Intrinsic Calibration
- Intrinsic calibration은 3차원 공간에 존재하는 물체가 2차원 이미지 공간에 투영되는 과정을 통해 카메라 고유의 특성을 파악하는 것이다
- intrinsic calibration 과정에서 intrinsic matrix, distortion coefficients를 계산할 수 있다
- 과정 : distortion된 이미지 -> undistortion -> detection -> POSE 추정
- distortion coefficient은 카메라마다 다르다
- 환경 : OpenCV-Python 사용
- 참고 : https://docs.opencv.org/4.x/dc/dbb/tutorial_py_calibration.html
- 그외의 여러 tool box가 있다
- GML calibration
- matlab
- mc-calib : multi camera에 대해서 calibration 수행
calibration pattern
- intrinsic calibration을 수행하기 위해서 준비물이 필요하다
- calibration pattern이라고 부르는 특별한 보드가 필요하다
- calibration pattern은 intrinsic calibration을 쉽고 간단하게 하기 위해 규격화된 모양을 만든 것이다

calibration board 예시
- calibration board에서 중요한 것은 일정하고 평면(Z=0)에 만들어져야 한다는 것이다
- calibration board는 레퍼런스로 활용하기 때문에 board에 왜곡이 있다면 결과가 제대로 나오지 않는다
- 조건
- 각 grid cell의 정확한 크기를 알고 있을 것
- grid의 사이즈를 알고 있을 것 (빨간색 점의 개수)
- 패턴 사이즈로 짝수와 홀수를 사용한다
: 둘다 짝수이면 가로, 세로를 구분하기 애매할 수 있기 때문이다

Intrinsic Calibration 구현
1. chessboard pattern 검출
- chessboard의 corner 검출한다
- opencv의 chessboard corner 검출 함수를 사용한다
cv.findChessboardCorner(gray이미지, (체스보드 사이즈))- return 값
- corners : 이미지 포인트의 위치
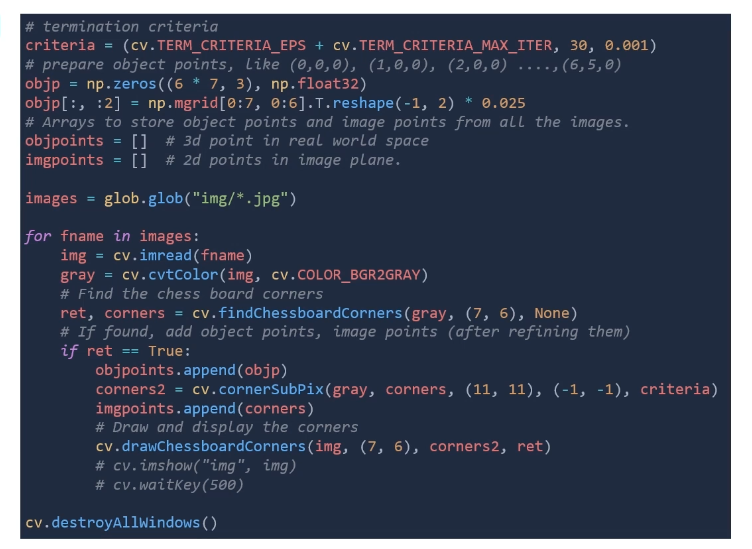
- criteria : corner 검출 조건
- objp : object point, 3차원의 체스보드를 의미한다
- 크기 : 체스보드의 사이즈, 3 (x,y,z)
- 0.025 : 체스보드의 사각형 사이즈 (m 단위)
- objpoints : x,y,z로 real world space에서의 좌표
- imgpoints : 2차원 이미지의 좌표
핵심 부분
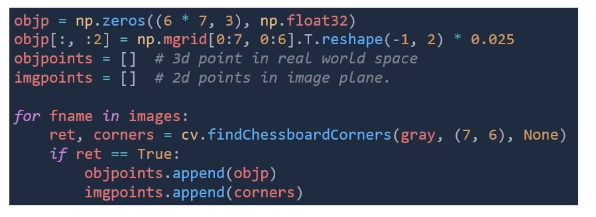
