Sage: 마이크로서비스 성능 장애, 상관관계 말고 인과관계로 찾기
0. 이 글을 읽기 전에
클라우드 환경에서 서비스가 갑자기 느려졌다. 대시보드를 열어보니 CPU 사용률이 높은 서비스가 몇 개 보인다. 그 중 하나를 골라서 스케일 아웃했는데도 latency가 나아지지 않는다. 이런 경험을 해봤다면, Sage가 왜 나왔는지 바로 와닿을 거야.
Sage는 2021년 ASPLOS에 발표된 논문으로, 마이크로서비스 환경에서 QoS 위반이 발생했을 때 단순히 "어떤 서비스가 느린가?"가 아니라 "어떤 서비스가 느림을 시작시켰는가?"를 찾는 시스템이야. 핵심 아이디어는 Causal Bayesian Network(CBN) 으로 서비스 간 인과 구조를 잡고, Graphical Variational Autoencoder(GVAE) 로 counterfactual을 생성해서 "이 서비스만 정상이었다면 QoS가 회복되었을까?"를 묻는 것이다.
이 글에서는 다음 질문들이 전부 납득될 때까지 설명할 거야.
- 왜 utilization threshold나 상관관계로는 root cause를 못 찾는가?
- 왜 RPC latency propagation에 Markov property가 성립하는가?
- CBN의 X, Y, Z는 각각 무엇인가?
- 를 왜 product로 factorize할 수 있는가?
- encoder의 conditioning set에 왜 같은 항이 들어가는가?
- CVAE만 쓰지 않고 왜 GSNN까지 섞는가?
- counterfactual로 root cause를 어떻게 찾는가?
1. 왜 기존 방법이 안 되는가
마이크로서비스의 backpressure 문제
모놀리식 서비스라면 "CPU가 높으면 그 프로세스가 범인"이라는 로직이 어느 정도 통한다. 하지만 수십~수백 개의 서비스가 RPC로 연결된 마이크로서비스 환경에서는 이 로직이 자주 틀린다. 왜냐하면 downstream 서비스가 막히면 upstream 서비스는 자기 일이 많아서가 아니라 응답을 기다리느라 CPU/메모리가 올라가기 때문이다. 이를 backpressure라고 한다.
즉, high utilization은 원인(cause)일 수도 있지만 결과(effect)일 수도 있다.
기존 autoscaling의 한계
AWS autoscaling 정책처럼 CPU utilization이 50~70%를 넘으면 해당 서비스를 스케일 아웃하는 방식은, backpressure를 맞고 있는 서비스를 실제 범인으로 오인하기 쉽다. 게다가 서비스마다 resource 요구량이 다르므로, 전역 threshold 하나로는 "적게 쓰고도 병목이 되는 서비스"를 잡지 못한다.
PC algorithm 기반 방법의 한계
CauseInfer나 Microscope 같은 시스템은 conditional independence test와 PC algorithm으로 인과 그래프를 데이터로부터 복원하려 한다. 그런데 이 방식은 두 가지 문제가 있다. 첫째, finite sample에서 conditional cross entropy 추정 오차가 발생하면 그래프 구조 자체가 틀어진다. 둘째, PC algorithm의 worst-case complexity는 노드 수에 대해 지수적으로 증가해서 수십 개 이상의 tier가 있는 실서비스에서 scaleability가 떨어진다.
Seer의 한계
Seer는 CNN+LSTM 기반 supervised 방식으로 QoS 위반을 미리 예측해서 막는다. 정확도는 높지만, 커널 수준에서 system stack 전반의 queue length를 millisecond 단위로 추적해야 하고, 학습 데이터를 만들려면 운영 중인 서비스에 resource contention을 강제로 주입해서 trace를 라벨링해야 한다. 대규모 production 환경에서는 이 과정 자체가 서비스를 망가뜨릴 수 있어서 practical하지 않다.
Sage는 이 모든 한계에 대한 대응으로 설계되었다. label이 없어도 되고, kernel instrumentation이 없어도 되고, 고주파 tracing이 없어도 된다.
2. Sage의 전체 그림
Sage의 흐름을 한 문장으로 요약하면 이렇다.
RPC trace로 CBN을 만들고, CBN 구조를 따르는 GVAE를 학습한 뒤, 서비스 metric을 하나씩 정상값으로 되돌린 counterfactual world를 만들어서 QoS가 회복되는지 확인한다.
