🤔 병합 정렬 / 합병 정렬이란?
합병의 사전적 의미를 살펴보니, 아래와 같다.
둘 이상의 기구나 단체, 나라 따위가 하나로 합쳐짐. 또는 그렇게 만듦.
그럼 합병 정렬은 두 개 이상의 리스트 혹은 배열을 정렬된 하나의 리스트 혹은 배열로 만든다는 얘기이다.
병합 정렬(Merge Sort)은 분할 정복(Divide and Conquer) 알고리즘을 기반으로 하는 정렬이다.
분할 정복(Divide and Conquer)란?
방대한 문제를 조금씩 나누어 용이하게 풀 수 있는 문제 단위로 쪼갠 다음 그것을 다시 합쳐서 해결하는 방식
병합 정렬의 원리를 간단히 설명하면, 정렬되어 있지 않은 배열을 동일한 크기의 배열로 분리한 다음, 분리된 배열을 정렬한 후 다시 병합하는 과정으로 정렬이 이루어집니다.
조금 더 쉽게 이해하기 위해 그림으로 표현하면 다음과 같다,
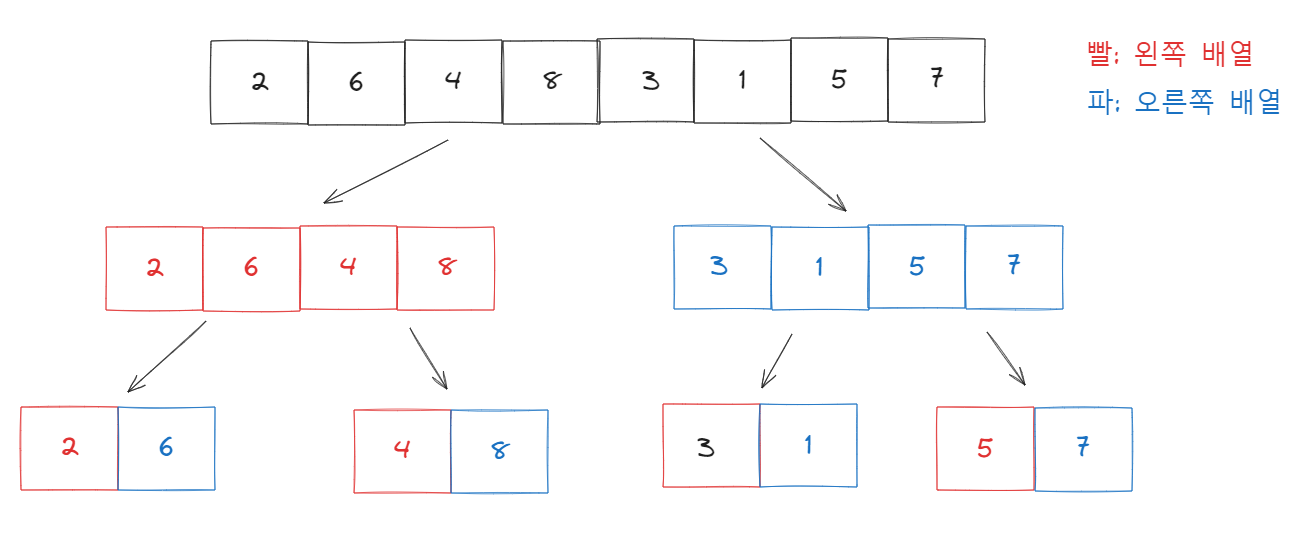
더 이상 나눌 수 없는 길이까지 나누어 하위 배열을 나타낸 그림이다. 이제 이를 정렬한 다음 병합해보겠다.
