
3. 정렬 + stack / queue + Hash
- 정렬
-> 정렬이란 데이터를 순서대로 나열하는 방법을 의미한다. 정렬은 알고리즘의 굉장히 중요한 주제인데, 이진 탐색을 가능하게도 하고, 데이터를 조금 더 효율적으로 탐색할 수 있게 만들기 때문이다.
ex)
[4, 6, 2, 9, 1] # 정렬되지 않은 배열
[1, 2, 4, 6, 9] # 오름차순으로 정렬된 배열!
[9, 6, 4, 2, 1] # 내림차순으로 정렬된 배열!-> 컴퓨터에게 정렬을 시키기 위해서는 명확한 과정을 설명해줘야 한다.
- 버블 정렬 (Bubble sort)
버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, … 이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬하는 방식이다. 중간 중간에 작은 숫자, 큰 숫자 순서로 있으면 내버려두고 큰 숫자, 작은 숫자 순서로 있으면 둘의 위치를 변경하면 된다.
ex)
1번째 : [4, 6, 2, 9, 1]
→ → → → 비교
2번째 : [4, 2, 6, 1, 9]
→ → → 비교
3번째 : [2, 4, 1, 6, 9]
→ → 비교
4번째 : [2, 1, 4, 6, 9]
→ 비교
즉, 배열의 크기만큼 반복했다가, 1개씩 줄어들면서 반복하게 된다.
- 선택 정렬 (selection sort)
말 그대로 선택해서 정렬한다는 느낌인데, 필요한 조건의 원소를 해당 배열에서 찾아서 맨 앞 자리와 교체하는 방식으로 정렬하는 방식이다.
ex)
1번째 : [4, 6, 2, 9, 1]
4, 6, 2, 9, 1 중 최솟값 찾기
2번째 : [1, 6, 2, 9, 4]
6, 2, 9, 4 중 최솟값 찾기
3번째 : [1, 2, 6, 9, 4]
6, 9, 4 중 최솟값 찾기
4번째 : [1, 2, 4, 9, 6]
9, 6 중 최솟값 찾기
즉, 배열의 크기만큼 반복했다가, 앞에서부터 1개씩 줄어들면서 반복하게 된다.
- 삽입 정렬 (Insertion sort)
선택 정렬이 전체에서 최솟값을 "선택" 하는 거 였다면, 삽입 정렬은 전체에서 하나씩 올바른 위치에 "삽입" 하는 방식이다. 선택 정렬은 현재 데이터의 상태와 상관없이 항상 비교하고 위치를 바꾸지만, 삽입 정렬은 필요할 때만 위치를 변경하므로 더 효율적인 방식이다.
ex)
1번째 : [4, 6, 2, 9, 1]
← 비교!
2번째 : [4, 6, 2, 9, 1]
← ← 비교!
3번째 : [2, 4, 6, 9, 1]
← ← ← 비교!
4번째 : [2, 4, 6, 9, 1]
← ← ← ← 비교!
즉, 1만큼 비교했다가, 1개씩 늘어나면서 반복하게 된다.
- 내부 반복문 안에서, 만약
array[i - j - 1] > array[i - j] 라면 두 값을 변경해주고,
아니라면 탈출하면 된다. 이유는 이미 앞에 있는 원소들이 정렬이 되었으므로 더 비교할 이유가 없기 때문이다.
위의 예시 중 3단계에 해당.
3단계 : [2, 4, 6, 9, 1]
9는 앞에 6과 비교하지만 6 < 9 이기 때문에 그대로 냅둬도 된다. 이후에 9와 4는 앞에 원소들은 이미 6보다 낮은 숫자들로 정렬되어 있으니 비교할 필요가 없다.
- 시간 복잡도 (Time Complexity)
-> 앞서 살펴본 세 가지 정렬방식은 모두 O(N^2) 만큼 걸린다. 그러나, 삽입 정렬은 버블 정렬과 선택 정렬과는 다른 면이 있는데, 버블 정렬과 선택 정렬은 최선의 경우의 수든 최악의 경우의 수든 항상 O(N^2) 만큼의 시간이 걸렸지만, 삽입 정렬은 최선의 경우에는 Ω(N) 만큼의 시간 복잡도가 걸린다. 거의 정렬이 된 배열이 들어간다면 break 문에 의해서 더 많은 원소와 비교하지 않고 탈출할 수 있기 때문이다.
- 병합 정렬 (Merge Sort)
병합 정렬은 배열의 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후 병합하는 작업을 반복하는 알고리즘이다.
ex)
A 라고 하는 배열이 1, 2, 3, 5 로 정렬되어 있고,
B 라고 하는 배열이 4, 6, 7, 8 로 정렬되어 있다면
이 두 집합을 합쳐가면서 정렬하는 방법이다.
array_a = [1, 2, 3, 5]
array_b = [4, 6, 7, 8]
def merge(array1, array2):
result = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
result.append(array1[array1_index])
array1_index += 1
else:
result.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
result.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2):
while array1_index < len(array1):
result.append(array1[array1_index])
array1_index += 1
return result
print(merge(array_a, array_b))
print("정답 = [-7, -1, 5, 6, 9, 10, 11, 40] / 현재 풀이 값 = ", merge([-7, -1, 9, 40], [5, 6, 10, 11]))
print("정답 = [-1, 2, 3, 5, 10, 40, 78, 100] / 현재 풀이 값 = ", merge([-1,2,3,5,40], [10,78,100]))
print("정답 = [-1, -1, 0, 1, 6, 9, 10] / 현재 풀이 값 = ", merge([-1,-1,0], [1, 6, 9, 10]))-
두 개의 배열을 합치기 위해서는 각 배열의 값들을 하나씩 비교한다.
