목표
- 정수형, 실수형, 복소수형, 문자열, 리스트, 튜플, 사전에 대한 자료형 익히기
정수형
- 정수를 다루는 자료형
- 양의 정수, 음의 정수, 0 포함
< 정수형 예제 >
a = 230
# 양의 정수
a = a + 5
print(a)
# 음의 정수
a = a - 400
print(a)
< 결과 값 >
235
-165실수형
- 실수형 ( Real Number )는 소수점 아래의 데이터를 포함하는 수 자료형
- 파이썬에서는 변수에 소수점을 붙인 수를 대입하면 실수형 변수로 처리
- 소수부가 0이거나, 정수부가 0인 소수는 0을 생략하고 작성할 수 있음
< 실수형 예제 >
a = 572.59
b = 17.28
# 양의 실수
print(a + b)
# 음의 실수
b = - 677.02
print(a + b)
# 소수부가 0일 떄 0을 생략
a = 321.
print(a)
# 정수부가 0일 때 0을 생략
a = -.123
print(a)< 결과 값 >
589.87
-104.42999999999995
321.0
-0.123실수형 더 알아보기
- 오늘날 가장 널리 쓰이는 IEEE754 표준에서는 실수형을 저장하기 위해 4byte 혹은 8byte의 고정된 크기의 메모리를 할당하므로, 컴퓨터 시스템은 실수 정보를 표현하는 정확도에 한계를 가진다
- 예를 들어 10진수 체계에서는 0.3과 0.6을 더한 값이 0.9로 정확히 떨어진다
- 하지만 2진수에서는 0.9를 정확히 표현할 수 있는 방법이 없다
- 컴퓨터는 최대한 0.9와 가깝게 표현하지만, 미세한 오차가 발생 됨
< 예제 >
a = 0.3 + 0.6
print(a)
if a == 0.9:
print(True)
else:
print(False)< 결과 값 >
0.8999999999999999
False- 개발 과정에서 실수 값을 제대로 비교하지 못해서 원하는 결과를 얻지 못할 수 있다.
- 이럴 때는 round()함수를 이용할 수 있으며, 이러한 방법이 권장됨
< round 함수 예제 >
#123.456을 소수 셋째 자리에서 반올림하려면 round(123.456 , 2)
print( round(123.456 , 2))< 결과 값 >
123.46지수 표현 방식
- e나 E를 이용한 지수 표현 방식을 이용
- e나 E 다음에 오는 수는 10의 지수부를 의미
- ex) 1e9 입력 -> 10의 9제곱(1,000,000,000)
- 지수 표현 방식은 임의의 큰 수를 표현하기 위해 사용
- 최단 경로 알고리즘에서는 도달할 수 없는 노드에 대하여 최단 거리를 무한(INF)로 설정하곤 함
- 이때 가능한 최댓값이 10억 미만이라면 무한(INF)의 값으로 1e9를 이용할 수 있음
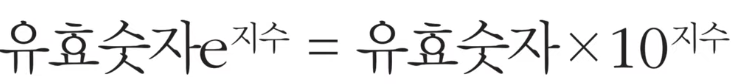
< 지수 표현 방식 예제 >
# 1,000,000,000의 지수 표현
a = 1e9
print(a)
# 752.5
a = 75.25e1
print(a)
# 3954e-3
a = 3954e-3
print(a)< 결과 값 >
1000000000.0
752.5
3.954수 자료형의 연산
- 수 자료형에 대하여 사칙연산과 나머지 연산이 많이 사용
- 단 나누기 연산자(/)를 주의해서 사용
- 파이썬에서 나누기 연산자(/)는 나눠진 결과를 실수형으로 반환
- 다양한 로직을 설계할 때 나머지 연산자(%) 를 이용해야 할 때가 많다.
- ex) a가 홀수인지 체크해야 하는 경우
- 파이썬에서는 몫을 얻기 위해 몫 연산자(//) 를 사용
- 이외에도 거듭 제곱 연산자(**) 를 비롯해 다양한 연산자들이 존재
< 수 자료형의 연산 >
a = 7
b = 3
# 나누기
print( a / b )
# 나머지
print( a % b )
# 몫
print( a // b )< 결과 값 >
2.3333333333333335
1
2리스트 자료형
- 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형
- C나 java에서의 배열 ( Array )의 기능 및 연결 리스트와 유사한 기능을 지원
- C++의 STL vector와 기능적으로 유사
- list대신에 배열 혹은 테이블이라고 부르기도 함

리스트 초기화
- 리스트는 대괄호([])안에 원소를 넣어 초기화하며, 쉼표(,)로 원소를 구분
- 비어 있는 리스트를 선언하고자 할 때는 list() 혹은 간단히 []를 이용할 수 있다
- 리스트의 원소에 접근할 때는 인덱스(Index) 값을 괄호에 넣는다.
