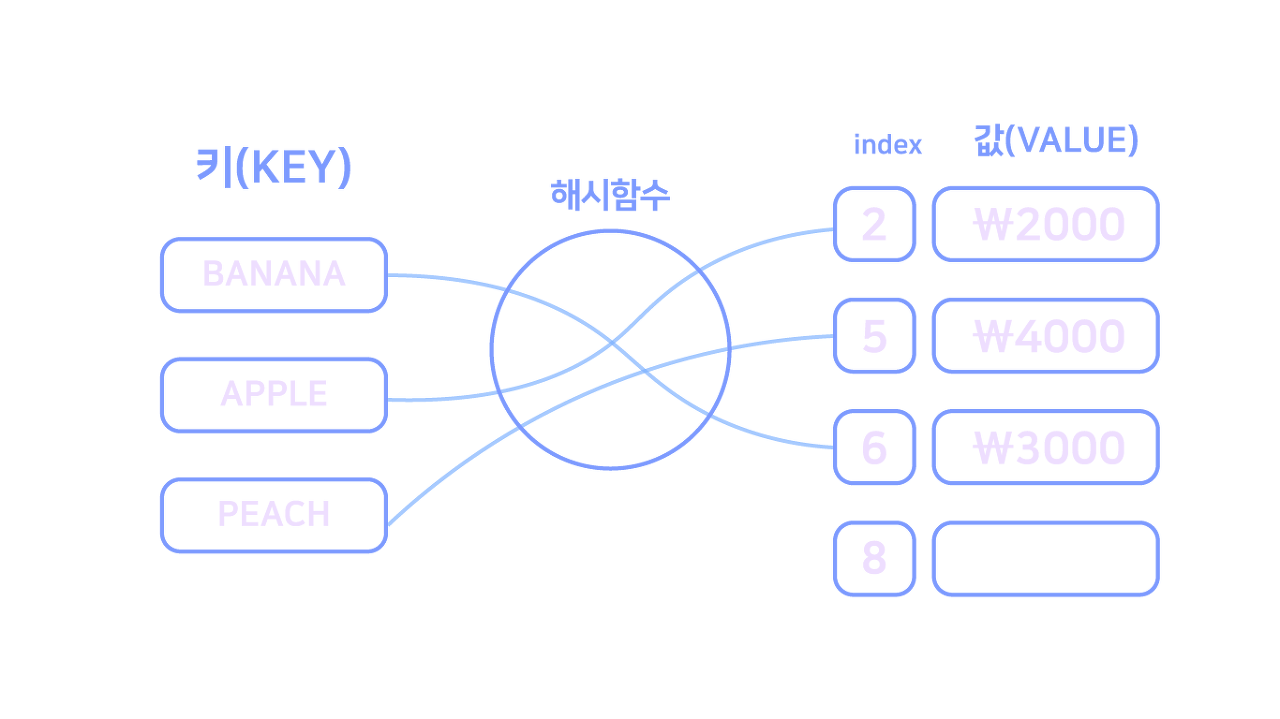
HashTable이란
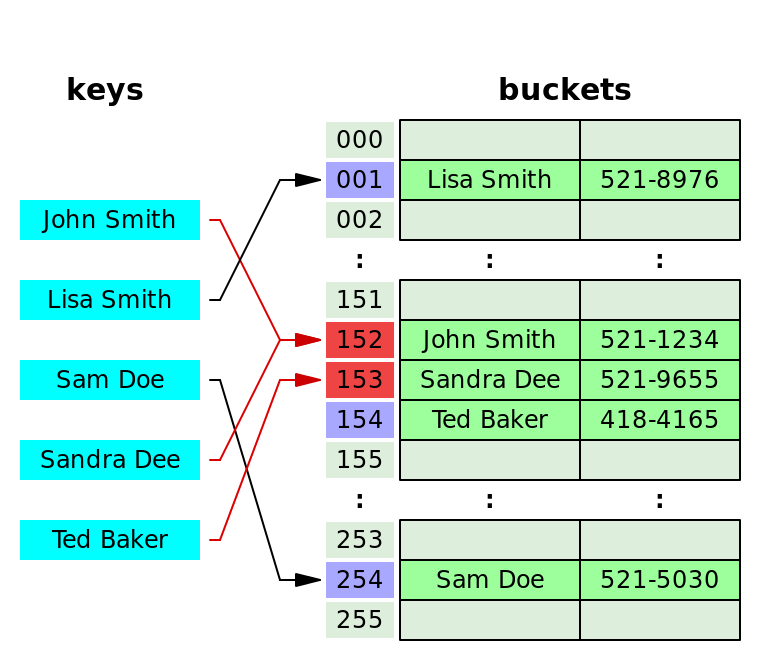
HashTable또는HashMap은 키를 값에 매핑할 수 있는 구조를 가진다.