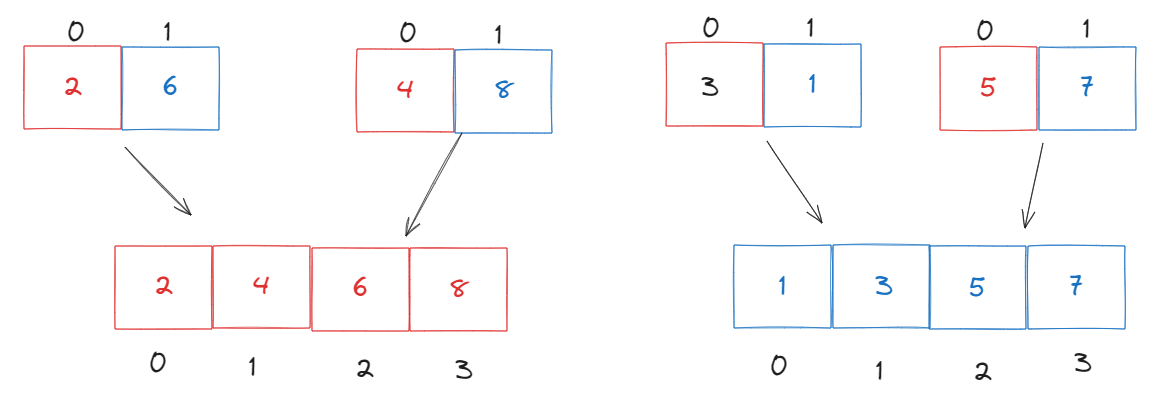
하위의 배열간 비교를 하여, 이를 병합한 모습이다. 이제 남은 두 배열이 정렬되는 모습을 살펴보자
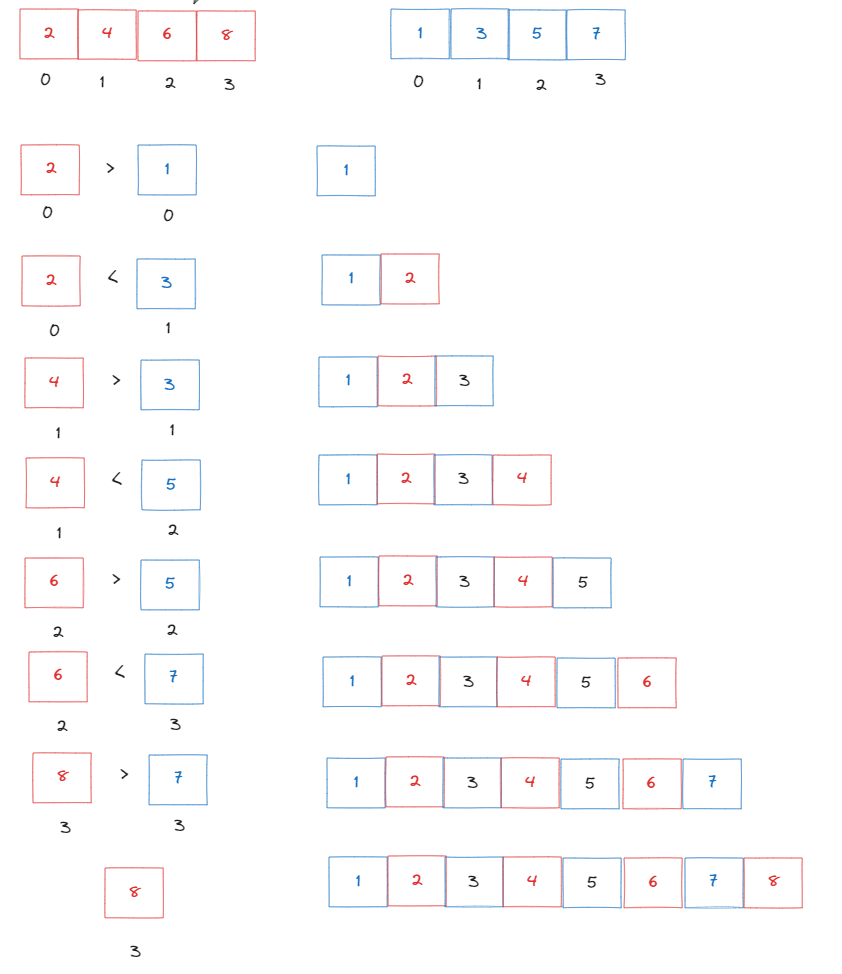
다음과 같이 왼쪽배열과 오른쪽 배열을 비교해가며 오름차순을 해 나가는 모습을 볼 수 있다.
현재 그림은 2개의 배열로 나누었지만, 위에서 살펴봤던 병합의 의미처럼 (둘 이상의...)
