ASCII
1960년대 미국에서 정의한 표준화한 부호체계(American Standard Code for Information Interchange)
7비트 즉, 128개의 고유한 값만 사용
1비트를 통신 에러 검출을 위해 사용하기 때문
아스키코드를 이용해 다른 언어를 표현하기에는 7비트로는 부족
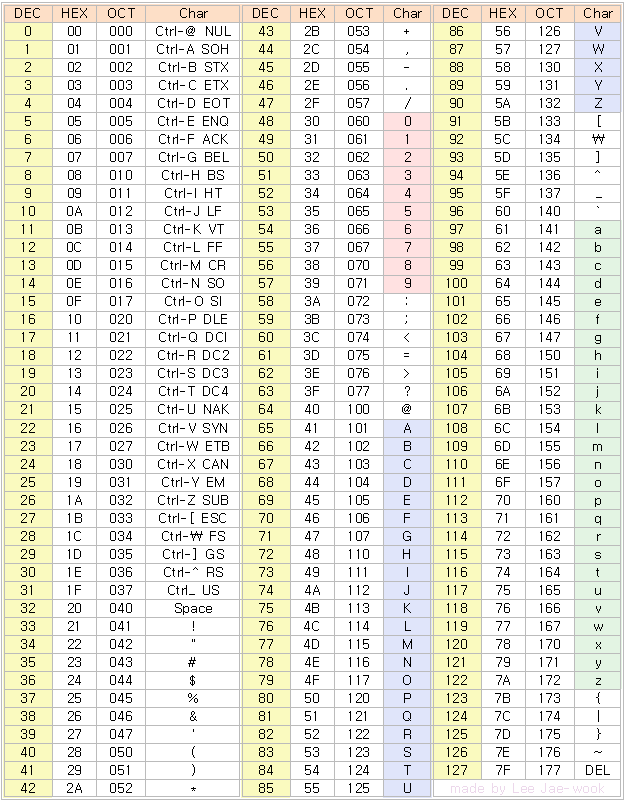
ANSI(American National Standards Institute)
8비트로 확장한 아스키 코드
비유럽 국가 특히 한국, 중국, 일본과 같은 문자가 많은 국가에서는 여전히 제한적
Unicode
용량을 크게 확장한 2byte (2의 16승 = 65536)의 유니코드가 등장
아스키 코드와 같이 집합체의 한 종류이며, 전 세계의 문자에 대해 각각의 번호를 지정하여 관리하고 있기 위해 만들어진 집합체
UTF-8
UTF-8은 유니코드를 인코딩(encoding)하는 방식이다. 전세계에서 사용하는 약속이다. (조합형 문자)
UTF-8은 1바이트에서 4바이트까지 가변바이트를 사용하기 때문에, 1바이트로 표현이 충분한 A같은 경우는 0x41로 표현
UTF-16
UTF-16은 16비트 즉, 2바이트로 표현하기 때문에, 0x0041로 표현
EUC-KR
EUC-KR은 한글 지원을 위해 유닉스 계열에서 나온 완성형 코드 조합이다.
완성형 코드란 완성 된 문자 하나하나마다 코드 번호를 부여한 것이다.
반대되는 개념으로 조합형 코드가 있는데, 이는 한글의 자음과 모음 각각에 코드 번호를 부여한 후 초성, 중성, 종성을 조합하여 하나의 문자를 나타내는 방식을 말한다.
EUC-KR은 ANSI를 한국에서 확장한 것으로 외국에서는 지원이 안 될 가능성이 높다.
EUC-KR - 웹에서 많이 사용
CP949 - 윈도우에서 많이 사용
EUC-KR은 2,350자의 한글, CP949는 11,172자의 한글을 표현할 수 있다.
CP949
CP949는 한글 지원을 위해 윈도우즈 계열에서 나온 확장 완성형 코드 조합이다.
EUC-KR은 2bytes의 완성형 코드로 2bytes 내에서는 표현할 수 있는 완성된 문자의 수는 한계가 있었다.
그래서 마이크로소프트에서 EUC-KR을 개선, 확장하여 만든 것이 CP949 이다. 여기서 949는 페이지 번호를 의미하며 한국을 의미한다. (참고로 일본어는 CP932, 중국어 간체는 CP936이다.)
기본적으로 EUC-KR과 호환이 되며, EUC-KR에서 표현이 되지 않는 문자는 조합을 하여 표현한다.
마이크로소프트가 만들었다고 하여 MS949라고 부르기도 한다.
.png)
i18n
국제화(Internationalization; i18n) : 첫글자 i 와 마지막 n 사이에 알파벳 18개가 있다는 뜻
SW 국제화란 : 국제적으로 통용되는 SW설계 개발 과정
SW 국제화에서 고려해야할 사항
- 유니코드
- 리소스 외부화 및 관리
- 로케일 대응
- Localizability
SW 현지화(localization)
- 현지화 번역
- 현지어 처리
- 문화적 사회적 객체처리
.png)
.png)
.png)