해시함수를 통해 해싱하여key,value를 저장한다.
위의 이미지와 같이key를 해시함수에 넣어 배열의 인덱스로 사용하면서 데이터를 저장한다.
🤷♂️ 해시함수란?
임의의 길이를 갖는 데이터를 고정된 길이의 데이터로 매핑한다.
(key를 해싱하면 해시값 또는 해시코드라고 한다.)
key와value으로 매핑되는 과정을 해싱(hashing)이라 한다.
👓 특징
HashTable은 아래와 같은 특징이 있다.
key value 저장, 해시함수의 경우에는 위에서 설명했으니 충돌처리에 대한 부분을 알아보자.
keyvalue저장- 해시함수 사용
- 충돌 처리
🧹 충돌처리
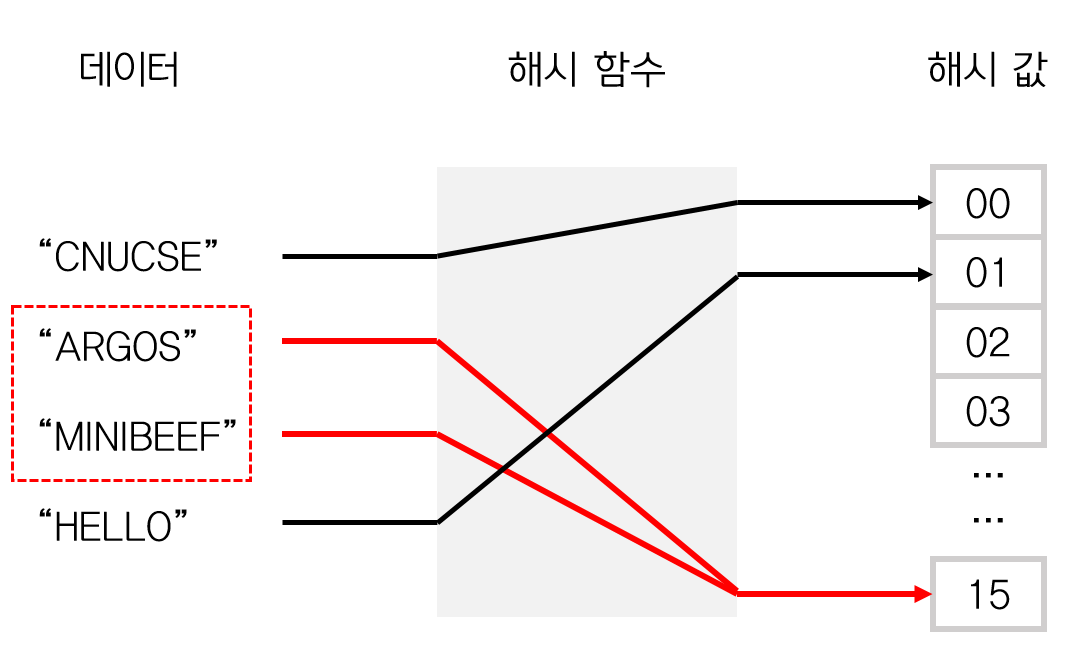
위의 이미지와 같이 다른 key를 해시 함수로 해시값 또는 해시코드를 생성했을때 동일한 해시값이 나올 수 있다. 이런 경우를 해시충돌(collision) 이라고 한다.