전체 파이프라인은 크게 네 단계다.설계 원칙을 논문에서 요약하면 다음과 같다.
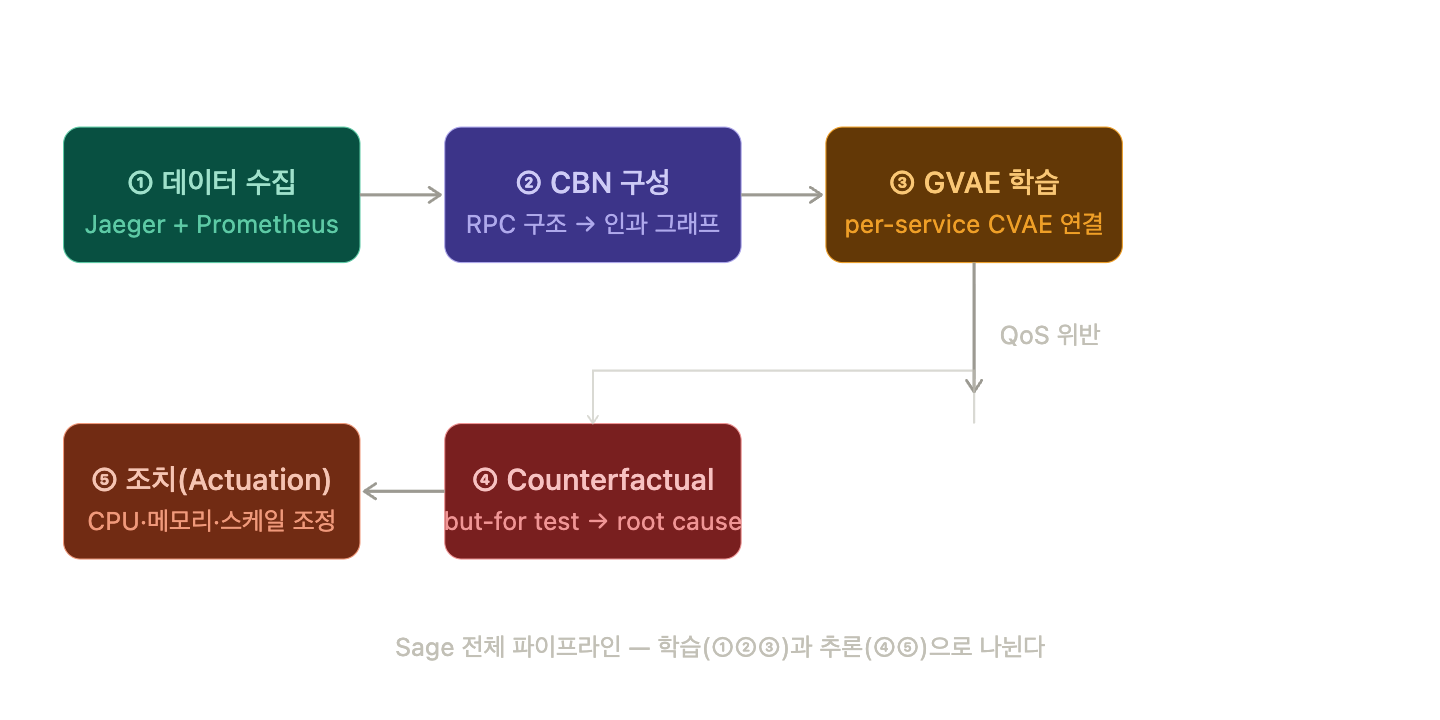
- Unsupervised learning: 라벨링 없이 동작한다. 운영 트래픽 trace를 그대로 학습 데이터로 쓴다.
- Sampling frequency에 강인함: 시간적 패턴에 의존하지 않아 Dapper 같은 aggressive sampling (1%)에서도 정확도가 유지된다.
- User-level metrics만 사용: 커널 계측 없이 cloud monitoring API와 distributed tracing framework로 얻을 수 있는 정보만 쓴다.
- Partial retraining: 서비스가 업데이트될 때 전체 재학습 없이 변경된 서비스와 그 이웃만 재학습한다.
- Fast resolution: 여러 후보 원인을 병렬로 검토해서 빠르게 수렴한다.
