AI - Deep Learning 2일차
학습 내용
기본적인 신경망 만들기
from keras import models
from keras import layers
network = models.Sequential() #하나의 신경망을 시작하기 위한 준비
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,))) #덴스레이어를 만든다
#512개의 신경을 생성
network.add(layers.Dense(10, activation='softmax', input_shape=(28 * 28,)))#10개의 신경을 생성
#네트워크를 완성#네트워크를 마무리
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#optimizer : 가중치를 조절해주는 역할
#loss : 손실값을 계산하는 역할
#분류할 때는 손실함수 중 categorical_crossentropy를 가장 많이 사용
#둘 중 하나를 판볗할 때는 binary_crossentropy를 많이 사용한다train_images = train_images.reshape(60000, 28*28) #모양을 바꾼다
#(60000, 28, 28)을 (60000, 784)로 바꾼다 28x28=784 일자로 펴서 컴퓨터가 계산하기 좋게 변경
#쓰기 좋게 실수형으로 변경
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape(10000, 28*28) #테스트 데이터는 1만개이다
test_images = test_images.astype('float32') / 255#카테고리컬 데이터로 만들기 위한 준비
from tensorflow.keras.utils import to_categorical
#카테고리컬 데이터로 바꿔준다
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)#네트워크 이용
#사이킷런이랑 명령어는 같다, 학습시킬 때 fit을 쓴다
network.fit(train_images, train_labels, epochs=5, batch_size=128) #epochs 반복횟수, batch_size 한 번 돌릴 때 데이터 사이즈
결과)
Epoch 1/5
469/469 [==============================] - 9s 9ms/step - loss: 0.2596 - accuracy: 0.9246
Epoch 2/5
469/469 [==============================] - 4s 8ms/step - loss: 0.1040 - accuracy: 0.9691
Epoch 3/5
469/469 [==============================] - 4s 8ms/step - loss: 0.0674 - accuracy: 0.9797
Epoch 4/5
469/469 [==============================] - 4s 8ms/step - loss: 0.0497 - accuracy: 0.9847
Epoch 5/5
469/469 [==============================] - 4s 8ms/step - loss: 0.0367 - accuracy: 0.9890반복할수록 loss(손실)이 점점 줄어들고 있고 accuracy(정확도)가 점점 올라간다.
여기에서 정확도는 훈련정확도로 높다고 무조건 좋은 것은 아니다. => 과적합 문제가 생길 수 있음
- 평가
실제로 테스트 데이터를 넣고 테스트해본다.
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:',test_acc)
결과)
test_acc: 0.979200005531311
#테스트 정확도도 높게 나왔다.영화 리뷰 분류 : 이진분류 예제
IMDB 데이터셋을 사용해서 실제 데이터를 분류해본다.
인터넷 영화 데이터베이스로부터 가져온 양근단의 리뷰가 50000개이며 x데이터는 리뷰의 단어들이고 y 데이터는 단어가 긍정적인지 부정적인지 라벨링이되어 있다.
from keras.datasets import imdb #영화 리뷰 데이터 가져옴
(train_data, train_label),(test_data, test_label) = imdb.load_data(num_words=10000)
#다 가져오면 데이터가 많아서 안에 있는 데이터 중 중요한 데이터 일부만 가져오겠다는 뜻
#그냥 load_data()하면 전체 데이터를 가지고 온다#학습용 데이터 개수 확인
len(train_data)
결과)
25000#테스트용 데이터 개수 확인
len(test_data)
결과)
25000#학습용 데이터의 첫번째 데이터 확인
train_data[0]
#전처리되어 있어 단어들이 모두 숫자로 변환되어 있음
결과)
[1,
14,
22,
16,
43,
530,
973,
... 중략 ...
178,
32]#positive인지 negative인지 라벨링을 확인
train_label[0]
결과)
1# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리
word_index = imdb.get_word_index()
# 정수 인덱스와 단어를 매핑하도록 뒤집는다
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 리뷰를 디코딩
# 0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺀다
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])import numpy as np
def vectorize_sequences(sequences, dimension=10000): #vecorize_sequences(시퀀스,차원을 받아들이는 함수)
results = np.zeros((len(sequences),dimension))
#0으로 초기화됨 10000개짜리 배열 생성, 튜플타입으로 생성해야 됨
#단어의 길이의 수만큼 생성
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#정수형 데이터를 실수형을 바꿔준다.