보통 이런 경우 해시충돌을 해결하는 방법이 2가지가 존재하는데 아래에서 알아보자
분리 연결법(Separate Chaining)
동일한 해시값에(동일한 버킷에) 저장되어야 하는 데이터가 있는 경우에 사용한다.
보통 LinkedList를 활용하거나 Tree구조를 사용하여 해결한다.
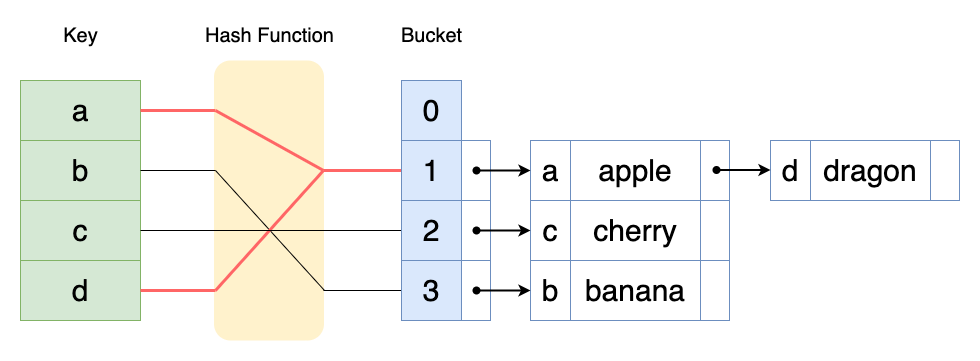
위의 이미지처럼 LinkedList의 구조나 Tree구조를 활용해 동일한 해시값(동일한 버킷)에
Chaining을 걸어 다음 데이터를 저장하여 충돌을 해결할 수 있다.
장단점
위와 같이 충돌을 해결할 경우에는 손쉽게 충돌을 해결할 수 있는 장점이 존재하지만, 데이터의 수가 많아질수록 탐색하는 시간이 많이 소요된다. 또한 Tree구조를 사용하면 삽입,삭제,조회에선 좋은 성능을 보여주지만, 메모리 사용량이 많다는 단점이 존재한다. LinkedList 또한 다음 Node를 가리키는 포인터를 위한 공간이 필요하기 때문에 메모리가 낭비될 수 있다.
개방 주소법(Open Addressing)
개방 주소법은 저장해야하는 해시값 또는 해시코드에 값이 존재하면 비어있는 다른곳에 저장하는 방법이다. (선형 탐사)
장단점
개방 주소법은 메모리 효율 측면에서 분리 연결법보다 좋다.
하지만 key하나에 하나의 value만 저장하기 때문에 가득차게 된다면 확장이 필요할 수 있다.
🛠️ 구현
HashTable을 간단히 구현해보고 하나씩 설명하려 한다.
우선 HashTable의 역할을 하는 Class를 구현하고 Hashing을 하는 메서드를 작성해보자.
HashTable
만들고 있는 HashTable은 Collision을 LinkedList의 구조의 형태로 해결하며 구현한다.
public class HashTable {
private int size = 7;
private Node[] dataMap; // HashTable(Bucket은 Node의 구조를 따른다.)
// HashTable 생성자
public HashTable() {
dataMap = new Node[size];
}
class Node {
String key;
int value;
Node next;
// 생성자
Node(String key, int value) {
this.key = key;
this.value = value;
}
}
// 해시함수(Ascii 값을 사용해 해싱하는 해시함수임)
public int hash(String key) {
int hash = 0;
char[] keyChars = key.toCharArray();
for(int i = 0; i < keyChars.length; i++) {
int asciiValue = keyChars[i];
hash = (hash + asciiValue * 23) % dataMap.length;
}
return hash;
}
}Set
이제 HashTable과 Bucket에 들어갈 Node, 해싱함수가 완성되었으니, 이제 HashTable에 데이터를 저장하는 메서드 Set을 작성해보자
...해시테이블 및 해싱 함수작성 내용...