꼭 2개의 배열로 나누어야 하는 것은 아니라고 한다.
일반적으로는 그림처럼 2개의 배열로 나누어 구현하는 방식을 이용한다고 하며
이러한 방식을 two-way 방식이라고 한다.😎 병합정렬의 특징
- 안정정렬(stable Sort) 알고리즘:
동일한 값을 가진 요소의 순서가 기존의 순서와 같이 유지된다.
이 말은 요소가 정렬된 상태에서는 어떠한 작업을 수행해도 위치가 바뀌지 않는다.
ex) [9(1), 5, 7, 9(2)] 해당 배열을 정렬했을 때! [5, 7, 9(1), 9(2)]일 경우
안정정렬이라고 부른다.
- 비제자리 정렬(Out-of-place Sort):
정렬의 대상이 되는 요소외에 추가적인 공간(메모리)을 필요로 한다.
이는 병합 과정에서 두 하위 배열을 새로운 배열에 합칠 때 발생한다.
- 시간 복잡도:
best, avg, worst 모두 O(N log N)의 시간 복잡도를 가진다.
👀 병합 정렬의 장, 단점
장점
- 안정정렬 알고리즘이다.
이것이 장점인 이유는, 우리가 배열을 정렬할 때 특정 조건이 붙을 수도 있다. 예를 들어 등수를 오름차순으로 정렬하는데, 같은 등수이면 이름을 기준으로 오름차순을 한다고 했을 때처럼
정렬 규칙이 존재하거나 특정 순서를 유지할 때 안정정렬이 좋다. - 시간 복잡도가 모두 O(N log N)을 가진다.
항상 두 배열로 나누기 때문에 최악의 경우에도 O(N log N)을 가져 방대한 데이터를 정렬할 때도 안정적인 성능을 가진다.
단점
- 비제자리 정렬
병합 과정에서 두 하위 배열을 하나의 새로운 배열로 합칠 때 추가적인 공간(메모리)이 필요하다.
그래서 만약 메모리 제약이 있을 경우 다른 정렬 알고리즘을 채택하는 것이 바람직하다.ex) 퀵 정렬
-> 최악의 경우가 O(N^2)이기 하지만, 나머지는 O(N logN)이며, 메모리 역시 log N만큼 든다고 한다. - 하위 배열에서 상위 배열로 복사하는 과정에서 데이터가 많을 경우 시간이 많이 소요된다.
😒 그럼 어떻게 시간복잡도가 O(N log N)으로 고정되나요?
아까 위의 동작 원리를 보면 배열을 둘 씩 나누어 하위 배열을 만드는 모습을 봤을 것이다.
이는, Merge Sort는 binary tree(이진 트리)형태로 분할하기 때문에 최종적으로 배열 크기가 1인 깊이 까지가면 log N이 된다.
이때 각 분할된 배열(N)들을 합병하는 과정을 거치기 때문에 O(N)의 크기를 가진다.
그래서 합병 정렬의 총 시간 복잡도는 O(N log N)의 크기를 가지는 것이다.
필자가 이해한 바는 이렇고 조금 더 세련되고 이해하기 쉬운 내용을 타 블로그에서 봤는데 이를 그대로 설명하면,
8의 크기를 가진 배열이 있다고 가정하자, 우리는 이를 절반씩 나눈다고 가정했을 때,
i번 째 레벨에서 노드(배열)의 개수는 한 노드(배열)안에 들어가 있는 원소의 개수는
그럼 1번 째 레벨(2648 / 3157)을 살펴보면
배열의 총 개수는 로 총 2개 한 노드안에 들어가 있는 원소의 개수는 로 총 4개를 가지는 것을 알 수 있다.
자 그러면 이를 계산해보면 결국 다음과 같다. 그래서 N이 남는다.
우리가 아까 위에서 설명했던 깊이가 log N만큼 진행된다고 했다.
그럼 합병 정렬을 통해 우리가 계산하는 총 연산 횟수는 이 되는 것이다.
※참고자료
자바 [JAVA] - 합병정렬 / 병합정렬 (Merge Sort) Stranger's LAB
이제 합병 정렬을 구현해보고자 한다.