- 인덱스는 0부터 시작
< 리스트 초기화 예제 >
# 직업 데이터를 넣어 초기화
a = [1,2,3,4,5]
print(a)
# 네 번째 원소만 출력
print(a[3])
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0] * n
print(a)< 결과 값 >
[1, 2, 3, 4, 5]
4
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]리스트의 인덱싱과 슬라이싱
인덱싱
- index 값을 입력하여 리스트의 특정한 원소에 접근하는 것을 인덱싱(indexing) 이라고 한다.
- python의 인덱스 값은 양의 정수와 음의 정수 모두 사용 가능
- 음의 정수를 넣으면 원소를 거꾸로 탐색
< 예제 >
a = [ 1, 2, 3, 4, 5, 6, 7, 8 ]
# 8번째 원소만 출력
print(a[7])
# 뒤에서 1번째 원소 출력
print( a[-3] )
# 4번째 원소 값 변경
a[3] = 7
print(a)< 결과 값 >
8
6
[1, 2, 3, 7, 5, 6, 7, 8]슬라이싱
- list에서 연속적인 위치를 갖는 원소들을 가져와야 할때 슬라이싱(Slicing)을 이용
- 대괄호 안에 콜론(:)을 넣어서 시작 index 와 끝 index를 설정할 수 있다.
- 끝 index 는 실제 인덱스보다 1을 더 크게 설정
< 예제 >
a = [ 1, 2, 3, 4, 5, 6, 7, 8 ]
# 두 번째 원소부터 네 번째 원소까지
print(a[1 : 4])< 결과 값 >
[2, 3, 4]리스트 컴프리헨션
- 리스트를 초기화하는 방법 중 하나
- 대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화 할 수 있다.
< 예제 >
# 0부터 9까지의 수를 포함하는 리스트
array= [ i for i in range(10) ]
print(array)
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [ i for i in range(20) if i % 2 == 1 ]
print(array)
# 0부터 19까지의 수 중에서 짝수만 포함하는 리스트
array = [ i for i in range(20) if i % 2 == 0 ]
print(array)
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [ i * i for i in range(1, 10) ]
print(array)< 결과 값 >
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
[1, 4, 9, 16, 25, 36, 49, 64, 81]리스트 컴프리헨션과 일반적인 코드의 차이점은?
코드1 - 리스트 컴프리헨션
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [ i for i in range(20) if i % 2 == 1 ]
print(array}코드2 - 일반적인 코드
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = []
for i in range(20):
if i % 2 == 1:
array.append(i)
print(array)
< 결과 값 >
[1, 1, 2, 3, 4, 5, 6, 7, 8, 9]리스트 컴프리헨션으로 2차원 리스트를 초기화할 때 효과적으로 사용하는 방법
- N x M 크기의 2차원 리스트를 한 번에 초기화 해야 할때 유용
- 좋은 예시
- array = [ [0] * m for _in range(n) ]
- 좋은 예시
- 만약 2차원 리스트를 초기화할 때 다음과 같이 작성하면 예기치 않은 결과가 나올 수 있음
- 잘못된 예시
- array = [ [0] m ] n
- 이코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식 함
- array = [ [0] m ] n
- 잘못된 예시
< 리스트 컴프리헨션 - 좋은예시 >
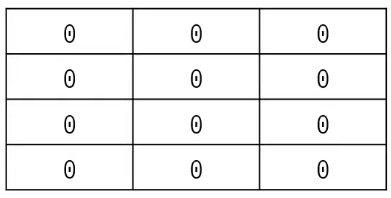
# N x M 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [ [0] * m for _ in range(n) ]
print(array)
array[1][1] = 5
print(array) < 결과 값 >
[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
[[0, 0, 0], [0, 5, 0], [0, 0, 0], [0, 0, 0]]< 리스트 컴프리헨션 - 잘못된 예시 >
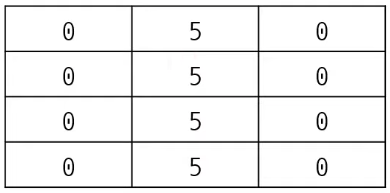
# N x M 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [ [0] * m ] * n
print(array)
array[1][1] = 5
print(array)< 결과 값 >
[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
[[0, 5, 0], [0, 5, 0], [0, 5, 0], [0, 5, 0]]( _ ) 언더바는 언제 사용?