3. RPC latency decomposition: 하나의 호출을 어떻게 쪼개나
Sage를 이해하려면 먼저 "RPC 한 번의 latency"를 어떻게 바라보는지부터 잡아야 한다.
클라이언트가 서버를 호출할 때, 전체 왕복 시간 (client-side latency)는 대략 다음으로 분해된다.
- : 서버가 실제로 요청을 처리하는 server-side latency
- : 요청이 네트워크를 통해 서버까지 도달하는 지연
- : 응답이 다시 클라이언트까지 오는 지연
Jaeger 같은 distributed tracing framework로는 application-level 시점만 찍을 수 있다. 커널 내부 구간(TCP/IP 처리 등)은 heartbeat 신호로 근사한다. 즉 Sage는 커널 전수 계측 없이 user-level tracing만으로 latency를 분해하겠다는 설계다.
중요한 점은, 하나의 RPC 에 대해 CBN에는 최소 4개의 노드가 생긴다는 것이다.
이것들이 나중에 CBN의 latency node(Y)가 된다.
4. 왜 latency propagation에 Markov property가 성립하는가
서비스 A가 B를 호출하고, B가 C, D를 병렬로 호출한다고 하자. B의 server-side latency는 자신의 처리 시간뿐만 아니라, C와 D의 응답을 기다리는 시간에도 의해 결정된다. 즉 downstream latency는 upstream으로 전파된다.
논문의 핵심 관찰은 이 전파가 local Markov property를 따른다는 것이다.
어떤 RPC latency는 자신의 child RPC latencies가 주어지면, non-descendant RPC들과 조건부 독립이다.
형식으로 쓰면:
예를 들어 RPC0가 RPC1을, RPC1이 RPC2를 호출하는 체인이라면, RPC1의 latency가 주어졌을 때 RPC0의 latency는 RPC2의 latency와 조건부 독립이다. RPC2의 지연이 이미 RPC1을 통해서만 RPC0에 영향을 줄 수 있기 때문이다.
논문은 이를 MI/CMI 실험으로 실증한다. 거리 2인 두 RPC의 MI는 높지만, 중간 RPC의 latency를 conditioning하면 CMI가 0에 수렴한다.
이 성질이 왜 중요하냐면, 이 덕분에 joint distribution을 per-RPC product로 factorize할 수 있기 때문이다. 다음 섹션이 바로 그 이야기다.
5. Sage의 CBN: X, Y, Z는 무엇인가
CBN에는 세 종류의 노드가 있다.
5.1 Metric node:
관측 가능한 resource-related metric. 논문은 이를 다시 두 그룹으로 나눈다.
- 서버 관련 metric : CPU utilization, memory bandwidth, context switch 등 → 서버 처리 시간에 영향
- 네트워크 관련 metric : RTT, packet loss rate, bandwidth 등 → RPC channel 지연에 영향
replica 수가 tier마다 달라도 입력 크기를 일정하게 유지하기 위해 각 metric을 percentile vector로 표현한다. 예를 들어 형태.
는 exogenous variable이다. CBN에서 다른 노드가 X를 결정하지 않는다. X는 모델 바깥에서 주어지는 외생 변수다.
5.2 Latency node:
관측 가능한 latency 변수. 각 RPC 마다:
tail latency가 QoS와 더 밀접하게 연결되어 있으므로 high percentile을 더 촘촘히 샘플링한다.
5.3 Latent variable:
관측되지 않는 숨은 요인. 논문은 이를 latency stochasticity를 설명하는 잠재 요인이라고 부른다. 같은 CPU utilization이더라도 그날그날 latency 분포가 달라지는 이유가 여기에 있다.
역시 두 가지로 나뉜다.
- : 개별 microservice를 캡처하는 server-related latent
- : 서비스 간 링크를 캡처하는 network-related latent
는 CBN에서 dashed node로 표현된다. 직접 측정할 수 없고, 모델이 추론해야 한다.
가 왜 필요하냐면, Sage가 단순한 deterministic mapping 이 아니라
라는 생성 모델을 세우기 때문이다. 이렇게 해야 "현재와 완전히 동일한 상황이 과거에 없었더라도, 그와 유사한 가능한 세계"를 샘플링해서 realistic counterfactual을 만들 수 있다.
6. 왜 서버 관련과 네트워크 관련 변수를 굳이 분리하는가
처음 보면 사소한 것 같지만, 이 분리는 구조 설계에서 중요하다.