-
그리고 더 작은 값을 새로운 배열에 하나씩 추가해간다.
-
그리고 나서 한 배열이 끝나면?
남은 배열의 모든 값을 새로운 배열에 추가하면 된다. -
그러기 위해서 result 라는 새로운 배열을 만든 다음에, while 문을 이용해서 비교 이후에 값을 추가하면 된다.
- 그렇다면, 배열을 합치는 것과 병합 정렬의 차이는..?
-> 분할 정복의 개념을 적용
분할 정복은 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
예를 들어서 [5, 4] 라는 배열이 있다면, 이 배열을 [5] 와 [4] 를 가진 각각의 배열로 작은 2개의 문제로 분리해서 생각하는 것이다. -> 이 둘을 합치면서 정렬한다면? 결국 전체의 정렬된 리스트가 될 수 있다.
-> 이 개념을 조금 더 확대해서 생각해보면...
[5, 3, 2, 1, 6, 8, 7, 4] 이라는 배열이 있다. 이 배열을 반으로 쪼개면
[5, 3, 2, 1][6, 8, 7, 4] 이 된다. 여기서 또 반으로 쪼개면
[5, 3][2, 1] [6, 8][7, 4] 이 되고, 마지막으로 또 반으로 쪼개면
[5][3] [2][1] [6][8] [7][4] 이 된다.
그렇다면, 다시 이 배열들을 두개씩 병합을 하면?
[5][3] 을 병합하면 [3, 5] 로
[2][1] 을 병합하면 [1, 2] 로
[6][8] 을 병합하면 [6, 8] 로
[7][4] 을 병합하면 [4, 7] 로
그러면 다시..
[3, 5] 과 [1, 2]을 병합하면 [1, 2, 3, 5] 로
[6, 8] 와 [4, 7]을 병합하면 [4, 6, 7, 8] 로
그러면 다시..
[1, 2, 3, 5] 과 [4, 6, 7, 8] 를 병합하면 [1, 2, 3, 4, 5, 6, 7, 8] 이 된다.
-> 문제를 쪼개서 일부분들을 해결하다보니, 어느새 전체가 해결되는것을 확인할 수 있다.
이를 분할 정복, Divide and Conquer 라고 한다.
-> 반복되는 메커니즘이 있다는 점에서, 재귀적으로도 한번 바라보자.
자기 자신을 포함하는 형식으로 함수를 이용해서 정의해보면,
함수명 MergeSort(시작점, 끝점) 이라고 해보자.
그러면
MergeSort(0, N) = Merge(MergeSort(0, N/2) + MergeSort(N/2, N))
라고 할 수 있다.
즉, 0부터 N까지 정렬한 걸 보기 위해서는
0부터 N/2 까지 정렬한 것과 N/2부터 N까지 정렬한 걸 합치면 된다.
(아까 봤던 [1, 2, 3, 5] 와 [4, 6, 7, 8] 을 합치면 정렬된 배열이 나온 것 처럼)
-> 여기서 MegeSort는 재귀함수니까, 재귀 함수의 필수 조건, 탈출 조건을 써줘야한다.
-> but, when?
문자열의 길이가 1보다 작거나 같을 때, 즉 하나의 원소만 존재할때는 반드시 정렬되어 있으므로, 해당 조건을 탈출 조건으로 걸면 된다.
- 스택(stack)
stack 이란?
-> 한쪽 끝으로만 자료를 넣고 뺄 수 있는 자료 구조.
-> LIFO (Last In First Out) 구조를 가지고 있는 자료 구조이다. 가장 처음에 넣은 원소가 가장 늦게 나오고, 가장 늦게 넣은 원소가 가장 빨리 나온다.
LIFO 형태의 자료구조가 필요한 이유는?
-> 넣은 순서를 쌓아두고 있기 때문이다.
ex)
컴퓨터의 되돌리기(Ctrl + Z) 기능을 떠올려보면 된다. 해당 기능을 위해서는 내가 했던 행동들을 순서대로 기억해야 하므로 스택을 사용한다.
스택 이라는 자료 구조에서 제공하는 기능은 다음과 같다.
push(data) : 맨 앞에 데이터 넣기
pop() : 맨 앞의 데이터 뽑기
peek() : 맨 앞의 데이터 보기
isEmpty(): 스택이 비었는지 안 비었는지 여부 반환해주기
- 큐(queue)
큐(queue)란?