// HashTable에 데이터를 저장하는 메서드
public void set(String key, int value) {
int index = hash(key);
Node newNode = new Node(key, value);
if(dataMap[index] == null) { // 저장하려는 index에 저장된 데이터가 없으면
dataMap[index] = newNode; // 현재 들어온 데이터를 저장
} else {
Node temp = dataMap[index]; // 저장하려는 index에 데이터가 존재하면
while(temp.next != null) { // 마지막 Node까지 탐색해 temp Node를 갱신
temp = temp.next;
}
temp.next = newNode; // 마지막 Node의 다음을 현재 데이터로 지정
}
}위와 같이 LinkedList의 구조를 활용해 Collision을 고려한 Set 메서드를 작성하였다.
이제 HashTable에 데이터를 저장할 때 충돌은 없다.
Set 개선하기
현재 Set 메서드는 같은 해시값에 대한 충돌은 없지만 Node내부에 Key가 동일한 경우에는 합산되는것이 아닌 다른 데이터로 취급하여 새로운 Node로 저장한다. 만약 같은 Key면 원래 존재하는 데이터에 값을 합산하고 그것이 아니라면 새로 추가하는 방향으로 개선하였다.
public void set(String key, int value) {
int index = hash(key);
Node newNode = new Node(key, value);
if(dataMap[index] == null) {
dataMap[index] = newNode;
} else {
Node temp = dataMap[index];
if(temp.key == key) { // 현재 저장하려는 인덱스에 데이터가 존재하고 키가 같다면
temp.value += value; // 합산하자
return;
}
while(temp.next != null) {
temp = temp.next;
if(temp.key == key) {
temp.value += value; // 여러개일 수 있으니 여기도 처리하자
return;
}
temp.next = newNode;
}
}
}이렇게 하면 저장하려는 해시값에 존재하는 Node중에 동일한 key를 가진 Node가 존재한다면 value를 합산하여 저장하게 된다.
Get
HashTable에 저장된 Node중에서 Key를 이용하여 해당하는 key를 가진 Node의 값을 확인하는 메서드를 작성하였다.
public int get(String key) {
int index = hash(key);
if(dataMap[index] == null) { // 해당하는 해시값에 데이터가 없다면
return 0; // 0을 반환
}
Node temp = dataMap[index]; // 있으면 dataMap의 인덱스에 해당하는 값을 임시 노드에 담는다.
while(temp != null) { // 끝까지 탐색
if(key.equals(temp.key)) { // 해당하는 키를 찾으면
return temp.value; // 해당하는 키의 값을 반환
}
temp = temp.next;
}
return 0; // 끝까지 찾았음에도 없으면 0을 반환한다.
}위와 같이 해당하는 해시값의 데이터가 있는지 없는지에 대한 분기처리를 먼저 진행하고 찾고자 하는 key에 해당하는 데이터가 있는지 탐색하여 있는지 없는지에 대해 다시한번 분기하면 원하는 결과를 얻을 수 있다.
Keys
이번에는 HashTable에 존재하는 모든 key를 반환하는 메서드를 작성해보았다.
ArrayList에 담아 존재하는 모든 Key를 반환해보자.
public ArrayList keys() {
ArrayList<String> allKeys = new ArrayList<>();
for(int i = 0; i < dataMap.length; i++) { // dataMap을 끝까지 탐색
if(dataMap[i] != null) { // dataMap에 현재 인덱스에 해당하는 데이터가 존재하면
Node temp = dataMap[i]; // 임시 노드에 담자
allKeys.add(temp.key); // 해당 키를 List에 add
if(temp.next != null) { // 현재 노드의 next가 또 있으면
while(temp.next != null) { // 충돌을 막기 위해 LinkedList구조를 사용하였으니 다음 노드가 있을지 모른다. 끝까지 탐색
temp = temp.next;
allKeys.add(temp.key); // 끝까지 탐색하면서 탐색된 키를 add
}
}
}
}
return allKeys; // 모든 탐색이 종료되면 key가 담긴 List를 반환하자.
