1. 학습내용
- Orange Data Mining
- Deep Learning 이론
- Anaconda Jupyter NoteBook 사용
2. 상세내용
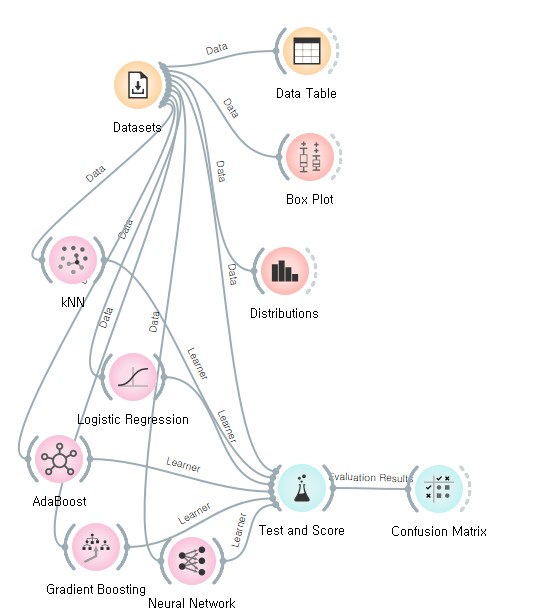
- 특정 데이터를 가져와서(Datasets), 데이터를 검토(Data Table)
- 'Box Plot' 데이터 유사성에 대한 박스권을 나타냄
- 그리고 각종 알고리즘을 테스트하여 정확도를 측정하여 최적의 알고리즘을 찾아낸다

- AUC : 정확도를 나타내는건데, ROC그래프에서 차지하는 범위의 넓이로 생각하면 된다.
- CA : AUC보다 확실한 의미의 정확도

- 특정 데이터를 가져와서(Datasets), 데이터를 검토(Data Table)
- 샘플을 Train과 Test로 나눔(Data Sampler)
- 그리고 Train과 Test의 정확도를 책정하고 Confusion Matrix로 나타낸다.

- 이미지를 가져와서(Import Images), 이미지를 검토(Image Viewer)
- Image Embedding으로 이미지에 대한 분석자료를 만듦
- Distance로 데이터를 Cluster(군집)시켜서 여러가지 형태로 나타낸다.