네트워크 bandwidth traffic은 CPU utilization과 상관될 수 있다. 하지만 그것이 곧바로 모든 서버 metric에 직접 인과적으로 영향을 준다고 보기 어렵다. 반대로 서버 내부 처리 로직이 링크의 delay 구조를 직접 정의하지도 않는다.
이 분리 덕분에 나중에 counterfactual을 만들 때 다음처럼 구분해서 검증할 수 있다.
- "CPU를 정상화했을 때의 세계" → 를 통해 서버 latency 경로만 개입
- "network RTT를 정상화했을 때의 세계" → 를 통해 네트워크 delay 경로만 개입
이 두 세계를 섞어서 만들면 어떤 원인 때문에 QoS가 회복되었는지 구분이 불가능해진다.
7. CBN을 어떻게 구성하는가: 4가지 규칙
Sage는 PC algorithm처럼 구조를 데이터로부터 전부 학습하지 않는다. 대신 RPC dependency graph와 latency propagation 도메인 지식을 이용해서 CBN을 직접 만든다. 논문은 다음 네 가지 규칙을 제시한다.
규칙 1: Metric node는 exogenous. 외부에서 주어진다. 의 분포는 모델이 설명하지 않는다. 다만 latent 의 분포는 대응하는 에 의해 modulate되므로 edge가 생긴다.
규칙 2: 비-leaf RPC의 server-side latency는 자신의 child RPC들의 client-side latency와, 해당 서버 tier의 metric/latent에 의해 결정된다.
규칙 3: client-side latency는 server-side latency + network delay + 호출자 상태의 결과다.
규칙 4: request/response network delay는 해당 링크의 network metric/latent로 결정된다.
한 가지 주의할 점이 있다. RPC graph의 화살표 방향과 CBN의 edge 방향은 반대로 보일 수 있다. 호출 방향(부모 → 자식)과 latency가 결정되는 방향(자식 latency → 부모 latency)이 다르기 때문이다. 부모가 자식을 호출하더라도, 부모의 server-side latency는 자식의 응답을 기다리는 시간에 의해 결정된다.
8. 핵심: 왜 를 factorize할 수 있는가
이 부분이 Sage 논문에서 가장 자주 헷갈리는 부분이다. 논문의 factorization 식이 갑자기 나온 것처럼 보이지만, 사실은 두 단계의 정당화가 있다.
8.1 출발점: chain rule
어떤 joint distribution이든 chain rule로는 항상 이렇게 쓸 수 있다.
그런데 이렇게 쓰면 각 항이 앞의 모든 노드를 조건으로 가져야 해서 너무 크다.
8.2 CBN의 local Markov property로 조건 집합을 줄인다
CBN에서는 각 노드가 자기 직접 부모들(Parents)만 주어지면 나머지 비자손들과 조건부 독립이다. 따라서
로 줄어든다. 결국
이게 논문 factorization의 본질이다. 앞서 섹션 7에서 정의한 가 바로 이 직접 부모들에 해당한다.
8.3 논문의 실제 식
논문은 이를 각 RPC의 4가지 latency node에 대해 다음처럼 쓴다.
9. 자주 드는 의문 1: "식 왼쪽엔 가 있는데 오른쪽에서 사라졌나?"
전혀 사라지지 않았다. 안으로 들어간 것뿐이다.
예를 들어
가 여전히 conditioning set 안에 있다. 논문이 라는 이름으로 묶어서 표기한 것일 뿐이다.
10. 자주 드는 의문 2: "decoder 입력으로 다른 를 넣으면 cheating 아닌가?"
decoder에 들어가는 는 복원하려는 target 그 자체가 아니라, 그 노드의 causal parent에 해당하는 다른 latency node들이다.
예를 들어 에서 입력으로 들어가는 는 의 인과적 부모들이다. "클라이언트 latency는 요청 delay + 서버 처리 시간 + 응답 delay로 결정된다"는 도메인 구조를 decoder에 직접 반영하는 것이다.
마찬가지로 에서 child RPC의 client-side latency들이 들어가는 이유는, 비-leaf RPC의 server-side latency가 자식 호출을 기다리는 시간에 의해 결정되기 때문이다.
