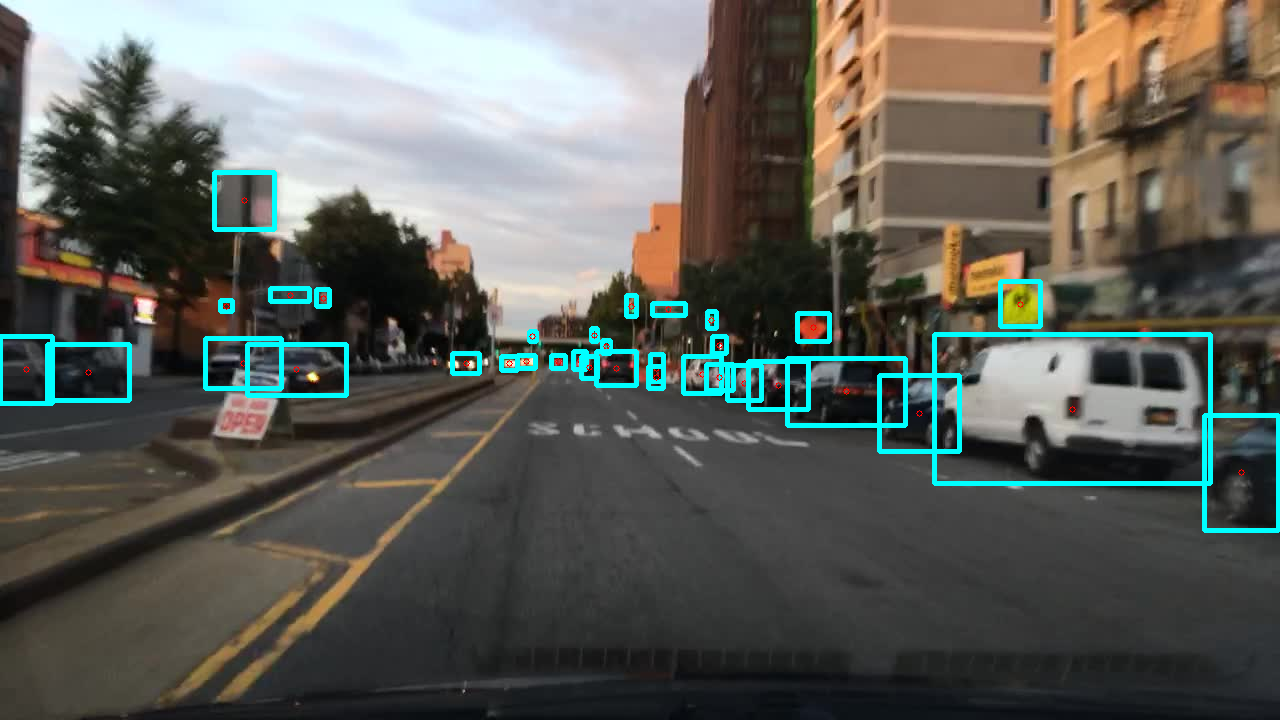
0. BDD dataset 및 환경 설정
- docker로 만든 pytorch 환경에서 구현했다 (사실 그냥 opencv가 설치되어 있는 환경이면 어디든 가능하다)
- docker pytorch 환경 구축 에서 만든 container를 사용했다
- 그런데!! cv2.imshow()가 안된다ㅠ 임시방편으로 cv2.write() 사용하여 이미지를 저장해서 확인하였다
- train 데이터는 양이 많아서 일단 val 데이터로 구현하였다
BDD data labels
- det_val.json 파일
- 1000개의 이미지에 대해 리스트 형식으로 구현되어 있다
- yolo 데이터 format으로 변환할 때 사용하는 부분들을 중점으로 json 파일을 보면 아래와 같이 구성되어 있다
[
{
"name" : "이미지 파일 이름.jpg",
"labels" [
{
"id": "이미지 안에서 검출되는 obejct_id",
"category": "class name",
"box2d" :{
"x1": left x 좌표,
"y1": top y 좌표,
"x2": right x 좌표,
"y2": botton y 좌표
}
},
.
.
.