- object point (m 단위)와 image point (pixel 단위)가 얼마나 잘 매칭되는지가 중요하다
- 3차원 월드 공간에 존재하는 object의 위치정보 (objpoints)
- 2차원 이미지 공간에 존재하는 object 이미지 픽셀 위치 정보 (imgpoints)
- 이 두개의 쌍을 올바르게 설정해야한다
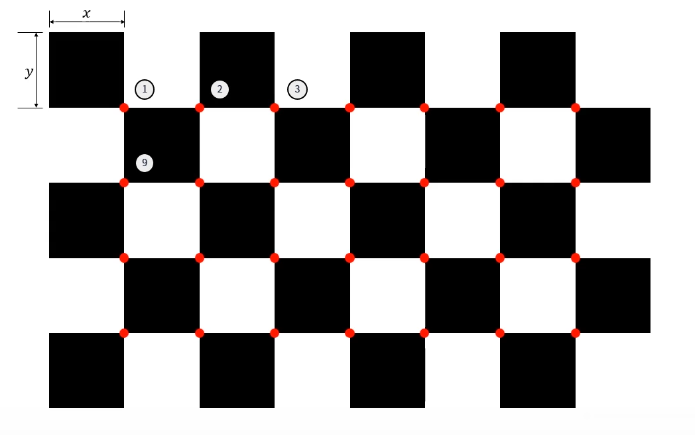
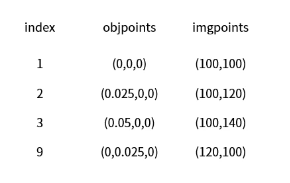
objpoints와 imgpoints의 관계
- pattern size : 4x7
- square size : 0.025 (m)
 |  |
|---|
-
1번이 원점 (origin) : (0,0,0)
-
objpoints를 camera coordinate 즉 (0,0,0)으로 시작하면 첫번째 인덱스를 기준으로 카메라가 해당 위치에 존재한다고 가정한다
2. camera calibration
ret, mtx, dist, rvecs, tvecs = cv.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)- return 값
- ret : 캘리브레이션 여부
- mtx : intrinsic matrix
- dist : 왜곡 계수
- rvecs, tvecs : extrinsic calibration (카메라에 대한 extrinsic과는 다르다)
- 해당 image에서의 rvec, tves이다
- 실제 이미지의 원점과 카메라 간의 R|t를 의미한다
- 이때 objpoints의 원점을 (0,0,0)으로 하여 계산한다
3. 왜곡 보정
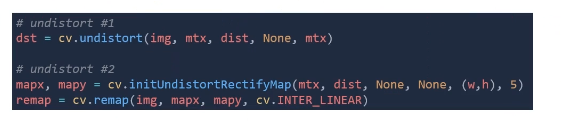
- opencv에는 왜곡 보정 함수가 2가지 있다
- cv.undistort()
- cv.initUndistortRectifyMap() + cv.remap()
- cv.undistort()은 내부적으로 cv.initUndistortRectifyMap(), cv.remap() 이 두가지를 호출하고 있다
- 하지만 RectifyMap을 계산하는 것은 camera matrix와 distortion coefficients를 알면 한번만 계산하면 된다
- 하나의 이미지인 경우 방법 두개의 속도가 같다
- 하지만 비디오의 경우에는 두 함수를 분리하여 카메라로부터 이미지를 받을 때 cv.remap()을 적용하는 것이 효율적이다
- 이미지를 받을 때 마다 rectifymap을 계산하는 것은 비효율적이다
- getOptimalNewCameraMatrix()
- 카메라의 고유한 특징 = camera matrix
- 최적의 camera matrix를 계산해주는 것
- calibrateCamera()과 같이 mtx 결과가 나온다. 이를 undistortion 방법에 넣어보며 calibrateCamera과 어떤 차이가 있는지 확인해보면 좋을 것 같다