필자 역시 더 좋은 코드를 작성해보고자 여러 블로그를 참고하며 적어봤으나, 위의 링크에 있는 정렬방법이 가장 이해하기 편했고, 코드 컨밴션이나 변수명에서 깔끔하여 해당 코드를 공부한 후 구현해보았다.
🐱👤 합병 정렬(Merge Sort) 구현 - Top down 방식
import java.util.Arrays;
public class Main {
static int[] temp;
public static void main(String[] args) {
int[] arr = new int[]{5,6,3,1,2,7,4};
System.out.println("정렬 전 배열 상태: " + Arrays.toString(arr));
merge_sort(arr);
System.out.println("정렬 후 배열 상태: "+ Arrays.toString(arr));
}
/*
* 정렬된 값을 임시로 가지고 있을
* 배열의 크기만한 temp 배열을 만들기 위한 메서드
*/
static void merge_sort(int[] arr) {
temp = new int[arr.length];
merge_sort(arr, 0, arr.length - 1);
}
static void merge_sort(int[]arr, int left, int right) {
/*
* 배열의 크기가 1인 상황
* 즉, 값이 하나 인 경우 더 이상 나눌 수 없는 형태이므로 그대로 return
*/
if(left == right) {
return;
}
/*
* 중앙값을 받기 위한 mid idx 변수
*/
int mid = (left + right) / 2;
/*
* 맨 위 merge_sort는 배열을 절반으로 나눴을 때, right가 mid인 값
* 아래 merge_sort는 배열을 절반으로 나눴을 때, mid+1부터 left인 값
* ex) 1,3,5,7, 2,4,6,8 -> 1,3,5,7이 첫 번째 / 2,4,6,8이 두 번째
*/
merge_sort(arr, left, mid);
merge_sort(arr, mid+1, right);
/*
* 분할 한 두 배열을 합치기 위한 메서드
*/
merge(arr,left,mid,right);
}
static void merge(int[]arr, int left, int mid, int right) {
int l = left;
int r = mid+1;
/*
* left(좌측)부터 차례대로 임시배열 temp에 정렬된 값을 넣기 위한 변수
* 추후 정렬된 temp배열을 arr배열에 다시 넣어 줄 것이다.
*/
int idx = left;
/*
* left(왼쪽 배열 첫 번째값)가 mid보다 작거나 같으며
* mid+1(오른쪽 배열 첫 번째 값)이 right보다 작거나 같을 때 반복
* 즉, 둘 중 하나만 먼저 끝나도 반복문은 종료된다.
*/
while(l <= mid && r <= right) {
/*
* 기존적으로 배열은 오름차순을 기준으로 한다.
* 즉, 왼쪽값이 오른쪽값보다 작다면! 그대로, 크다면! 변경한다.
*/
/*
* 해당 조건문이 가장 중요한 데, 이 조건문을 통해 안정정렬이 가능하다.
* 즉, 현재 비교하고자 하는 값이 같다면! 좌측 값을 넣음으로써
* 기존에 정렬된 값을 동일한 위치에서 유지할 수 있는 것이다.
* ex) [9(1), 7, 5, 9(2)] -> 정렬하면 [5,7,9(1),9(2)]가 가능한 것
*/
if(arr[l] <= arr[r]) {
temp[idx] = arr[l];
idx++;
l++;
}
else {
temp[idx] = arr[r];
idx++;
r++;
}
}
/*
* while문이 종료된 후 왼쪽 배열 혹은 오른쪽 배열의 잔여 요소를
* 반환하기 위한 조건 반복문
* 남은 값은 이미 정렬된 상태이기 때문에 그대로 넣어주면 된다.
*/
if(l > mid) {
while(r <= right) {
temp[idx] = arr[r];
idx++;
r++;
}
}
else{
while(l <= mid) {
temp[idx] = arr[l];
idx++;
l++;
}
}
/*
* 정렬된 임시 배열 temp를 본 배열(arr)에 넣어줌
* 이로인해 추후 상위 부분리스트에서 정렬된 arr을 활용할 것이며
* 남은 정렬 부분까지 마무리 짓게 된다.