}위 처럼 dataMap을 탐색하면서 임시 Node의 담긴 key를 List에 넣어주었다.
코드를 보면 하나의 조건과 반복문이 중첩으로 또 존재하는데 이는 우리가 분리연결법(Separate Chaining) 을 사용하여 충돌처리를 LinkedList의 구조를 활용해 진행했기 때문이다.
임시노드 temp에 담긴 temp.next 내에서 다른 Node를 가리키고 있을 수 있기 때문에 if의 조건으로 temp.next가 비어있지 않다면, 즉 존재한다면 해당 LinkedList를 탐색한다.
while의 조건으로 temp.next가 null인경우 반복을 멈추게 하여 끝까지 탐색하게 한다.
그 과정에서 존재하는 모든 key를 allKeys라는 List에 add하여 추가한다.
모든 반복이 종료되면 allKeys를 반환하여 메서드를 종료하게 된다.
🙇♂️ 연습 문제
- 2개의 배열을 받고 그 두개의 배열에서 공통되는 항목이 1개라도 존재하는지 확인하는 메서드를 작성한다. 반환 타입은
Boolean이다.
HashMap을 사용하고 O(n)의 시간복잡도를 고려해야한다.
public boolean itemInCommon(int[] arr1, int[] arr2) {
// arr1을 담을 HashMap을 생성
HashMap<Integer, Boolean> hashMap = new HashMap<>();
for(int i : arr1) {
hashMap.put(i, true); // arr1의 요소를 key로 사용하고 값은 전부 true로 넣는다.
}
for(int i : arr2) {
// arr2의 요소값에 해당하는 key가 hashMap에 존재하면 true를 반환한다.
// (공통된 항목이 있다는 소리)
if(hashMap.get(i) != null) {
return true;
}
}
return false; // 만약 여기까지 온다면 공통된 요소가 없다는 말. false를 반환
}- 정수 배열이 주어졌을 때, 해시 테이블(HashMap)을 사용하여 배열 내의 모든 중복을 찾자
반환 타입은List<Integer>로 한다.
public static List<Integer> findDuplicates(int[] nums) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
// 해시맵에 배열의 요소를 key로 사용, getOrDefault를 사용해 value를 0 + 1로 하여 카운트함
for(int num : nums) {
hashMap.put(num, hashMap.getOrDefault(num, 0) + 1);
}
List<Integer> duplicates = new ArrayList<>();
// 해시맵을 순회 탐색하면서 카운트가 1보다 큰 key를 List에 담음
for(Map.Entry<Integer, Integer> entry : hashMap.entrySet()) {
if(entry.getValue() > 1) {
duplicates.add(entry.getKey());
}
}
return duplicates; // 중복된 요소들만 담겼으니 반환
}getOrDefault
첫번째 인자로 전달하는 값이 없을 경우, 두번째 인자로 전달한 값을 기본으로 한다.
- 주어진 소문자 문자열에서 해시테이블(HashMap)을 사용하여 반복되지 않는 첫 번째 문자열을 찾는 메서드를 작성하자. 만약 반복되지 않는 문자열이 없다면
null을 반환한다.