Sage에서 "다른 Y를 conditioning"한다는 것은 "인과 구조상 부모에 해당하는 latency node를 conditioning variable로 둔다"는 뜻이지, autoregressive하게 자기 자신을 예측하는 것이 아니다.
11. latent prior와 posterior의 factorization
세 분포를 모두 정리하면 다음과 같다.
Prior: 만 보고 를 샘플링
각 latent는 자기 대응 metric만 본다. 서버 latent는 서버 metric이, 네트워크 latent는 네트워크 metric이 modulate한다.
Posterior: 와 를 모두 보고 를 추론
encoder의 conditioning set 는 prior보다 더 넓다.
12. 자주 드는 의문 3: 는 왜 필요한가
에는 단순히 , , 외에 항이 추가되어 있다. 처음 보면 이게 왜 필요한지 의아하다.
이건 Bayesian network에서 collider(V-structure) 처리 문제다.
일반적인 Bayesian network에서 경로 차단 규칙을 생각해보자.
- 체인 : 를 conditioning하면 경로가 막힌다.
- Fork : 를 conditioning하면 경로가 막힌다.
- Collider : 기본적으로 경로가 막혀 있다. 그런데 collider 나 그 자손을 conditioning하면 오히려 경로가 열린다.
Sage에서 encoder는 를 추정할 때 이미 여러 를 관측한 상태다. 이 중 일부는 에 대해 collider 역할을 하는 노드일 수 있다. 이 collider를 conditioning한 상태에서 posterior를 추론하면, 원래는 막혀 있던 경로가 열리면서 추가적인 의존성이 생긴다.
는 바로 이 패턴, 즉
를 형성하는 노드들이다.
이걸 encoder의 conditioning set에 포함하는 이유는, posterior inference 시 collider가 열리면서 생기는 추가 의존성을 반영하기 위해서다. decoder의 에는 이 항이 없는데, decoder는 생성 방향의 local parent structure만 사용하면 되기 때문이다. encoder는 를 역방향으로 추론해야 하므로, 관측된 때문에 열리는 경로까지 고려해야 한다.
13. Sage의 생성 모델: CVAE + GSNN hybrid
13.1 CVAE의 기본 구조
Sage는 counterfactual 생성을 위해 Conditional Variational Autoencoder(CVAE) 를 사용한다. CVAE는 조건 가 주어졌을 때 latent 를 통해 target 의 분포를 생성한다.
- Encoder : 관측된 로부터 latent 의 posterior를 추론
- Prior network : 만 보고 latent 의 prior를 학습
- Decoder : 로부터 를 생성
학습 시에는 encoder posterior에서 를 샘플링해서 decoder를 학습한다. 생성 시에는 prior에서 를 샘플링해서 를 만든다.
13.2 CVAE loss: negative ELBO
- Reconstruction term: posterior에서 뽑은 latent로 decoder가 원래 를 잘 복원하도록 강제한다.
- KL term: encoder posterior가 generation에 쓸 prior와 너무 멀어지지 않게 regularize한다. 은 disentangled latent factor를 장려하는 hyperparameter다.
13.3 왜 GSNN까지 추가하는가
CVAE에는 하나의 구조적 문제가 있다. 학습 시와 생성 시에 를 뽑는 분포가 다르다는 것이다.
- 학습: (posterior)
- 생성: (prior)
이 불일치를 보완하기 위해 Sage는 Gaussian Stochastic Neural Network(GSNN) 항을 추가한다.
GSNN loss는 posterior가 아니라 prior에서 직접 샘플링한 로도 decoder가 를 잘 생성하도록 학습한다. 즉 generation phase에서 실제로 쓰는 분포를 학습에도 반영한다.
최종 hybrid loss는
직관적으로 요약하면:
- CVAE 항은 "latent inference를 잘 하게 만든다"
- GSNN 항은 "generation phase에서도 안정적으로 작동하게 보강한다"
13.4 왜 하나의 큰 CVAE가 아니라 GVAE를 쓰는가
논문은 전체 마이크로서비스 그래프를 하나의 큰 CVAE로 모델링하지 않는다. 이유는 세 가지다.
- 큰 CVAE 하나는 CBN의 구조 정보를 직접 반영하지 못해서 spurious correlation에 기반한 counterfactual을 만들 수 있다.
- 전체를 하나로 묶으면 partial retraining이 불가능해진다.
