
저희가 rmse를 이용하여 성능평가를 해주었는데요. rmse를 사용한 이유는 캐글에서 성능평가를 할 때 rmse를 사용하라고 나와있어서 사용하게 되었습니다.
mse가 아닌 rmse를 사용한 이유는 분산 대신 표준편차를 사용하는 이유와 비슷한데 우선 공식을 보면 예측값과 관측값의 차이를 제곱해주고 평균을 구한 게 mse인데 여기에 루트를 씌워주면 rmse가 됩니다. rmse는 제곱한 것에 다시 루트를 씌워준 것이기 때문에 더 직관적으로 볼 수 있습니다. 또한 mse는 제곱을 해주었기 때문에 큰 오차를 작은 오차에 비해 확대시키기 때문에 왜곡이 발생할 수 있습니다.
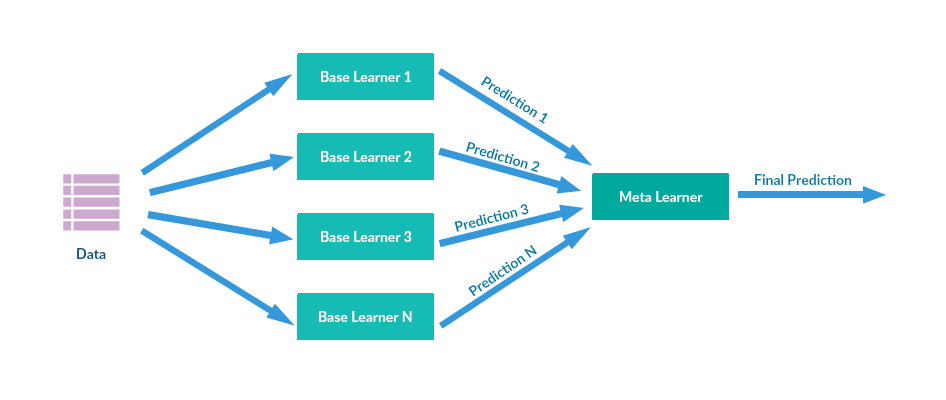
스태킹에 대해 설명하겠습니다.
스태킹은 여러 모델들이 학습한 데이터를 통해 도출된 예측 데이터를 쌓아서 합쳐주고 그것을 다시 메타 모델에 학습시켜 최종적인 예측값을 도출해주는 원리입니다.
코드에 나와있는 6가지 모델들을 사용하였고 메타 모델로는 xgboost를 이용하였습니다.
6가지 모델들이 도출한 데이터를 쌓아주고 이렇게 스태킹된 데이터를 xgboost에 학습시켜 최종적인 예측값을 도출해줄 것입니다.
score 함수에 대해 설명하겠습니다.
우선 scores 딕셔너리를 만들어주고 거기에 각 모델별로 계산한 평균과 표준편차를 구해서 넣어줍니다. 여기서 평균을 구해주는 이유는 cv가 교차검증이라는 뜻인데 교차 검증에서는 데이터를 여러 개의 폴드로 나누고 각 폴드에 대해 모델을 학습하고 평가합니다. 이때 나온 폴드에서의 rmse값을 평균내준 것이기 때문에 평균을 구해준 것입니다. 표준 편차는 작을수록 모델의 예측값들이 평균값 주변에 집중되어 있어 모델의 안정성이 높다고 볼 수 있습니다. 이렇게 모델별로 저장된 rmse값들은 나중에 시각화를 통해 모델별로 rmse값을 비교해줄 것입니다.
fit함수에 대해 설명하겠습니다.
fitting한다는 것은 훈련시킨다는 것과 같은 의미입니다. fit함수는 향후 예측을 위해 모델들을 훈련시켜주는 함수입니다.
코드를 보면 (stack_gen_model)스태킹 모델부터 (gbr_model_full_data)gbr 모델까지 fitting 해주었습니다.
이렇게 fitting된 모델들은 아래 blending 작업을 해줄때 predict 메서드를 통해 예측을 해줄 수 있습니다.
