최초의 흐름 구조
- api요청(/api/education/articles) -> 크롤링 수행 -> 값 반환
문제점
시간이 매우 오래 걸리는 문제점 발생 -> 사용성이 떨어짐
그래서, 빠른 응답 속도를 위해 캐싱을 적용하기로 했다.
1차 개선 흐름 구조
- api요청(/api/education/articles) -> 캐시 조회(10분) -> 캐시 없을 시 크롤링 수행 -> 값 반환
문제점
캐싱을 10분 뒤 만료되게 TTL을 설정해놓아서
캐싱 데이터가 날아갔을 시 다시 크롤링을 해야 하는 게 매우 번거롭고 사용성이 떨어졌음.
캐시 데이터에 영속성을 부여해주기 위해 확장성이 좋은 RDS를 덧대어 추가했다.
2차 개선 흐름 구조
- api요청(/api/education/articles) -> 캐시 조회(10분) -> 캐시 없을 시 RDS 조회 -> RDS없을 시 크롤링 수행 -> 값 반환
문제점
DB를 끼고 나니, '캐싱이 굳이 필요한가?' 라는 생각이 들었다.
보통 DB없이 메모리를 이용한 게 캐싱의 장점인데
이렇게 가버리면 그냥 DB에서 가져오는 거랑 다를 바가 없다고 느꼈음.
그래서 DB에서 그냥 가져오는 것과 캐싱으로 가져오는 것의 차이를 제대로 알아야겠다 싶었다.
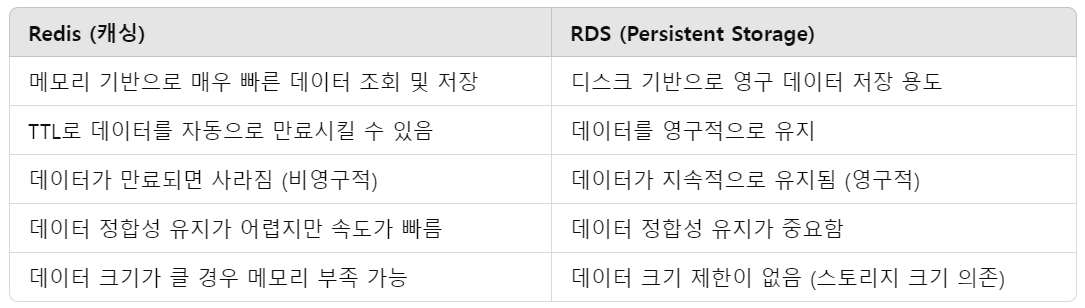
캐싱과 DB직접 조회의 차이
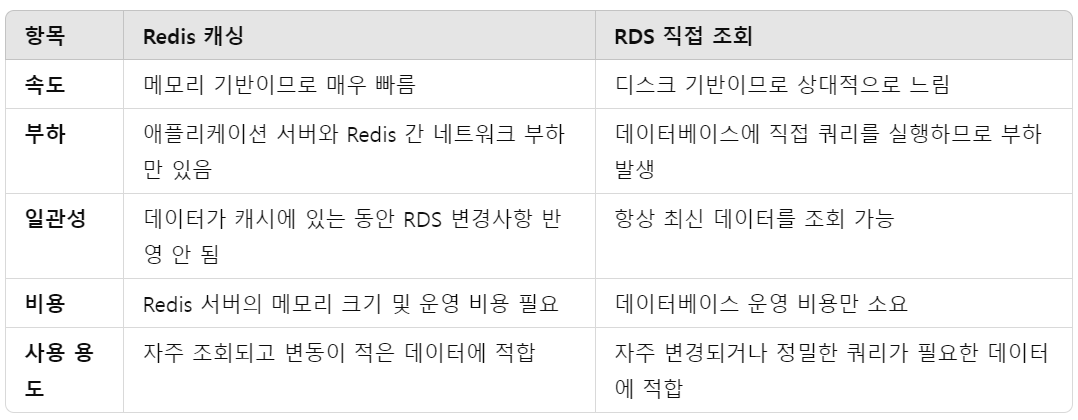
가장 큰 차이점은 메모리 기반이냐 vs 디스크 기반이냐의 차이인 것 같다.
운영체제를 공부할 때 공부한 부분인데 실제 개발에 이렇게 적용되는 구나 싶었음
매번 쿼리를 날려 가져오는 게 DB에 부하를 주기 때문에 쿼리를 최적화하기 위해서도 캐싱이 필요했다.
차이를 확실히 알고 나서 두 가지를 가장 효율적으로 쓰는 법은 뭐가 있을까? 생각 끝에 구조를 조금 바꾸기로 했다.
최종 변경한 흐름 구조
- api요청(/api/education/articles) -> 캐시 조회(10분) -> 캐시 없을 시 RDS 조회 -> 반환
=> 크롤링 로직을 아예 뺐다. 생각해보니 호출 로직 사이에 크롤링 작업을 껴놓을 필요가 없었다.
크롤링을 수행하는 목적은 '정합성' 때문인데, 이건 별도로 스케줄러를 돌려서 주기적으로 업데이트 시키고 RDS에서 가져오는 로직만 추가하면 됨
=> DB 업데이트는 별도로, 그걸 가져오는 캐싱 작업도 별도로!
=> 이렇게 하면 최적화 된 설계가 가능하다고 느껴졌다.

(구) https://hansjour.tistory.com/ 이사옴. 성장하는 하루를 쌓아가는 블로그