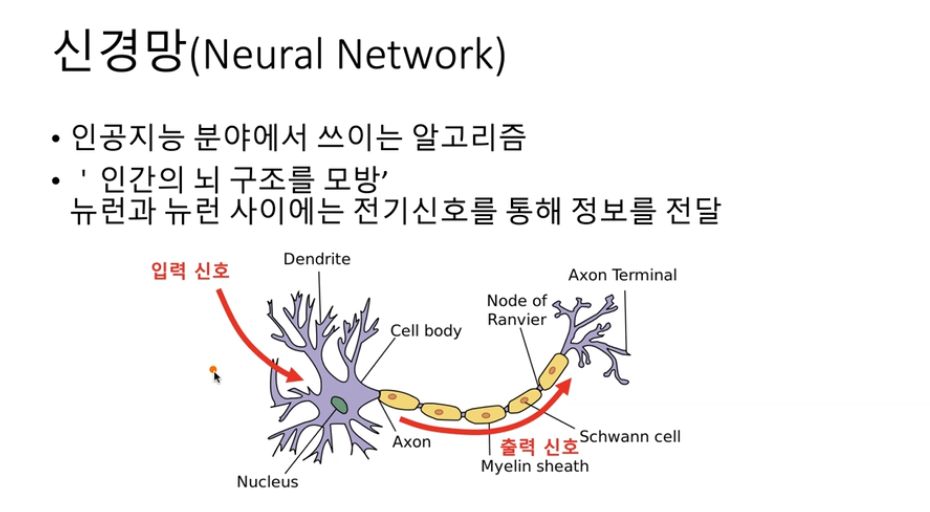
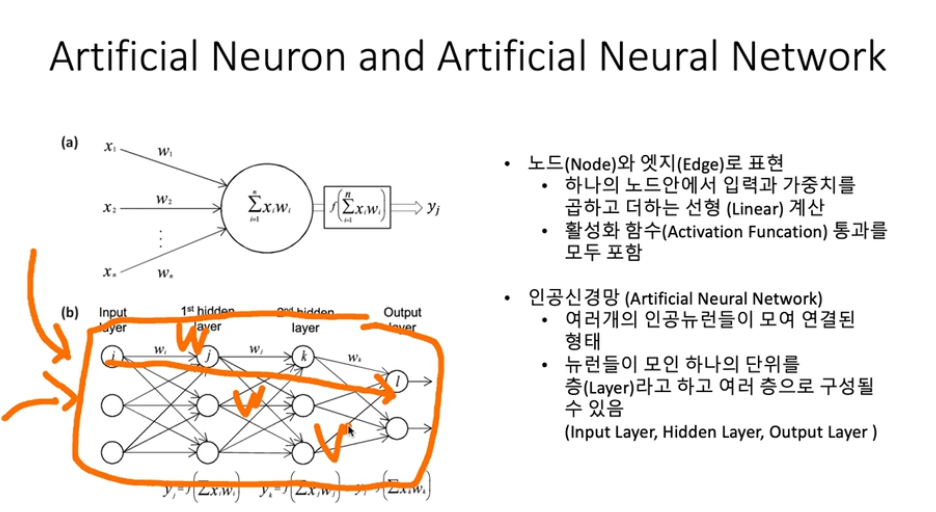
딥러닝 들어가기 전에 기본적으로 알고갈 내용!
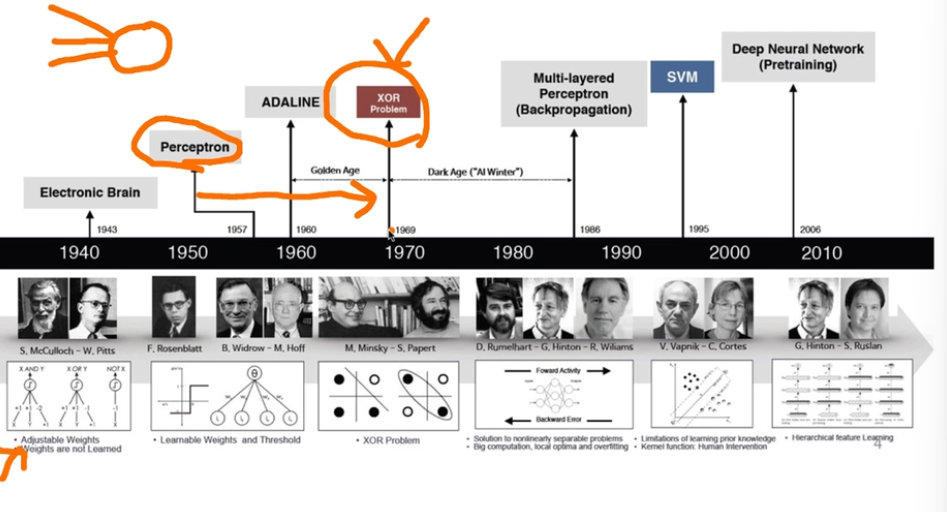
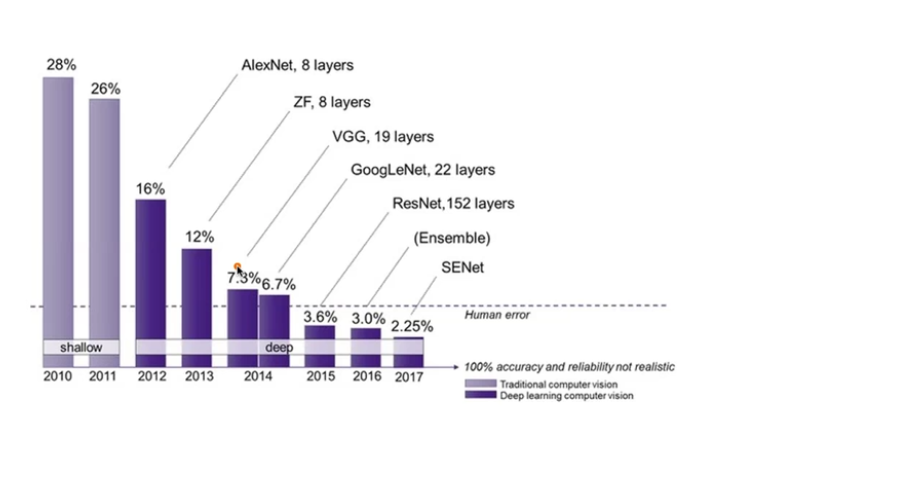
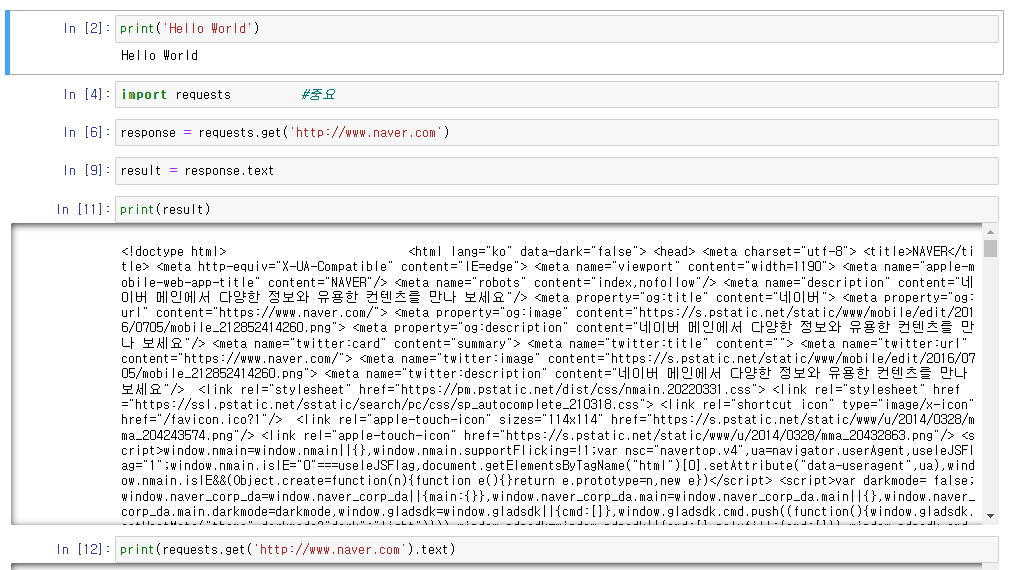

마우스 우클릭 해제 : 기타 도구에서 JS해제하고 새로고침하면 가능!
3. 금일소감
<ol>
<li>내가 이 수업을 먼저 들었어야했다...2222222</li>
<li>Jupyter의 시작!</li>
<li>복습인데 예습같은 기분</li>
<li>가고 싶은 방향은 프론트엔드지만, 백엔드 코드구현 자동화를 위해서 머신러닝은 꾸준하게 공부해야겠다.</li>
</ol>
필요하다면 공부하는 개발자, 한승준