반환 타입은Characterornull
ex) 예를 들어 leetcode라는 문자열이 주어지면 메서드는 l을 반환해야 한다.
public Character firstNonRepeatingChar(String str) {
HashMap<Character, Integer> hashMap = new HashMap<>();
// str을 toCharArray를 통해 char형 배열로 변환하여 순회 탐색
for(char ch : str.toCharArray()) {
// hashMap에 ch를 key로 사용, 해당하는 key가 없으면 0 + 1을 하여 카운트(반복 유무 판단용)
hashMap.put(ch, hashMap.getOrDefault(ch, 0) + 1);
}
for(Map.Entry<Character, Integer> entry : hashMap.entrySet()) {
// 해당 조건에 걸린다면 반복되지 않는 문자임,
// 순차적으로 탐색하기 때문에 제일 먼저 조건에 걸린 문자는 반복되지 않는 문자중 첫번째임
if(entry.getValue() == 1) {
return entry.getKey();
}
}
return null; // 조건에 걸리지 않으면 반복되자 않는 문자열이 존재하지 않는다는것
}- 주어진 문자열 배열에서 해시테이블(HashMap)을 사용하여 애너그램을 찾아 그룹화한
List를 반환해야한다. 반환 타입은List<List<String>>이다.
ex) 예를 들어, 입력 배열이 ["eat", "tea", "tan", "ate", "nat", "bat"]인경우 애너그램그룹은 [["eat", "tea", "ate"], ["tan", "nat"]]이다.
public List<List<String>> groupAngrams(String[] strArr) {
HashMap<String, List<String>> hashMap = new HashMap<>();
for(String str : strArr) {
// 들어온 문자열 배열을 char형 배열로 변환
char[] charArr = str.toCharArray();
// 정렬한다.(정렬하면 알파벳 순서로 정렬된다.)
Arrays.sort(charArr);
String sortedStr = new String(charArr); // 해시맵에 키로 사용
if(!hashMap.containsKey(sortedStr)) { // 해시맵에 해당 키가 존재하지 않으면
// 해당키와 비어있는 ArrayList를 생성하여 해시맵에 추가한다.
hashMap.put(sortedStr, new ArrayList<>());
}
// 해시맵에 해당 키가 존재한다면?
hashMap.get(sortedStr).add(str); // 해당 키의 value인 List를 가져와 그 안에 해당되는 문자를 추가한다.
}
// 검사가 전부 끝났다면 새로운 리스트를 만들어 hashMap에 존재하는
// value(List<String> 타입)을 전부 넣어 반환한다.
return new ArrayList<>(hashMap.values());
}주어진 문자열 배열을 char타입의 배열로 변환환 뒤 Arrays.sort()를 통해 정렬하였다.
Arrays.sort()를 사용해 알파벳 순으로 정렬하고 정렬한 문자를 String 생성자를 통해 문자열로 변환하여 HashMap의 key로 사용하였다. 이렇게 하면 애너그램을 쉽게 묶을 수 있다.
그 뒤엔 HashMap내에 해당 키가 존재하는지에 대해 검사를 진행하고 반환할 List에 담아서 반환하면 된다.
- 정수 배열과
target정수를 이용해 주어진 배열에서 두 숫자의 합이target정수와 동일하다면, 해당하는 숫자의 인덱스를 찾아 반환하는 메서드를 작성하자.
반환 타입은int[]이다.
먼저 나는 HashMap을 사용하지 않고 문제를 풀어보았다.
풀이는 아래와 같다.
public int[] twoSum(int[] arr, int sumNum) {
if(arr.length == 0) return new int[]{}; // 들어온 배열이 비어있으면
for(int i = 0; i < arr.length; i++) {
for(int j = arr.length - 1; j > i; j--) {
int temp = arr[i] + arr[j];
if(temp == sumNum) {
int[] result = {i, j};
return result;
}
}
}
return new int[]{}
}위 코드처럼 HashMap을 사용하지 않고 중첩 Loop문을 이용해 문제를 풀 수 있다. 하지만 중첩 Loop로 인해 시간 복잡도가 높아지는 단점이 존재한다.