- 어떤 서비스의 latency가 어떤 경로로 frontend에 전파되는지 추적이 안 된다.
그래서 Sage는 서비스별로 작은 CVAE를 만들고, 이를 CBN 구조에 따라 연결한 GVAE(Graphical VAE) 를 구성한다. 앞서 factorize했던 식 덕분에 최종 loss도 per-service 합으로 쓸 수 있다.
Encoder와 prior network는 병렬 학습이 가능하다. Decoder는 부모 decoder의 출력이 입력으로 필요하므로 CBN의 깊이만큼 직렬로 cascade된다.
14. counterfactual query로 root cause를 찾는 방법
드디어 Sage의 핵심 응용 부분이다.
14.1 아이디어: but-for test
Sage는 site reliability engineer(SRE)가 운영에서 하는 사고 실험을 모델 위에서 가상으로 실행한다.
SRE라면 의심되는 서비스의 버전이나 자원 설정을 "안전했던 상태"로 되돌려보고, 다른 조건은 그대로 유지하면서 QoS가 회복되는지 볼 것이다. Sage는 이 과정을 실제 intervention 없이 학습된 생성 모델 위에서 가상 세계로 수행한다.
형식적으로는 이런 질문이다.
만약 서비스 의 metric 만 정상 상태였다면, end-to-end latency 는 QoS를 만족했을까?
이게 전형적인 but-for test다: "그 원인이 없었더라면 결과도 발생하지 않았을까?"
14.2 "정상값"은 어디서 가져오나
논문은 QoS를 만족했던 구간의 per-tier performance/usage median을 normal values로 정의한다. QoS 위반이 발생하면 이 값들을 참조해서 각 서비스를 "정상 상태"로 되돌린 counterfactual을 만든다.
14.3 두 서비스 중 누가 범인인가: 예시
서비스 1과 서비스 2의 CPU utilization이 모두 비정상이라고 하자.
Counterfactual 1: 서비스 1의 metric만 정상값으로. 서비스 2는 그대로.
→ end-to-end latency를 GVAE로 생성 → QoS 회복 여부 확인
Counterfactual 2: 서비스 2의 metric만 정상값으로. 서비스 1은 그대로.
→ end-to-end latency를 GVAE로 생성 → QoS 회복 여부 확인
만약 Counterfactual 1에서는 QoS가 여전히 깨지고, Counterfactual 2에서 회복된다면 → 서비스 2가 root cause다.
단일 서비스 하나만 바꿔서 회복이 안 된다면, 논문은 여러 서비스 조합도 iterative하게 탐색한다. 매 iteration에서 end-to-end latency를 가장 많이 낮추는 서비스를 추가한다.
14.4 비인과적 RPC는 그대로 재사용
counterfactual을 만들 때, CBN이 causal relationship을 알려주므로 검사 중인 서비스와 인과적으로 무관한 RPC들은 현재 latency를 그대로 재사용한다. 전체 그래프를 다시 샘플링하지 않아도 된다. 이는 실제 국소 개입(local intervention)의 효과를 제대로 모사한다.
15. 2단계 root cause 분석
Sage는 실용성을 위해 two-level approach를 쓴다.
1단계: culprit service 찾기
각 서비스마다 모든 metric을 정상값으로 되돌린 service-level counterfactual을 만든다. end-to-end latency를 QoS 이하로 가장 많이 낮추는 서비스를 culprit로 지정한다.
2단계: culprit resource 찾기
culprit service가 정해지면, 그 서비스 내부의 자원별 counterfactual을 만든다.
- CPU frequency/utilization → CPU indicator
- memory utilization → memory indicator
- network bandwidth, TCP latency, ICMP latency → network indicator
한 번에 "서비스 + 자원"을 동시에 찾는 one-level 방식보다 더 빠르고 간단하다.
16. Sage의 시스템 구현
Sage의 실제 구현은 세 컴포넌트로 구성된다.
Data Streamer: Jaeger와 Prometheus에 HTTP로 쿼리해서 trace와 metric을 가져온다. feature encoding, aggregation, dimensionality reduction, normalization을 수행하고 RPC latency percentile과 tier별 usage percentile을 출력한다.
GVAE: PyTorch로 구현. 각 VAE의 encoder/decoder/prior network는 3~5개의 fully connected layer. 매 두 hidden layer 사이에 batch normalization, 마지막 hidden layer 이후에 dropout을 적용한다.