{
"id": "이미지 안에서 검출되는 obejct_id",
"category": "class name",
"box2d" :{
"x1": left x 좌표,
"y1": top y 좌표,
"x2": right x 좌표,
"y2": botton y 좌표
}
}
]
},
{
반복
}
]
- 즉 json 파일안에 여러 이미지에 대한 정보가 리스트로 담겨있고, 하나의 이미지에서 검출되는 여러 object들에 대한 정보가 담겨있다
- {class_id} {x} {y} {width} {height}
- {x} {y} : object의 중심 x, y 좌표
- {width} {height} : oject의 width, height
- 이때 x, t, width, height는 0 ~ 1 사이의 값으로 normalization 되어 있다
2. 구현
2-1. import 및 변수 설정
- 파일 경로, class id와 같이 구현하면서 필요한 변수들을 설정한다
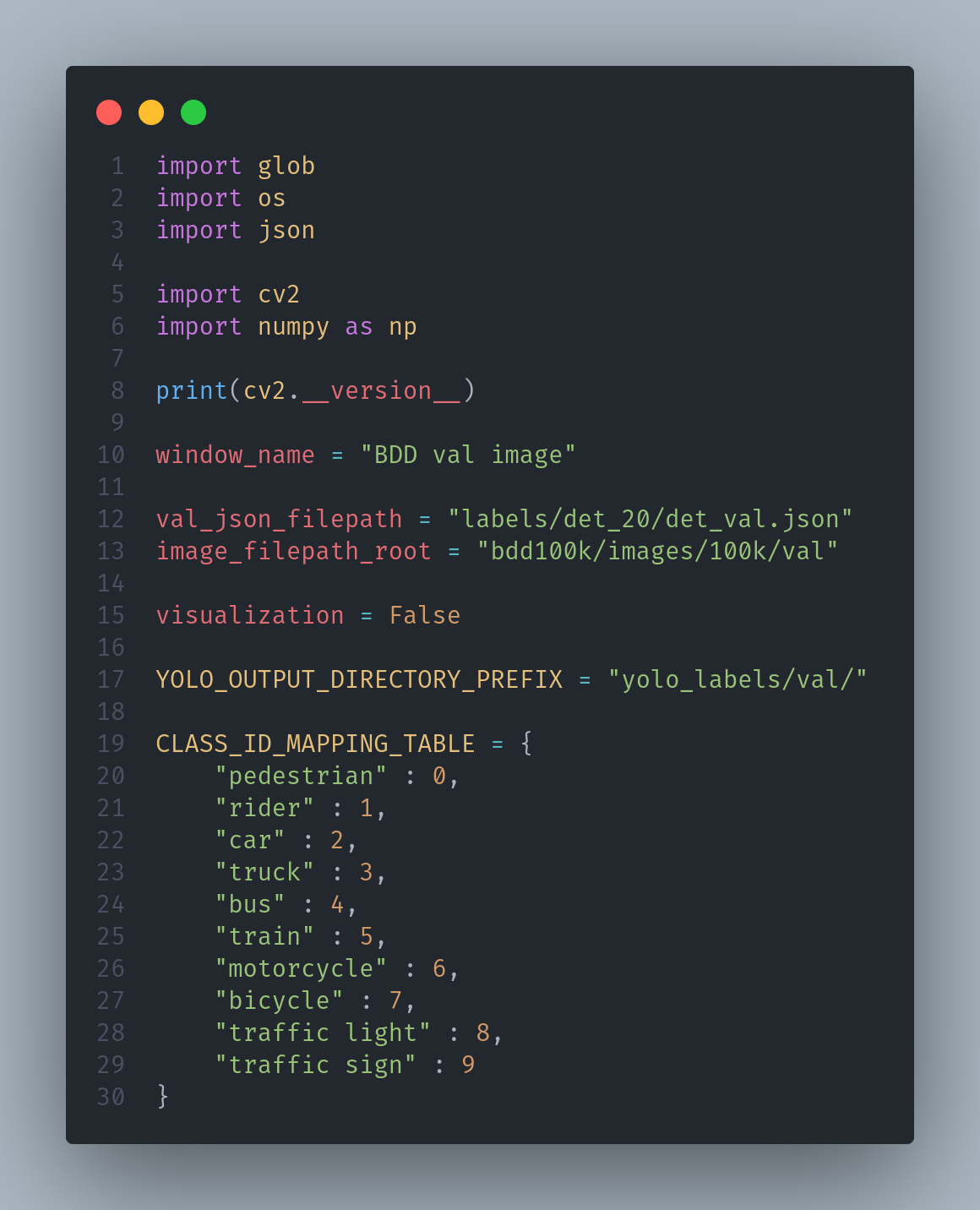
- window_name : 시각화할 window명
- val_json_filepath : 읽어올 json 파일 경로
- image_filepath_root : image 데이터들이 위치해 있는 파일 경로
- visualization : 이미지를 시각화하는지 여부
- YOLO_OUTPUT_DIRECTORY_PREFIX : yolo 데이터 format으로 변경한 결과를 저장할 경로
- CLASS_ID_MAPPING_TABLE : class의 이름과 그에 맞는 id 값
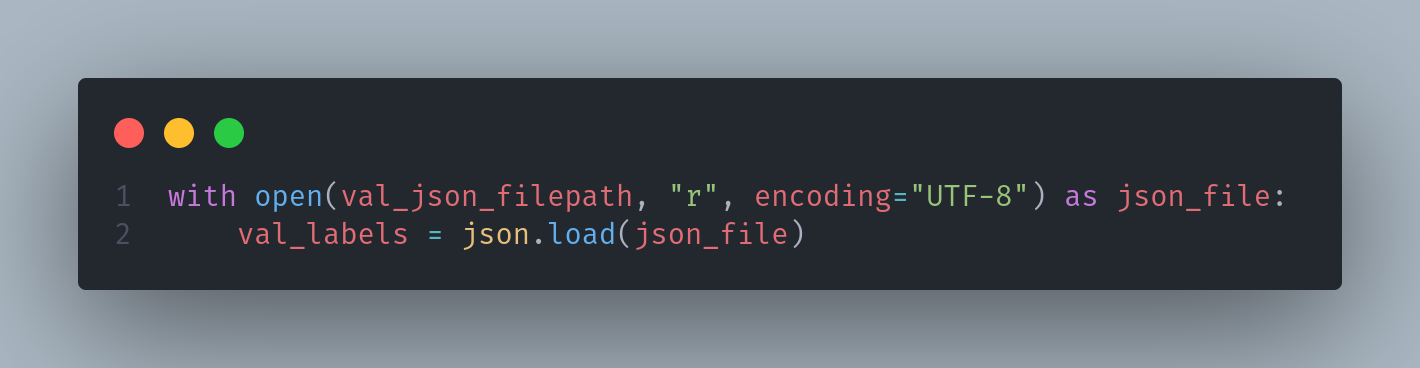
2-2. json 파일 불러오기
2-3. 이미지 데이터 불러오는 함수 작성
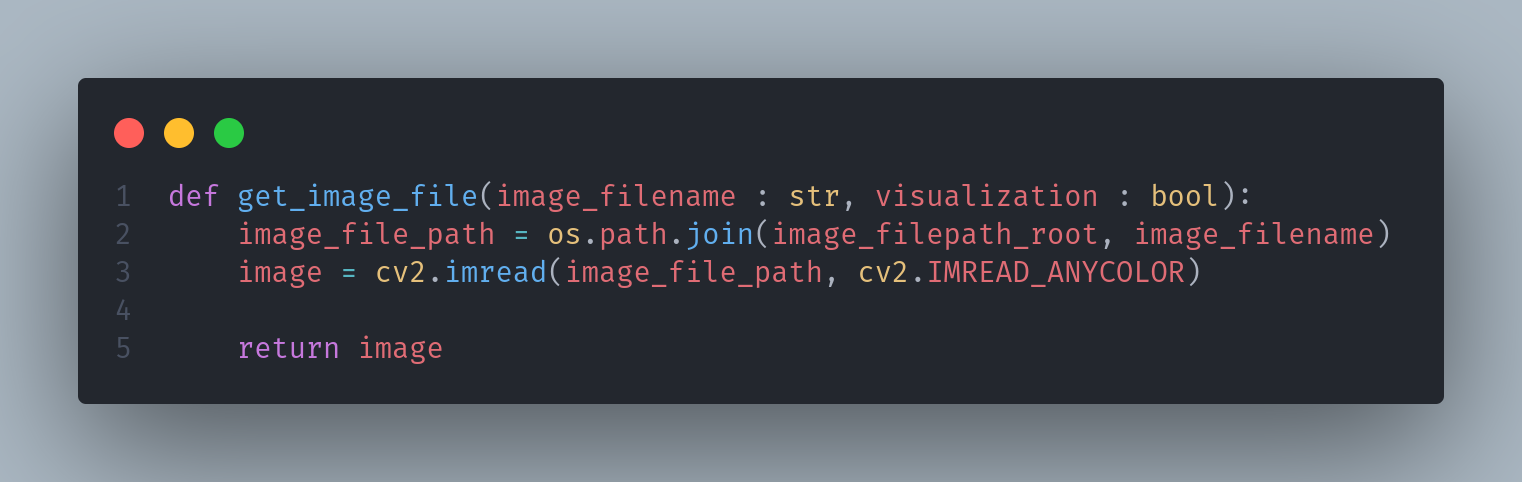