- 파이썬에서는 반복을 수행하되 반복을 위한 변수의 값을 무시하고자 할때 언더버(_)를 사용
< 1부터 9까지의 자연수 더하기 및 Hello World를 5번 출력 예제 >
# 1부터 9까지의 자연수를 더하기
summary = 0
for i in range( 1, 10 ) :
summary += i
print(summary)
# "Hello World" 5번 출력하기
for _ in range(5):
print("Hello World")< 결과 값 >
45
Hello World
Hello World
Hello World
Hello World
Hello World
리스트 관련 기타 Method

< 리스트 관련 기타 Method 예제 1 >
# 대상 1 =======================
a = [1,4,3]
print( "기본 리스트 : " , a )
# 리스트에 원소 삽입
a.append(2)
print("리스트에 원소 삽입 : " , a)
# 오른차순 정렬
a.sort()
print( "오름차순 정렬 : ", a )
# 내림차순 정렬
a.sort( reverse = True )
print( "내림차순 정렬 : " , a )< 결과 값 >
기본 리스트 : [1, 4, 3]
리스트에 원소 삽입 : [1, 4, 3, 2]
오름차순 정렬 : [1, 2, 3, 4]
내림차순 정렬 : [4, 3, 2, 1]< 리스트 관련 기타 Method 예제 2 >
a = [4, 3, 2, 1]
# 리스트 원소 뒤집기
a.reverse()D
print( "원소 뒤집기 : " , a )
# 특정 인덱스에 데이터 추가
a.insert( 2 , 3 )
print ("인덱스 2에 3추가 : " , a )
# 특정 값인 데이터 개수 세기
print( "값이 3인 데이터 개수 : " , a.count(3) )
# 특정 값 데이터 삭제
a.remove(1)
print( "값이 1인 데이터 삭제 : " , a )< 대상 2 결과 값 >
원소 뒤집기 : [1, 2, 3, 4]
인덱스 2에 3추가 : [1, 2, 3, 3, 4]
값이 3인 데이터 개수 : 2
값이 1인 데이터 삭제 : [2, 3, 3, 4]리스트에서 특정 값을 가지는 원소를 모두 제거
< 예제 >
a = [ 1, 2, 3, 4, 5, 5, 5 ]
remove_set = { 3, 5 } # 집합 자료형
# remove_list에 포함되지 않은 값만을 저장
result = [ i for i in a if i not in remove_set ]
print(result)< 결과 값 >
[1, 2, 4]문자열 자료형
< 예제 >
data = 'Hello World'
print(data)
# 백슬래시(\)를 사용하면, 큰 따옴표나 작은 따옴표를 원하는 만큼 포함 할 수 있음
data = "Don't you know \"Python\"?"
print(data)< 결과 값 >
Hello World
Don't you know "Python"?문자열 연산
- 문자열 변수에 덧셈(+)을 이용하면 문자열이 더해져서 연결이 된다.
- 문자열 변수를 특정한 양의 정수와 곱하는 경우, 문자열이 그 값만큼 여러 번 더해진다.
- 문자열에 대해서도 인덱싱과 슬라이싱을 이용할 수 있다.