Actuation Controller: root cause가 특정되면 자원 조정 명령을 내린다. 어떤 자원이 원인으로 지목되느냐에 따라 CPU frequency 조정, 서비스 scale up/out, co-scheduled task 제한, LLC 파티셔닝(Intel CAT), 네트워크 bandwidth 파티셔닝(Linux tc qdisc) 등 다양한 조치를 취한다. 먼저 해당 노드 내에서 자원을 조정하고, 그것으로 부족할 때만 새 노드에 scale out하거나 migration한다.
전체 master는 약 6KLOC Python으로 구현되어 있고, fault tolerance를 위해 hot stand-by 2개를 유지한다.
Tracing overhead: 1% sampling frequency에서 p99 latency 기준 약 2.6%, max throughput 기준 약 0.66%. Prometheus는 10초 interval로 수집 시 오버헤드가 negligible하다고 보고한다.
17. 마이크로서비스 업데이트 처리: partial + incremental retraining
마이크로서비스는 자주 업데이트된다. 수백 노드짜리 클러스터를 매번 처음부터 재학습하면 몇 시간이 걸릴 수 있다.
Sage는 두 가지 전략을 조합한다.
Selective partial retraining: CBN의 causal structure를 이용해서 업데이트된 노드와 그 descendants에 해당하는 neuron만 재학습한다. 다른 노드들은 인과적으로 영향을 받지 않으므로 건드리지 않는다.
Incremental retraining: 이전 모델의 파라미터를 초기값으로 재사용한다. 서비스가 추가/삭제/변경되면 해당 부분만 network를 reshape한다.
논문은 RPC graph가 변경되지 않으면 Sage는 모델을 아예 재학습하지 않고, RPC graph가 바뀌면 low-frequency trace로 CBN을 업데이트한 뒤 변경된 서비스와 upstream만 재학습한다고 설명한다.
결과적으로 partial+incremental 방식은 from-scratch 대비 3~30배 빠른 재학습을 달성하고, 업데이트 직후에도 from-scratch보다 훨씬 빠르게 정확도를 회복한다.
online learning의 catastrophic forgetting 문제 는 현재 데이터와 이전 데이터를 학습 배치에 interleave해서 완화한다. class imbalance 문제 (QoS 만족 trace가 위반 trace보다 훨씬 많은 문제)는 minority class를 oversample해서 대응한다.
18. 실험 결과
실험 환경
- Local cluster: 2-socket 40-core 서버 5대 + 88-core 서버 2대, 10GbE NIC, Docker
- Google Compute Engine: 84 노드, Social Network 배포, 스케일 검증용
워크로드
- Chain, Fanout (synthetic Thrift microservice topologies)
- Social Network, Media Service, Hotel Reservation (DeathStarBench [48])
핵심 결과
| 지표 | 결과 |
|---|---|
| Root cause 식별 정확도 | 93% 이상 (모든 워크로드) |
| Counterfactual 생성 | 0.91 이상 (모든 애플리케이션) |
| RMSE (Chain / Fanout / Social) | 7.8 / 5.1 / 3.2 |
| GCE (6.7× 규모) inference 시간 증가 | +26.5% (Seer는 유사 규모에서 4× 증가) |
| Local inference 시간 | 49ms |
| GCE inference 시간 | 62ms |
Incomplete instrumentation 상황에서는 Seer 정확도가 50% non-instrumented 시 34%까지 떨어지지만, Sage는 동일 조건에서도 94%를 유지한다.
19. Sage가 왜 PC algorithm 기반 방법보다 유리한가
요약하면 이렇다.
| Sage | CauseInfer / Microscope | |
|---|---|---|
| 구조 학습 방식 | RPC graph 기반 직접 구성 | conditional independence test + PC algorithm |
| 스케일 문제 | CBN depth 기반 직렬 decoder → sub-linear | PC algorithm worst-case 지수 복잡도 |
| 오차 원인 | 없음 (구조가 직접 주어짐) | finite sample CI test 오차 + trace discretization |
| causality 검증 방식 | counterfactual로 매 이벤트 검증 | graph 구조 traversal |
20. Sage vs Seer: 무엇이 다른가
| Sage | Seer | |
|---|---|---|
| 방식 | unsupervised, reactive | supervised, proactive |
| 데이터 라벨링 | 불필요 | 운영 서비스에 contention 주입 필요 |
| instrumentation | user-level metrics | kernel-level queue length 계측 |
| tracing frequency | low-frequency sampling으로 충분 | millisecond 단위 고주파 tracing 필요 |
| QoS violation 대응 | 발생 후 빠르게 탐지 + 조치 | 발생 전 예측으로 회피 |
| production 적용성 | high | 대규모 prod에서 부담 |
Seer가 예측(proactive)이라는 점에서 더 이상적으로 보이지만, Sage는 현실적인 대규모 production 배포 가능성을 훨씬 높게 가져간 설계다.