*/
for(int i = left; i <= right; i++) {
System.out.print(temp[i] + " ");
arr[i] = temp[i];
}
System.out.println();
}
}

해당 방법이 Top-down 방식이라고 한다. 위에서 보여준 그림이 Top-down 방식으로 나타낸 것이다.
Top-down 방식은 기본적으로 재귀적으로 접근하여 문제를 풀기 때문에
스택 오버플로우와 같은 문제가 발생할 수 있다.
🐱👤 합병 정렬(Merge Sort) 구현 - Bottom up 방식
먼저 코드를 확인하기 이전에 bottom-up 방식에 대해서 간략히 설명하면,
위의 top-down방식을 봤을 때는 8의 크기를 가지는 배열이 존재한다면, 절반씩 나누어서 분할한 것을 기억할 수 있다.
반대로 bottom up 방식은, 먼저 하위 부분부터 만든 다음 정렬하며 병합하는 방식이다.
이를 그림으로 표현한다면, 다음과 같다.
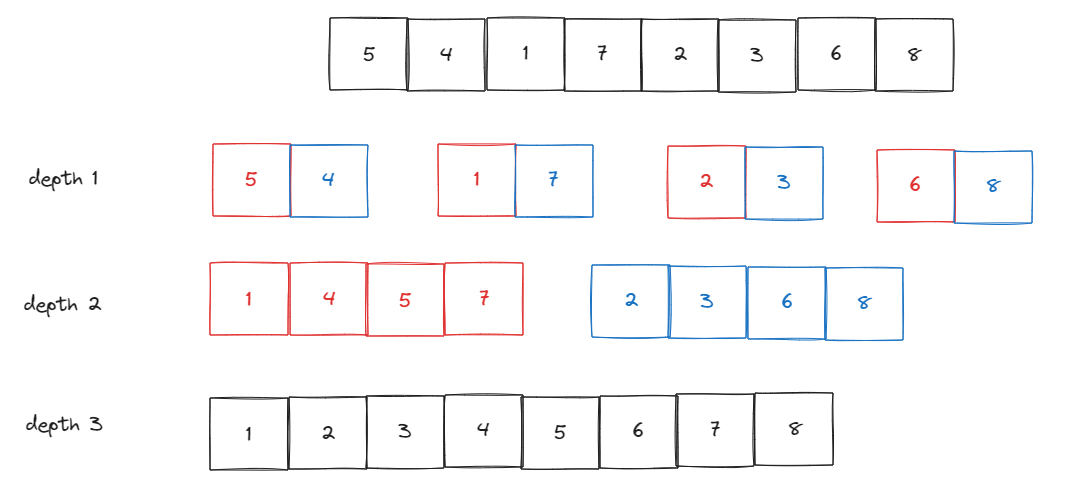
이제 한번 구현해보자
import java.util.Arrays;
public class Main {
static int[] temp;
public static void main(String[] args) {
int[] arr = new int[]{5,4,1,7,2,3,6,8};
System.out.println("정렬 전 배열 상태: " + Arrays.toString(arr));
merge_sort(arr);
System.out.println("정렬 후 배열 상태: "+ Arrays.toString(arr));
}
/*
* 정렬된 값을 임시로 가지고 있을
* 배열의 크기만한 temp 배열을 만들기 위한 메서드
*/
static void merge_sort(int[] arr) {
temp = new int[arr.length];
merge_sort(arr, 0, arr.length - 1);
}
static void merge_sort(int[]arr, int left, int right) {
/*
* 배열의 개수가 1, 2, 4, 8.. 이렇게 아래서부터 위로 증가한다고 보면 된다.
* top down 방식은
* 예로 배열 크기가 8일때, 8 -> 4, 4 -> 2,2 / 2,2 -> 1,1 / 1,1 // 1,1 / 1,1
* 했던 것을 반대로 한다고 보면 된다.
* size의 반복횟수가 길이와 같은 이유는,
* 배열의 개수가 홀수일 경우 길이 -1만큼 넣기 때문에 수가 짝수이다.
* 근데 만약, 길이가 <=가 아닌 <만 해버리면, 마지막 남은 한 수는
* 확인하지 못하는 경우가 발생하기 때문에 반드시 <=를 해줘야 하는 것이다.