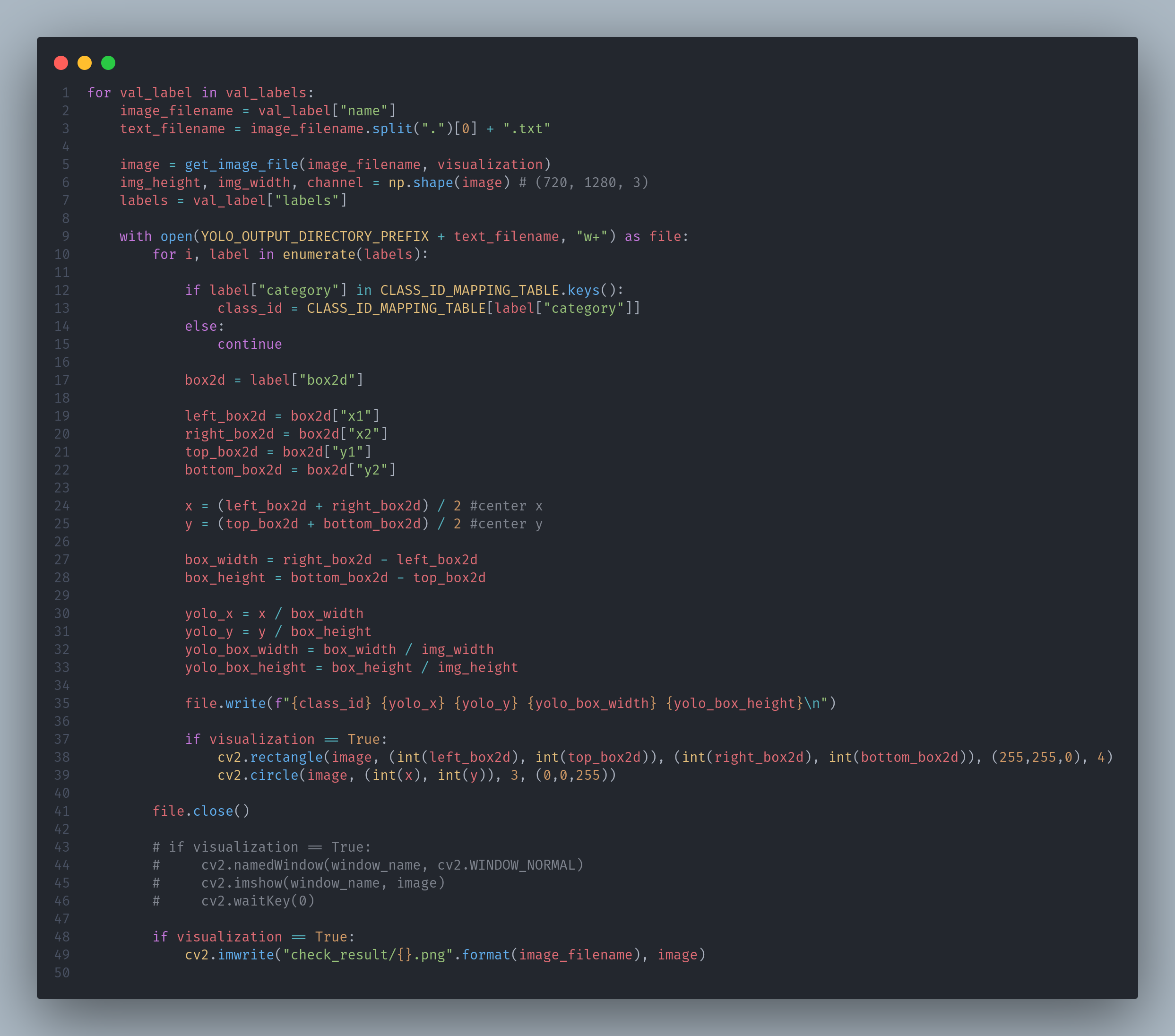
- json 파일에서의 "name"에서 파일명을 얻어온다
- json 파일에서의 "labels"에서 하나의 이미지 안에 있는 여러 object에 대한 정보를 얻어온다
- "category"를 통해 class 정보를 얻고 앞에서 만든 CLASS_ID_MAPPING_TABLE을 통해 class_id를 얻는다
- 이때 CLASS_ID_MAPPING_TABLE에 존재하지 않는 class가 있을 수 있으므로 예외처리를 해준다
- "box2d"에서 x, y값들을 얻어오고 이를 yolo format에 맞게 중심 x, y 좌표와 width, height 값으로 변환한다
- 변환한 값들을 0 ~ 1 사이의 값으로 normalization 한다
- txt 파일으로 yolo 데이터를 저장한다
- 시각화해서 확인하기 위해 object box(파란색 사각형)와 중심점(빨간색 원)을 그려준다