- 다만 문자열은 특정 인덱슫의 값을 변경할 수 없다 ( Immutable )
< 예제 >
a = "Hello"
b = "World"
print( a + " " + b )
a = "String"
print( a * 3)
a = "ABCDEF"
print( a[2 : 4])< 결과 값 >
Hello World
StringStringString
CD튜플 자료형
- 리스트와 유사
- 한 번 선언된 값을 변경할 수 없다
- 리스트는 대괄호 '[]'를 이용하지만 튜플은 소괄호'()'를 이용
- 리스트에 비해 상대적으로 공간 효율적
< 예제 >
a = ( 1 , 2, 3, 4, 5, 6, 7, 8 ,9 )
# 네 번째 원소만 출력
print(a[3])
# 두 번째 원소부터 네 번째 원소까지
print(a[1 : 4])< 결과 값 >
4
(2, 3, 4)튜플을 사용하면 좋은 경우
- 서로 다른 성질의 데이터를 묶어서 관리해야 할 때
- 최단 경로 알고리즘에서는 (비용, 노드번호)의 형태로 튜플 자료형을 자주 사용
- 데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때
- 튜플은 변경이 불가능하므로 리스트와 다르게 키 값으로 사용
- 리스트보다 메모리를 효율적으로 사용
사전 자료형
- 키(Key) 와 값(Value)를 쌍으로 데이터를 가지는 자료형
- 리스트나 튜플의 값을 순차적으로 저장하는 것과는 대비
- 변경 불가능한(Immutable) 자료형을 키(Key)로 사용할 수 있다.
- 파이썬의 사전 자료형은 해시 테이블(Hash Table)을 이용하므로 데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리가 가능하다.
< 예제 >
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
print(data)
if '사과' in data :
print(" '사과' 를 키로 가지는 데이터가 존재")< 결과 값 >
{'사과': 'Apple', '바나나': 'Banana', '코코넛': 'Coconut'}
'사과' 를 키로 가지는 데이터가 존재사전 자료형 관련 메서드
- 키 데이터만 뽑아서 리스트를 이용할때 keys() 함수 사용
- 값 데이터만 뽑아서 리스트로 이용할때 values() 함수 사용
< 예제 >
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
# 키 데이터만 담은 리스트
key_list = data.keys()
# 값 데이터만 담는 리스트
value_list = data.values()
print(key_list)
print(value_list)
# 각 키에 따른 값을 하나씩 출력
for key in key_list :
print(data[key])
# 다르게 데이터를 담는 방법
b = {
'홍길동' : 97,
'이순신' : 98
}
print(b)
print(b['이순신'])
key_list = list( b.keys() )
value_list = list( b.values() )
print(key_list)
print(value_list)< 결과 값 >
dict_keys(['사과', '바나나', '코코넛'])
dict_values(['Apple', 'Banana', 'Coconut'])
Apple
Banana
Coconut
{'홍길동': 97, '이순신': 98}
98
['홍길동', '이순신']
[97, 98]
집합 자료형
- 특징
- 중복을 허용하지 않음
- 순서가 없다
- 리스트 혹은 문자열을 이용해서 초기화 할 수 있다.
- 이때 set()함수를 사용
- 혹은 중괄호 ({})안에 각 원소를 콤마(,)를 기준으로 구분하여 초기화 가능
- 데이터 조회 및 수정에 있어서 O(1)의 시간에 처리 가능
< 예제 >
# 집합 자료형 초기화 방법1
data = set( [1, 1, 2, 3, 4, 4, 5] )
print(data)
# 집합 자료형 초기화 방법2
data = {1, 1, 2, 3, 4, 4, 5}
print(data)< 결과 값 >
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5}집합 자료형의 연산
- 합집합
- 집합 A에 속하거나 B에 속하는 원소들로 이루어진 집합
- 교집합
- 집합 A에도 속하고 B에도 속하는 원소로 이루어진 집합
- 차집합
- 집합 A으 원소 중에서 B에 속하지 않는 원소들로 이루어진 집합
< 예제 >
a = set( [1,2,3,4,5] )
b = set( [3,4,5,6,7] )
# 합집합
print( a | b )
# 교집합
print( a & b )
# 차집합
print( a - b )< 결과 값 >
{1, 2, 3, 4, 5, 6, 7}
{3, 4, 5}
{1, 2}집합 자로형 관련 함수
< 예제 >
data = set([1,2,3])
print(data)
# 새로운 원소 추가
data.add(4)
print(data)
# 새로운 원소 여러 개 추가
data.update([5,6])
print(data)
# 특정한 값을 갖는 원소 삭제
data.remove(3)
print(data)< 결과 값 >
{1, 2, 3}
{1, 2, 3, 4}
{1, 2, 3, 4, 5, 6}
{1, 2, 4, 5, 6}사전 자료형과 집합 자료형의 특징
- 리스트나 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있음
- 사전 자료형과 집합 자료형은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다
- 사전의 키(Key) 혹은 집합의 원소(Element)를 이용해 O(1) 의 시간 복잡도로 조회
< Reference Site >
DEV