21. Sage의 한계
논문 자체도 한계를 명확히 적는다.
1. 과거에 본 적 없는 상황은 탐지 어렵다
Sage도 data-driven 모델이다. 학습 데이터에서 전혀 없었던 failure mode는 generative model이 realistic counterfactual을 만들기 어렵다. 논문은 이 경우 Chaos Monkey 같은 fault injection 도구로 수집한 데이터를 보충할 수 있다고 언급한다.
2. resource 관련 문제에만 초점
Sage는 deployment, configuration, resource provisioning 관련 성능 문제를 타겟으로 한다. concurrency bug나 algorithmic inefficiency 같은 design bug는 현재 시스템에서 직접 다루지 못한다. 모든 resource-related source를 counterfactual로 제거해도 QoS 위반이 남으면 개발자가 개입해야 한다.
3. RPC dependency cycle 처리
일반적인 CBN은 cycle을 표현하지 못한다. bidirectional streaming RPC처럼 cycle이 생기는 경우, Sage는 양 방향을 하나의 metanode로 합쳐서 처리한다. 이는 그 RPC 내부 구조를 일부 단순화한다.
4. false positive/negative 발생 케이스
논문에서 false negative(3~4%)의 주요 원인은 여러 서비스에 동시에 독립적인 문제가 발생한 경우다. 예를 들어 네트워크 문제가 서비스 A를 때리는 동시에 CPU 문제가 서비스 B를 때리면, 하나씩 되돌리는 방식으로는 동시 복합 원인을 놓칠 수 있다. False positive(3~5%)는 QoS를 실제로 위반하지 않을 정도의 spurious correlation 때문에 발생한다.
22. 핵심 개념 정리
Q. RTT와 RPC latency는 같은 개념인가?
아니다. RTT는 네트워크 왕복 시간에 가까운 개념이고, RPC client-side latency 는 네트워크 delay뿐 아니라 서버 처리 시간과 application queueing까지 포함한다. Sage는 이 둘을 /와 /로 분리해서 각각 독립적으로 모델링한다.
Q. 는 그냥 노이즈인가?
완전한 백색 잡음이 아니다. 는 "설명되지 않은 잔차"보다는 "생성 모델에서 latency stochasticity를 담당하는 숨은 상태"에 가깝다. counterfactual generation에서 realistic한 latency sample을 만들기 위해 필수적이다.
Q. "서비스 1을 정상값으로 바꿨는데도 QoS가 회복되지 않았다" → "서비스 1은 원인이 아니다"인가?
"서비스 1 alone만으로는 QoS 위반을 설명하지 못한다"로 이해해야 한다. 여러 서비스가 복합적으로 원인일 수도 있다. 논문은 단일 서비스로 회복이 안 되면 조합 탐색으로 넘어간다고 설명한다.
23. 마무리
Sage를 한 문장으로 다시 압축하면 이렇다.
CBN으로 마이크로서비스 간 인과 구조를 잡고, 그 구조를 따르는 GVAE를 학습한 뒤, "이 서비스만 정상이었다면?"이라는 counterfactual 질문으로 QoS 위반의 실제 원인을 찾는다.
Sage가 흥미로운 이유는 단순히 정확도가 높아서가 아니다. "상관관계가 아니라 인과관계로 성능 문제를 찾겠다"는 아이디어를, 운영 환경에서 실제로 쓸 수 있는 수준의 practical한 제약(label 불필요, low-frequency sampling, user-level metric만 사용, partial retraining)과 함께 풀어냈다는 점이다.
이 글은 Sage 논문(ASPLOS '21, Yu Gan et al.)을 바탕으로 작성되었다.
논문 원문: https://dl.acm.org/doi/10.1145/3445814.3446700
