1. 기본환경 : Google Colab or Jupyter
1. 학습내용
- Processing

2. 주요코드
# 먼저 필요한 패키지를 가져옵니다.
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt입력하세요!pip install imblearn #설치 필수
abalone_columns = list()
for l in open('abalone_attributes.txt'):
abalone_columns.append(l.strip())
data = pd.read_csv('abalone.txt', header = None, names = abalone_columns )
label = data['Sex']data = (data - np.min(data)) / (np.max(data) - np.min(data)) #Min-Max 스켈링from sklearn.preprocessing import MinMaxScaler
mMscaler = MinMaxScaler()
mMscaled_data = mMscaler.fit_transform(data)
from sklearn.preprocessing import StandardScaler
sdscaler = StandardScaler()
sdscaled_data = sdscaler.fit_transform(data)from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
ros = RandomOverSampler()
rus = RandomUnderSampler()
<!-- OVER -->
oversampled_data, oversampled_label = ros.fit_resample(data, label)
oversampled_data = pd.DataFrame(oversampled_data, columns=data.columns)
<!-- UNDER -->
undersampled_data, undersampled_label = rus.fit_resample(data, label)from sklearn.datasets import make_classification
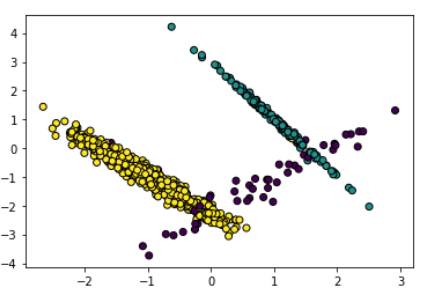
data, label = make_classification(
n_samples = 1000,
n_classes=3,
n_features=2,
n_repeated=0,
n_informative=2,
n_redundant=0,
n_clusters_per_class=1,
weights=[0.05, 0.15, 0.8],
class_sep=1,
random_state=2022
<!-- 그림으로 나타내는 코드 -->
plt.scatter(data[:,0],data[:,1], c=label, linewidth=1, edgecolor='black')
)
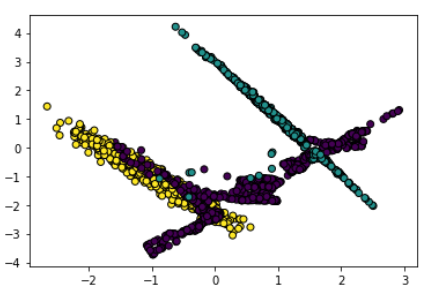
from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=5)
smoted_data, smoted_label = smote.fit_resample(data, label)
print('원본 데이터의 클래스 비율 \n{}'.format(pd.get_dummies(label).sum()))
print('\nSMOTE 결과 \n{}'.format(pd.get_dummies(smoted_label).sum()))
<!-- 그림으로 나타내는 코드 -->
plt.scatter(smoted_data[:,0], smoted_data[:,1],
c=smoted_label, linewidth=1, edgecolor='black'
)
from sklearn.datasets import load_digits
digits = load_digits()
data = digits.data
label = digits.target
<!-- 그림으로 나타내는 코드 -->
plt.imshow(data[0].reshape(8,8))
print('Label : {}'.format(label[0]))
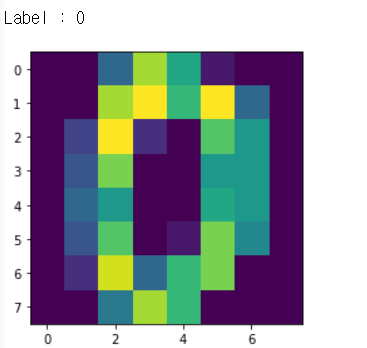
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
new_data = pca.fit_transform(data)
<!-- 그림으로 나타내는 코드 -->
plt.scatter(new_data[:,0], new_data[:,1], c=label, linewidth=1, edgecolor ='black')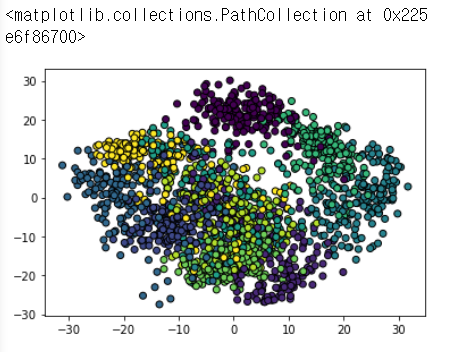
data = pd.read_csv('abalone.txt', header=None, names = abalone_columns)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 가로로 정리
label_encoded_label = le.fit_transform(label)
# 세로로 정리
label_encoded_label.reshape(-1,1)
#판다스 형태로 변환(보기좋음)
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)),label_encoded_label.reshape((-1, 1))], axis=1),columns=['label', 'label_encoded'])
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False) #True(디폴트)는 매트릭스, False는 배열로 나옴
one_hot_encoded = ohe.fit_transform(label.values.reshape((-1,1)))
print(one_hot_encoded) #확인용(안해도됨)
from sklearn.datasets import load_wine
wine = load_wine()
print(wine.DESCR) #확인용(안해도됨)
data = wine.data
label = wine.target
columns = wine.feature_names
data = pd.DataFrame(data, columns = columns)
data.head() #확인용(안해도됨)#3개 군집정도 생각하고 kmeans 알고리즘 적용
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
#데이터 적용
kmeans.fit(data)
#군집에 데이터 알고리즘 적용시킨값 넣기
cluster = kmeans.predict(data)
#그림으로 표현
plt.scatter(data[:,0],data[:,1], c=cluster,
lineWidth=1, edgecolor='black')
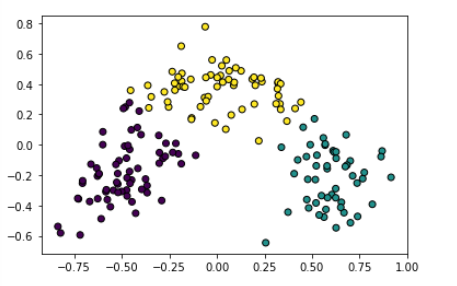
3. 실습
- 데이터 정리
- MinMax 스켈링
- PCA 축소
a. 데이터 정리
from sklearn.datasets import load_wine
wine = load_wine()
print(wine.DESCR) #확인
data = wine.data
label = wine.target
columns = wine.feature_names
data = pd.DataFrame(data, columns = columns)
data.head() #확인
data.shape #확인
b. MinMax 스켈링
#MinMax
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
data #확인
c. PCA 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
data = pca.fit_transform(data)4. 금일소감
<ol>
<li>추가 모집 이후 첫 수업</li>
<li>인공지능 겁나 어려움</li>
<li>프론트엔드 공부는 따로 해야할 듯</li>
</ol>
필요하다면 공부하는 개발자, 한승준