-> 한쪽 끝으로 자료를 넣고, 반대쪽에서는 자료를 뺄 수 있는 선형구조.
-> FIFO (First In First Out) 구조를 가지고 있는 자료 구조이다. 가장 처음에 넣은 원소가 가장 먼저 나오고, 가장 늦게 넣은 원소가 가장 늦게 나온다.
FIFO 형태의 자료구조가 필요한 이유는?
-> 순서대로 처리되어야 하는 일에 필요하기 때문이다.
주문이 들어왔을 때 먼저 들어온 순서대로 처리해야 할 때, 혹은 먼저 해야 하는 일들을 저장하고 싶을 때 큐를 사용한다.
큐라는 자료 구조에서 제공하는 기능은 다음과 같다.
enqueue(data) : 맨 뒤에 데이터 추가하기
dequeue() : 맨 앞의 데이터 뽑기
peek() : 맨 앞의 데이터 보기
isEmpty(): 큐가 비었는지 안 비었는지 여부 반환해주기
큐는 데이터 넣고 뽑는 걸 자주하는 자료구조이기 때문에, 스택과 마찬가지로 링크드 리스트와 유사하게 구현할 수 있는데, 스택과 다른점은 큐는 끝과 시작의 노드를 전부 가지고 있어야 하므로, self.head 와 self.tail 을 가지고 시작한다.
- 해쉬(Hash)
해쉬 테이블이란?
-> 컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다. 해시 테이블은 해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산한다. 데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행된다.
-> 키로 데이터를 저장하고 찾을 수 있는 방법이기에, 파이썬의 딕셔너리와 같은 개념이라고 보면 된다.
-> 키를 통해 바로 데이터를 받아올 수 있으므로, 속도가 획기적으로 빨라지고, 찾는 데이터가 있는지 배열을 전부 둘러볼 필요 없이, 키에 대해서 검색하면 바로 값을 조회할 수 있는 아주 유용한 자료구조이다.
- 딕셔너리가 내부적으로는 배열을 사용하는데, 인덱스를 몇번에 넣어야 하는지, 몇번에서 찾아야 하는지를 알기 위해서 이용하는 것이 바로 해쉬 함수이다.
-> 여기서 해쉬함수란?
-> 해쉬 함수(Hash Function)는 임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수이다.
충돌
-> 그런데 만약 해쉬의 값이 같으면..? or 해쉬 값을 배열의 길이로 나눴더니 똑같은 숫자가 된다면..?
-> 같은 어레이의 인덱스로 매핑이 되어서 데이터를 덮어 써버리는 결과가 발생하고, 이를 충돌(collision)이 발생했다고 한다. -> 이런 충돌을 따로 해결해줘야 한다.
-> 충돌을 해결하는 첫번째 방법은 바로 링크드 리스트를 사용하는 방식이다. 이 방식을 연결지어서 해결한다고 해서 체이닝(Chaining) 이라고 한다.
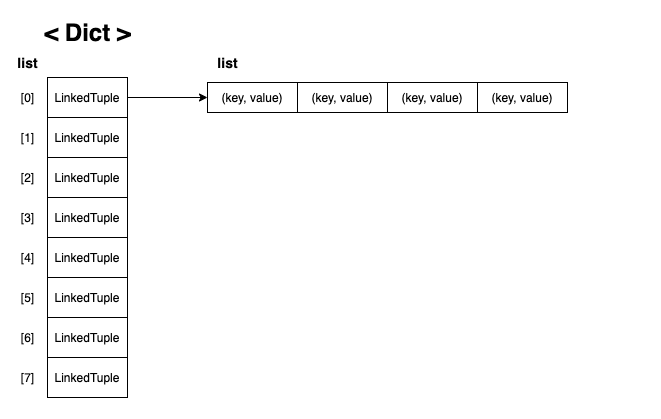
-> 충돌을 해결하는 두 번째 방법은 배열의 다음 남는 공간에 넣는 것 이다. fast 의 해쉬 값이 3이 나와서 items[3] 에 들어가는데, slow 의 해쉬 값이 동일하게 3이 나왔다. 그러면, items[4] 를 보는데, 이미 차있기 때문에 그 다음 칸인 items[5] 를 본다. 여긴 비어 있으니까 items[5] 에 slow 의 value 값을 넣어서 충돌을 해결하는 방식을 개방 주소법(Open Addressing) 이라고 한다.
- 해쉬 정리
해쉬 테이블(Hash Table)은 "키" 와 "데이터"를 저장함으로써 즉각적으로 데이터를 받아오고 업데이트하고 싶을 때 사용하는 자료구조이다.
해쉬 함수(Hash Function)는 임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수이다.
해쉬 테이블의 내부 구현은 키를 해쉬 함수를 통해 임의의 값으로 변경한 뒤 배열의 인덱스로 변환하여 해당하는 값에 데이터를 저장한다.
그렇기 때문에 즉각적으로 데이터를 찾고, 추가할 수 있는 것이고, 만약, 해쉬 값 혹은 인덱스가 중복되어 충돌이 일어난다면? -> 체이닝과 개방 주소법 방법으로 해결할 수 있다.