y_train = np.array(train_label).astype('float32')
y_test = np.array(test_label).astype('float32')# 신경망 만들기
from keras import models
from keras import layers
model = models.Sequential() #신경 생성
model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) #input_shape는 첫번째 데이터에만 주면 됨
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))from keras import losses
from keras import metrics
from tensorflow.keras import optimizers
# model.compile(optimizer='rmsprop',
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics='accuracy')
#신경망 준비 완료x_val = x_train[:10000] #2만5천개 중에 서 앞에서 부터 만개까지 가져옴
partial_x_train = x_train[10000:]
y_val = y_train[:10000] #2만5천개 중에 서 앞에서 부터 만개까지 가져옴
partial_y_train = y_train[10000:]- 실제로 학습시켜서 제대로 동작하는지 검증하기
history = model.fit(partial_x_train,
partial_y_train,
epochs=3,
batch_size=512,
validation_data=(x_val, y_val))
#epochs 학습을 얼마나 할지 지정
#batch_size 데이터의 단위
#validation_data 검증 작업
결과)
Epoch 1/3
30/30 [==============================] - 2s 34ms/step - loss: 0.4950 - accuracy: 0.7893 - val_loss: 0.3804 - val_accuracy: 0.8606
Epoch 2/3
30/30 [==============================] - 1s 19ms/step - loss: 0.2954 - accuracy: 0.9037 - val_loss: 0.3026 - val_accuracy: 0.8854
Epoch 3/3
30/30 [==============================] - 1s 18ms/step - loss: 0.2155 - accuracy: 0.9303 - val_loss: 0.3274 - val_accuracy: 0.8616history_dict = history.history
history_dict.keys()
결과)
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])# 그래프로 그려서 확인
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy'] #validation 정확도 가져오기
loss = history.history['loss'] #loss값 저장
val_loss = history.history['val_loss'] #validation loss값 가져오기
epochs = range(1,len(acc) + 1)#손실 그래프 그리기
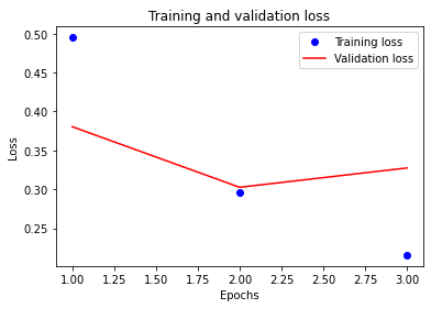
plt.plot(epochs, loss, 'bo', label='Training loss') #x에는 반복횟수, y에는 로스값, 파란 동그라미로 표시
plt.plot(epochs, val_loss, 'r-', label='Validation loss')#x에는 반복횟수, y에는 밸리데이션로스값, 빨간선으로 표시
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()- 그래프 설명
x는 반복 횟수, y는 로스 횟수이다.
반복할수록 로스값이 얼마나 줄어드는지 확인했다.
학습하면 할수록 로스값이 떨어졌다.
하지만 학습율이 올라가면 올라갈수록 검증손실 값은 올라가는 걸 알 수 있다.
=> 검증손실 값이 내려가다가 올라가는 포인트가 과대적합 포인트이다
#정확도 그래프 그리기
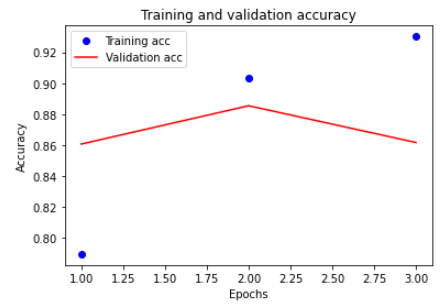
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'r-', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()- 그래프 설명
마찬가지로 반복횟수가 증가할수록 학습정확도는 올라가지만 검증정확도는 두번째 반복에서 가장 정확도가 좋다.
- 모델 평가
results = model.evaluate(x_test, y_test)
결과)
782/782 [==============================] - 2s 3ms/step - loss: 0.3404 - accuracy: 0.8582
#정확도 0.8582#예측
model.predict(x_test)
결과)
array([[0.3295951 ],
[0.99504805],
[0.99003863],
...,
[0.27628434],
[0.35289758],
[0.81273484]], dtype=float32)학습 후기
오늘은 신경망 모델을 만들어보았다. 만드는 방법은 다르지만 과적합을 막으면서 가장 높은 정확도를 가지는 모델을 찾는다는 목적은 같다.
반복되는 개념은 이제 알겠는데 아직 이해가 안 가는 부분이 많다. 매일 추가로 자료를 찾아보며 공부중인데 부족한게 많아서 하루가 모자랄 정도로 시간이 부족하다. 하지만 문제가 생기고 찾는 과정도 다 도움이 될 거라고 생각한다. 화이팅!

열심히 하는 중