*/
for(int size = 1; size <= arr.length; size = size * 2) {
/*
* 인덱스 번호를 불러오기 위한 반복문
* size가 1이라면, 한 개씩 비교하는 것이기 때문에
* 왼쪽 오른쪽해서 총 두 개의 인덱스 값을 받아 비교할 것이다.
* 그래서 i증가량이 2 * size인 것,
*/
for(int i = 0; i <= arr.length - size; i += (2 * size)) {
int l = i;
/*
* 우리가 흔히 미드를 구할 떄 (0 + arr.length-1) / 2 로 구했던 것을 알 것이다.
* 이를, length가 곧 size가 되었다고 생각하면 된다.
* 그럼 /2를 안하는 이유는??..
* 필자 생각으로는, 이미 배열을 두 개로 나눈 상태이기 때문에 /2를 해주지 않는 것이라 이해했다.
*/
int mid = l + size - 1;
/*
* r 역시 마찬가지다. 하지만, 여기서 l과 r은 비교 대상이 되는 배열로,
* 결국 2 * size가 곧 비교 대상 배열의 마지막 인덱스가 될 것이다.
* 근데 왜 right와 비교해서 최솟값을??
* size가 커지면, 또 l값이 커지면 right보다 커지는 순간이 반드시 오기 때문이다.
*/
int r = Math.min(l + (2 * size) -1, right);
/*
* 분할 한 두 배열을 합치기 위한 메서드
*/
merge(arr, l, mid, r);
}
}
}
static void merge(int[]arr, int left, int mid, int right) {
int l = left;
int r = mid+1;
/*
* left(좌측)부터 차례대로 임시배열 temp에 정렬된 값을 넣기 위한 변수
* 추후 정렬된 temp배열을 arr배열에 다시 넣어 줄 것이다.
*/
int idx = left;
/*
* left(왼쪽 배열 첫 번째값)가 mid보다 작거나 같으며
* mid+1(오른쪽 배열 첫 번째 값)이 right보다 작거나 같을 때 반복
* 즉, 둘 중 하나만 먼저 끝나도 반복문은 종료된다.
*/
while(l <= mid && r <= right) {
/*
* 기존적으로 배열은 오름차순을 기준으로 한다.
* 즉, 왼쪽값이 오른쪽값보다 작다면! 그대로, 크다면! 변경한다.
*/
/*
* 해당 조건문이 가장 중요한 데, 이 조건문을 통해 안정정렬이 가능하다.
* 즉, 현재 비교하고자 하는 값이 같다면! 좌측 값을 넣음으로써
* 기존에 정렬된 값을 동일한 위치에서 유지할 수 있는 것이다.
* ex) [9(1), 7, 5, 9(2)] -> 정렬하면 [5,7,9(1),9(2)]가 가능한 것
*/
if(arr[l] <= arr[r]) {
temp[idx] = arr[l];
idx++;
l++;
}
else {
temp[idx] = arr[r];
idx++;
r++;
}
}
/*
* while문이 종료된 후 왼쪽 배열 혹은 오른쪽 배열의 잔여 요소를
* 반환하기 위한 조건 반복문
* 남은 값은 이미 정렬된 상태이기 때문에 그대로 넣어주면 된다.
*/
if(l > mid) {
while(r <= right) {
temp[idx] = arr[r];
idx++;
r++;
}
}
else{
while(l <= mid) {
temp[idx] = arr[l];
idx++;
l++;
}
}
/*
* 정렬된 임시 배열 temp를 본 배열(arr)에 넣어줌
* 이로인해 추후 상위 부분리스트에서 정렬된 arr을 활용할 것이며
* 남은 정렬 부분까지 마무리 짓게 된다.
*/
for(int i = left; i <= right; i++) {
System.out.print(temp[i] + " ");
arr[i] = temp[i];
}
System.out.println();
}
}

top-down 방식과 비교했을 때, 정렬하는 방식이 다른 것을 파악할 수 있다.
❤ 참고자료
자바 [JAVA] - 합병정렬 / 병합정렬 (Merge Sort) Stranger's LAB