아래 코드는 HashMap을 이용해 문제를 풀이한 코드이다.
public int[] twoSum(int[] arr, int sumNum) {
Map<Integer, Integer> hashMap = new HashMap<>();
// 배열을 끝까지 탐색하자
for(int i = 0; i < arr.length; i++) {
// 현재 배열 인덱스의 값을 담자
int num = arr[i];
// (목표값 - 현재 배열 인덱스의 값)을 하면 필요한 숫자가 무엇인지 알 수 있다.
int complement = target - num;
// 필요한 숫자가 HashMap에 key로 존재한다면
if(hashMap.containsKey(complement)) {
// 그 key의 값과 현재 배열의 인덱스를 반환하자
return new int[]{map.get(complement), i};
}
// 만약 없다면 Hashmap에 현재 배열의 숫자와 인덱스를 저장하자.
hashMap.put(num, i);
}
// 마지막으로 해당하는게 없다면 비어있는 배열을 반환
return new int[]{};
}HashMap을 사용하면 위와 같이 중첩 Loop를 사용하지 않고 문제를 풀 수 있다.
- 정수 배열과
target정수가 주어지면 해시테이블(HashMap)을 사용하여 합을 더한 연속된 부분의 배열 인덱스를 찾는 메서드를 작성하자.
ex) 예를 들어 {1,2,3,4,5} 배열이 있을때 target 정수가 9라면 결과는 {1,3}이다.
public int[] subarraySum(int[] nums, int target) {
Map<Integer, Integer> sumIndex = new HashMap<>();
// 누적합계가 0일때 인덱스를 -1로 설정해 첫번째 부터 기록
sumIndex.put(0, -1);
// 누적 합계
int currentSum = 0;
for(int i = 0; i < nums.length; i++) {
// 현재 배열의 값을 누적함
currentSum += nums[i];
// 해시맵에 (누적합계 - target = 시작값)이 있으면
if(sumIndex.containsKey(currentSum - target)) {
// 해시맵에서 해당하는 key의 다음 인덱스부터 현재 인덱스까지 반환
return new int[]{sumIndex.get(currentSum - target) + 1, i};
}
// 누적합계와 현재 배열의 인덱스를 저장하고 갱신.
sumIndex.put(currentSum, i);
}
// 해당되는게 없다면 비어있는 배열을 반환
return new int[]{};
}위 코드의 과정을 밑에서 자세하게 설명한다.
nums = {1,2,3,4,5}
target = 9
초기 상태
sumIndex = {0: -1}
currentSum = 0;
첫번째 반복(i = 0)
currentSum = currentSum + nums[0] => (0 + 1 = 1)
sumIndex에 1 - 9 = -8이 존재하지 않으므로 sumIndex갱신(sumIndex.put(currentSum, i);)
두번째 반복(i = 1)
currentSum = currentSum + nums[1] => (1 + 2 = 3)
sumIndex에 3 - 9 = -6이 존재하지 않으므로 sumIndex갱신
세번째 반복(i = 2)
currentSum = currentSum + nums[2] => (3 + 3 = 6)
sumIndex에 6 - 9 = -3이 존재하지 않으므로 sumIndex갱신
네번째 반복(i = 3)
currentSum = currentSum + nums[3] => (6 + 4 = 10)
sumIndex에 10 -9 = 1(첫번째 반복시 누적합)이 존재함.
조건에 따라 int[]{sumIndex.get(current - target) + 1, i}를 반환함.
(current - target는 찾고자 하는 부분 배열의 시작점 이전까지의 누적합임)😄 마무리
HashTable에 대하여 알아보고자 했지만 HashMap을 더 많이 사용하게 되었다.
HashTable에 대한 이론적인 부분은 숙지하였지만 좀 깊이있게 공부를 한 느낌은 들지 않는다.
또 연습문제를 풀다 보니 HashMap을 이용한 문제를 조금 더 연습할 필요가 있다고 느꼈다.
특히 부분합 부분에 대한 문제가 잘 이해가 되지 않아 코드를 작성하면서 왜 시작 인덱스가 그런식으로 구해지는지 이해가 잘 가지 않았기 때문이다. 해당 자료구조를 사용하는 문제를 집중적으로 더 풀이해봐야겠다.
